
MySQL 中分区表
MySQL 中的分区表
InnoDB 逻辑存储结构
InnoDB 存储引擎的存储逻辑,所有数据都会被逻辑的保存在一个空间中,这个空间称为 InnoDB(Tablespace) 表空间,本质上是一个或多个磁盘文件组成的虚拟文件系统。InnoDB 表空间不仅仅存储了表和索引,它还保存了回滚日志(redo log)、插入缓冲(insert buffer)、双写缓冲(doublewrite buffer)以及其他内部数据结构。
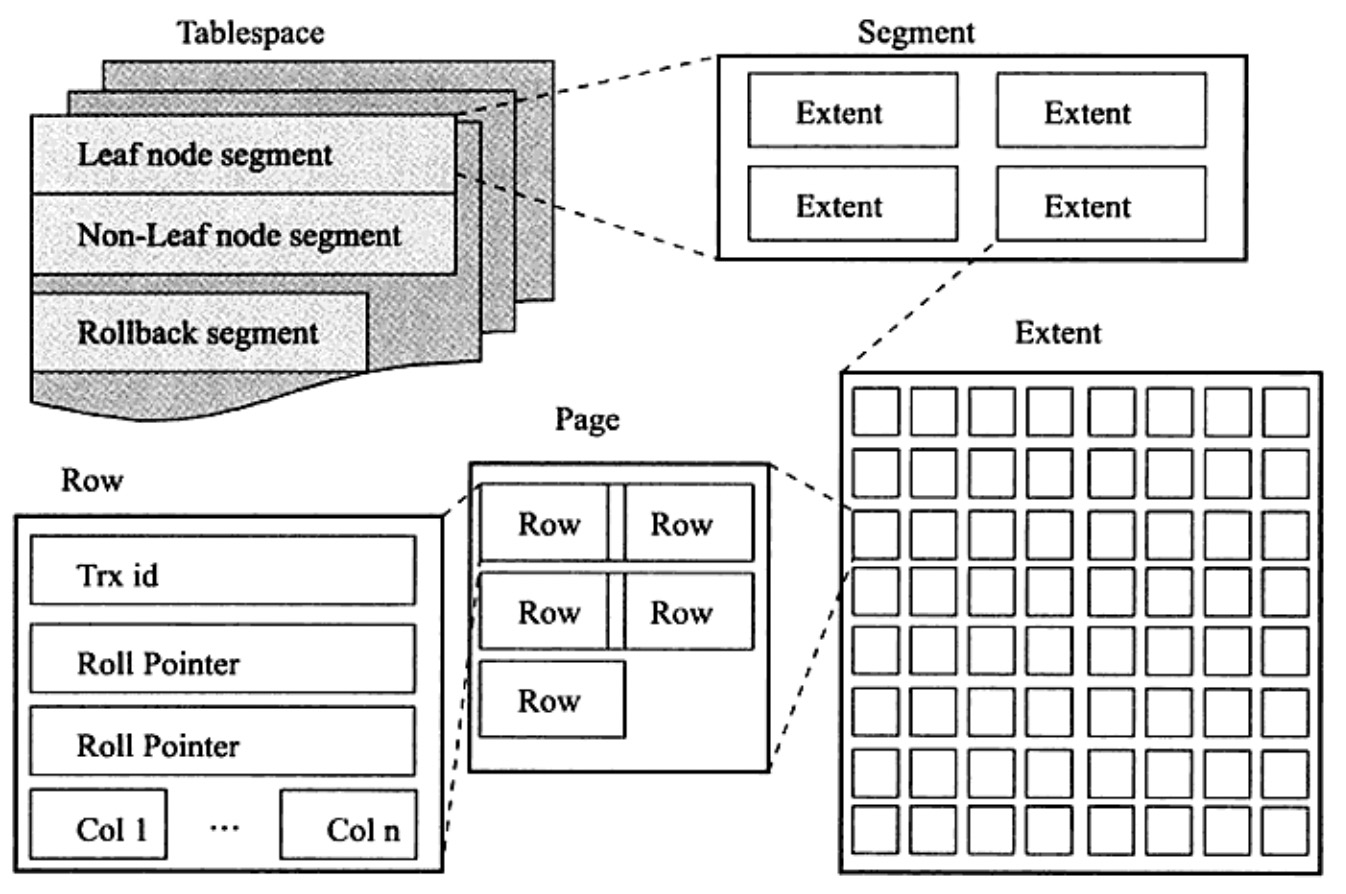
表空间,由段(segment),区(extend),页(page)组层。页在一些文档中也被称为块(block)。
表空间 (Tablespace)
表空间可以看做是 InnoDB 存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
在默认情况下,InnoDB 存储引擎有一个共享的表空间 ibdatal 即所有的数据都存放在这个表空间中。如果用户开启了 innodb_file_per_table,则每张表内的数据都可以单独的存放到一个表空间中。
不过即使开启了 innodb_file_per_table,每张表内的存放的数据只是数据,索引和插入缓存 Bitmap 页,其它类的数据回滚信息,插入缓存页,系统事务信息,二次写缓冲,还是会放在原来的共享表空间中。这也能说明一个问题,及时开始了 innodb_file_per_table,贡献表空间的数据还是会不断的增大。
段 (segment)
表空间是由各个段组层的,常见的段由数据段,索引段,回滚段等。
对于 InnoDB 存储引擎的存储数据存储结构 B+ 树,只有叶子节点存储数据,其它节点存储索引信息。也就是叶子节点存储的是数据段,非叶子节点存储的是索引段。
在 InnoDB 存储引擎中,对段的管理都是由引擎自身所完成的,我们一般不能也没有必要对其进行操作。
区 (extent)
区是由连续页组成的空间,在任何情况下每个区的大小都是 1MB,为了保证区中页的连续性,InnoDB 存储引擎会一次性的从磁盘申请 4~5 个区。在默认情况下,InnoDB 存储引擎的大小为 16KB,即一个区中一共有 64 个连续的页。
InnoDB 1.0.x 版本开始引入了压缩页,每个页的大小可以通过参数 KEY_BLOCK_SIZE 设置为 2K,4K,8K,因此每个区对应的页的数量就应该为 512,256,128。
InnoDB 1.0.x 版本新增加了参数 innodb_page_size ,通过该参数可以将默认页的大小设置为 4k,8k,但是页中的数据库不会压缩,这时候区中页的数量同样是 256,128。不管页的大小怎么变化,区的大小总是1M.
不过需要注意的是,用户启动了参数 innodb_file_per_table 设置了单独的表空间,创建的表默认大小是 96KB。不过一个区中有64个连续的页,创建的表至少是 1MB 才对?
原因是每个段开始时,会先用32个页大小的碎片页来存放数据,在使用完,这些页之后才是64个连续页的申请,这样的目的,对于一些小表,或者 undo 这类的段,可以在开始申请较少的空间,节省磁盘容量的开销。
页 (page)
和大多数的数据库一样,InnoDB 有页 (page) 的概念(也称为块),页是 InnoDB 磁盘管理的最小单位。在 InnoDB 存储引擎中,默认每个页的大小为 16KB。
从 InnoDB 1.2.x 版本开始,可以通过 innodb_page_size 修改页的大小,可以设置为 4k,8k,16k。如果修改完成,所有表中页的大小都是 innodb_page_size,不能对其进行再次修改,除非使用 mysqldump 导入和导出操作产生的新的库。
innoDB存储引擎中,常见的页类型有:
1、数据页(B-tree Node);
2、undo页(undo Log Page);
3、系统页 (System Page);
4、事物数据页 (Transaction System Page);
5、插入缓冲位图页(Insert Buffer Bitmap);
6、插入缓冲空闲列表页(Insert Buffer Free List);
7、未压缩的二进制大对象页(Uncompressed BLOB Page);
6、压缩的二进制大对象页 (compressed BLOB Page)。
行 (row)
InnoDB 存储引擎是按行进行存放的,每个页存放的数据是有硬性要求的,最多允许存放 16KB/2-200,即7992行记录。
InnoDB 数据页结构
页是 InnoDB 存储引擎管理数据库的最小单位,这里我们再来看下 InnoDB 数据页的内部结构。
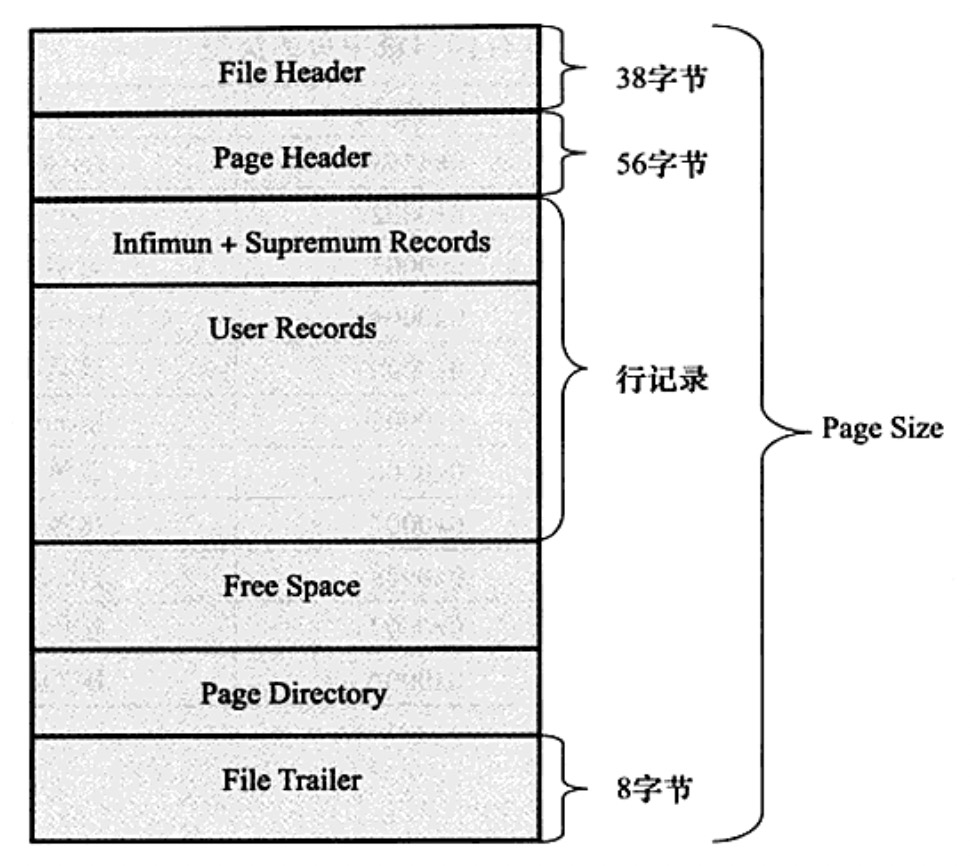
InnoDB 数据页由下面7部分组层
1、File Header (文件头);
2、Page Header (页头);
3、Infimum 和 Supremum Records;
4、User Records(用户记录,机行记录);
5、Free Space (空闲空间);
6、Page Directory(页目录);
7、File Trailer(文件结尾信息)。
其中 File Header,Page Header,File Trailer 用来记录该页一些空间,大小是固定的,分别为38,56,8 字节。
User Records,Free Space,Page Directory 这部分为实际的行记录存储空间,大小是动态的。
1、File Header:用来记录页的一些头部信息;
2、Page Header:用来记录数据页的状态信息;
3、Infimum 和 Supremum Records:在 InnoDB 存引擎中,每个数据页由连个虚拟的行记录,用来限定记录的边界。Infimum 记录的是比页中任何主键都要小的值,Supremum 中记录的是页中最大值的边界。这两个值随着页的创建而创建并且永远都不会被删除。
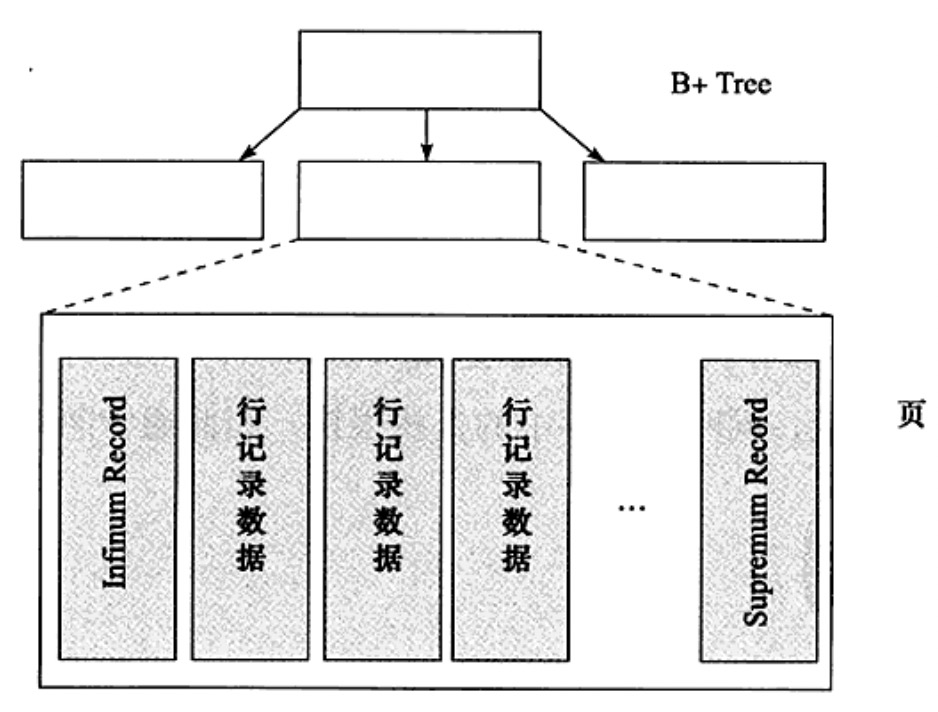
4、User Record 和 Free Space:User Record 存储的是实际的行记录,Free Space 指的就是空闲空间,是个链表数据结构,在一条数据被删除后会加入到空闲链表中。
5、Page Directory:存放是页的相对位置,这里的重点是相对为位置而不是偏移量,有时候也称为这些记录指针为 Slots 或者 Directory Slots。
InnoDB 引擎中的槽是一个稀疏目录,一个槽中可能有多条记录,当记录被插入或删除的时候需要对槽进行分裂或平衡的维护操作。
在 Slots 中记录按照所索引键值顺序存放,这样可以通过二叉查询迅速找到记录的指针。所以 B+ 树索引本省并不能找到具体的一条记录,能找到的只是该记录所在的页。数据把页载入到内存中,然后通过 Page Directory 进行二次查询,二叉查询的结果只是一个粗略的结果。只不过二叉查询的是时间负载度很低,同时在内存中查询很快,因此通常忽略这部分查询所需要的时间。
6、File Trailer:用于检测页是否已经完整当的写入到磁盘中,在默认配置下 InnoDB 引擎每次从磁盘中读取一个页就会检测页的完整性,该部分会有一定的开销,用户可以通过参数 innodb_checksums 来开启或者关闭这个页完整性的检查。
分区别表的概念
分区的过程是将一个表或者索引分为多个更小,更可管理的部分。就访问数据库的应用来说,从逻辑上讲只有一个表或者索引,但是在物理上这个表或者索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
数据库分区和分表相似,都是按照规则分解表。不同在于分表将大表分解若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置了。应用程序读写的时候操作还是表名,DB自动去组织分区的数据。
MySQL 数据库支持的分区类型为水平分区,不支持垂直分区。MySQL 中数据库的分区是局部分区索引,一个分区中即存放了数据又存放了索引。全局分区是指,数据存放在各个分区中,但是所有的数据的索引存放在一个对象中。
MySQL 数据库支持下面几种类型的分区
1、RANGE 分区:行数据基于一个给定连续区间的列值被放入分区。MySQL 5.5 开始支持 RANGE COLUMNS 的分区;
2、LIST 分区:和 RANGE 分区类似,只是 LIST 分区面向的是离散的值。MySQL 5.5 开始支持 LIST COLUMNS 的分区;
3、HASH 分区:根据用户自定义的表达是的返回值来进行分区,返回值不能为负数;
4、KEY 分区:根据 MySQL 数据库提供的哈希函数来进行分区。
分区表的优点
1、可以让单表存储更多的数据;
2、分区表的数据更容易维护,可以通过整个隔断批量删除大量数据,也可以增加新的隔断来支持新插入的数据。此外,还可以优化、检查、修复一个独立分区;
3、有些查询可以从查询条件确定只落在少数区域,速度快;
4、分区表的数据还可以分布在不同的物理设备上,从而高效利用多种硬件设备;
5、可以使用分区表,避免 InnoDB 单索引的反弹访问、ext3 文件系统的 inode 锁定竞争等特殊瓶颈;
6、可备份和恢复单个分区。
缺点
1、一个表最多只能有 1024个分区;
2、如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来;
3、分区表无法使用外键约束;
4、NULL 值会使分区过滤无效;
5、所有分区必须使用相同的存储引擎。
分区类型
下面对几种分区进行一一实践下
1、RANGE 分区
RANGE 是最常用的分区类型,会根据指定的范围进行分区划分,来个栗子实践下
CREATE TABLE `t` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
PARTITION BY RANGE( id ) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20)
);
insert into t values(1),(2),(10),(15);
可以看到,使用 RANGE 分区类型,通过 id 对数据进行了分区处理
p0 分区:id < 10;
p1 分区:10 <= id < 20;
查看分区的数据
$ SELECT * FROM t PARTITION (p0);
+----+
| id |
+----+
| 1 |
| 2 |
$ SELECT * FROM t PARTITION (p1);
+----+
| id |
+----+
| 10 |
| 15 |
+----+
RANGE 分区是对历史数据进行分区的一种方便的方法,RANGE分区用边界定义了表或索引中分区的范围和分区间的顺序。
RANGE 通常用于日期列的分区,使用 RANGE 分区通过时间字段对数据进行分区划分,在查询特定时间段的数据的时候,假定每个分区有一个月的数据,这样查询某个月的数据的时候,可以通过月份直接定位到该分区,这样数据查询扫描就直接缩小到一个分区了。
RANGE 也适用于定期加载新数据和清除旧数据的场景。加入数据会保留一个滚动的数据窗口,将过去一年的数据保持在线。使用 RANGE 分区,只需要在每次添加一个新月份的分区之后,删除最后一个月的分区数据即可。
RANGE 的适用场景:
1、经常在某些列上的按照范围扫描非常大的表,在这些列上对表进行分区可以实现分区查询;
2、希望维护数据的滚动窗口;
3、不能在指定的时间内完成大型表的管理操作,例如备份和恢复,但是可以根据分区范围列将它们划分为更小的逻辑块。
2、LIST 分区
LIST 和 RANGE 分区有点类似,只是分区列是离散的不是连续的,LIST 分区根据数据的枚举值进行分区。
来个栗子,必须根据城市对数据进行分区存储,不同城市的数据存储在不同的分区中。
1、北京;
2、上海;
3、杭州;
4、浙江;
5、洛阳;
6、南宁;
7、郑州;
8、南京;
9、湖州。
CREATE TABLE `t_city` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`city_code` int(11) NOT NULL
) ENGINE=InnoDB
PARTITION BY LIST (`city_code`)
(PARTITION p1 VALUES IN (1, 2, 3),
PARTITION p2 VALUES IN (4, 5, 6),
PARTITION p3 VALUES IN (7, 8, 9)
);
insert into t_city values(1, "小明", 1),(2, "小白", 3),(10, "小红", 5),(15, "小李", 7);
查看分区数据
$ SELECT * FROM t_city PARTITION (p1);
+----+--------+-----------+
| id | name | city_code |
+----+--------+-----------+
| 1 | 小明 | 1 |
| 2 | 小白 | 3 |
+----+--------+-----------+
LIST 分区就是根据枚举值进行分区,每个分区的值都是离散的。只支持整形,非整形字段需要通过函数转换成整形。
在 5.5 版本之后,引入了 LIST COLUMN,可以使用多个列作为分区键,并允许使用非整数类型的数据类型列作为分区列。可以使用字符串类型、DATE 和 DATETIME 列。与使用RANGE COLUMNS进行分区一样,不需要在 COLUMNS() 子句中使用表达式将列值转换为整数。
CREATE TABLE `t_city_v1` (
`id` int(11) NOT NULL,
`name` varchar(32) NOT NULL,
`city` varchar(32) NOT NULL
) ENGINE=InnoDB
PARTITION BY LIST COLUMNS (`city`)
(PARTITION p1 VALUES IN ("北京", "上海", "杭州"),
PARTITION p2 VALUES IN ("浙江", "洛阳", "南宁"),
PARTITION p3 VALUES IN ("郑州", "南京", "湖州")
);
3、HASH 分区
HASH 分区的目的是将数据均匀的分布到预先定义的各个分区中,保证各个分区的数据数据量大致都是一样的。
在 RANGE 分区和 LIST 分区中,必须明确的指定一个给定的列值或列值集合应该保存在哪个分区中,在 HASH 分区中,MySQL 会自动完成这些工作。
使用 HASH 分区的目的如下:
-
1、使分区间数据分布均匀,分区间可以并行访问;
-
2、根据分区键使用分区修剪,基于分区键的等值查询开销减小;
-
3、随机分布数据,以避免I/O瓶颈。
分区键的选择一般要满足以下要求:
-
1、选择唯一或几乎唯一的列或列的组合;
-
2、为每个2的幂次分区创建多个分区和子分区。例如:2、4、8、16、32、64、128等。
来个栗子
CREATE TABLE `t_hash` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY HASH(custkey)
( PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4
);
insert into t_hash values(1, "小明"),(2, "小白"),(10, "小红"),(15, "小李");
查看分区数据
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_hash';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 1 |
| p3 | `custkey` | NULL | 2 |
| p4 | `custkey` | NULL | 1 |
+------+-----------+-------+------------+
指定 HASH 分区的数量将自动生成各个分区的内部名称。
CREATE TABLE `t_hash_1` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY HASH(custkey)
PARTITIONS 8;
查看分区数据
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_hash_1';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p0 | `custkey` | NULL | 0 |
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 0 |
| p3 | `custkey` | NULL | 0 |
| p4 | `custkey` | NULL | 0 |
| p5 | `custkey` | NULL | 0 |
| p6 | `custkey` | NULL | 0 |
| p7 | `custkey` | NULL | 0 |
+------+-----------+-------+------------+
4、KEY 分区
KEY 分区和 HASH 分区类似。不同之处,HASH 使用用户自定义的函数进行分区,KEY 分区使用 MYSQL 数据库提供的函数进行分区。
KEY 分区使用 MySQL 服务器提供的 HASH 函数;KEY 分区支持使用除 blob 和 text 外其他类型的列作为分区键。
KEY 分区有如下几种情况:
1、KEY 分区可以不指定分区键,默认使用主键作为分区键;
2、没有主键时,则选择非空唯一键作为分区键;
3、若无主键又无唯一键,则必须指定分区键,否则报错。
CREATE TABLE `t_key` (
`custkey` int(11) NOT NULL,
`name` varchar(25) NOT NULL,
PRIMARY KEY (`custkey`)
) ENGINE=InnoDB
PARTITION BY KEY(custkey)
PARTITIONS 8;
查看分区数据
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t_key';
+------+-----------+-------+------------+
| part | expr | descr | TABLE_ROWS |
+------+-----------+-------+------------+
| p0 | `custkey` | NULL | 0 |
| p1 | `custkey` | NULL | 0 |
| p2 | `custkey` | NULL | 0 |
| p3 | `custkey` | NULL | 0 |
| p4 | `custkey` | NULL | 0 |
| p5 | `custkey` | NULL | 0 |
| p6 | `custkey` | NULL | 0 |
| p7 | `custkey` | NULL | 0 |
+------+-----------+-------+------------+
子分区
子分区是在分区的基础之上在进行分区,有时也称这种分区为复合分区。MYSQL 从 5.1 开始支持对已经通过 range 和 list 分区的表在进行子分区,子分区可以使用 hash 分区,也可以使用 key 分区。
CREATE TABLE `t_hash_5` (
`id` int(11) NOT NULL,
`purchased` date NOT NULL,
`name` varchar(25) NOT NULL,
KEY `purchased` (`purchased`)
) ENGINE=InnoDB
PARTITION BY RANGE(year(purchased))
SUBPARTITION BY HASH (to_days(purchased))
SUBPARTITIONS 4 (
partition p0 values less than (1990),
partition p1 values less than (2000),
partition p2 values less than (MAXVALUE)
);
上面的栗子,可以看到首先进行了 RANGE 分区,然后又进行了一次 HASH 分区,分区的数量就是 3X4 = 12 个,首先创建了 3 个 RANGE 分区,同时每个 RANGE 分区又创建了 4 个 HASH 子分区,一共就是 12 个分区。
子分区创建有下面几个注意的点
1、每个分区的数量必须相同;
2、要在一个分区表的任何分区上使用 SUBPARTITION 来定义子分区,就需要给所有的分区定义子分区;
3、每个 SUBPARTITION 字句必须包含一个分区的名字;
4、子分区的名字必须是唯一的。
获取 MySQL 分区表的信息
1、show create table 表名,获取创建分区表的时候的创建语句;
show create table t;
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t | CREATE TABLE `t` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
/*!50100 PARTITION BY RANGE ( id)
(PARTITION p0 VALUES LESS THAN (10) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (20) ENGINE = InnoDB) */ |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2、show table status 可以查看表是不是分区表;
show table status;
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
| t | InnoDB | 10 | Dynamic | 4 | 8192 | 32768 | 0 | 0 | 0 | NULL | 2023-06-08 01:43:39 | 2023-06-08 01:43:39 | NULL | utf8mb4_unicode_ci | NULL | partitioned | |
| user | InnoDB | 10 | Dynamic | 2 | 8192 | 16384 | 0 | 0 | 0 | 4 | 2023-06-07 03:15:28 | NULL | NULL | utf8mb4_unicode_ci | NULL | | |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+--------------------+----------+----------------+---------+
2 rows in set (0.01 sec)
Create_options 是 partitioned 就表示是分区表。
3、通过 information_schema.partitions 表,可以查询表具有哪几个分区、分区的方法、分区中数据的记录数等信息;
$ select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='t';
+------+------+-------+------------+
| part | expr | descr | table_rows |
+------+------+-------+------------+
| p0 | id | 10 | 2 |
| p1 | id | 20 | 2 |
+------+------+-------+------------+
4、通过 explain 可以查看查询预计使用的分区;
$ explain select * from t where id=10;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t | p1 | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
可以看到上面的查询使用到了分区 p1。
总结
1、InnoDB 存储引擎的存储逻辑,所有数据都会被逻辑的保存在一个空间中,这个空间称为 InnoDB(Tablespace) 表空间,本质上是一个或多个磁盘文件组成的虚拟文件系统。InnoDB 表空间不仅仅存储了表和索引,它还保存了回滚日志(redo log)、插入缓冲(insert buffer)、双写缓冲(doublewrite buffer)以及其他内部数据结构。
2、表空间,由段(segment),区(extend),页(page)组层。页在一些文档中也被称为块(block)。
3、分区的过程是将一个表或者索引分为多个更小,更可管理的部分。就访问数据库的应用来说,从逻辑上讲只有一个表或者索引,但是在物理上这个表或者索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
4、数据库分区和分表相似,都是按照规则分解表。不同在于分表将大表分解若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置了。应用程序读写的时候操作还是表名,DB自动去组织分区的数据。
5、MySQL 数据库支持下面几种类型的分区
-
1、RANGE 分区:行数据基于一个给定连续区间的列值被放入分区。MySQL 5.5 开始支持
RANGE COLUMNS的分区; -
2、LIST 分区:和 RANGE 分区类似,只是 LIST 分区面向的是离散的值。MySQL 5.5 开始支持
LIST COLUMNS的分区; -
3、HASH 分区:根据用户自定义的表达是的返回值来进行分区,返回值不能为负数;
-
4、KEY 分区:根据 MySQL 数据库提供的哈希函数来进行分区。
参考
【高性能MySQL(第3版)】https://book.douban.com/subject/23008813/
【MySQL 实战 45 讲】https://time.geekbang.org/column/100020801
【MySQL技术内幕】https://book.douban.com/subject/24708143/
【MySQL学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/mysql
【InnoDB 表空间】https://blog.csdn.net/u010647035/article/details/105009979
【何时选择LIST分区】https://help.aliyun.com/document_detail/412383.html?spm=a2c4g.412381.0.0.5bc411405bQXje

 浙公网安备 33010602011771号
浙公网安备 33010602011771号