
Python学习之字符串和编码
字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。字符串类型是str。
- Python 3版本中,字符串是以Unicode编码的。对于单个字符的编码,python提供
ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符。
x = '中' y = 'A' z = 66 print(ord(x)) print(ord(y)) print(chr(z))
结果如下: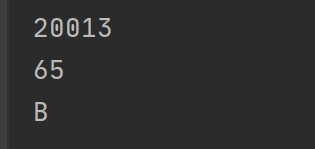
- Python对
bytes类型的数据用带b前缀的单引号或双引号表示: x = b'ABC'。str变为bytes,需要用encode()方法;bytes变为str,需要用decode()方法。
iret1 = "ABC" iret2 = '中文' iret3 = b'ABC' iret4 = b'\xe4\xb8\xad\xe6\x96\x87' print(iret1.encode("ascii")) print(iret2.encode("UTF-8")) print(iret3.decode('ascii')) print(iret4.decode('UTF-8'))
结果如下:

- 要计算str的长度,用len()方法。
字符串格式化
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符:
| 占位符 | 替换内容 |
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x |
十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数。
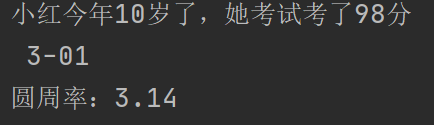
print("小红今年%d岁了,她考试考了%d分"%(10,98)) print('%2d-%02d' % (3, 1)) print("圆周率:%.2f" % 3.1415926)
结果如下:
- format():另一种格式化字符串的方法是使用字符串的
format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,
print('Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125))
结果如下:
- f-string:最后一种格式化字符串的方法是使用以
f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
r = 2.5 s = 3.14 * r ** 2 print(f'The area of a circle with radius {r} is {s:.2f}')
结果如下:

访问字符串的值
Python访问字符串,可以使用方括号[ ]来截取,遵循左闭右开原则,截取格式如下:
变量[头下标 : 尾下标]
实例:
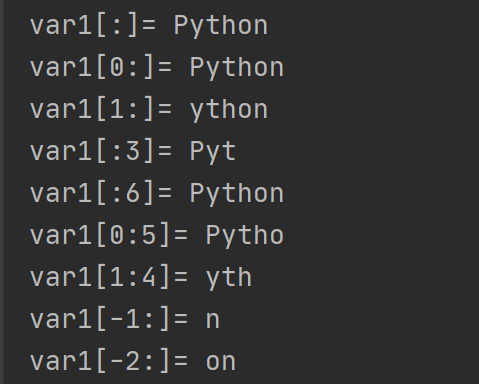
var1 = "Python" # 索引值以 0 为开始值,-1 为从末尾的开始位置。 print("var1[:]=", var1[:]) print("var1[0:]=", var1[0:]) print("var1[1:]=", var1[1:]) print("var1[:3]=", var1[:3]) print("var1[:6]=", var1[:6]) print("var1[0:5]=", var1[0:5]) print("var1[1:4]=", var1[1:4]) print("var1[-1:]=", var1[-1:]) print("var1[-2:]=", var1[-2:])
结果:
字符串运算符

内建函数

实例:
# capitalize() ----将字符串的第一个字符转换为大写 str1 = "where there is a will,there is a way." print("1.str=", str1.capitalize()) # 1.str= Where there is a will,there is a way. # center(width, fillchar) ----返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 str2 = "Python" print("2.str=", str2.center(21, "*")) # 2.str= ********Python******* # count(str, beg= 0,end=len(string))----返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 str3 = "abcdabcdabcdabcdabcdefgefgefg" print("3.字符串adc出现的次数:", str3.count("abc")) # 3.字符串adc出现的次数: 5 print("3.字符串efg出现的次数:", str3.count("efg", 0, 24)) # 3.字符串efg出现的次数: 1 # bytes.decode(encoding="utf-8", errors="strict")----bytes类型变为str类型 # errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', ' str4 = b'\xe4\xb8\xad\xe6\x96\x87' print("4.str=", str4.decode("utf-8", "strict")) # 4.str= 中文 # encode(encoding='UTF-8',errors='strict')----str类型变为bytes类型 str5 = "中文" print("5.str=", str5.encode("utf-8")) # 5.str= b'\xe4\xb8\xad\xe6\x96\x87' # endswith(suffix, beg=0, end=len(string))----检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. str6 = "Knowledge is power!!!" print("6.str6字符串以!!结尾吗?", str6.endswith("!!")) # 6.str6字符串以!!结尾吗? True print("6.str6字符串以r结尾吗?", str6.endswith("r")) # 6.str6字符串以r结尾吗? False # expandtabs(tabsize=8)----把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 str7 = "Knowledge\tis power" print("7.原字符串str7=", str7) # 7.原字符串str7= Knowledge is power print("7.转换后字符串str7=", str7.expandtabs(1)) # 7.转换后字符串str7= Knowledge is power # find(str, beg=0, end=len(string))----检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 str8 = "Knowledge is power!" print("8.i在字符串中的开始位置:", str8.find("i")) # 8.i在字符串中的开始位置: 10 print("8.p在字符串中的开始位置:", str8.find("p", 0, 10)) # 8.p在字符串中的开始位置: -1 # index(str, beg=0, end=len(string))----跟find()方法一样,只不过如果str不在字符串中会报一个异常。 str9 = "i think knowledge is power" print("9.k在字符串中的开始位置:", str9.index("k")) # 9.k在字符串中的开始位置: 6 # isalnum()----如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False str10 = "" str101 = "111aaa" str102 = "中文" # 返回true??? str103 = "www.runoob.com" print("10.0:", str10.isalnum()) # False print("10.1:", str101.isalnum()) # True print("10.2:", str102.isalnum()) # True print("10.3:", str103.isalnum()) # False # isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False str110 = "111aaa" str111 = "111中文" str112 = "aaa中文" str113 = "aaa中文.com" print("11.0:", str110.isalpha()) # False print("11.1:", str111.isalpha()) # alse print("11.2:", str112.isalpha()) # True print("11.3:", str113.isalpha()) # False # isdigit()----如果字符串只包含数字则返回 True 否则返回 False.. str120 = "111" str121 = "111a" print("12.0:", str120.isdigit()) # True print("12.1:", str121.isdigit()) # False # islower()----如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False str130 = "Knowledge IS power" str131 = "knowledge is power" print("13.0:", str130.islower()) # False print("13.1:", str131.islower()) # True # isupper()----如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False str140 = "Knowledge IS power" str141 = "KNOWLESGE IS POWER" print("14.0:", str140.isupper()) # False print("14.1:", str141.isupper()) # True # isnumeric()----如果字符串中只包含数字字符,则返回 True,否则返回 False str150 = "112233" str151 = "111222a" print("15.0:", str150.isnumeric()) # True print("15.1:", str151.isnumeric()) # False # isspace()----如果字符串中只包含空白,则返回 True,否则返回 False. str160 = " " str161 = " a" print("16.0:", str160.isspace()) # True print("16.1:", str161.isspace()) # False # istitle()----如果字符串是标题化的(见 title())则返回 True,否则返回 False。istitle() 方法检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。 str170 = "Knowledge Is Power" str171 = "Knowledge is power" print("17.0:", str170.istitle()) # True print("17.1:", str171.istitle()) # False # join(seq)----以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 str18 = ("p", "y", "t", "o", "n") s1 = "-" s2 = "*" print("18.0:", s1.join(str18)) # 18.0: p-y-t-o-n print("18.1:", s2.join(str18)) # 18.1: p*y*t*o*n # len(string)----返回字符串长度 str19 = "Knowledge Is Power" print("19:", len(str19)) # 19: 18 # ljust(width[, fillchar])----返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 str20 = "python!!!" print("20:", str20.ljust(40, "&")) # 20: python!!!&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&& # rjust(width,[, fillchar])----返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 str21 = "python!!!" print("21:", str21.rjust(40, "&")) # 21: &&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&python!!! # lower()----转换字符串中所有大写字符为小写. str22 = "Knowledge IS Power" print("22:", str22.lower()) # 22: knowledge is power # upper()----转换字符串中的小写字母为大写 str23 = "Knowledge IS Power" print("23:", str23.upper()) # 23: KNOWLEDGE IS POWER # lstrip()----截掉字符串左边的空格或指定字符。 str240 = " Knowledge Is Power" str241 = "666666Knowledge Is Power888888" print("24.0:", str240.lstrip(" ")) # 24.0: Knowledge Is Power print("24.1:", str241.lstrip("6")) # 24.1: Knowledge Is Power888888 # rstrip()----删除字符串末尾的空格或指定字符. str25 = "666666Knowledge Is Power888888" print("25:", str25.rstrip("8")) # 25: 666666Knowledge Is Power # strip([chars])----在字符串上执行 lstrip()和 rstrip() str26 = "******Knowledge Is Power*********" print("26:", str26.strip("*")) # 26: Knowledge Is Power # maketrans()----创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 str270 = "Knowledge Is Power" str271 = "we" str272 = "34" print("27:", str270.translate(str.maketrans(str271, str272))) # 27: Kno3l4dg4 Is Po34r # max(str)----返回字符串 str 中最大的字母。 str28 = "AbcDabcEabc" print("str28字符串最大的字母:", max(str28)) # c # min(str)----返回字符串 str 中最小的字母。 str29 = "AbcDabcEabc" print("str29字符串最小的字母:", min(str28)) # A # replace(old, new [, max])----把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 str30 = "abcabcabcabcabcabcabddefabcabcabcabc" print("30.0:", str30.replace("abc", "123")) # 30.0: 123123123123123123abddef123123123123 print("30.1:", str30.replace("abc", "123", 6)) # 30.1: 123123123123123123abddefabcabcabcabc # rfind(str, beg=0,end=len(string))----类似于 find()函数,不过是从右边开始查找. str31 = "Knowledge Is Power" print("31:字符e从右往左出现的第一个位置:", str31.rfind("e")) # 31:字符e从右往左出现的第一个位置: 16 # print("31:字符z从右往左出现的第一个位置:", str31.rfind("z")) # 报异常 # rindex( str, beg=0, end=len(string))----类似于 index(),不过是从右边开始. str32 = "Knowledge Is Power" print("32:字符w从右往左出现的第一个位置:", str32.rindex("w")) # 32:字符w从右往左出现的第一个位置: 15 # print("32:字符z从右往左出现的第一个位置:", str32.rindex("z")) # 不会报异常,也不会打印任何消息。 # split(str="", num=string.count(str))---- 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 str33 = "Knowledge Is Power!!!we" print("33:", str33.split(" ")) # 33: ['Knowledge', 'Is', 'Power!!!we'] print("33:", str33.split("w")) # 33: ['Kno', 'ledge Is Po', 'er!!!', 'e'] print("33:", str33.split("w", 1)) # 33: ['Kno', 'ledge Is Power!!!we'] # splitlines([keepends])---- 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 str34 = "123\r456\r\n789\n012" print("34.0:", str34.splitlines()) # 34.0: ['123', '456', '789', '012'] print("34.1:", str34.splitlines(True)) # 34.1: ['123\r', '456\r\n', '789\n', '012'] # startswith(substr, beg=0,end=len(string))----检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 str35 = "Knowledge Is Power!" print("字符串str35是以Know开头吗?", str35.startswith("Know")) # True print("字符串str35是以now开头吗?", str35.startswith("now")) # False # swapcase()---- 将字符串中大写转换为小写,小写转换为大写 str36 = "Knowledge IS Power!" print("36:大写变小写,小写变大写:", str36.swapcase()) # 36:大写变小写,小写变大写: kNOWLEDGE is pOWER! # title()----返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) str37 = "knowledge is power!" print("37:", str37.title()) # 37: Knowledge Is Power! # translate(table, deletechars="")----根据 str 给出的表(包含 256 个字符,由maketrans制作)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 # 制作翻译表 bytes_tabtrans = bytes.maketrans(b'abcdefghijklmnopqrstuvwxyz', b'ABCDEFGHIJKLMNOPQRSTUVWXYZ') # 转换为大写,并删除字母o print("38:", b'runoob'.translate(bytes_tabtrans, b'o')) # 38: b'RUNB' # zfill (width)----返回长度为 width 的字符串,原字符串右对齐,前面填充0 str39 = "Knowledge IS Power!" print("39:", str39.zfill(50)) # 39: 0000000000000000000000000000000Knowledge IS Power! # isdecimal() ----检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 str401 = "python12349876" str402 = "12349876" print("40.1:", str401.isdecimal()) # False print("40.2:", str402.isdecimal()) # True
记录学习笔记,有其他参考,如有侵权,联系删除
本文来自博客园,作者:rissa,转载请注明原文链接:https://www.cnblogs.com/rissa/p/14044898.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号