Kafka 分区机制产生的消息推送和消费逻辑
使用过 Kafka 的同学都知道 Kafka 的消息组织方式是三层结构:主题 - 分区 - 消息。一个主题会有多个分区,每条消息只会保存到该主题下的某一个分区,而不是会在多个分区保存。
为什么 Kafka 要设计分区的概念而不是用主题来承载消息呢?
在 Kafka 中,Topic 是逻辑的概念,Partition 是物理的概念,这个对于用户来说是透明的。Producer 只用注意自己的消息要投递到哪个 Topic,Consumer 则只用关心自己订阅哪个 Topic,消息存储在集群的哪个 broker 他们无需关心。
而实际要关心这个问题的 Kafka 服务端为了性能考虑,假设把一个 Topic 内的消息全部存储到一个 broker 上,那么这个 broker 将会成为集群的性能瓶颈,有朝一日这个 Topic 消息规模大爆发这台机器也会 down 掉。所以把一个 Topic 内的数据分布到整个集群来存储自然成为一个合理的设计方案。Partition 就是水平扩展的一个概念。
现代分布式系统其实也都在应用分区存储的概念,只是不同的分布式系统对分区的叫法不尽相同。比如在 Kafka 中叫分区,在 MongoDB 和 Elasticsearch 中就叫分片 Shard,而在 HBase 中则叫 Region,在 Cassandra 中又被称作 vnode。从表面看起来它们实现原理可能不尽相同,但对底层分区(Partitioning)的整体思想却从未改变。
主题是逻辑上的消息容器,分区是消息的实际承载者。分区的功能还能让业务使用方实现很多有用的功能。下面我们聊聊因为分区机制的产生导致生产者和消费者去匹配分区而产生的配套逻辑,生产者如何将消息推送到对应的分区,消费者如何消费到自己专属的分区是我们这一篇探讨的问题。
生产者推送消息分区逻辑
partition 的概念本身是为了分区存储,那么怎么做到存储的均匀肯定是需要考虑的事情,下面我们从 Producer 发送消息的地方进入看看如何执行分区逻辑。
Kafka v2.4.0 之前的版本实现方式与之后的版本有区别,我们分别来看。先看 v2.4.0之前的版本实现,首先从 KafkaProducer 的 doSend() 方法进去:
/**
* Implementation of asynchronously send a record to a topic.
*/
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// first make sure the metadata for the topic is available
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
......
......
......
//这里就是分区的逻辑
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
......
......
......
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
......
......
......
}
}
上面的代码中 partition(record, serializedKey, serializedValue, cluster)这里调用的就是分区的逻辑:
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
跟进去之后就会进入到 Partitioner 的默认实现类 逻辑当中:
public class DefaultPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
//这里每次进来都会自增1
int nextValue = nextValue(topic);
//获取所有可用的分区
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
//采用取余操作,每次得到的结果肯定是自增的且小于等于可用的 partition 数
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
}
这段代码主要有两个逻辑:
-
当 key 为空的时候(key 就是你为每条消息定义的键),走的是轮询的操作,可以见上面代码注释。
轮询的好处是分配绝对均匀,这种方式要比随机分配的效果更好。
-
当 key 不为空的时候,通过它的 murmur2() hash 算法对 key 进行 hash 计算来分配 Partition 落点。这种方式能保证所有 key 相同的 消息都会落到同一个 Partition 中。
从上面的逻辑看,发送消息最好还是要设置 key。比如当你有一个需求是要保证消费的有序性你会怎么做呢?
这个就可以从 key 的设计上来考虑,如果消息带 key 的话就会分配到同一个 partition 中,一个 partition 最多只能被一个分组内的一个 Consumer 消费,那么这个 partition 内的数据消费肯定就是有序的。
在 Kafka 2.4.0之后,Kafka 对未指定 key 的分区逻辑做了修改,引入了新的粘分区缓存类 StickyPartitionCache,没有 key 时,程序会去缓存中获取分区数:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
//没有key,去粘分区中获取partition
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
//有key,去序列化后的key的hash,模分区数
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
//更新粘分区缓存中的分区数,详情看nextPartition方法。
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
StickyPartitionCache.partition() 实现:
public int partition(String topic, Cluster cluster) {
//缓存中有,直接返回,如果缓存中没有,就用nextPartition方法更新缓存
Integer part = indexCache.get(topic);
if (part == null) {
return nextPartition(topic, cluster, -1);
}
return part;
}
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
//更新缓存,这个逻辑本质上也是轮询,与老版本逻辑类似
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = indexCache.get(topic);
Integer newPart = oldPart;
if (oldPart == null || oldPart == prevPartition) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
//可用分区数小于1,则使用总分区数随机分配分区
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
} else if (availablePartitions.size() == 1) {
//可用分区为1
newPart = availablePartitions.get(0).partition();
} else {
//多个可用分区,随机分配
while (newPart == null || newPart.equals(oldPart)) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
//cache中没有分区数,或者是新的batch时,更新分区数
if (oldPart == null) {
indexCache.putIfAbsent(topic, newPart);
} else {
indexCache.replace(topic, prevPartition, newPart);
}
return indexCache.get(topic);
}
return indexCache.get(topic);
}
StickyPartitionCache 是为了保证不产生过多的小 batch 导致 producer 发送过多的请求。
老版本分区方式,各个消息拥有不同的分区号,会被轮询到每一个分区中,因为发送时一个 batch 中分区号必须相同,这样就会产生很更多的网络请求。而 StickyPartitionCache 保证了没有可以的消息使用相同的分区号,发送时以一个整体发送网络请求到相同的分区中,可以提高 Kafka 的吞吐量。
消费者消费分区逻辑
消费者要消费哪个分区的计算逻辑是在 Consumer 端做的,而不是在 Kafka 的 broker 端。第一个加入到消费群组的 Consumer 被称为该群组的 Coordinator,它的作用就是来协调组员告知谁应该消费哪些 Partition。
知道了消费分区的计算是在 Consumer 端做的之后我们就不难理解为啥能在 Client 的代码中看到分区分配计算逻辑。
Kafka提供了 3 种消费者分区分配策略:RangeAssignor、RoundRobinAssignor、StickyAssignor。我们逐个来了解一下。
RangeAssignor - 范围分配
Kafka 默认采用 RangeAssignor 的分配算法。范围分配器算法逻辑很简单,按照 Topic 的范围,每个 Consumer 会得到计算出的最均衡范围内的 Partition,排在前列的 Consumer 总是拥有最多的 Partition。
public class RangeAssignor extends AbstractPartitionAssignor {
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
//消费者数量
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
//消费者数量
List<String> consumersForTopic = topicEntry.getValue();
//分区数
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
//每个消费者至少要消费的分区个数 = 分区数 / 消费者数量
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// 计算平均分配后多出的分区数 = 分区数 % 消费者数量
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
//计算第i个消费者,分配分区的起始位置
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
//计算第i个消费者,分配到的分区数量
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
}
从上面的算法中可以看到,当 Partition 数量多于 Consumer 数量的时候序号低的 Consumer 会分配更多的 Partition;如果 Consumer 数量大于 Partition 数量的时候超过 Partition 数量的 Consumer 则不会去执行消费。
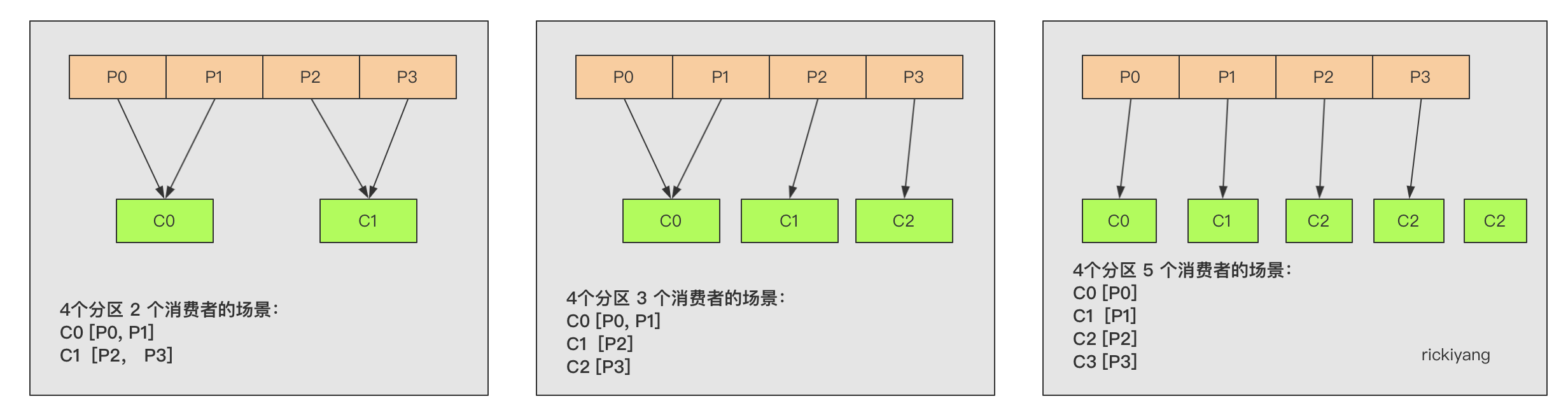
这里还有另一个问题,一个 Topic 的 Partition 数量多于 Consumer 还好,如果这个 Consumer 同时监听了多个 Topic 都有这种情况,且每个 Topic 下该 Consumer 都排在低序号位置,那么它的消费压力将非常的大。
RoundRobinAssignor - 循环路由分配
RoundRobinAssignor 的分配策略是将消费组内订阅的所有 Topic 的分区及所有消费者进行排序后尽量均衡的分配(RangeAssignor 是针对单个 Topic 的分区进行排序分配的)。如果消费组内,消费者订阅的 Topic 列表是相同的(每个消费者都订阅了相同的 Topic),那么分配结果是尽量均衡的(消费者之间分配到的分区数的差值不会超过 1)。如果订阅的 Topic 列表是不同的,那么分配结果是不保证“尽量均衡”的,因为某些消费者不参与一些 Topic 的分配。
public class RoundRobinAssignor extends AbstractPartitionAssignor {
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
//存放所有的 consumer
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet()));
//所有的consumer订阅的所有的TopicPartition的List
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)){
final String topic = partition.topic();
// 如果当前这个assigner(consumer)没有订阅这个topic,直接跳过
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
//跳出循环,表示终于找到了订阅过这个TopicPartition对应的topic的assigner
//将这个partition分派给对应的assigner
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
}
RoundRobinAssignor 的分配策略更像是顺序分配:
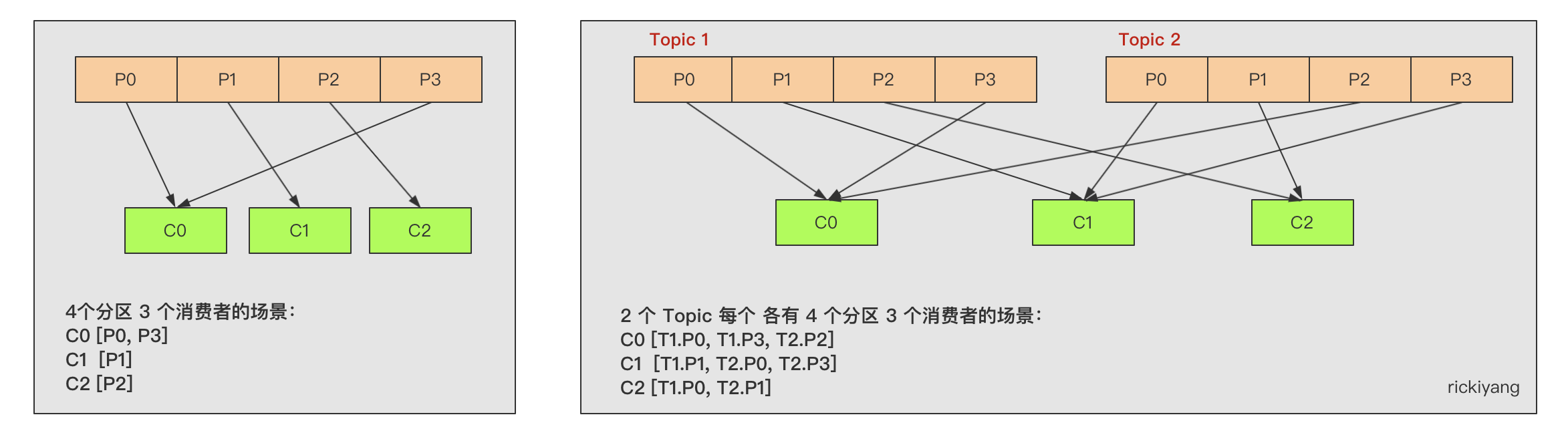
StickyAssignor - 粘性分配
StickyAssignor 分区分配算法能在上一次分配的结果的基础上尽量少的调整分区分配的变动,节省因分区分配变化带来的开销。Sticky 可以理解为分配结果是带 “粘性的”——每一次分配变更相对上一次分配做最少的变动。
出现这个算法的意图不难推测:一旦 Partition 和 Conusmer 数量确定之后大概率是很久都不会有什么变化的,RoundRobinAssignor 算法基本已经平摊 Partition 给 Consumer,那么后面就没有必要再让这个过程重新来一遍,能有一个分配记忆功能肯定是最好不过。所以 StickyAssignor 的目标有两点:
- 分区的分配尽量的均衡。
- 每一次重分配的结果尽量与上一次分配结果保持一致。
当这两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出 StickyAssignor 特性的。
StickyAssignor 为了实现上述目的,代码逻辑相当复杂,我们一起来看一下:
public class StickyAssignor extends AbstractPartitionAssignor {
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
//当前分配状态列表
Map<String, List<TopicPartition>> currentAssignment = new HashMap<>();
partitionMovements = new PartitionMovements();
//补全currentAssignment,将不属于currentAssignment的Consumer添加进去(如果新增了一个Consumer,这个Consumer上一次是没参与分配的,新添加进去分配的Partition列表为空)
prepopulateCurrentAssignments(subscriptions, currentAssignment);
boolean isFreshAssignment = currentAssignment.isEmpty();
//记录着每个Partition可以分配给哪些Consumer
final Map<TopicPartition, List<String>> partition2AllPotentialConsumers = new HashMap<>();
// 记录着每个Consumer可以分配的Partition列表
final Map<String, List<TopicPartition>> consumer2AllPotentialPartitions = new HashMap<>();
// initialize partition2AllPotentialConsumers and consumer2AllPotentialPartitions in the following two for loops
for (Entry<String, Integer> entry: partitionsPerTopic.entrySet()) {
for (int i = 0; i < entry.getValue(); ++i)
partition2AllPotentialConsumers.put(new TopicPartition(entry.getKey(), i), new ArrayList<String>());
}
for (Entry<String, Subscription> entry: subscriptions.entrySet()) {
String consumer = entry.getKey();
consumer2AllPotentialPartitions.put(consumer, new ArrayList<TopicPartition>());
for (String topic: entry.getValue().topics()) {
for (int i = 0; i < partitionsPerTopic.get(topic); ++i) {
TopicPartition topicPartition = new TopicPartition(topic, i);
consumer2AllPotentialPartitions.get(consumer).add(topicPartition);
partition2AllPotentialConsumers.get(topicPartition).add(consumer);
}
}
// add this consumer to currentAssignment (with an empty topic partition assignment) if it does not already exist
if (!currentAssignment.containsKey(consumer))
currentAssignment.put(consumer, new ArrayList<TopicPartition>());
}
// currentPartitionConsumer记录了当前每个Partition分配给了哪个Consumer——就是把currentAssignment从Consumer作为Key转换到Partition作为Key用于辅助分配
Map<TopicPartition, String> currentPartitionConsumer = new HashMap<>();
for (Map.Entry<String, List<TopicPartition>> entry: currentAssignment.entrySet())
for (TopicPartition topicPartition: entry.getValue())
currentPartitionConsumer.put(topicPartition, entry.getKey());
//这里对所有的分区进行排序
List<TopicPartition> sortedPartitions = sortPartitions(
currentAssignment, isFreshAssignment, partition2AllPotentialConsumers, consumer2AllPotentialPartitions);
//记录所有要被分配的分区,上面已排序的分区存入这里
List<TopicPartition> unassignedPartitions = new ArrayList<>(sortedPartitions);
for (Iterator<Map.Entry<String, List<TopicPartition>>> it = currentAssignment.entrySet().iterator(); it.hasNext();) {
Map.Entry<String, List<TopicPartition>> entry = it.next();
if (!subscriptions.containsKey(entry.getKey())) {
//如果这个消费者之前就已经存在了,那么就把它从当前待分配分区中移除
for (TopicPartition topicPartition: entry.getValue())
currentPartitionConsumer.remove(topicPartition);
it.remove();
} else {
for (Iterator<TopicPartition> partitionIter = entry.getValue().iterator(); partitionIter.hasNext();) {
TopicPartition partition = partitionIter.next();
if (!partition2AllPotentialConsumers.containsKey(partition)) {
//如果这个消费者之前消费的分区不存在也将它移除
partitionIter.remove();
currentPartitionConsumer.remove(partition);
} else if (!subscriptions.get(entry.getKey()).topics().contains(partition.topic())) {
// 如果该分区不能保持分配给其当前使用者,则是因为该使用者不再订阅其主题,
//将其从使用者的currentAssignment中删除
partitionIter.remove();
} else
unassignedPartitions.remove(partition);
}
}
}
// 至此,我们已经将所有有效的主题分区保留给消费者分配,并删除了
//所有无效的主题分区和无效的使用者。现在我们需要分配 unassignedPartitions
//分配给使用者,以便主题分区分配尽可能平衡。
//根据已经分配了多少个主题分区的升序排序的使用者集合
TreeSet<String> sortedCurrentSubscriptions = new TreeSet<>(new SubscriptionComparator(currentAssignment));
sortedCurrentSubscriptions.addAll(currentAssignment.keySet());
//下面开始分配操作
balance(currentAssignment, sortedPartitions, unassignedPartitions, sortedCurrentSubscriptions,
consumer2AllPotentialPartitions, partition2AllPotentialConsumers, currentPartitionConsumer);
return currentAssignment;
}
}
上述核心代码中有几个对象我们先说一下:
| 变量 | 说明 |
|---|---|
| Map<String, List |
用来存储当前分配状态的列表。如果 currentAssignment 为空,则是初次分配。 |
| Map<TopicPartition, List |
记录每个 Partition 可以分配给哪些 Consumer |
| Map<String, List |
记录着每个 Consumer 可以分配的 Partition 列表 |
| Map<TopicPartition, String> currentPartitionConsumer | 记录了当前每个 Partition 分配给了哪个 Consumer,把 currentAssignment 从 Consumer 作为 Key 转换到 Partition 作为 Key 用于辅助分配。 |
| List |
记录所有需要分配的分区。 |
这几个对象都是用于后续的分配数据的辅助结构。
说完这几个对象我们接着说函数整体的执行流程:
-
首先 prepopulateCurrentAssignments(subscriptions, currentAssignment); 这里会补全currentAssignment,将不属于 currentAssignment 的 Consumer 添加进去(如果新增了一个 Consumer,这个 Consumer 上一次是没参与分配的,新添加进去分配的 Partition 列表为空)。
-
下面的 for 循环会继续去填充上面提到的 partition2AllPotentialConsumers 和 consumer2AllPotentialPartitions 这两个辅助结构。
-
下面有个 sortPartitions() 方法对所有分区进行排序,排序的规则有两种:
如果不是初次分配且每个 Consumer 订阅是相同的,那么:
- 对 Consumer 按照它所分配的 Partition 数进行排序;
- 按照上一步的排序结果将每个 Consumer 分配的分区插入到 sortedPartitions 数组中;
- 将不属于任何 Consumer 的分区也加入到 sortedPartitions 中。
如果是初次分配:
将 Partition 按照 partition2AllPotentialConsumers 从低到高的顺序分配,将这些 Partition 插入 sortedPartitions。
-
遍历 currentAssignment,将已经分配了的 Partition 从 sortedPartitions 中移除,剩下的就是需要分配的 Partition,记为 unassignedPartitions。
-
接着就对分区进行调整,来达到分配平衡的目的,重点关注 balance() 函数:
- 将上一步 unassignedPartitions 中保存的未分配的分区分配出去,分配的策略是:按照当前的分配结果,每一次分配时将分区分配给订阅了对应 Topic 的 Consumer 列表中拥有的分区最少的那一个 Consumer;
- 校验每一个分区是否需要调整,如果分区不需要调整,则从 sortedPartitions 中移除。分区是否可以被调整的规则是:这个分区在 partition2AllPotentialConsumers 中多于一个 Consumer,即这个分区可以被超过一个 Consumer 消费。
- 校验每个 Consumer 是否需要调整被分配的分区,如果不能调整,则将这个 Consumer 从 sortedCurrentSubscriptions 中移除,不参与后续的重分配。判断是否调整的规则是:如果当前 Consumer 分配的分区数少于它可以被分配的最大分区数(即 consumer2AllPotentialPartitions 的大小),或者它的分区满足上一条规则即它分配的 Partition 被多于一个 Consumer 消费。
- 将以上步骤中获取的可以进行重分配的分区进行重新的分配。每次分配时都进行校验,如果当前已经达到了均衡的状态,则终止调整。均衡状态的判断依据是 Consumer 之间分配的分区数量的差值不超过 1;或者所有 Consumer 已经拿到了它可以被分配的分区之后仍无法达到均衡的上一个条件。如果不满足上面两个条件,且一个 Consumer 所分配的分区数少于同一个 Topic 的其他订阅者分配到的所有分区的情况,那么还可以继续调整,属于不满足均衡的情况。
- 后面的流程就跟普通的分配差不多,最终会将本次分配的结果保存到私有对象 PartitionMovements 中。
看一下下面这个再分配的示例:
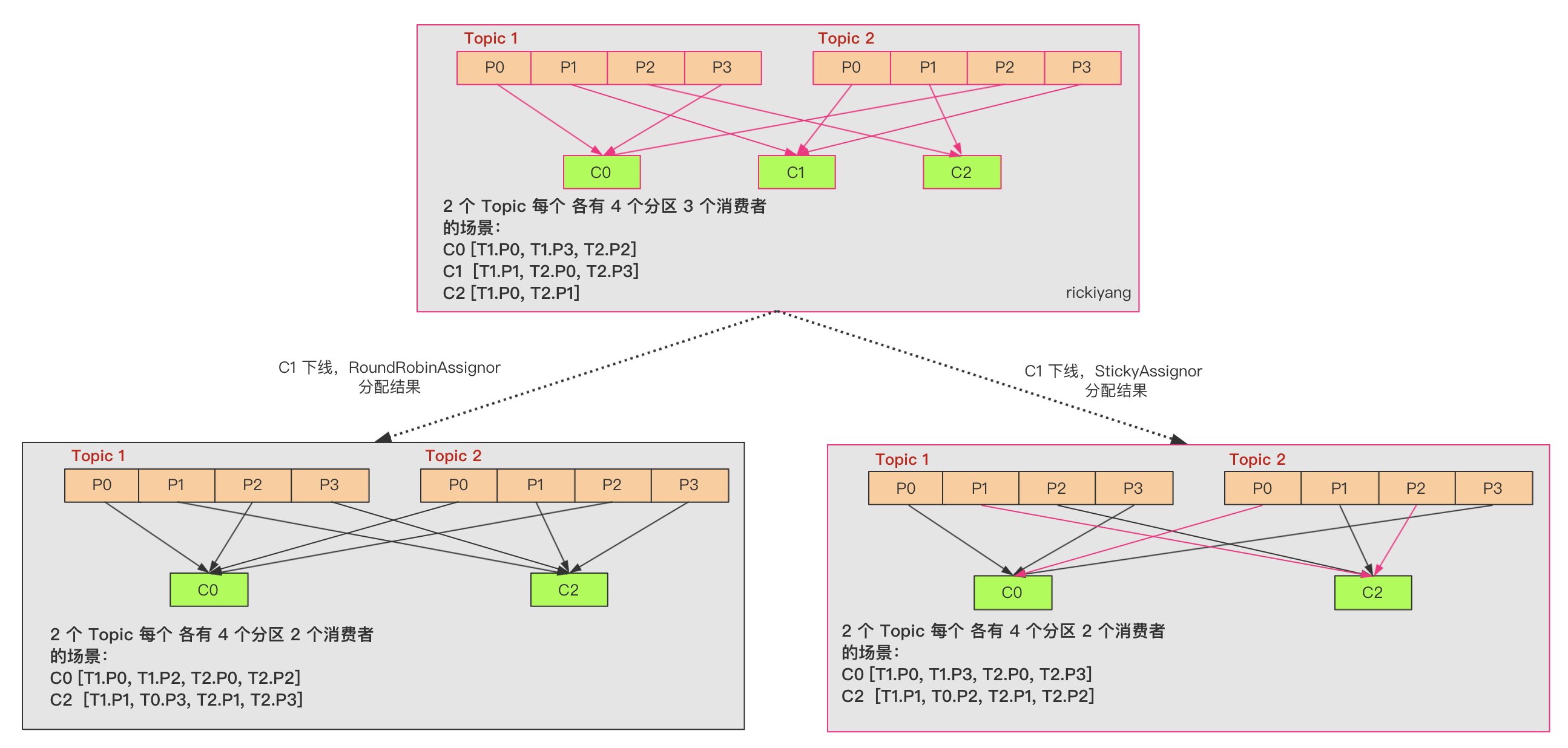
上面这个案例列举了 C1 这个 Consumer 下线之后 RoundRobinAssignor 和 StickyAssignor 两种算法rebalance 之后的区别。可以看到 RoundRobinAssignor 就是全部做了一次再分配;StickyAssignor 算法则有很大的区别,C0 和 C2 之前分配的 Partition 没动过,C1 之前分配到的 Partition 按照新的算法规则分配给C0 和 C2,再分配之前 C2 只分配到 2 个分区,所以优先分配给 C2。
总结
本篇从算法的角度概述了分区机制产生后生产者如何将消息投放到对应的分区,消费者如何消费到属于自己的分区而不至于重复消费。关于消费端分配分区涉及到新增消费者和减少消费者产生的 rabalance,这也是很重要的一个部分,限于篇幅可以后面再起一篇详述。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号