生成器和推导式以及生成器表达式
一.生成器
1.生成器的本质就是迭代器.
2.生成器的特点和迭代器一样,取值方式和迭代器一样(__next__(),send():给上一个yield传值).
3.生成器一般由生成器函数或者生成器表达式来创建.
4.其实就是手写的迭代器.
5.在Python中有三种方式来获取生成器:
(1).通过生成器函数
(2).通过各种推导式来实现生成器
(3).通过数据的转换也可以获取生成器
二.生成器函数
1.和普通函数没有区别,里面由yield的函数就是生成器函数.
def func():
print("111")
return 222
ret = func()
print(ret)
结果:
111
222
将函数中的return换成yield就是生成器
def func():
print("111")
yield 222
ret = func()
print(ret)
结果:
<generator object func at 0x10567ff68>
两个函数很是相似但是运行结果不同,就是由于函数中存在了yield,既然存在yield的,那么这个函数就是一个
生成器函数,这个时候我们再次执行这个函数的时候就不再是函数的执行了,而是获取这个函数的生成器.
2.生成器函数在执行的时候,默认不会执行函数体,返回生成器.
3.通过生成器的__next__()分段执行这个函数.
def func():
print("111")
yield 222
gener = func() # 这个时候函数不会执行. 而是获取到生成器
ret = gener.__next__() # 这个时候函数才会执行. yield的作用和return一样. 也是返回数据
print(ret)
结果:
111
222
可以看到,yield和return的效果是一样的,那么区别就在于:yield是分段来执行一个函数;return是直接停止执行函数
def func():
print("111")
yield 222
print("333")
yield 444
gener = func()
ret = gener.__next__()
print(ret)
ret2 = gener.__next__()
print(ret2)
ret3 = gener.__next__() # 最后一个yield执行完毕. 再次__next__()程序报错,也就是说和return无关了.
print(ret3)
结果:
111
Traceback (most recent call last):
222
File "F:/python/python kecheng/day13/code/02 生成器函数.py", line 105, in <module>
333
444
ret3 = gener.__next__() # 最后一个yield执行完毕. 再次__next__()程序报错,也就是说和return无关了.
StopIteration
当程序运行完最后yield,那么后面继续进行__next__()程序会报错
4.作用:
假设我一生需要10000颗鸡蛋
def cloth():
lst = []
for i in range(0, 10000):
lst.append("鸡蛋"+str(i))
return lst
cl = cloth()
return就相当于我直接买了10000颗鸡蛋,没地存,贼尴尬,最好的效果就是我吃一颗,买一颗
def cloth():
for i in range(0, 10000):
yield "鸡蛋"+str(i)
cl = cloth()
print(cl.__next__())
print(cl.__next__())
print(cl.__next__())
print(cl.__next__())
...
区别:第一种直接一次性全拿出来,很占用内存,第二种使用生成器,一次就拿一个出来,
用多少买多少生成器是一个一个的指向下一个,不会回去,__next__()到哪,指针就到哪,
下一次继续获取指针指向的值
5.send()给上一个yield传值,不能再开头(没有上一个yield),最后一个yield也不可以用send()
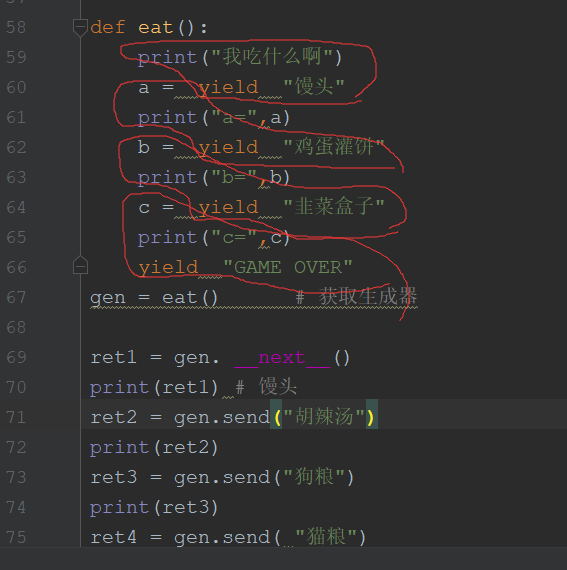
def eat():
print("我吃什么啊")
a = yield "馒头"
print("a=",a)
b = yield "鸡蛋灌饼"
print("b=",b)
c = yield "韭菜盒子"
print("c=",c)
yield "GAME OVER"
gen = eat() # 获取生成器
ret1 = gen. __next__()
print(ret1) # 馒头
ret2 = gen.send("胡辣汤")
print(ret2)
ret3 = gen.send("狗粮")
print(ret3)
ret4 = gen.send( "猫粮")
print(ret4)
结果:
我吃什么啊
馒头
a= 胡辣汤
鸡蛋灌饼
b= 狗粮
韭菜盒子
c= 猫粮
GAME OVER
运行过程:
6.send和__next__()区别:
(1).send和next都是让生成器向下走一次
(2).send可以给上一个yield的位置传递值,不能给最后一个yield发送值,在第一次执行生成器代码的
时候不能使用send()
7.生成器可以使用for循环来获得内部元素:
def func():
print(111)
yield 222
print(333)
yield 444
print(555)
yield 666
gen = func()
for i in gen:
print(i)
结果:
111
222
333
444
555
666
三.推导式
1.列表推导式 [结果 for循环 条件筛选]
lst = []
for i in range(1, 15):
lst.append(i)
print(lst)
列表推导式是通过一行来构建你想要的列表,列表推导式看起来代码简单,
但是出现错误很难排查
列表推导式的常用写法:[结果 for 变量 in 可迭代对象]
lst = [i for i in range(1, 15)]
print(lst)
我们还可以对列表中的数据进行筛选
筛选模式:
[结果 for 变量 in 可迭代对象 if 条件]
# 获取1-100内所有的偶数
lst = [i for i in range(1, 100) if i % 2 == 0]
print(lst)
# 寻找名字中带有两个e的人的名字
names = [['Tom', 'Billy', 'Jefferson' , 'Andrew' , 'Wesley' , 'Steven' ,'Joe'],
[ 'Alice', 'Jill' , 'Ana', 'Wendy', 'Jennifer', 'Sherry']]
lst = [name for line in names for name in line if type(name) == str and name.count("e") == 2]
print(lst)
lst = []
for line in names:
for name in line:
if name.count("e") == 2:
lst.append(name)
print(lst)
结果:
['Jefferson', 'Wesley', 'Steven', 'Jennifer']
['Jefferson', 'Wesley', 'Steven', 'Jennifer']
2.字典推导式 {k:v for循环 条件筛选}
# 将[11,22,33,44] =>转换为: {0:11,1:22,2:33}
lst = [11,22,33,44]
dic = {i:lst[i] for i in range(len(lst)) if i < 4} # 字典推导式就一行
print(dic)
结果:
{0: 11, 1: 22, 2: 33, 3: 44}
# 将字典中的key和value互换
dic = {"jj": "林俊杰", "jay": "周杰伦", "zs": "赵四", "ln":"刘能"}
d = {v : k for k,v in dic.items()}
print(d)
结果:
{'林俊杰': 'jj', '周杰伦': 'jay', '赵四': 'zs', '刘能': 'ln'}
3.集合推导式 {k for循环 条件筛选}
# 集合推导式
lst = [1, 1, 4, 6,7,4,2,2]
s = { el for el in lst } #去重
print(s)
结果:
{1, 2, 4, 6, 7}
四.生成器表达式
1.语法:(结果 for循环 条件筛选)
生成器表达式和列表推导式的语法基本是一样的,只是把[]换成()
gen = (i for i in range(10))
print(gen)
结果:
<generator object <genexpr> at 0x106768f10>
打印的结果就是一个生成器,我们可以使用for循环来循环这个生成器
gen = ("麻花藤我第%s次爱你" % i for i in range(10))
for i in gen:
print(i)
2.特点:
(1).惰性机制
(2).只能向前
(3).节省内存(鸡蛋)
def func():
print(111)
yield 222
g = func() #生成器g
g1 = (i for i in g) #生成器g1,但是g1的数据来源于g
g2 = (i for i in g1) #生成器g2,来源于g1
print(list(g)) #获取g中的数据,这时func()才会被执行.打印111,获取到222,g完毕
print(list(g1)) #获取g1中的数据,g1的数据来源是g,但是g已经取完了.g1也就没有数据了
print(list(g2)) #和g1同理
结果:
111
[222]
[]
[]
3.生成器表达式和列表推导式的区别:
(1).列表推导式比较耗内存,一次性加载.生成器表达式几乎不占内存,使用的时候
才分配和使用内存
(2).得到的值不一样,列表推导式得到的是一个列表,生成器表达式获取的是一个
生成器
举个例子:
同样一篮子鸡蛋,列表推导式:直接拿到一篮子鸡蛋;生成器表达式:拿到一个老母鸡,
需要鸡蛋就给你下蛋
(3)生成器的惰性机制:生成器只有在访问的时候才取值,说白了你要找他他才会给你值,
不找他,他是不会执行的.
深坑==>生成器,要值的时候才拿值
4.总结:推导式有:列表推导式,字典推导式,集合推导式,没有元祖推导式
(1)生成器表达式:(结果 for 变量 in 可迭代对象 if 条件筛选)
(2)生成器表达式可以直接获取到生成器对象,生成器对象可以直接进行for循环,生成器具有
惰性机制.
5.一个面试题,难度系数:极极极极极极极难:
# 求和
def add(a, b):
return a + b
# 生成器函数 # 0-3
def test():
for r_i in range(4):
yield r_i
# 0,1,2,3
g = test() # 获取生成器
for n in [2, 10]:
g = (add(n, i) for i in g)
print(g) # 生成器:<generator object <genexpr> at 0x0000019284B24FC0>
# 到最后往里面放数据就对了
# 取的是n为10的值,2在运行时没有取值,只是取了一个:(add(n, i) for i in g)公式
# 然后取值时将2的值带入for循环g = (add(n, i) for i in (add(n, i) for i in g))
# n = 10 则原式变为:g = (add(10, i) for i in (add(10, i) for i in g))
# 然后带入生成器g的值:0,1,2,3
print(list(g)) #[20, 21, 22, 23]
print(list(g)) # []
结果:
<generator object <genexpr> at 0x0000024D3B2D4FC0>
[20, 21, 22, 23]
[]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号