[Hive][COUNT] 使用count后出现null问题排查
[Hive][COUNT] 使用count后出现null问题排查
问题概述
使用hive进行用户频次类数据分组提取时,最终的结果出现了全部为null的记录,同时也有全为0的记录,分析原因
v1HQL逻辑
with sup_tab as(
取出用户所用行为记录
)
select 用户id, count( 条件1 ) as cnt_1, count( 条件2 ) as cnt_2 ,...
from sup_tab
where 时间窗口限制
group by 用户标识
v1存在问题
由于HQL的select后的字段只能是统计字段,以及分组字段,即只能出现count,sum,avg等聚合函数和group by 字段之后的分组字段,所以,若想要使得用户id(非用户标识)出现在最终的表中,所以我采用了以下逻辑
v2HQL逻辑
with sup_tab as(
取出用户所用行为记录
)
select 用户id, count( 条件1 ) as cnt_1, count( 条件2 ) as cnt_2 ,...
from (
用户基本信息
from sup_tab
) id
left join
(
统计量
from sup_tab
where 时间窗口限制
group by 用户标识
) cnt
on id.用户标识 = cnt.用户标识
为什么不使用用户id进行分组统计
因为用户id字段存在空值和非法值
问题分析
首先明确三点
- A left join B B中若无A的条目,则全部填充为NULL
- COUNT(NULL) = 0
- select COUNT from where 是对满足了where后的数据进行操作
问题出在统计频次时,使用了时间窗口进行过滤,这导致一些用户的行为全部被过滤掉,所以在最终统计过程中没有这个人,在left join过程中出现了NULL填充现象
解决方法
方案一:使用 inner join 代替 left join
好处:直接去除没有数据的用户,不会出现全NULL的用户了
坏处:需要shuffle操作,这导致HQL执行速度down
方案二:不使用id表,直接从cnt表中获得用户id
v1方法: 将用户id加在group by 后
是否有潜在风险?
首先明确以下两点逻辑
- HQL会根据group by后面的字段进行分组统计 如果有ABC三个字段,如果A中有a个不重复字段,B中有b个不重复字段,C中有c个不重复字段,在不考虑where过滤的情况下,那么最终会出现abc个数据记录
- 想输出用户id时,一个用户标识字段中对应一个用户id(可能是空值或非法值,但同一个用户标识字段内,对应的用户id都相同,是空值时均为空值,是非法值时均为非法值)
所以使用v1方法,理论上是存在风险的,但是实际在操作过程中,是可以规避风险的
好处:回避join导致的shuffle
坏处,group by 后字段数量增加,效率可能降低? (这一点是我有所顾虑的,没有去实践)
v2方法,使用collect_set(字段)[0]方法
collect_set(字段)可以将数据记录,然后返回一个去重后的列表,常用做列转行数据,如果不想对数据进行去重,那么使用collect_list(字段)即可,只需要取这个去重列表的第0个数据就可以达到获得用户ID的目的,根据v1方法的分析,在使用collect_set进行突破group by限制时,其中只会有一个数据,如果有一个以上时,说明一个用户识别字段对应多个用户ID,需要进行排查。
写在最后
由于公司数据需要保密,所以基本上只能描述问题和思路,具体问题不能直观贴出来,SQL的相关逻辑还是要多进行测试,但直接拿大数据表来测试逻辑又不合适,我并没有学习过MySQL这种SQL类编程,所以,找了一个在线练习的网站,希望有相同问题的朋友可以在一些在线网站测试一些简单逻辑,就不用装SQL到个人PC上了。
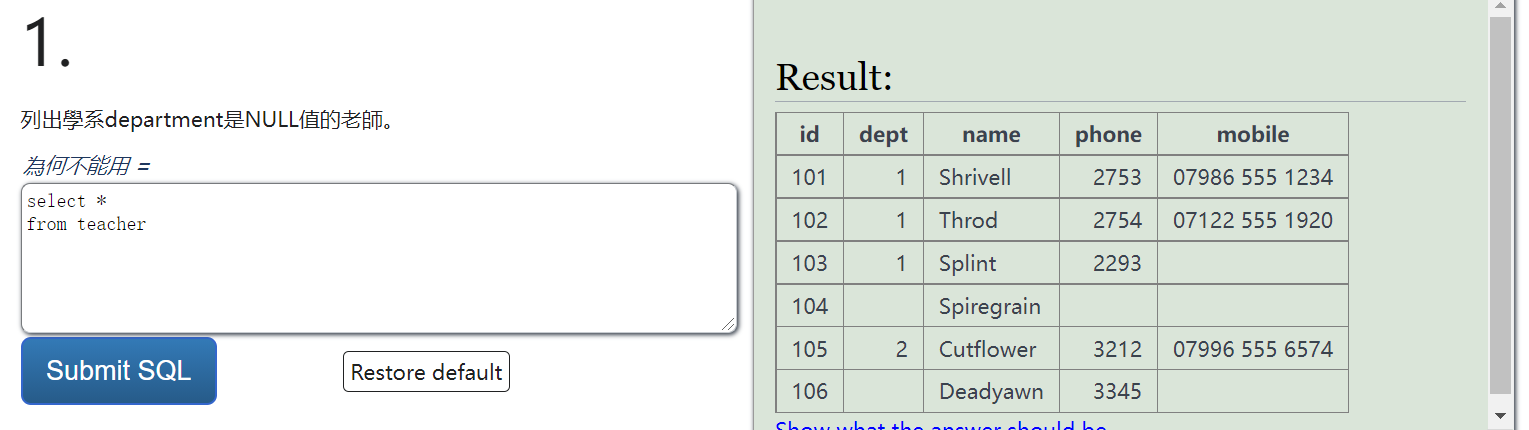
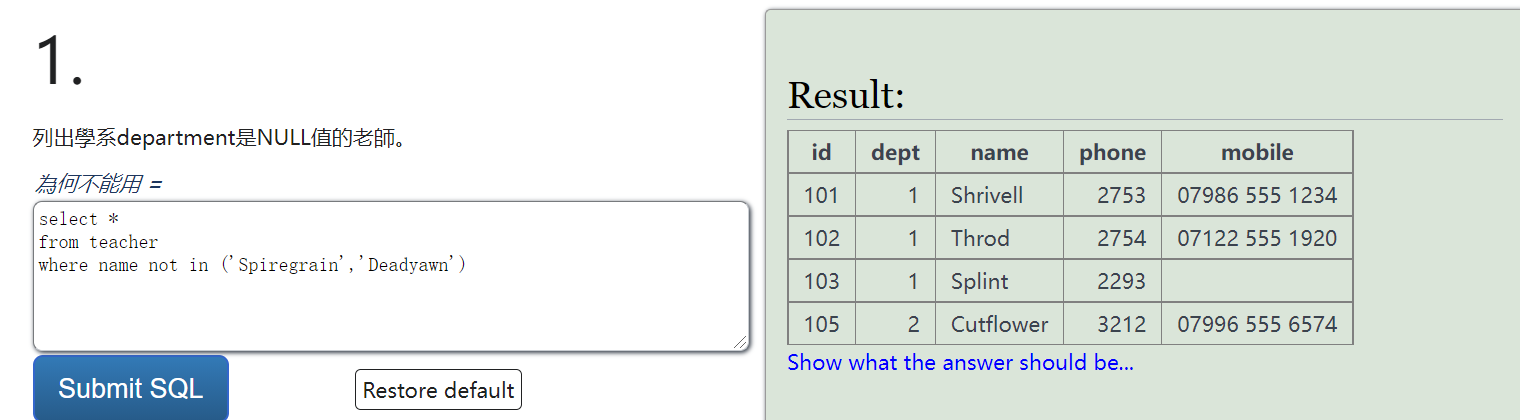
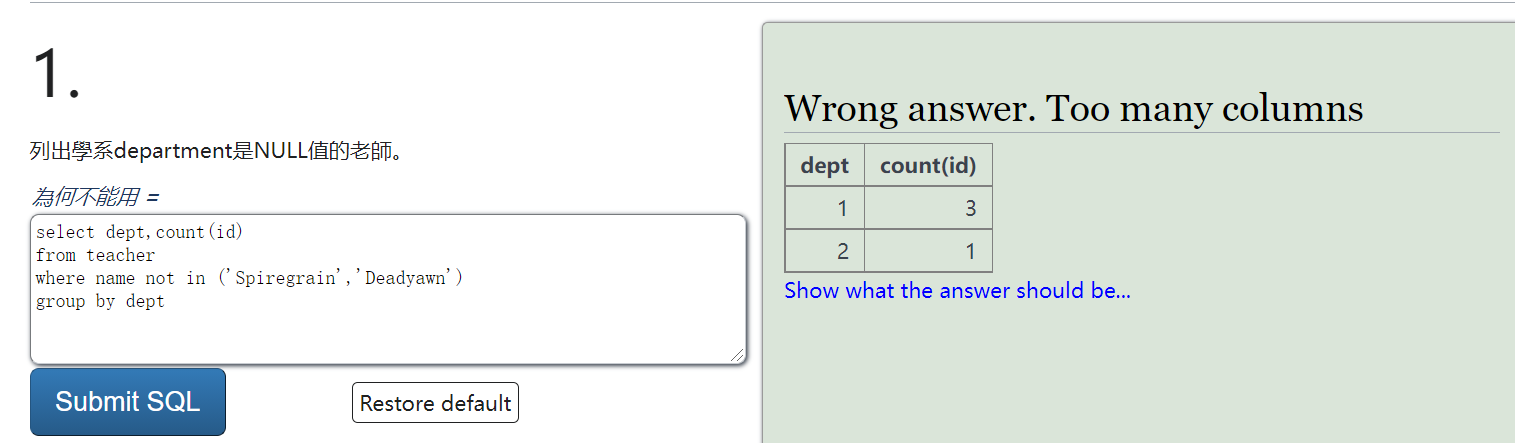
SQL逻辑练习
https://sqlzoo.net/wiki/Using_Null/zh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号