Unicode字符集、UTF-8编码、ZERO WIDTH NO-BREAK SPACE、大小端和BOM(修订中)
如有问题欢迎指正
一、Unicode字符集
Universal Character Set又称统一码、万国码、单一码包括字符集、编码方案等,它的字符和码点存在映射关系,每个字符有且仅有一个二进制编码(码点),目前已编码code范围为U+0000 to U+10FFFF,Unicode字符集更新到Unicode15。Unicode有两种字符集:UCS2和UCS4。USC2不够用(已经有U+10FFFF),目前只考虑UCS4,理论上它有2^31容量足以将全世界所有文字和符号囊括进去。(由于直接用Unicode编码中文存储和传输会造成很大的空间时间浪费,所以对其改进形成不同的编码方式,不同语言文字支持可自由选择)它的编码方式目前有三种比较常见:UTF-8、UTF-16、UTF-32(其他还有UTF-7和UTF-7.5)。其中UTF-8与字节序(BOM)无关且兼容ASCII编码。(可以看计算机组成原理相关的书籍中有关“字符表示”部分)
Unicode编码字符映射表查询链接:https://www.utf8-chartable.de/unicode-utf8-table.pl或直接在官网直接查pdf表。
Unicode截止2023-3-31迭代到Unicode15.0,共10FFFF个码点,个别码点未编码闲置。

附官网:Unicode官网字符表官网
二、UTF-8编码
- 定义:Unicode Translation Format - 8(Unicode转换格式),是Unicode编码方案的一种,是针对Unicode的一种可变长度字符编码——单字节、双字节、三字节、四字节模式。ASCII字节(0x00-0x7F)仅占1字节,UTF-8编码可以通过屏蔽位和移位操作快速读写。字节FF和FE在UTF-8编码中永远不会出现,因此他们可以用来区分UTF-16或UTF-32文本。字节顺序无关的,它的字节顺序在所有系统中都是一样的,因此它实际上并不需要BOM。
- UTF-8由于有填充符,同样的文本编码后比GBK等编码的文件长,但以7位ASCII字符为主的英文文档大大节省了编码长度(全世界中文文档远远少于英文)。
- 编码规则
二进制状态,7位(前127个字符)和ASCII编码完全相同,大于127的Unicode,会根据此Unicode字符转换成UTF-8字节的数量,填充字节数标识符作为前缀:如果是两个字节,首字节填充11+0,其中1的个数表示字节数,0表示字节数标志符结束,当计算机读取到110开头的字节时,会知道这个字符由两个字节表示,会继续往后读取一个字节;第二个字节10开头,表示此字节和前面是同一个字符。以此类推Unicode字符转换成UTF-8编码格式为三四字节的编码规则。下为Unicode字符转换UTF-8格式的对照表:
|
Unicode符号范围:码点 (十六进制0x) |
UTF-8编码方式(二进制) | |
| 0000 0000~0000 007F | 0XXX XXXX |
二进制7位的Unicode编码成UTF-8编码方式(0~111 1111),共127个,用于兼容ASCII |
| 0000 0080~0000 07FF | 110X XXXX 10XX XXXX |
二进制11位的Unicode编码成UTF-8编码方式(1000 0000~111 1111 1111),共2^11 - 2^7个字符 |
| 0000 0800~0000 FFFF | 1110 XXXX 10XX XXXX 10XX XXXX |
二进制12~16位的Unicode编码成UTF-8编码方式(1000 0000 0000~1111 1111 1111 1111),共2^16-2^11个 |
| 0001 0000~0001 FFFF | 1111 0XXX 10XXXXXX 10XXXXXX 10XXXXXX |
二进制17~21位的Unicode编码成UTF-8编码方式(1 0000 0000 0000 0000~1 1111 1111 1111 1111 1111),共2^21 - 2^17个字符 |
- 无法直接从Unicode字符数判断出UTF-8文本的字节数,因为UTF-8采用的是不定长的编码方式。
- 由UTF-8的编码方式可以看出,由于填充位,有一部分码点在UTF-8中并没有码点值,永远废弃闲置状态,如FE、FF。
- UTF-8编码有带BOM和不带BOM两种,两者的唯一区别是带BOM的文本开头有U+FFEF字符,而不带的没有。
4.编码规则讲解
如“王”字符的码点为 0x0000 738B:
首先声明:UTF8编码一次读取两位十六进制,即二进制8位,一个字节,所以叫UTF8。讲解基于汇编。编码时,有一个计数指针默认为0(为了方便理解添加的东西,实际不存在这玩意儿,直接用整个字符前缀来计数的),整个字符前缀默认0 和 一个清空为0的存储空间(忘记叫什么了)
738B,从后往前读两位:8B-->1000 1011-->发现超过111 1111(8-1=7位),添加前缀10,计数1个字节,整个前缀前面添加一个1后变为10,存储空间数据为1000 1011,剩余位数8-6=2位:10-->继续读两位,为73-->0111 0011-->加上前面剩余的两位,需要编码:0111 0011 10, 超过两字节范围8-2-1=5-->取需要编码的后6位:001101添加上前缀10,压进存储空间为:1000 1110 1000 1011,计数2个字节,整个前缀前面添加一个1后变为110-->剩余四位:0111,小于等于8-3-1(8位-(计数+1)-1),可以编码完,根据规则编码为1110 0111,压进存储空间。
最终UTF8编码规则编码出的二进制为:1110 0111 1000 1110 1000 1011
4.如何解码?
用上面的1110 0111 1000 1110 1000 1011举例。(例子为大端模式,小端模式的话细节有些许差异,但存储结果一样)
如果文本传输没有异常,解码读取第一个字节——1110 0111,发现开头是1,判断非ASCII,会去查询非ASCII字符,然后发现读取了三个1遇到终止符0,确定后面查询索引表范围为0000 0800~0000 FFFF,将数据位0111取出放到内存。往后读取发现是1然后遇到计数位终止符0(有个校验过程),继续读取整个字节即:1000 1110,将数据位00 1110取出压进内存,此时内存中数据为0111 00 1110;继续解码,1000 1011,计数位是10,cpu判定这是上一个字符的字节,将数据位为001011压进内存中,此时内存中数据为:0111 0011 1000 1011,用16进制表示为:U+738B。查询Unicode映射表得到该字符为:王。
5.为什么这么编码?
- Unicode编码是ISO为了统一全世界的编码而做出的规范,将全世界所以字符罗列进去,但总给了32位(2^32约等于42.9亿)来编码这些字符,而有些如ASCII和扩展ASCII等编码,由于占用空间较少并且常用,出于空间利用率和传输效率考虑,发展为可变长度的编码方式。同时需要考虑CPU读取时解码效率和字节校验,将字符码点添加计数位进行简单包装,于是产生了UTF-8编码(根据一次读取不同长度,还产生了UTF-16和UTF-32编码)。
- UTF8编码长度可变,所以需要有计数位,而为了计算机方便读取和写入,直接用在整个字符前面添加1来记录字节数。
- 最古老的ASCII编码被大家共识,所以需要兼容它,需要减去127即0x7F,即从0x80开始编码。来看看127的二进制XXX XXXX,只需要添加一位就是一字节,可以区分ASCII和非ASCII,计算机只要读到0就一定是ASCII字符,读到1就是非ASCII字符,由此做到兼容ASCII字符集。
- 为什么填充位是10呢?主要为了区别于一个新字符开头,1个1代表一个字节,0表示计数位结束,在计算机解码时10表示这里有一个字节,同时保证解码结果唯一性(半字,双字型等字符不会被胡乱分开合并读取)、校验和解码效率,当总的计数字节。(就是个霍夫曼编码规则)
- 前缀:类似填充位,1表示一个字节,0表示计数位结束,在计算机解码时非ASCII字符前缀假如为11110,表示计算机后面读取的4个字节都都需要push进这个字符,往后面读取三个字节的开头必定是10,第四个字节开头必定不是10,以此作为校验防止字节丢失和异常。
三、ZERO WIDTH NO-BREAK SPACE
- 定义:
原:是Unicode字符集中码点值为U+FEFF的字符,称为没有宽度不中断的空格符。
现:当以UTF-16或UTF-32来将UCS/统一码字符组成字符串编码时,用它标识字节序(BOM),当接收的数据为Unicode编码U+FEFF为大端对其,当接收的数据为U+FFFE为小端对齐。它的在UTF-8编码的文本文件中,根据UTF-8编码规则,UTF-8编码为BE BB EF。
2.在Unicode3.2后,U+FEFF字符的不可见字符功能废弃,只能出现在字节流开头表示字节序BOM,用U+2060来表示零宽度不中断空格。
四、大小端
首先,CPU寻址是顺序寻址(0x0001到0xFFFF),如果在大端中,先读到的是高位,小端相反,这和他们存储数据的方式有关,即大端和小端两种数据存储模式,大小端只和CPU芯片规定有关,和硬盘缓存等无关,大小端只是CPU摆放数据和读取数据的方式。如果不同的存储模式,读取同一份文件解码后的结果也会不同,方便两种系统交互。
必须知道:什么是高位字节,什么是低位字节。如字符U+123F,一个字节8位就是两个16进制数,而高低和数学里面的高低位一样,可以推论出:高位字节是12,低位字节是3F。
大端模式:Big Endian,又称大端字节序,也是网络传输字节序。数据的高位,保存在内存的低地址中,而数据的低位保存在内存的高地址中;如:U+FEFF(二进制:1111 1110 1111 1111)用UTF8编码方式在大端地址中为:11101111 10111011 10111111(下划线为填充位,地址从低到高,十六进制表示为:BE BB EF)。
小端模式:Little Endian,又称小端字节序。数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地址中;如:U+FEFF在小端中为:10111111 10111011 11101111(下划线为填充位,地址从低到高,十六进制表示为:EF BB BE)。如果CPU采用小端模式,在网络中接收文件后需要将文件转换字节序。
两者的区别在于低地址中保存高位字节还是低位字节,这种区别仅存在于多字节的编码,如一个32位的数据0x12345678存放到存储器时(原数据为大端),两种模式的寄存器地址存储数据如下:
原寄存器地址R1截取(16进制表示):
| ...高 | 68 | 67 | 66 | 65 | ....低地址 |
| 低 | 78 | 56 | 34 | 12 | 高位字节 |
新内存中BE存放地址截取:
| ...高 | 1F | 1E | 1D | 1C | ....低地址 |
| 低 | 78 | 56 | 34 | 12 | 高位字节 |
若是存放在BE存放地址截取:
| ...高 | 1F | 1E | 1D | 1C | ....低地址 |
| 高 | 12 | 34 | 56 | 78 | 低位字节 |
两种模式各有优缺点,两种模式之争吵了一个世纪了,目前大多系统都可以切换模式。
大小端模式文件传输方式:如果两个传输文件的cpu都采用大端模式,文件不需要转换存储模式,直接写入到寄存器的数据段。但如果两个CPU字节序不同,文件传输后则需要进行转换,为了统一,iso规定的网络传输协议都是大端模式,在文件传输时,文件会按照协议要求转换为大端字节序,然后传输到目标计算机,CPU再将网络文件转换为本地字节序。
存在疑点:计算机接收网络文件时,io流存储位置,缓存存储位置,什么时候如何转换?计算机发送网络文件时,转换后文件存储位置,什么时候如何转换?
五、BOM(声明:只分析了UTF8,但它主要作用于UTF-16和UTF-32)
- 定义:(Byte Oder Mark)字节顺序标记是由字符U+FEFF开头的数据流,U+FEFF码点是定义字节序和编码形式的结构,主要用于未标记的明文文件。在一些高层协议中,特别是在有规定Unicode数据流形式的协议中,BOM格式可能会强制使用(或者禁止)。(某些协议对BOM格式有规定)[AF]UTF8文件中带BOM文本中,如果前三个字节编码是BE BB EF或者EF BB BE,解码过来就是FEFF或者FFEF,这样就区分开两种数据存储模式,方便CPU解码时切换读取方式。
- 为什么使用BOM?系统如8086这种是只能使用小端模式,如果一份文件从另一台使用大端模式的系统传输过来,查看解码时就会面临不同的解码方式,还有一些系统默认的是小端模式,如果没有修改模式,也会面临统一的困境。两种模式的系统之间交流被cpu字节序所阻,CPU必须用一些特殊手段辨认到底使用什么解码方式,于是产生了字节序BOM。BOM字节序由两个字节的字符U+FEFF表达,读取文件第一个字符,如果CPU用默认方式解码后的是FEFF,文件编码方式是大端,如果是FFFE则是小端。
- 如何区分是否带BOM:只需读取前三个字节(未解码),判断是BF BB EF或者EF BB BF,则是带BOM,没有则否。
- java判定代码和去BOM
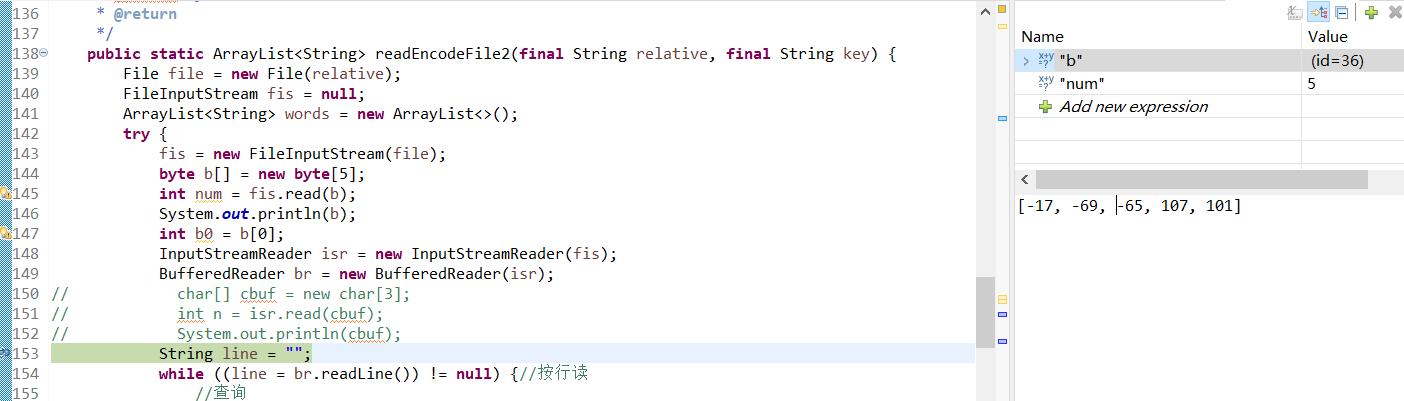
/** 判断BOM * 编码格式 字节流开头字节 * UTF-8 0xef bb bf * UTF-16LE 0xff fe * UTF-16BE 0xfe ff * UTF-32LE 0xff fe 00 00 * UTF-32BE 0x00 00 ff fe **/ //此处仅展示UTF8 int head[] = new int[4]; FileInputStream fis = fis = new FileInputStream("src/file/strategy1.txt"); BufferedInputStream bis = new BufferedInputStream(fis);//缓冲流回拨文件指针 //以下三行为获取字节流首部三个字节 head[0] = fis.read(); head[1] = fis.read(); head[2] = fis.read(); bis.mark(3);//设定标记 if (head[0] == 0xef && head[1] == 0xbb && head[2] == 0xbf) { System.out.println("utf8"); bis.reset();//指针回拨 } else { System.out.println("else or no BOM"); } head[3] = bis.read(); System.out.println(head[3]);//239以上为用文件字节流的头三个字节(10进制整型)和16进制数值比较,判断是否有BOM。还要一种方案:判断字节流的read(byte[] b)方法,如下
byte[] head = new byte[3]; fis.read(head);// 将文件字节流头三个字节读取到head字节数组中 if (head[0] == -17 && head[1] == -69 && head[2] == -65) { System.out.println("UTF8"); } else { System.out.println("others or no BOM"); }
但为什么读取到的是-17 -69 -65,不知道。已知-17是1001 0001,239的二进制表示也是1110 1111,-17刚好是239的补码,而java是的数字是有符号位的,所以怀疑有进行什么转换。 - 下面贴上部分调试片段,有代码:
![]()
![]()
![]()
五、其他编码方式
与UTF8同属Unicode编码的编码方式有:UTF-16,UTF-32,顾名思义,UTF32是一次读32位——8个16位数字,即四个字节,UTF-16一次读16位——4个16位数字,即两个个字节。编码规则大同小异,都不兼容ASCII,但他们两个一定有BOM,因为他们一次读取超过1个字节,会存在压栈顺序问题,也就是大小端模式问题(也有使用不带BOM的,但会硬性规定大小端如:UTF-16BE、UTF-16LE)。
有关UTF-16和UTF-32转链接:https://blog.csdn.net/nitianxiaozi/article/details/77908020
- 对UTF-8编码有兴趣的推荐文章:
字符编码ASCII UTF8 字节序 大端 小端 (就挺神奇,为什么诗歌美文网会有这玩意儿)
- Unicode编码表:
https://www.utf8-chartable.de/unicode-utf8-table.pl
- 实在想全面深入研究:Unicode官网字符表官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号