

dubbo分布式和消息队列
更正一下,rabbitMQ的消息的终点是队列而非交换器,而rocketMQ的终点是topic,因为topic包含队列。
正是dubbo的出现,才让越来越多的公司选择分布式架构。
例如在两台机器上有两个服务A、B,如果A要调用B的某个方法,使用http固然可以,但会比较麻烦,而采用RPC(远程过程调用)就会让你像调用本地方法一样简单,dubbo就是一个轻量级的RPC框架。
讲一下RPC原理。
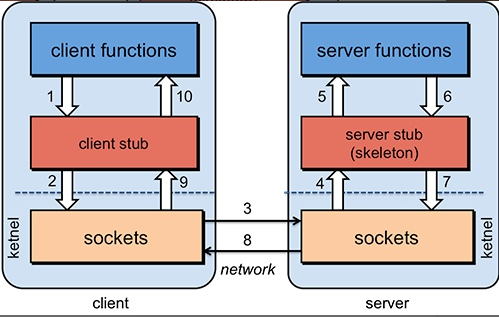
我用调用本地方法的方式调用远程服务。
client stub接收到调用后将参数和方法等组装成能在网络运输的消息体,并发送到服务端。
然后远程服务server stub接收到消息体并解码。
server stub把解码后的数据交给本地方法进行调用,产生结果后将结果进行返回给server stub。
server stub再将结果进行打包返回给client stub,解码后最终到达我这里。
分布式是面向服务的即SOA,我们常见的IE浏览器和服务端之间的通信是基于http的,而FPC能实现真正意义上的分布式,利用client stub和server stub之间传输数据而非http,更快。而且基于FPC的dubbo框架具有服务注册和服务监听功能。每一个服务提供者都要在注册中心注册自己的服务,而服务消费者则从注册中心调用服务,监听是为了监听服务者和消费者调用的次数。注册中心和监听中心都宕机也不影响服务提供者和消费者,它们可以直连。而且消费者可以阅读自己已经缓存的服务列表来和服务提供者取得联系,因此若服务提供者全部宕机,那服务消费者就会一直发送连接请求。另外dubbo也提供了负载均衡的功能,就是说一堆集群的服务都注册时,消费者不会一直消费某一个服务而让其他服务空闲。
其实dubbo就是这么个东西,有一个注册中心,所有的集群服务端都可以在这里注册服务,所有的消费者都来dubbo消费,dubbo根据负载均衡策略来决定让消费者消费哪个服务,同时监听功能监听服务者和消费者调用的次数。这里可以结合zookeeper统一管理集群的配置即每个服务提供者注册watch事件,看到了znode信息变化就都同步改变。
dubbo的应用场景例如现在服务端是一堆机器的集群,dubbo就可以作为它们的头,因为它有注册中心。它能有效管理,因为它有负载均衡策略。zookeeper可作为dubbo的左右手,也可以叫做跑腿的。
消息中间件也叫消息队列,有kafka、rabbitMQ、rocketMQ等。都是基于消息模型的,即生产者、主题、消费者。
rabbitMQ的主题是交换器,即消息的终点。
有四种类型,决定了是否路由消息到队列的规则,fanout散开表示不管路由键和绑定键是否匹配都会将消息路由到所有队列上。direct则是只将消息路由到路由键和绑定键完全匹配的队列上。topic则是将绑定键用一个靠点号分隔并且用*代替零个或多个单词的式子来表示例如sas.*(类似于正则表达式)。
rocketMQ就是把交换器换成了主题,主题里包含多个队列。且每个队列只能被一个消费者消费。
每个消费者可以被一个消费者组也就是消费者集群代替,这样一个挂了其他可以接着上,消息消费过后会产生消费位移,这样一个消费者组就不会消费到同一个消息。
如果生产者把消息送到topic后,topic只将每条消息发送到一个队列,那么这叫集群模式,如果发到所有队列,那叫广播模式。因为一个消费者组只能消费一个队列。其实广播模式和集群模式的选择在topic和队列之间就已经确定了。
broker相当于消息队列服务器,和topic的关系是多对多。broker类似于dubbo即有一个注册中心。
rocket和rabbit的区别就是前者的主题相当于后者的交换机加上队列。
服务端接收到一个请求后,将请求参数等写入 消息中间件,然后返回执行下一次请求(这有点类似js的http异步执行,即当前线程立即返回让下一个线程执行,而自己则异步执行自己的任务),JDK1.8以后,Future实现了真正的异步(以前是阻塞即等当前线程的任务执行完才返回也叫同步),因此我们将队列的声明以及消息的消费放到ExecutorService es=Executors.newFixedThreadPool(7);Future f=es.submit(new CallAble(){...})的...里面,这后面半句话相当于start了线程并且它是异步的即不影响当前线程的结束。f.get()前面有一大段代码也没事。
activeMQ虽然支持五种消息类型(键值对、流、二进制、对象序列、字符串),它是基于JMS(java API)的,支持两种订阅模式(一对一和一对多),但是它的性能最差,不推荐使用。关键是它没有交换机,直接跟队列搞事。
rabbitMQ具有交换器,producer将消息写到交换器,会产生一个路由键。然后服务端的消息队列绑定交换器,会产生一个绑定键,只有当绑定键和路由键匹配的时候消息才会路由到队列,根据绑定键的类型决定是否路由消息到队列里(也就是说根据交换器类型的不同,可能会无视绑定键,从而无脑地必定往队列路由),消息队列是作为容器的也就是消息到了消息队列就算完成了,然后消费者可以消费同一个队列,队列和交换器不一样,交换器可以发散一样同时路由,而队列是一根线只能按序,因此当有多个消费者时,会一部分被a消费者消费,另一部分被b消费者消费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号