深度学习优化算法总结——从SGD到Adam
本文参考自:SGD、Momentum、RMSprop、Adam区别与联系
上一篇博客总结了一下随机梯度下降、mini-batch梯度下降和batch梯度下降之间的区别,这三种都属于在Loss这个level的区分,并且实际应用中也是mini-batch梯度下降应用的比较多。为了在实际应用中弥补这种朴素的梯度下降的一些缺陷,有许多另外的变种算法被提出,其中一些由于在许多情况下表现优秀而得到广泛使用,包括Momentum、Nesterov Accelerated Gradient、Adagrad和Adam等。
梯度下降
利用梯度下降求解的时候遵循这样一个模式,对于当前模型的参数 \(\boldsymbol{\theta}\),计算在训练样本上的损失 \(\boldsymbol{\theta}\),接下来计算损失函数 \(\boldsymbol{\theta}\) 关于参数 \(\boldsymbol{\theta}\) 的梯度 \(\nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})\),接下来沿着 \(\nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})\) 的反方向更新。再考虑到计算参数更新量的方式,可以将其一般化为下面这几个步骤:
(1)计算损失函数关于参数 \(\boldsymbol{\theta}\) 的梯度:
(2)根据历史梯度计算一阶动量和二阶动量:
(3)计算参数更新量,其中 \(\eta\) 为学习率,\(\varepsilon\)防止分母为0,通常取1e-8:
(4)进行参数更新:
随机梯度下降SGD
朴素的SGD中没有动量的概念,即 \(\boldsymbol{m}_{t}=\boldsymbol{g}_{t}\),\(\boldsymbol{V}_{t}=\boldsymbol{I}\),\(\varepsilon=0\)。此时参数更新量就是\(\Delta \boldsymbol{\theta}_{t}=\eta \cdot \boldsymbol{g}_{t}\),即
SGD在下降过程中会出现震荡(即使通过mini-batch梯度下降能够缓解),特别是容易陷入局部最优点或者是鞍点。
Momentum
Momentum借鉴了物理中动量的概念,能够有效的加速学习速度。原因在于Momentum使用了历史梯度的指数加权平均来调整参数更新方向,使得震荡方向的更新减慢,向最优解方向的更新加快,最终更快的收敛。Momentum使用了一阶动量来实现这个目的:
没有使用二阶动量\(\boldsymbol{V}_{t}=\boldsymbol{I}\),\(\varepsilon=0\)。\(\beta_1\) 的经验值是0.9,即当前时刻的下降方向主要有前一时刻的方向加上一点当前时刻的梯度方向得到。
Nesterov Accelerated Gradient
Nesterov Accelerated Gradient算法在损失函数有增大趋势的时候减缓学习速率。下图非常有助于理解
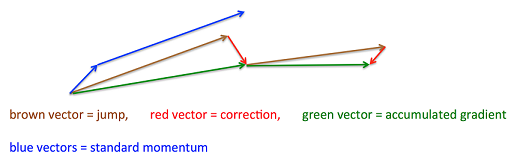
具体来说,NAG先沿着上一步的梯度更新一次参数(相当于估计下一次的近似位置),在更新后的位置重新计算梯度,然后用这个梯度值进行修正得到更新方向:
接下来计算一阶动量并计算参数的更新方向,更新参数(这一步同Momentum)。
Adagrad
前面的集中方法对于所有的参数都使用了相同的更新速率进行更新,但事实上在更新过程中可能有的参数已经进行了很大的更新,只需要微调即可。Adagrad算法就实现了这个功能,通过用某个参数的所有历史梯度平方和来缩放其更新量,达到自适应的改变所有参数的学习率的目的。
这样历史梯度平方和小的参数得到更大的学习率。其中一阶动量使用梯度。
虽然Adagrad有一些较好的性质,但是在训练深度神经网络的时候往往会导致学习率衰减过量甚至在训练后期衰减到0。
RMSprop
RMSprop算法由Hinton大师在Coursera课程上提出,解决了Adagrad学习率下降过快的问题,主要是改变了Adagrad中二阶动量的计算方式,才用了类似于Momentum的指数移动平均的方式来计算二阶动量:
这样不会出现由于历史梯度平方和累计造成的学习率急剧下降的问题。Hinton建议 \(\beta_{2}=0.9\)。
Adam
Adam = Adaptive + Momentum,顾名思义Adam集成了SGD的一阶动量和RMSProp的二阶动量。即:
感觉是除了SGD之外我这个菜鸟在程序中见到的最多的优化方式了。\(\beta_{1}\) 和 \(\beta_{2}\) 也不用多说了,一个用来修正一阶动量,一个用来修正二阶动量。
参考资料:
https://zhuanlan.zhihu.com/p/32488889
https://zhuanlan.zhihu.com/p/32626442

 浙公网安备 33010602011771号
浙公网安备 33010602011771号