is和==的区别以及编码及解码
一.is和 == 的区别
1.is 比较内存地址
id() ---------获取内存地址
1 # a = 'alex'
2 # print(id(a)) # 36942544 内存地址
3
4 # n = 10
5 # print(id(n)) #1408197120
6
7 # li = [1,2,3]
8 # print(id(li)) #38922760
(1)小数据池
数字小数据池的范围: -5~256


# n = 5//2
# n1 = 2
# print(n is n1) #True
# n = -6
# n1 = -6
# print(n is n1) #False
# n = -5
# n1 = -5
# print(n is n1) #True
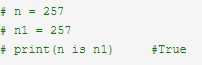
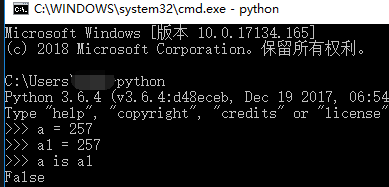
# n = 257
# n1 = 257
# print(n is n1) #True
#列表
# li =[1,2,3]
# li2 =[1,2,3]
# print(li is li2) #False
#元组
# tu =(1,2,3)
# tu1 =(1,2,3)
# print(tu is tu1) # False
#字典
# dic1 = {'name':'alex'}
# dic = {'name':'alex'}
# print(dic1 is dic) #False
因Pycharm修改了规则,所以数据池的范围只能在终端中测出
字符串中如果有特殊字符他们的内存地址就不一样(字符串中不能包含特殊符号 '+,-,*,/,@..等等,但是下划线'_'属于小数据池)
1 # a = 'alex@'
2 # a1 = 'alex@'
3 # print(a is a1) # Fales
字符串中单个*20以内他们的内存地址一样,单个*21以上内存地址不一致
1 # a = 'a'*21
2 # b = 'a'*21
3 # print(a is b)
4
5 # a = 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
6 # b = 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
7 # print(a is b)
黑框 == 终端
注意:
在py文件中. 如果你只是单纯的定义一个字符串.那么一般情况下都是会
被添加到小数据池中的. 我们可以这样认为: 在使用字符串的时候, python会帮我们把字符串
进行缓存, 在下次使用的时候直接指向这个字符串即可. 可以节省很多内存
这个问题千万不要纠结. 因为官⽅方没有给出⼀一个完美的结论和定论.所以只能是⾃自⼰己摸索.
2.== 比较两边的值
1 # a = 'alex'
2 # b = 'alex'
3 # print(a == b) # True
4
5 # n = 10
6 # n1 = 10
7 # print(n == n1) # True
8
9 # li1 = [1,2,3]
10 # li2 = [1,2,3]
11 # print(li1 == li2) # True
二.编码和解码
(1).ASCII 码:
不支持:中文
支持:英文, 数字, 符号
8位(bit) 一个字节(byte)
(2).GBK 码(国标码):
支持:中文, 英文, 数字, 符号, 韩文几日文等部分东亚文字
英文: 16位(bit) 二个字节(byte)
中文: 16位(bit) 二个字节(byte)
(3).Unicode 万国码:
支持:世界上的大部分语言, 数字, 符号
英文: 32位(bit) 四个字节(byte)
中文: 32位(bit) 四个字节(byte)
...
(4),UTF-8 长度可变的万国码,最少用8位(bit)
英文: 8位(bit) 一个字节
中文: 24位(bit) 三个字节
...
Python3中, 程序运行阶段使用的事Unicode显示所有内容
bytes类型
传输和存储都是使用bytes
Pycharm 存储的时候默认是使用UTF-8
encode(编码方式) -----------拿到明文编码后对应的字节
decode(编码方式) -----------将编码后的字节解码成对应的明文
1 # s = 'alex'
2 # print(s.encode('utf-8')) # 编码 encode('utf-8') utf-8 是指定要编码成什么样的编码类型
3 # s1 = s.encode('utf-8')
4 # print(s1.decode('utf-8')) # alex
1 # s = '饿了吗'
2 # s1 = s.encode('utf-8') #b'饿了吗' #b'\xe9\xa5\xbf\xe4\xba\x86\xe5\x90\x97'
3 # print(s1)
4 # print(s.encode('gbk'))
注意用什么进行编码就要用什么进行解码,不然会懵逼
# -*- encoding:utf-8 -*-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号