

RabbitMQ在秒杀场景中的简单应用
转载
https://www.cnblogs.com/hello-/articles/10345026.html
一、秒杀:全过程
1、秒杀业务为什么难做?
1)im系统,例如qq或者微博,每个人都读自己的数据(好友列表、群列表、个人信息);
2)微博系统,每个人读你关注的人的数据,一个人读多个人的数据;
3)秒杀系统,库存只有一份,所有人会在集中的时间读和写这些数据,多个人读一个数据。
例如:小米手机每周二的秒杀,可能手机只有1万部,但瞬时进入的流量可能是几百几千万。
又例如:12306抢票,票是有限的,库存一份,瞬时流量非常多,都读相同的库存。读写冲突,锁非常严重,这是秒杀业务难的地方。那我们怎么优化秒杀业务的架构呢?
2、优化方向
优化方向有两个(今天就讲这两个点):
(1)将请求尽量拦截在系统上游(不要让锁冲突落到数据库上去)。传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小。以12306为例,一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0。
(2)充分利用缓存,秒杀买票,这是一个典型的读多写少的应用场景,大部分请求是车次查询,票查询,下单和支付才是写请求。一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%,非常适合使用缓存来优化。好,后续讲讲怎么个“将请求尽量拦截在系统上游”法,以及怎么个“缓存”法,讲讲细节。
3、常见秒杀架构
常见的站点架构基本是这样的(绝对不画忽悠类的架构图)
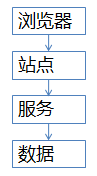
(1)浏览器端,最上层,会执行到一些JS代码
(2)站点层,这一层会访问后端数据,拼html页面返回给浏览器
(3)服务层,向上游屏蔽底层数据细节,提供数据访问
(4)数据层,最终的库存是存在这里的,mysql是一个典型(当然还有会缓存)
这个图虽然简单,但能形象的说明大流量高并发的秒杀业务架构,大家要记得这一张图。后面细细解析各个层级怎么优化。
4、各层次优化细节
第一层,客户端怎么优化(浏览器层,APP层)
问大家一个问题,大家都玩过微信的摇一摇抢红包对吧,每次摇一摇,就会往后端发送请求么?回顾我们下单抢票的场景,点击了“查询”按钮之后,系统那个卡呀,进度条涨的慢呀,作为用户,我会不自觉的再去点击“查询”,对么?继续点,继续点,点点点。。。有用么?平白无故的增加了系统负载,一个用户点5次,80%的请求是这么多出来的,怎么整?
(a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(b)JS层面,限制用户在x秒之内只能提交一次请求;
APP层面,可以做类似的事情,虽然你疯狂的在摇微信,其实x秒才向后端发起一次请求。这就是所谓的“将请求尽量拦截在系统上游”,越上游越好,浏览器层,APP层就给拦住,这样就能挡住80%+的请求,这种办法只能拦住普通用户(但99%的用户是普通用户)对于群内的高端程序员是拦不住的。firebug一抓包,http长啥样都知道,js是万万拦不住程序员写for循环,调用http接口的,这部分请求怎么处理?
第二层,站点层面的请求拦截
怎么拦截?怎么防止程序员写for循环调用,有去重依据么?ip?cookie-id?…想复杂了,这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,甚至不需要统一存储计数,直接站点层内存存储(这样计数会不准,但最简单)。一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。
5s只透过一个请求,其余的请求怎么办?缓存,页面缓存,同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面。同一个item的查询,例如车次,做页面缓存,x秒内到达站点层的请求,均返回同一页面。如此限流,既能保证用户有良好的用户体验(没有返回404)又能保证系统的健壮性(利用页面缓存,把请求拦截在站点层了)。
页面缓存不一定要保证所有站点返回一致的页面,直接放在每个站点的内存也是可以的。优点是简单,坏处是http请求落到不同的站点,返回的车票数据可能不一样,这是站点层的请求拦截与缓存优化。
好,这个方式拦住了写for循环发http请求的程序员,有些高端程序员(黑客)控制了10w个肉鸡,手里有10w个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照uid限流拦不住了。
第三层 服务层来拦截(反正就是不要让请求落到数据库上去)
服务层怎么拦截?大哥,我是服务层,我清楚的知道小米只有1万部手机,我清楚的知道一列火车只有2000张车票,我透10w个请求去数据库有什么意义呢?没错,请求队列!
对于写请求,做请求队列,每次只透有限的写请求去数据层(下订单,支付这样的写业务)
1w部手机,只透1w个下单请求去db
3k张火车票,只透3k个下单请求去db
如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”。
对于读请求,怎么优化?cache抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的。如此限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了。
当然,还有业务规则上的一些优化。回想12306所做的,分时分段售票,原来统一10点卖票,现在8点,8点半,9点,...每隔半个小时放出一批:将流量摊匀。
其次,数据粒度的优化:你去购票,对于余票查询这个业务,票剩了58张,还是26张,你真的关注么,其实我们只关心有票和无票?流量大的时候,做一个粗粒度的“有票”“无票”缓存即可。
第三,一些业务逻辑的异步:例如下单业务与 支付业务的分离。这些优化都是结合 业务 来的,我之前分享过一个观点“一切脱离业务的架构设计都是耍流氓”架构的优化也要针对业务。
第四层 最后是数据库层
浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。db基本就没什么压力了,闲庭信步,单机也能扛得住,还是那句话,库存是有限的,小米的产能有限,透这么多请求来数据库没有意义。
全部透到数据库,100w个下单,0个成功,请求有效率0%。透3k个到数据,全部成功,请求有效率100%。
5、总结
上文应该描述的非常清楚了,没什么总结了,对于秒杀系统,再次重复下我个人经验的两个架构优化思路:
(1)尽量将请求拦截在系统上游(越上游越好);
(2)读多写少的常用多使用缓存(缓存抗读压力);
浏览器和APP:做限速
站点层:按照uid做限速,做页面缓存
服务层:按照业务做写请求队列控制流量,做数据缓存
数据层:闲庭信步
并且:结合业务做优化
6、Q&A
问题1、按你的架构,其实压力最大的反而是站点层,假设真实有效的请求数有1000万,不太可能限制请求连接数吧,那么这部分的压力怎么处理?
答:每秒钟的并发可能没有1kw,假设有1kw,解决方案2个:
(1)站点层是可以通过加机器扩容的,最不济1k台机器来呗。
(2)如果机器不够,抛弃请求,抛弃50%(50%直接返回稍后再试),原则是要保护系统,不能让所有用户都失败。
问题2、“控制了10w个肉鸡,手里有10w个uid,同时发请求” 这个问题怎么解决哈?
答:上面说了,服务层写请求队列控制
问题3:限制访问频次的缓存,是否也可以用于搜索?例如A用户搜索了“手机”,B用户搜索“手机”,优先使用A搜索后生成的缓存页面?
答:这个是可以的,这个方法也经常用在“动态”运营活动页,例如短时间推送4kw用户app-push运营活动,做页面缓存。
问题4:如果队列处理失败,如何处理?肉鸡把队列被撑爆了怎么办?
答:处理失败返回下单失败,让用户再试。队列成本很低,爆了很难吧。最坏的情况下,缓存了若干请求之后,后续请求都直接返回“无票”(队列里已经有100w请求了,都等着,再接受请求也没有意义了)
问题5:站点层过滤的话,是把uid请求数单独保存到各个站点的内存中么?如果是这样的话,怎么处理多台服务器集群经过负载均衡器将相同用户的响应分布到不同服务器的情况呢?还是说将站点层的过滤放到负载均衡前?
答:可以放在内存,这样的话看似一台服务器限制了5s一个请求,全局来说(假设有10台机器),其实是限制了5s 10个请求,解决办法:
1)加大限制(这是建议的方案,最简单)
2)在nginx层做7层均衡,让一个uid的请求尽量落到同一个机器上
问题6:服务层过滤的话,队列是服务层统一的一个队列?还是每个提供服务的服务器各一个队列?如果是统一的一个队列的话,需不需要在各个服务器提交的请求入队列前进行锁控制?
答:可以不用统一一个队列,这样的话每个服务透过更少量的请求(总票数/服务个数),这样简单。统一一个队列又复杂了。
问题7:秒杀之后的支付完成,以及未支付取消占位,如何对剩余库存做及时的控制更新?
答:数据库里一个状态,未支付。如果超过时间,例如45分钟,库存会重新会恢复(大家熟知的“回仓”),给我们抢票的启示是,开动秒杀后,45分钟之后再试试看,说不定又有票哟~
问题8:不同的用户浏览同一个商品 落在不同的缓存实例显示的库存完全不一样 请问老师怎么做缓存数据一致或者是允许脏读?
答:目前的架构设计,请求落到不同的站点上,数据可能不一致(页面缓存不一样),这个业务场景能接受。但数据库层面真实数据是没问题的。
问题9:就算处于业务把优化考虑“3k张火车票,只透3k个下单请求去db”那这3K个订单就不会发生拥堵了吗?
答:(1)数据库抗3k个写请求还是ok的;(2)可以数据拆分;(3)如果3k扛不住,服务层可以控制透过去的并发数量,根据压测情况来吧,3k只是举例;
问题10;如果在站点层或者服务层处理后台失败的话,需不需要考虑对这批处理失败的请求做重放?还是就直接丢弃?
答:别重放了,返回用户查询失败或者下单失败吧,架构设计原则之一是“fail fast”。
问题11.对于大型系统的秒杀,比如12306,同时进行的秒杀活动很多,如何分流?
答:垂直拆分
问题12、额外又想到一个问题。这套流程做成同步还是异步的?如果是同步的话,应该还存在会有响应反馈慢的情况。但如果是异步的话,如何控制能够将响应结果返回正确的请求方?
答:用户层面肯定是同步的(用户的http请求是夯住的),服务层面可以同步可以异步。
问题13、秒杀群提问:减库存是在那个阶段减呢?如果是下单锁库存的话,大量恶意用户下单锁库存而不支付如何处理呢?
答:数据库层面写请求量很低,还好,下单不支付,等时间过完再“回仓”,之前提过了。
二、秒杀全过程
业务介绍

什么是秒杀?通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动比如说京东秒杀,就是一种定时定量秒杀,在规定的时间内,无论商品是否秒杀完毕,该场次的秒杀活动都会结束。这种秒杀,对时间不是特别严格,只要下手快点,秒中的概率还是比较大的。
淘宝以前就做过一元抢购,一般都是限量 1 件商品,同时价格低到「令人发齿」,这种秒杀一般都在开始时间 1 到 3 秒内就已经抢光了,参与这个秒杀一般都是看运气的,不必太强求
务特点

同时并发量大
秒杀时会有大量用户在同一时间进行抢购,瞬时并发访问量突增 10 倍,甚至 100 倍以上都有。
库存量少
一般秒杀活动商品量很少,这就导致了只有极少量用户能成功购买到。
业务简单
流程比较简单,一般都是下订单、扣库存、支付订单
技术难点

有业务的冲击
秒杀是营销活动中的一种,如果和其他营销活动应用部署在同一服务器上,肯定会对现有其他活动造成冲击,极端情况下可能导致整个电商系统服务宕机
直接下订单
下单页面是一个正常的 URL 地址,需要控制在秒杀开始前,不能下订单,只能浏览对应活动商品的信息。简单来说,需要 Disable 订单按钮
页面流量突增
秒杀活动开始前后,会有很多用户请求对应商品页面,会造成后台服务器的流量突增,同时对应的网络带宽增加,需要控制商品页面的流量不会对后台服务器、DB、Redis 等组件的造成过大的压力
架构设计思想

限流
由于活动库存量一般都是很少,对应的只有少部分用户才能秒杀成功。所以我们需要限制大部分用户流量,只准少量用户流量进入后端服务器
削峰
秒杀开始的那一瞬间,会有大量用户冲击进来,所以在开始时候会有一个瞬间流量峰值。如何把瞬间的流量峰值变得更平缓,是能否成功设计好秒杀系统的关键因素。实现流量削峰填谷,一般的采用缓存和 MQ 中间件来解决
异步
秒杀其实可以当做高并发系统来处理,在这个时候,可以考虑从业务上做兼容,将同步的业务,设计成异步处理的任务,提高网站的整体可用性
缓存
秒杀系统的瓶颈主要体现在下订单、扣减库存流程中。在这些流程中主要用到 OLTP 的数据库,类似 MySQL、SQLServer、Oracle。由于数据库底层采用 B+ 树的储存结构,对应我们随机写入与读取的效率,相对较低。如果我们把部分业务逻辑迁移到内存的缓存或者 Redis 中,会极大的提高并发效率
整体架构
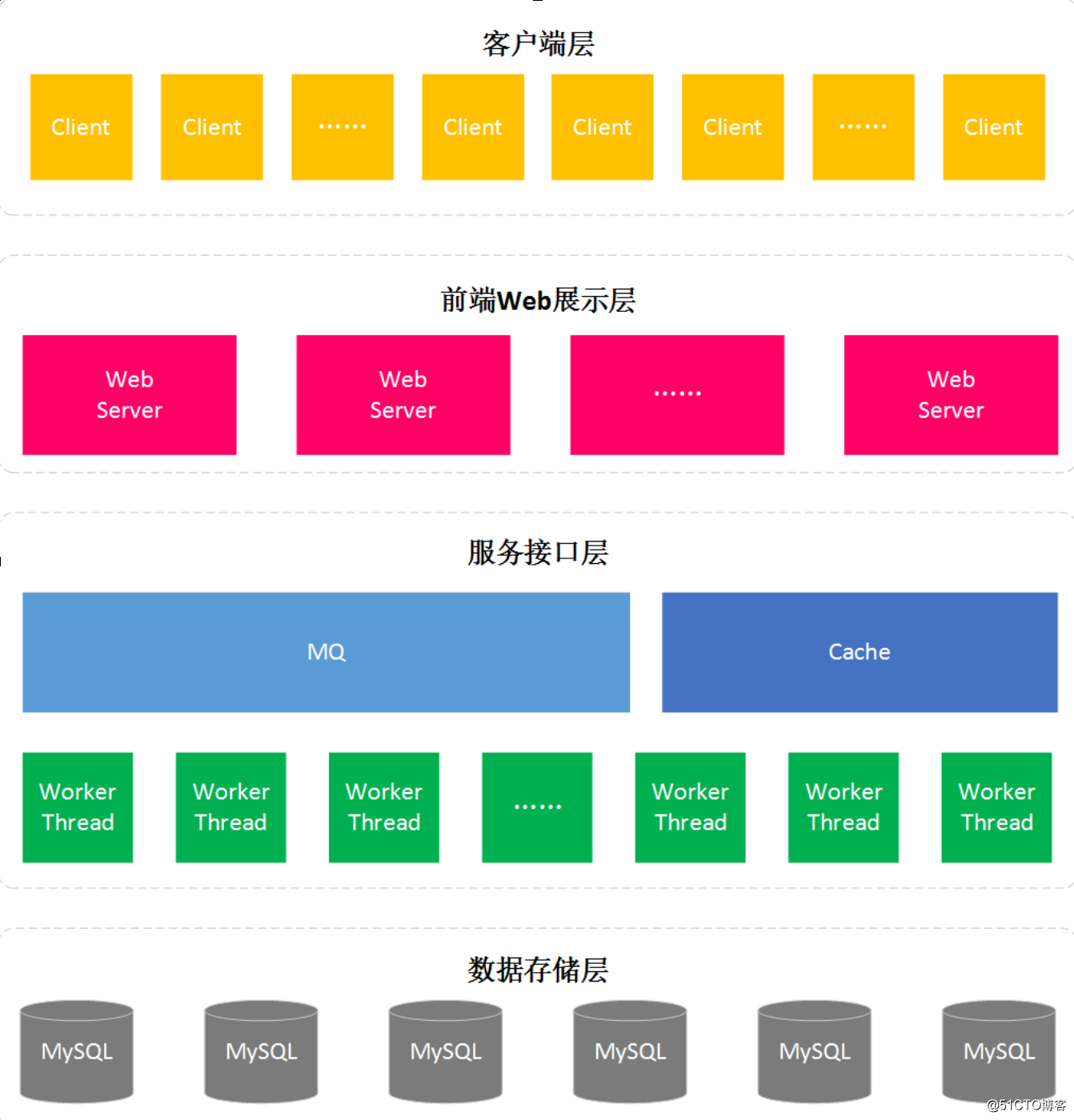
客户端优化
客户端优化主要有两个问题
秒杀页面
秒杀活动开始前,其实就有很多用户访问该页面了。如果这个页面的一些资源,比如 CSS、JS、图片、商品详情等,都访问后端服务器,甚至 DB 的话,服务肯定会出现不可用的情况。所以一般我们会把这个页面整体进行静态化,并将页面静态化之后的页面分发到 CDN 边缘节点上,起到压力分散的作用
防止提前下单
防止提前下单主要是在静态化页面中加入一个 JS 文件引用,该 JS 文件包含活动是否开始的标记以及开始时的动态下单页面的 URL 参数。同时,这个 JS 文件是不会被 CDN 系统缓存的,会一直请求后端服务的,所以这个 JS 文件一定要很小。当活动快开始的时候(比如提前),通过后台接口修改这个 JS 文件使之生效
API 接入层优化
客户端优化,对于不是搞计算机方面的用户还是可以防止住的。但是稍有一定网络基础的用户就起不到作用了,因此服务端也需要加些对应控制,不能信任客户端的任何操作。一般控制分为 2 大类
限制用户维度访问频率
针对同一个用户( Userid 维度),做页面级别缓存,单元时间内的请求,统一走缓存,返回同一个页面
限制商品维度访问频率
大量请求同时间段查询同一个商品时,可以做页面级别缓存,不管下回是谁来访问,只要是这个页面就直接返回
SOA 服务层优化
上面两层只能限制异常用户访问,如果秒杀活动运营的比较好,很多用户都参加了,就会造成系统压力过大甚至宕机,因此需要后端流量控制
对于后端系统的控制可以通过消息队列、异步处理、提高并发等方式解决。对于超过系统水位线的请求,直接采取 「Fail-Fast」原则,拒绝掉
秒杀整体流程图
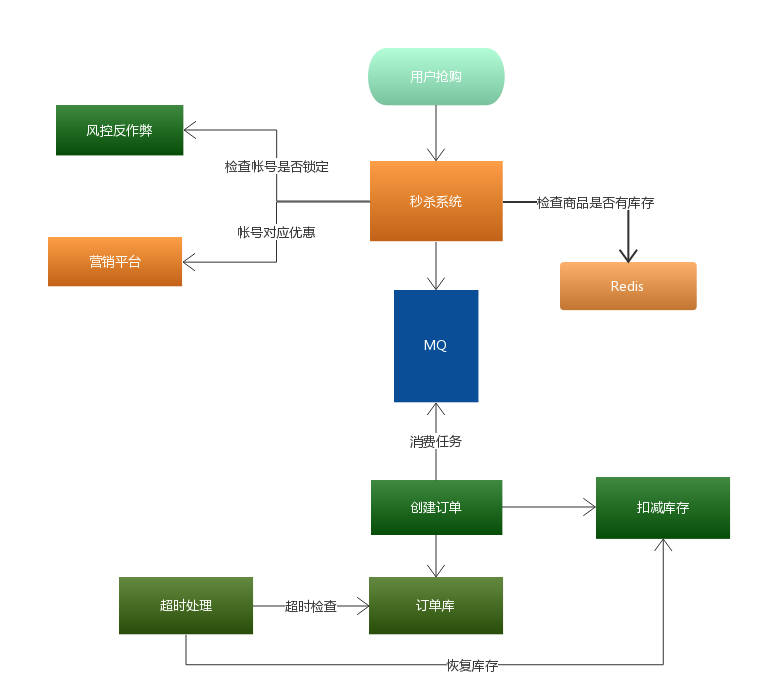
秒杀系统核心在于层层过滤,逐渐递减瞬时访问压力,减少最终对数据库的冲击。通过上面流程图就会发现压力最大的地方在哪里?
MQ 排队服务,只要 MQ 排队服务顶住,后面下订单与扣减库存的压力都是自己能控制的,根据数据库的压力,可以定制化创建订单消费者的数量,避免出现消费者数据量过多,导致数据库压力过大或者直接宕机。
库存服务专门为秒杀的商品提供库存管理,实现提前锁定库存,避免超卖的现象。同时,通过超时处理任务发现已抢到商品,但未付款的订单,并在规定付款时间后,处理这些订单,将恢复订单商品对应的库存量
总结
核心思想:层层过滤
- 尽量将请求拦截在上游,降低下游的压力
- 充分利用缓存与消息队列,提高请求处理速度以及削峰填谷的作用
三、秒杀服务层和后端,示例1:rabbitMQ队列
秒杀业务的核心是库存处理,用户购买成功后会进行减库存操作,并记录购买明细。
当秒杀开始时,大量用户同时发起请求,这是一个并行操作,多条更新库存数量的SQL语句会同时竞争秒杀商品所处数据库表里的那行数据,导致库存的减少数量与购买明细的增加数量不一致,因此,我们使用RabbitMQ进行削峰限流并且将请求数据串行处理。
首先我先设计了两张表,一张是秒杀库存表,另一张是秒杀成功表。

CREATE TABLE seckill (
seckill_id BIGINT NOT NULL AUTO_INCREMENT COMMENT '商品库存id',
name VARCHAR (120) NOT NULL COMMENT '商品名称',
number INT NOT NULL COMMENT '库存数量',
initial_price BIGINT NOT NULL COMMENT '原价',
seckill_price BIGINT NOT NULL COMMENT '秒杀价',
sell_point VARCHAR (500) NOT NULL COMMENT '卖点',
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '秒杀创建时间',
start_time TIMESTAMP NOT NULL COMMENT '秒杀开始时间',
end_time TIMESTAMP NOT NULL COMMENT '秒杀结束时间',
PRIMARY KEY (seckill_id)
);
ALTER TABLE seckill COMMENT '秒杀库存表'; CREATE INDEX idx_create_time ON seckill (create_time); CREATE INDEX idx_start_time ON seckill (start_time); CREATE INDEX idx_end_time ON seckill (end_time);
CREATE TABLE success_killed (
success_id BIGINT NOT NULL AUTO_INCREMENT COMMENT '秒杀成功id',
seckill_id BIGINT NOT NULL COMMENT '秒杀商品id',
user_phone BIGINT NOT NULL COMMENT '用户手机号',
state TINYINT NOT NULL DEFAULT - 1 COMMENT '状态标志:-1:无效;0:成功',
create_time TIMESTAMP NOT NULL COMMENT '秒杀成功创建时间',
PRIMARY KEY (success_id)
);
ALTER TABLE success_killed COMMENT '秒杀成功表'; CREATE INDEX idx_create_time ON success_killed (create_time);
接下来我开始模拟用户请求,往RabbitMQ中发送100个手机号。
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare("task_seckill")
def request_goods(seckill_id, user_phone):
for i in range(100):
set_goods(seckill_id, user_phone)
def set_goods(seckill_id, user_phone):
goods = "%s-%s" % (seckill_id, user_phone)
channel.basic_publish(exchange='',
routing_key='task_seckill',
properties=pika.BasicProperties(
delivery_mode=2
),
body=goods)
然后我用RabbitMQ监听seckill_queue队列,当队列中接收到消息就会自动触发RabbitMQService类中的executeSeckill方法,消息将作为方法的参数传递进来执行秒杀操作。
class RabbitMQService:
def __init__(self):
url = "mysql+pymysql://root:123456@192.168.10.1:3306/lb4?charset=utf8"
from sqlalchemy import create_engine
engine = create_engine(url)
self.con = engine.connect()
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
self.channel.queue_declare("task_seckill")
self.channel.basic_consume(self.execute_seckill,
queue='task_seckill')
def execute_seckill(self, ch, method, pros, body):
good_list = body.split("-")
if not good_list:
return
seckill_id, user_phone = good_list
if not seckill_id:
return
seckill_id = int(seckill_id)
with self.con.begin():
good_number = self.con.execute("select number from seckill where seckill_id=%s", (seckill_id)).fetchone()["number"]
if good_number <= 0:
return
lastid = self.con.execute("update seckill set number=number-1 where seckill_id=%s", (seckill_id)).lastid
if lastid:
self.con.execute("insert into success_killed........")
def start_consuming(self):
self.channel.start_consuming()
RabbitMQService().start_consuming()
在前端页面使用倒计时插件增强用户体验效果。
四、秒杀服务层之redis示例
# redis命令:
# exists key: 判断key是否存在---如果返回key说明存在,否则不存在。
# 递增和递减都是原子操作:
# incr key: 每次递增1.如果key不存在,则创建value为0的key
# decr key: 每次递减1.如果key不存在,则创建value为0的key
# incrby key increment: 每次增加increment。如果key不存在,则创建value为0的key
# decrby key increment: 每次减少increment。如果key不存在,则创建value为0的key
import logging
from logging import handlers
import redis
from flask import Flask
app = Flask(__name__)
# 定义logger:
rf_handler = handlers.TimedRotatingFileHandler('redis.log',
when='midnight',
interval=1,
backupCount=7)
format = "%(asctime)s %(filename)s line:%(lineno)d [%(levelname)s] %(message)s"
rf_handler.setFormatter(logging.Formatter(format))
logging.getLogger().setLevel(logging.INFO)
logging.getLogger().addHandler(rf_handler)
# 连接redis
pool = redis.ConnectionPool(host="localhost",
port=6379,
decode_response=True)
rs = redis.Redis(connection_pool=pool)
def limit_handler():
# return: True: 允许; False: 拒绝
amount_limit = 100 # 限制数量
key_name = 'xxx_goods_limit' # redis key name
incr_amount = 1 # 每次增加数量
# 判断key是否存在
if not rs.exists(key_name):
# setnx是原子性的,允许并发操作
rs.setnx(key_name, 100)
# 数据插入后再判断是否大于限制数
if rs.incrby(key_name, incr_amount) <= amount_limit:
return True
return False
@app.route("/limit")
def v2():
if limit_handler():
logging.info("successful")
else:
logging.info("failed")
return 'limit'
if __name__ == '__main__':
app.run(debug=True)
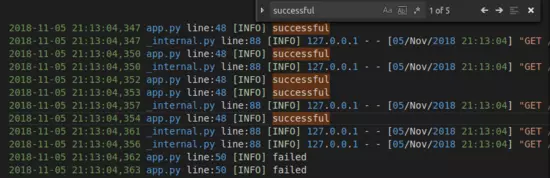
简单测试,安装工具: sudo apt install apache2-utils
测试命令:ab -c 100 -n 200 http://127.0.0.1:5000/limit
# -c表示并发数, -n表示请求数
测试结果:通过日志可以看到最多只有5个successful
部署测试方案:
supervisor + gunicorn + gevent
1).安装依赖:
- apt-get install supervisor
- pip install gevent
- pip install gunicorn
2).生成配置:
echo_supervisord_conf > supervisord.conf
3).修改配置, 在supervisord.conf最后添加
[program:redis-limit] directory = /home/dong/projects/py ;程序的启动目录 command = gunicorn -k gevent -w 4 -b 0.0.0.0:5000 app:app ; 启动命令, 使用gevent, 开启4个进程 autostart = true ; 在 supervisord 启动的时候也自动启动 startsecs = 5 ; 启动 5 秒后没有异常退出,就当作已经正常启动了 autorestart = true ; 程序异常退出后自动重启 startretries = 3 ; 启动失败自动重试次数,默认是 3 redirect_stderr = true ; 把 stderr 重定向到 stdout,默认 false stdout_logfile_maxbytes = 20MB ; stdout 日志文件大小,默认 50MB stdout_logfile_backups = 20 ; stdout 日志文件备份数 stdout_logfile = /home/dong/projects/py/limit_stdout.log
4).启动supervisor服务
supervisord -c ./supervisord.conf
5).查看supervisor应用
# 如果没有启动可以手动start redis-limit
supervisorctl -c ./supervisord.conf
6).测试
ab -c 100 -n 200 http://127.0.0.1:5000/limit
五、秒杀服务层和后端,示例2:RabbitMQ+Redis集群+Quartz实现简单高并发秒杀
花了两天时间实现了一个使用rabbitMQ队列和redis集群存取数据以及使用Quartz触发添加秒杀商品。
这一块小功能很早就想做的,自从自学了redis的命令,发现了expire能够设置自动消亡的时候,我就已经开始蠢蠢欲动了,接着在接触rabbitMQ工作模式(多个消费者争抢数据)的时候,我已经下决心要实现秒杀了。
上个项目是9月底和朋友做完的,一个高并发分布式的项目,开6台centOS虚拟机搭建nginx、主从服务器、redis集群,rabbitMQ队列,amoeba实现读写分离和主从数据库,以及Solr搜索。这个项目是用来练手linux与分布式的,大多数精力都花在搭环境上了,基本步骤也都能百度到,不想写到博客。正好这个秒杀的功能不多不少,思路还有点意思,所以写一下与大家分享。
秒杀的设计理念:
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。前台页面控制
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件(RabbitMQ)等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。(RabbitMQ实现)
内存缓存:秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
第一次尝试:
纯粹使用一台redis实现秒杀,是有同步安全问题的
因为redis是支持高并发的,一秒可以承受10000次的请求,所以暂且使用一台redis试试效果,毕竟单台redis是单线程,并发安全问题会少一点。
首先创建秒杀商品表,这只是简单的一个Demo,只需要id, title, price, num, KillTime 五个属性,分别指代商品id,商品标题,商品价格,秒杀商品的数量,以及秒杀开始的时间。
这个我是模仿淘宝的整点抢购,每一个小时扫描一次秒杀商品表,将商品按抢购时间发布出来,将id作为key,num作为value写入redis,并设置消亡时间为1s(为了测试方便设了5秒)。
当用户点击抢购按钮,首先在前端进行控制,如果时间还没到整点前后两分钟的区间,直接在前端拦截(没写),else才发送请求,使用ajax与restful方式发送请求的url,根据接收的参数,反馈不一样的信息。
后台收到请求之后,首先根据id从redis中get对应的num,如果为null,返回”notbegin”,判断num>0则decr自减,返回true,否则返回finished,如果catch到了错误,返回false。
前端function:
<script type="text/javascript">
function startKill(btn) {
var id = $(btn).attr("id");
$.ajax({
type : "GET",
url : "${app}/SecKill/startKill/" + id,
dataType : 'text',
success : function(data) {
if (data == "true") {
alert("恭喜,抢购成功");
} else if (data == "notbegin") {
alert("活动还没开始哦!");
} else if (data == "finished") {
alert("商品已经抢完");
} else {
alert("抱歉,抢购失败");
}
}
});
}
function tick(){
var today = new Date();
var timeString = today.toLocaleString();
$(".clock").innerHTML = timeString;
window.setTimeout("tick();", 100);
}
window.onload = tick;
服务与后端代java码略。
参考:
https://blog.csdn.net/mydistance/article/details/85236513
https://blog.csdn.net/a724888/article/details/81038138
https://blog.csdn.net/G626316/article/details/78650508
https://blog.csdn.net/sijg16/article/details/79144406

 浙公网安备 33010602011771号
浙公网安备 33010602011771号