Openstack入坑指南
什么是云计算
概念
云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息,可以按需求提供给计算机和其他设备。用户不需要了解”云“中的基础设施细节,不必具有相应的专业知识,也无需直接控制。云计算描述了一种基于互联网的新的IT服务增加、使用和交付模式。
我们举一个例子来理解云计算,云计算中的”云“可以理解为天上的云,天上的云可以变成雨水降落到地上,落到地上的水蒸发后又变成云彩。这样就形成了一个循环。
这里的雨水表示计算资源,比如虚拟机、存储、网络等等。
云变水的过程表示获取资源的过程。
水变云的过程表示资源回收的过程。
云计算就像云水的循环过程一样,按需分配,循环利用。
为什么需要云计算
云计算的本质是希望解决资源利用率、计算能力不足和成本的问题。
- 有效解决硬件单点故障的问题
- 单点故障会造成服务的中断,要解决单点故障,需要为每个硬件准备备用硬件,不但增加了硬件购置成本,部署与维护成本也大。
- 按需增减资源
这里的资源指的是硬件、带宽等。自己管理服务器会面临一个很头疼的问题,
- 增加服务的时候,需要购买服务器,购买服务器需要时间;使用云服务器的时候,可随时增加素驱动的结果:需求拉动和技术推动。业务需求的拉动,希望解决业务应用的问题,云计算本质上是希望解决资源利用率、计算能力不足和成本的问题。技术发展的推动,使得云计算具备了技术上的可行性,技术的发展推动了IT创新的商业价值。云计算的出现也有其必然性。
- 减少服务的时候,需要把购置的服务器取下,服务器会退还给厂商或者闲置下来,而云服务器不用的时候,直接不续费就好了(比如说阿里云)
- 在未使用云服务器之前,加入我们需要一台低配置的服务器运行一个服务,服务器需要空间存放,每年的耗电量也不小,因此都是使用一台服务器运行多个服务来降低服务器的购买和维护成本;而使用云服务器之后,需要什么样的配置,直接购买即可,对服务器的职责进行分离,减少各个服务之间的互相影响,效率更高。
- 在托管服务器的时候,我们需要购买带宽,一般在与ISP服务商签订合同之前需要确定带宽大小,当后期发现购买的带宽过多或者过少的时候,是无法减小或增加带宽的; 使用云服务器之后,可以灵活的增减带宽,可以随时对带宽进行增减。举个例子,对类似于淘宝的电商网站,假设每年只有双11和双12期间需要大量带宽,其他时间网站流量很小,这个时候使用云服务器就可以针对双11和双12增加带宽,其他时间只要保持一般的流量就可以了。
- 更好的费用支付方式
- 一般在IDC托管服务器的时候,合同都是以年为单位签订合同,一次支付一个季度的费用; 而使用云服务器, 可以支付更短时间内的费用,像阿里云可以按照月为单位进行支付, 或者按照使用量来购买,比如按照网络流量支付费用。
- BGP解决南北线路问题
- 宽带市场一直有”南电信北联通“的问题(即中国联通的根基在北方市场、中国电信的根基在南方市场),所以我们需要考虑南北互通的问题,即路由问题。比如说,南方的联通用户,在访问上海电信机房的服务器的时候,先要绕路到联通的北京总出口(假设在北京),再回到上海。虽然使用光纤的速度很快,但是当联通的总出口出现瓶颈,无法负担巨大的网络流量时,联通的用户访问电信网络的服务器就会变慢。BGP就解决了南北互通时的绕路问题,优化了线路。
云计算服务模式
云计算有三种模式:
- IaaS:基础设施即服务——消费者使用“基础计算资源”,如处理能力、存储空间、网络组件或中间件。消费者能掌控操作系统、存储空间、已部署的应用程序及网络组件(如防火墙、负载平衡器等),但并不掌控云基础架构。例如:Amazon AWS、Rackspace。
- PasS:平台即服务——消费者使用主机操作应用程序。消费者掌控运作应用程序的环境(也拥有主机部分掌控权),但并不掌控操作系统、硬件或运作的网络基础架构。平台通常是应用程序基础架构。例如:Google App Engine。
- SaaS: 软件即服务——消费者使用应用程序,但并不掌控操作系统、硬件或运作的网络基础架构。是一种服务观念的基础,软件服务供应商,以租赁的概念提供客户服务,而非购买,比较常见的模式是提供一组账号密码。例如:Microsoft CRM与Salesforce.com。
云计算应用
- 公有云 —— 公用云服务可通过网络及第三方服务供应者,开放给客户使用,“公用”一词并不一定代表“免费”,但也可能代表免费或相当廉价,公用云并不表示用户数据可供任何人查看,公用云供应者通常会对用户实施使用访问控制机制,公用云作为解决方案,既有弹性,又具备成本效益。
- 私有云 —— 私有云具备许多公用云环境的优点,例如弹性、适合提供服务,两者差别在于私有云服务中,数据与程序皆在组织内管理,且与公用云服务不同,不会受到网络带宽、安全疑虑、法规限制影响;此外,私有云服务让供应者及用户更能掌控云基础架构、改善安全与弹性,因为用户与网络都受到特殊限制。
- 云物联 —— “物联网就是物物相连的互联网”。这有两层意思:第一,物联网的核心和基础仍然是互联网,是在互联网基础上的延伸和扩展的网络;第二,其用户端延伸和扩展到了任何物品与物品之间,进行信息交换和通信。
- 云存储 —— 云存储是在云计算(cloud computing)概念上延伸和发展出来的一个新的概念,是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。 当云计算系统运算和处理的核心是大量数据的存储和管理时,云计算系统中就需要配置大量的存储设备,那么云计算系统就转变成为一个云存储系统,所以云存储是一个以数据存储和管理为核心的云计算系统。
- 云游戏 —— 云游戏是以云计算为基础的游戏方式,在云游戏的运行模式下,所有游戏都在服务器端运行,并将渲染完毕后的游戏画面压缩后通过网络传送给用户。在客户端,用户的游戏设备不需要任何高端处理器和显卡,只需要基本的视频解压能力就可以了。
- 云安全 —— 云安全(Cloud Security)是一个从“云计算”演变而来的新名词。云安全的策略构想是:使用者越多,每个使用者就越安全,因为如此庞大的用户群,足以覆盖互联网的每个角落,只要某个网站被挂马或某个新木马病毒出现,就会立刻被截获。 “云安全”通过网状的大量客户端对网络中软件行为的异常监测,获取互联网中木马、恶意程序的最新信息,推送到Server端进行自动分析和处理,再把病毒和木马的解决方案分发到每一个客户端。
- 混合云 —— 混合云结合公用云及私有云,这个模式中,用户通常将非企业关键信息外包,并在公用云上处理,但同时掌控企业关键服务及数据。
OpenStack
OpenStack 简介
OpenStack是一个由NASA(美国国家航空航天局)和Rackspace合作研发并发起的,以Apache许可证授权的自由软件和开放源代码项目。作为一个开源的云计算管理平台项目,旨在为公共及私有云的建设与管理提供软件的开源项目,帮助服务商和企业内部实现类似于 Amazon EC2 和 S3 的云基础架构服务(Infrastructure as a Service, IaaS)。
OpenStack项目及组件
- 控制台
服务名:Dashboard
项目名:Horzon
功能:提供一个Web前端控制台,以此来展示OpenStack的功能. - 计算
服务名:计算(Compute)
项目名:Nova
功能:一套控制器,用于为单个用户或使用群组管理虚拟机实例的整个生命周期,根据用户需求来提供虚拟服务。负责虚拟机创建、开机、关机、挂起、暂停、调整、迁移、重启、销毁等操作,配置CPU、内存等信息规格。 - 网络
服务名:网络&地址管理(Network)
项目名:Neutron
功能:提供云计算的网络虚拟化技术,为OpenStack其他服务提供网络连接服务。为用户提供接口,可以定义Network、Subnet、Router,配置DHCP、DNS、负载均衡、L3服务,网络支持GRE、VLAN。插件架构支持许多主流的网络厂家和技术,如OpenvSwitch。 - 对象存储
服务名:对象存储(Object Storage)
项目名:Swift
功能:一套用于在大规模可扩展系统中通过内置冗余及高容错机制实现对象存储的系统,允许进行存储或者检索文件。可为Glance提供镜像存储,为Cinder提供卷备份服务。 - 块存储
服务名:块存储 (Block Storage)
项目名:Cinder
功能:为运行实例提供稳定的数据块存储服务,它的插件驱动架构有利于块设备的创建和管理,如创建卷、删除卷,在实例上挂载和卸载卷。 - 认证服务
服务名:认证服务(Identity Service)
项目名:Keystone
功能:为OpenStack其他服务提供身份验证、服务规则和服务令牌的功能,管理Domains、Projects、Users、Groups、Roles。 - 镜像服务
服务名:镜像服务(Image Service)
项目名:Glance
功能:一套虚拟机镜像查找及检索系统,支持多种虚拟机镜像格式(AKI、AMI、ARI、ISO、QCOW2、Raw、VDI、VHD、VMDK),有创建上传镜像、删除镜像、编辑镜像基本信息的功能。 - 计费服务
服务名:计费(Metering)
项目名:Ceilometer
功能:能把OpenStack内部发生的几乎所有的事件都收集起来,然后为计费和监控以及其它服务提供数据支撑。 - 编排服务
服务名:部署编排 (Orchestration)
项目名:Heat
功能:提供了一种通过模板定义的协同部署方式,实现云基础设施软件运行环境(计算、存储和网络资源)的自动化部署。 - 数据库服务
服务名:数据库服务(Database Service)
项目名:Trove
功能:为用户在OpenStack的环境提供可扩展和可靠的关系和非关系数据库引擎服务。
OpenStack各组件详解
-
组件逻辑关系图

- Openstack新建云主机流程图
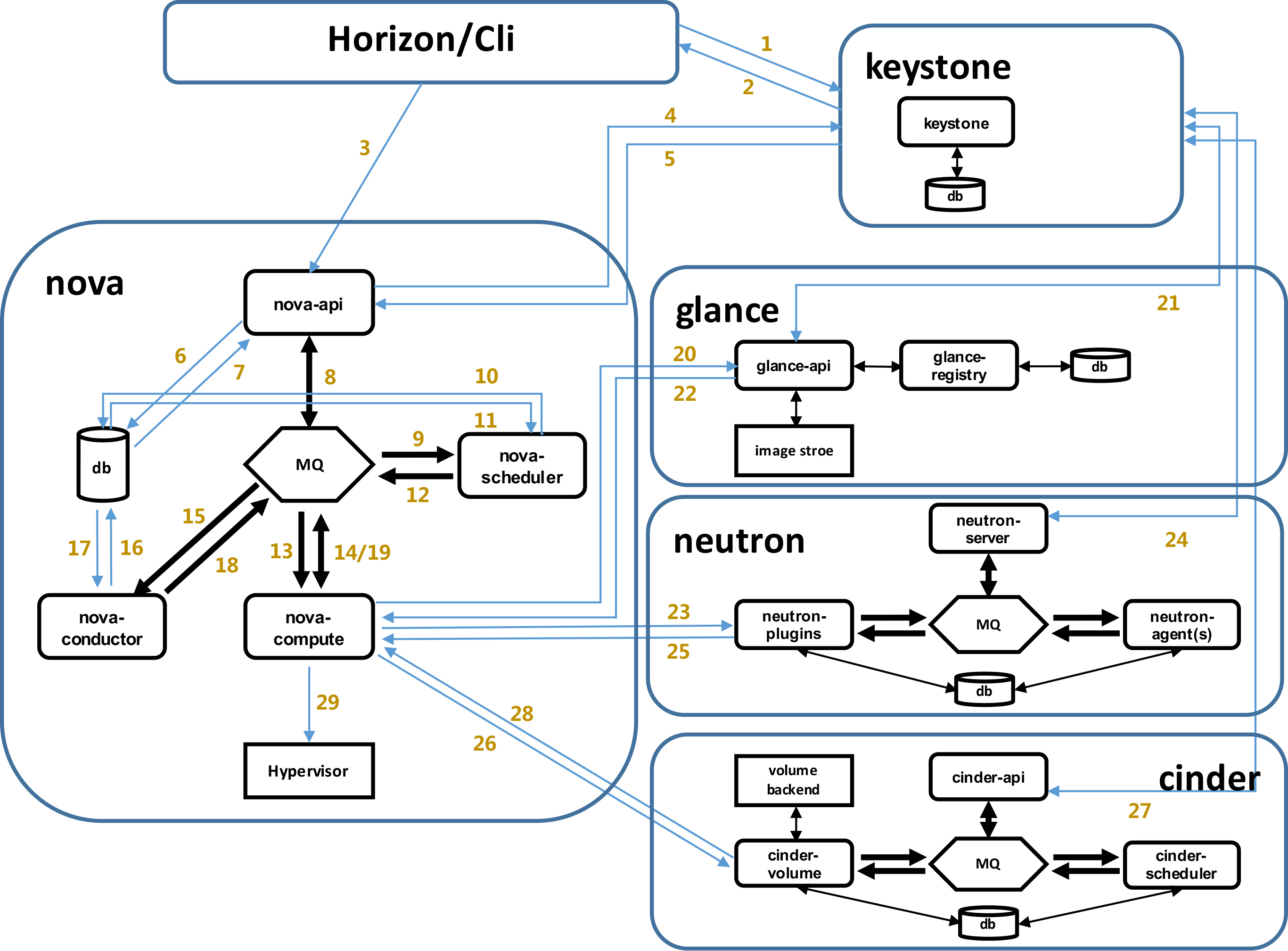
虚拟机创建过程:
- 界面或命令行通过RESTful API向keystone获取认证信息。
- keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
- 界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
- nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
- keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
- 通过认证后nova-api和数据库通讯。
- 初始化新建虚拟机的数据库记录。
- nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
- nova-scheduler进程侦听消息队列,获取nova-api的请求。
- nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
- 对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
- nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
- nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
- nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
- nova-conductor从消息队队列中拿到nova-compute请求消息。
- nova-conductor根据消息查询虚拟机对应的信息。
- nova-conductor从数据库中获得虚拟机对应信息。
- nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
- nova-compute从对应的消息队列中获取虚拟机信息消息。
- nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
- glance-api向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机镜像信息(URL)。
- nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
- neutron-server向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机网络信息。
- nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
- cinder-api向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机持久化存储信息。
- nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
keystone 组件
- keystone 中的概念
- User —— 使用 OpenStack Service 的的对象被称为用户,这里的用户可以是人、服务、系统。
- Role —— 用来划分权限。给User指定Role的过程,就是给User指定权限的过程。可以简单理解为公司内部职位和职员的关系。公司职员在不同的岗位有不同的权限。在OpenStack中,Keystone返回给User的Token中包含了Role列表,被访问的Service会判断访问它的User和User提供的Token中的Role。系统默认使用 Role 是 admin(管理) 和 _member_(成员) 。
- Project (Tenant)—— 可以理解为一个人或者服务所拥有的资源集合。一个Project中可以包含多个User, 每一个User都可以根据分配的权限来使用Project中的资源。比如使用Nova创建的虚拟机要被指定到某个Project中,Cinder创建的卷也要指定到某个Project中,User访问Project中的资源前,需要先与Project关联,并指定User在Project中的Role。
- Policy —— Openstack对User的验证除了身份验证,还需要鉴别 User 对某个Service是否有访问权限。Policy用来定义什么角色对应什么权限。对Keystone来说,Policy其实是一个JSON文件,默认是 /etc/keystone/policy.json 。通过Policy,Keystone实现了对User的权限管理。
- Token —— 令牌,使用一个字符串表示。Token中包含了在指定的范围和指定的时间内可以被访问的资源。Token一般被用户持有。
- Credentials —— 用于确认用户身份的凭证。
- Authentication —— 确定用户身份的过程。
- Service —— 指Openstack中运行的组件服务。
- EndPoint —— 一个可以通过网络来访问和定位某个OpenStack Service的地址,通常表现为一个URL。EndPoint 分三种:
- Admin Url —— 供admin用户使用,Port:35357
- Internal Url —— OpenStack 内部服务使用,Port: 5000
- Public Url —— 供其他用户使用,Port: 5000
需要注意的是,虽然这里分了三种 URL, 在使用 EndPoint 访问的时候,用户的权限是和URL无关的,用户的权限只和 Role 有关,和用户访问哪一个URL无关。




cinder主要组成及其功能:
Cinder-api 是 cinder 服务的 endpoint,提供 rest 接口,负责处理 client 请求,并将 RPC 请求发送至 cinder-scheduler 组件。
Cinder-scheduler 负责 cinder 请求调度,其核心部分就是 scheduler_driver, 作为 scheduler manager 的 driver,负责 cinder-volume 具体的调度处理,发送 cinder RPC 请求到选择的 cinder-volume。
Cinder-volume 负责具体的 volume 请求处理,由不同后端存储提供 volume 存储空间。目前各大存储厂商已经积极地将存储产品的 driver 贡献到 cinder 社区

openstack组件间通过调用各组件api提供的rest接口来实现通信,组件内通信则基于rpc(远程过程调用)机制,而rpc机制是基于AMQP模型实现的。
从rpc使用的角度出发,nova,neutron,和cinder的流程是相似的,我们以cinder为例阐述rpc机制。
Openstack 组件内部的 RPC(Remote Producer Call)机制的实现是基于 AMQP(Advanced Message Queuing Protocol)作为通讯模型,从而满足组件内部的松耦合性。AMQP 是用于异步消息通讯的消息中间件协议,AMQP 模型有四个重要的角色:
Exchange:根据 Routing key 转发消息到对应的 Message Queue 中
Routing key:用于 Exchange 判断哪些消息需要发送对应的 Message Queue
Publisher:消息发送者,将消息发送的 Exchange 并指明 Routing Key,以便 Message Queue 可以正确的收到消息
Consumer:消息接受者,从 Message Queue 获取消息
消息发布者 Publisher 将 Message 发送给 Exchange 并且说明 Routing Key。Exchange 负责根据 Message 的 Routing Key 进行路由,将 Message 正确地转发给相应的 Message Queue。监听在 Message Queue 上的 Consumer 将会从 Queue 中读取消息。
Routing Key 是 Exchange 转发信息的依据,因此每个消息都有一个 Routing Key 表明可以接受消息的目的地址,而每个 Message Queue 都可以通过将自己想要接收的 Routing Key 告诉 Exchange 进行 binding,这样 Exchange 就可以将消息正确地转发给相应的 Message Queue。
Publisher可以分为4类:
Direct Publisher发送点对点的消息;
Topic Publisher采用“发布——订阅”模式发送消息;
Fanout Publisher发送广播消息的发送;
Notify Publisher同Topic Publisher,发送 Notification 相关的消息。
Exchange可以分为3类:
1.Direct Exchange根据Routing Key进行精确匹配,只有对应的 Message Queue 会接受到消息;
2.Topic Exchange根据Routing Key进行模式匹配,只要符合模式匹配的Message Queue都会收到消息;
3.Fanout Exchange将消息转发给所有绑定的Message Queue。
AMQP消息模型

RPC 发送请求
Client 端发送 RPC 请求由 publisher 发送消息并声明消息地址,consumer 接收消息并进行消息处理,如果需要消息应答则返回处理请求的结果消息。
OpenStack RPC 模块提供了 rpc.call,rpc.cast, rpc.fanout_cast 三种 RPC 调用方法,发送和接收 RPC 请求。
1.rpc.call 发送 RPC 请求并返回请求处理结果,请求处理流程如图 5 所示,由 Topic Publisher 发送消息,Topic Exchange 根据消息地址进行消息转发至对应的 Message Queue 中,Topic Consumer 监听 Message Queue,发现需要处理的消息则进行消息处理,并由 Direct Publisher 将请求处理结果消息,请求发送方创建 Direct Consumer 监听消息的返回结果
2.rpc.cast 发送 RPC 请求无返回,请求处理流程如图 6 所示,与 rpc.call 不同之处在于,不需要请求处理结果的返回,因此没有 Direct Publisher 和 Direct Consumer 处理。
3.rpc.fanout_cast 用于发送 RPC 广播信息无返回结果

nova-api 接收rest请求
nova-scheduler 负责调度
nova-compute 负责调用虚拟化驱动,建立虚拟机等
nova-conductor 帮助nova-compute 访问数据库,并将查询结果返回给nova-compute
Neutron
在网络这一块,OpenStack经历了由nova-network(早期)到Quantum(F版本)再到Neutron(H版本)的演进过程。
流程图:

neutron-server 接到请求 --> 将请求发送到MQ --> neotron-plugins 得到请求 --> 发送请求到MQ --> neotron-agent 建立网络设备。
neutron包含组件及功能介绍:
neutron-server :对外提供rest api,接收请求 并将请求分发到不同的 neutron-plugin 上。
neutron-plugin : 处理 Neutron Server 发来的请求,维护 OpenStack 逻辑网络的状态, 并调用 Agent 处理请求。每个厂商基于Openstack开发了模拟自己硬件的软件,这个软件就是plugin。 在早期,每个厂商开发各自的plugin,功能也是各自实现,有大量的代码是重复的;另外,不同的厂商有不同的开发标准,导致程序的兼容性很差。针对这种情况neutron-plugin 被分为了两部分:Core-plugin 和 Service-plugin 。
- Core-plugin : Neutron中即为ML2(Modular Layer 2),负责管理L2的网络连接。ML2中主要包括network、subnet、port三类核心资源,对三类资源进行操作的REST API被neutron-server看作Core API,由Neutron原生支持。其中:
- Network : 代表一个隔离的二层网段,是为创建他的租户而保留的一个广播域。Subnet 和 Port 始终被分配给某个特定的network。 Network 的类型包括Flat、Vlan、VxLan、Gre等等
- Subnet:代表一个IPv4/v6的CIDR地址池,以及与其相关的配置,如网关、DNS等等,该 Subnet 中的 VM 实例随后会自动继承该配置。Subnet 必须关联一个 Network。
- Port:代表虚拟交换机上的一个虚拟交换端口。VM 的网卡连接 VIF 连接Port后,就会拥有 MAC 地址和 IP 地址,Port 的 IP 地址是从Subnet 地址池中分配的。
- Service-plugin : 即为除core-plugin以外其它的plugin,包括l3 router、firewall、loadbalancer、VPN、metering等等,主要实现L3-L7的网络服务。这些plugin要操作的资源比较丰富,对这些资源进行操作的REST API被neutron-server看作Extension API,需要厂家自行进行扩展。
neutron-agent : 处理 Plugin 的请求,负责在 network provider 上真正实现各种网络功能。和 plugin 是一一对应的关系,
在架构设计上, Neutron沿用了OpenStack完全分布式的思想,各组件之间通过消息机制进行通信,使得Neutron中各个组件甚至各个进程都可以运行在任意的节点上,如前面的流程图所示。这种微内核的架构使得开发者可以集中精力在网络业务的实现上。目前Neutron提供了众多的插件与驱动,基本上可以满足各种部署的需要,如果这些还难以支撑实际所需的环境,则可以方便地在Neutron的框架下扩展插件或驱动。
Neutron对Quantum的插件机制进行了优化,将各个厂商L2插件中独立的数据库实现提取出来,作为公共的ML2插件存储租户的业务需求,使得厂商可以专注于L2设备驱动的实现,而ML2作为总控可以协调多厂商L2设备共同运行”。在Quantum中,厂家都是开发各自的Service-plugin,不能兼容而且开发重复度很高,于是在Neutron中就为设计了ML2机制,使得各厂家的L2插件完全变成了可插拔的,方便了L2中network资源扩展与使用。
ML2作为L2的总控,其实现包括Type和Mechanism两部分,每部分又分为Manager和Driver。Type指的是L2网络的类型(如Flat、VLAN、VxLAN等),与厂家实现无关。Mechanism则是各个厂家自己设备机制的实现,如下图所示。当然有ML2,对应的就可以有ML3,不过在Neutron中L3的实现只负责路由的功能,传统路由器中的其他功能(如Firewalls、LB、VPN)都被独立出来实现了,因此暂时还没有看到对ML3的实际需求。

一般而言,neutron-server和各neutron-plugin部署在控制节点或者网络节点上,而neutron agent则部署在网络节点上和计算节点上。我们先来简单地分析控制端neutron-server和neutron-plugin的工作,然后再分析设备端neutron-agent的工作。
(注意,以前厂商开发的L2 plugin跟ML2都存在于neutron/plugins目录下,而可插拔的ML2设备驱动则存在于neutron/plugins/ml2/drivers目录下)
控制端的实现 —— 从neutron-server的启动开始说起。neutron-server时,主要就干了两件事,第一是启动wsgi服务器监听Neutron REST API,第二是启动rpc服务,用于core plugin与agent间的通信,两类服务作为绿色线程并发运行。从SDN的角度来看,wsgi负责Neutron的北向接口,而Neutron的南向通信机制主要依赖于rpc来实现(当然,不同厂家的plugin可能有其它的南向通信机制)。
- 北向方面,Neutron的wsgi通过Paste工具进行模板化部署,它接收Neutron REST API的业务请求,然后通过APIRouter将其分发给对应的plugin。
- Neutron内部,plugin与数据库交互,获取业务的全局参数,然后通过rpc机制将操作与参数传给设备上的Agent(某些plugin和ML2 Mechanism Driver通过别的方式与Agent通信,比如REST API、NETCONF等)。
- RPC机制就可以理解为Neutron的南向通信机制,Neutron的RPC实现基于AMPQ模型,plugins和agents之间通常采用“发布——订阅”模式传递消息,agents收到相应plugins的***NotifyApi后,会回调设备本地的***CallBack来操作设备,完成业务的底层部署。
设备端的实现 —— 控制端neutron-server通过wsgi接收北向REST API请求,neutron-plugin通过rpc与设备端进行南向通信。设备端agent则向上通过rpc与控制端进行通信,向下则直接在本地对网络设备进行配置。
OSI七层:



| 层 | 数据单元 | 典型设备 | 功能 |
|---|---|---|---|
| 应用层 | 数据 | 计算机:应用程序 | 直接和应用程序连接并提供常见的网络应用服务 |
| 表示层 | 数据 | 计算机:编码方式 | 将数据按照网络能理解的方案进行格式化 |
| 会话层 | 数据 | 计算机:建立会话 | 负责在网络中的两节点之间建立、维持和终止通信 |
| 传输层 | 数据段 | 计算机:进程和端口 | 提供端到端的交换数据的机制,检查分组编号与次序 |
| 网络层 | 数据包 | 网络:路由器 | 将网络地址转化为对应的物理地址,并且决定如何将数据从发送方传到接收方 |
| 数据链路层 | 数据帧 | 网络:交换机、网桥 | 控制物理层和网络层之间的通讯 |
| 物理层 | 比特 | 网络:集线器、网线 | 产生并检测电压,以便发送和接收携带数据的信号,提供为建立、维护和拆除物理链路所需要的机械的、电气的、功能的和规程的特性 |
应用层:就是应用软件使用的协议,如邮箱使用的POP3,SMTP、远程登录使用的Telnet、获取IP地址的DHCP、域名解析的DNS、网页浏览的http协议等;这部分协议主要是规定应用软件如何去进行通信的。
表示层:决定数据的展现(编码)形式,如同一部电影可以采样、量化、编码为RMVB、AVI,一张图片能够是JPEG、BMP、PNG等。
会话层:为两端通信实体建立连接(会话),中间有认证鉴权以及检查点记录(供会话意外中断的时候可以继续,类似断点续传)。
传输层:将一个数据/文件斩件分成很多小段,标记顺序以被对端接收后可以按顺序重组数据,另外标记该应用程序使用的端口号及提供QOS。(不同的应用程序使用不同计算机的端口号,同样的应用程序需要使用一样的端口号才能正常通信)
网络层:路由选路,选择本次通信使用的协议(http、ftp等),指定路由策略及访问控制策略。(IP地址在这一层)
数据链路层:根据端口与MAC地址,做分组(VLAN)隔离、端口安全、访问控制。(MAC地址在这一层)处理VLAN内的数据帧转发,跨VLAN间的访问,需要上升到网络层。
物理层:将数据最终编码为用0、1表示的比特流,然后传输。
网络模式
根据创建网络的用户的权限,Neutron network 可以分为:
-
Provider network:管理员创建的和物理网络有直接映射关系的虚拟网络。
-
Tenant network:租户普通用户创建的网络,物理网络对创建者透明,其配置由 Neutorn 根据管理员在系统中的配置决定
根据网络的类型,Neutron network 可以分为:Local、Flat / Flat Dhcp 、VLan 、Gre 、VxLan
1. Local —— 所有的组件全部安装在一台机器上,多用于测试环境。
2. Flat / Flat Dhcp —— Flat模型最为简单,所有的虚拟机共用一个私有IP网段,IP地址在虚拟机启动时完成注入,虚拟机间的通信直接通过HyperVisor中的网桥转发,公网流量在该网段的网关上进行NAT(Nova-network实现为开启nova-network主机内核的iptables,Neutron实现为网络节点上的l3-agent)。Flat DHCP模型与Flat区别在于网桥中开启了DHCP进程,虚拟机通过DHCP消息获得IP地址(Nova-network实现为nova-network主机中的dnsmaq,Neutron实现为网络节点上的dhcp-agent)。
优点:结构简单,稳定
缺点:全部租户都在一个水平面上,租户之间没有隔离,因为全部租户都在一个子网内,当大规模部署后,其广播风暴将会是不小的负面因素。

3. VLan
LAN 表示 Local Area Network,本地局域网,通常使用 Hub 和 Switch 来连接LAN 中的计算机。一般来说,当你将两台计算机连入同一个 Hub 或者 Switch 时,它们就在同一个 LAN 中。同样地,你连接两个 Switch 的话,它们也在一个 LAN 中。一个 LAN 表示一个广播域,它的意思是,LAN 中的所有成员都会收到 LAN 中一个成员发出的广播包。可见,LAN 的边界在路由器或者类似的3层设备。
VLAN 表示 Virutal LAN。一个带有 VLAN 功能的switch 能够同时处于多个 LAN 中。最简单地说,VLAN 是一种将一个交换机分成多个交换机的一种方法。比方说,你有两组机器,group A 和 B,你想配置成组 A 中的机器可以相互访问,B 中的机器也可以相互访问,但是A组中的机器不能访问B组中的机器。你可以使用两个交换机,两个组分别接到一个交换机。如果你只有一个交换机,你可以使用 VLAN 达到同样的效果。你在交换机上分配配置连接组A和B的机器的端口为 VLAN access ports。这个交换机就会只在同一个 VLAN 的端口之间转发包。
带 VLAN 的交换机的端口分为两类:
-
- Access port:这些端口被打上了 VLAN Tag。离开交换机的 Access port 进入计算机的以太帧中没有 VLAN Tag,这意味着连接到 access ports 的机器不会觉察到 VLAN 的存在。离开计算机进入这些端口的数据帧被打上了 VLAN Tag。
- Trunk port: 有多个交换机时,组A中的部分机器连接到 switch 1,另一部分机器连接到 switch 2。要使得这些机器能够相互访问,你需要连接两台交换机。 要避免使用一根电缆连接每个 VLAN 的两个端口,我们可以在每个交换机上配置一个 VLAN trunk port。Trunk port 发出和收到的数据包都带有 VLAN header,该 header 表明了该数据包属于那个 VLAN。因此,只需要分别连接两个交换机的一个 trunk port 就可以转发所有的数据包了。通常来讲,只使用 trunk port 连接两个交换机,而不是用来连接机器和交换机,因为机器不想看到它们收到的数据包带有 VLAN Header。

一个计算节点上的网络实例
它反映的网络配置如下:
- Neutron 使用 Open vSiwtch —— OVS。
- 一台物理服务器,网卡 eth1 接入物理交换机,预先配置了网桥 br-eth1。
- 创建了两个 neutron VLAN network,分别使用 VLAN ID 101 和 102。
- 该服务器上运行三个虚机,虚机1 和 2 分别有一个网卡接入 network 1;虚机2 和 3 分别有一个网卡接入 network 2.

Neutron 在该计算节点上做的事情:
- 创建了 OVS Integration bridge br-int。它的四个 Access 端口中,两个打上了内部 Tag 1,连接接入 network 1 的两个网卡;另两个端口的 VLAN Tag 为 2。
- 创建了一对 patch port,连接 br-int 和 br-eth1。
- 设置 br-int 中的 flow rules。对从 access ports 进入的数据帧,加上相应的 VLAN Tag,转发到 patch port;从 patch port 进入的数据帧,将 VLAN ID 101 修改为 1, 102 修改为 2,再转发到相应的 Access ports。
- 设置 br-eth1 中的 flow rules。从 patch port 进入的数据帧,将内部 VLAN ID 1 修改为 101,内部 VLAN ID 2 修改为 102,再从 eth1 端口发出。对从 eth1 进入的数据帧做相反的处理。

优点:租户有隔离
缺点: 1. VLAN 使用 12-bit 的 VLAN ID,所以 VLAN 的第一个不足之处就是它最多只支持 4096 个 VLAN 网络(当然这还要除去几个预留的),对于大型数据中心的来说,这个数量是远远不够的。
2. VLAN 是基于 L2 的,所以很难跨越 L2 的边界,在很大程度上限制了网络的灵活性。
- 3. VLAN 操作需手工介入较多,这对于管理成千上万台机器的管理员来说是难以接受的。
更多具体内容参考:
http://www.cnblogs.com/sammyliu/p/4626419.html
gre与vxlan请参考
http://www.cnblogs.com/sammyliu/p/4622563.html
http://www.cnblogs.com/xingyun/p/4620727.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号