
BERT学习笔记
bert 论文阅读
-
一、模型结构
-
是一个多层的双向transformer encoder
-
注意这里tranformer模型输入的是embedding后的词向量
-
-
二、输入编码
-
可以编码一个单句或一串单句
-
Token Embedding
-
每个词被表示成一个768维的向量 CLS表示开始符号 SEP表示结束符号

这里使用WordPiece tokenization的原因是这种表示方法使Bert只需要存储很少的词汇,并且很少遇到未登陆词
-
-
Segment Embedding
-
用于区分句子的表示 比如哪些单词属于句子1 那些单词属于句子2
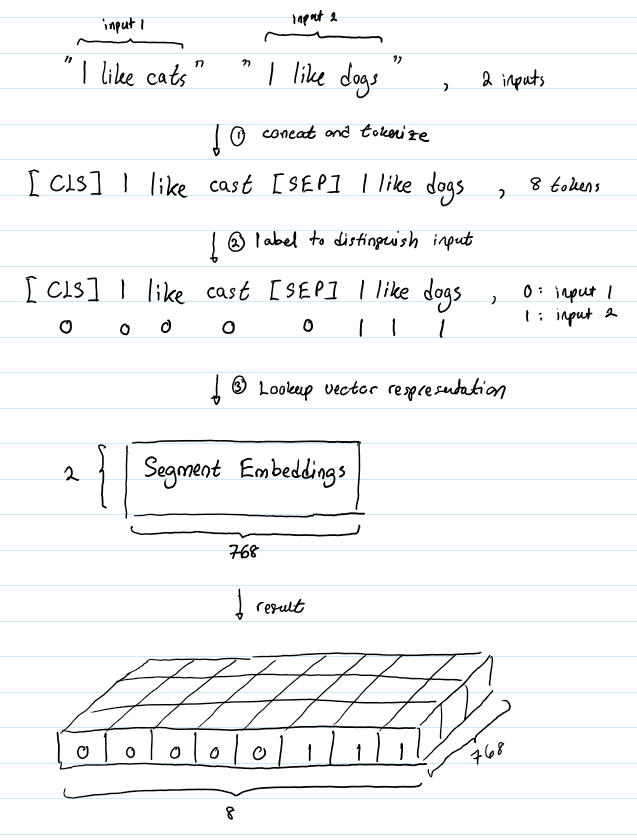
-
-
Position Embedding
-
和transformer中的一样 目的在于区分句子中词的位置关系
I think, therefore I am
第一个I和第二个I应该有不同的向量表示
-
bert中的最大句子长度是512 所以Position Embedding layer 是一个size为(512,768)的lookup table
-
不同句子同样的位置,位置编码是一样的
-
-
联合表示
- 很简单 就是将三部分的represention对应的元素相加 形成一个(1, n, 768)的表示
-
-
三、预训练任务(目标函数)
- 论文不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,使用两个新的无监督预测任务对BERT进行预训练。
- 任务1: Masked LM 遮蔽语言模型
- 只计算mark位置的损失
- 任务2:下一句预测

 浙公网安备 33010602011771号
浙公网安备 33010602011771号