大数据高级查询语言引擎总结
大数据高级查询语言引擎总结
高级查询语言引擎用来处理大规模数据,一般运行在其它分布式处理系统的上层,它提供类SQL的查询语言,同时它通过解析器将查询语言转化为分布式处理作业,并调用分布式处理系统进行运算。它为复杂的海量数据并行计算提供了了简单的操作和编程接口。
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Hive的用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 的查询,比如 select from tbl 不会生成 MapReduce 任务)。
Pig
Pig是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
Pig的查询经过Pig Latin的转换后变成了一道MapReduce的作业,通过MapReduce多个线程,进程或者独立系统并行执行处理的结果集进行分类和归纳。Map() 和 Reduce() 两个函数会并行运行,即使不是在同一的系统的同一时刻也在同时运行一套任务,当所有的处理都完成之后,结果将被排序,格式化,并且保存到一个文件。Pig利用MapReduce将计算分成两个阶段,第一个阶段分解成为小块并且分布到每一个存储数据的节点上进行执行,对计算的压力进行分散,第二个阶段聚合第一个阶段执行的这些结果,这样可以达到非常高的吞吐量,通过不多的代码和工作量就能够驱动上千台机器并行计算,充分的利用计算机的资源,打消运行中的瓶颈。也就是说,Pig最大的作用就是对mapreduce算法(框架)实现了一套shell脚本 ,类似我们通常熟悉的SQL语句,在Pig中称之为Pig Latin,在这套脚本中我们可以对加载出来的数据进行排序、过滤、求和、分组(group by)、关联(Joining),Pig也可以由用户自定义一些函数对数据集进行操作,也就是传说中的UDF(user-defined functions)。
Pig Latin 是一个相对简单的语言,它可以执行语句。一调语句 就是一个操作,它需要输入一些内容(比如代表一个元组集的包),并发出另一个包作为其输出。一个包 就是一个关系,与表类似,您可以在关系数据库中找到它(其中,元组代表行,并且每个元组都由字段组成)。用 Pig Latin 编写的脚本往往遵循以下特定格式,从文件系统读取数据,对数据执行一系列操作(以一种或多种方式转换它),然后,将由此产生的关系写回文件系统。Pig 拥有大量的数据类型,不仅支持包、元组和映射等高级概念,还支持简单的数据类型,如 int、long、float、double、chararray 和 bytearray。如果使用简单的类型,除了称为 bincond 的条件运算符(其操作类似于 C ternary 运算符)之外,还有其他许多算术运算符(比如 add、subtract、multiply、divide 和 module)。并且,还有一套完整的比较运算符,包括使用正则表达式的丰富匹配模式。所有 Pig Latin 语句都需要对关系进行操作(并被称为关系运算符)。有一个运算符用于从文件系统加载数据和将数据存储到文件系统中。有一种方式可以通过迭代关系的行来 FILTER 数据。此功能常用于从后续操作不再需要的关系中删除数据。另外,如果需要对关系的列进行迭代,而不是对行进行迭代,可以使用 FOREACH 运算符。FOREACH 允许进行嵌套操作,如 FILTER 和 ORDER,以便在迭代过程中转换数据。ORDER 运算符提供了基于一个或多个字段对关系进行排序的功能。JOIN 运算符基于公共字段执行两个或两个以上的关系的内部或外部联接。SPLIT 运算符提供了根据用户定义的表达式将一个关系拆分成两个或两个以上关系的功能。最后,GROUP 运算符根据某个表达式将数据分组成为一个或多个关系。
Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala最开始是参照 Dremel系统进行设计的。Dremel是Google的交互式数据分析系统,它构建于Google的GFS(Google File System)等系统之上,支撑了Google的数据分析服务BigQuery等诸多服务。Dremel的技术亮点主要有两个:一是实现了嵌套型数据的列存储;二是使用了多层查询树,使得任务可以在数千个节点上并行执行和聚合结果。列存储在关系型数据库中并不陌生,它可以减少查询时处理的数据量,有效提升 查询效率。Dremel的列存储的不同之处在于它针对的并不是传统的关系数据,而是嵌套结构的数据。Dremel可以将一条条的嵌套结构的记录转换成列存储形式,查询时根据查询条件读取需要的列,然后进行条件过滤,输出时再将列组装成嵌套结构的记录输出,记录的正向和反向转换都通过高效的状态机实现。另 外,Dremel的多层查询树则借鉴了分布式搜索引擎的设计,查询树的根节点负责接收查询,并将查询分发到下一层节点,底层节点负责具体的数据读取和查询执行,然后将结果返回上层节点。
Impala其实就是Hadoop的Dremel,Impala使用的列存储格式是Parquet。Parquet实现了Dremel中的列存储,未来还将支持 Hive并添加字典编码、游程编码等功能。Impala的系统架构如图1所示。
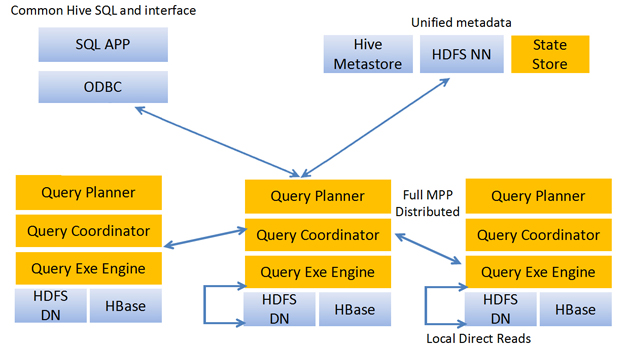
Impala使用了Hive的SQL接口(包括SELECT、 INSERT、Join等操作),但目前只实现了Hive的SQL语义的子集(例如尚未对UDF提供支持),表的元数据信息存储在Hive的 Metastore中。StateStore是Impala的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册、错误检测等功能。 Impala在每个节点运行了一个后台服务Impalad,Impalad用来响应外部请求,并完成实际的查询处理。Impalad主要包含Query Planner、Query Coordinator和Query Exec Engine三个模块。QueryPalnner接收来自SQL APP和ODBC的查询,然后将查询转换为许多子查询,Query Coordinator将这些子查询分发到各个节点上,由各个节点上的Query Exec Engine负责子查询的执行,最后返回子查询的结果,这些中间结果经过聚集之后最终返回给用户。
在Cloudera的测试中,Impala的查询效率比Hive有数量级的提升。从技术角度上来看,Impala之所以能有好的性能,主要有以下几方面的原因:Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销;省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多;Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销;通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销;用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令;使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
其他
作为一种查询语言,Sawzall是一种类型安全的脚本语言。由于Sawzall自身处理了很多问题,所以完成相同功能的代码就简化了非常多-与MapReduce的C++代码相比简化了10倍不止。Sawzall语法和表达式很大一部分都是从C照搬过来的;包括for循环,while循环,if语句等等都和C里边的很类似。定义部分借鉴了传统Pascal的模式。Sawzall有很多其他的传统特性,比如函数以及一个很广泛的选择基础函数库。在基础函数库中是给调用代码使用的国际化的函数,文档分析函数等等。
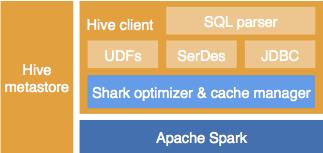
Shark是Spark上的数据仓库实现,它可以看做是Spark+Hive。它运行在Spark上,相对于在Hadoop上它运行Hive查询在内存上要快100倍,而在硬盘上快10倍。它在Spark上的架构图可以参考图2。
Mahout是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Apache Mahout项目已经发展到了它的第三个年头,目前已经有了三个公共发行版本。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
来源:https://greeensy.github.io/2014/06/20/query-computing/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号