


一:构建模版参数categories:
1:了解前端需要的格式:
categories = {
"1":{
"channels":[
{"id":1, "name":"手机", "url":"http://shouji.jd.com/"},
{"id":2, "name":"相机", "url":"http://www.itcast.cn/"}
],
"sub_cats":[
{
"id":38,
"name":"手机通讯",
"sub_cats":[
{"id":115, "name":"手机"},
{"id":116, "name":"游戏手机"}
]
},
{
"id":39,
"name":"手机配件",
"sub_cats":[
{"id":119, "name":"手机壳"},
{"id":120, "name":"贴膜"}
]
}
]
},
"2":{
"channels":[],
"sub_cats":[]
}
}
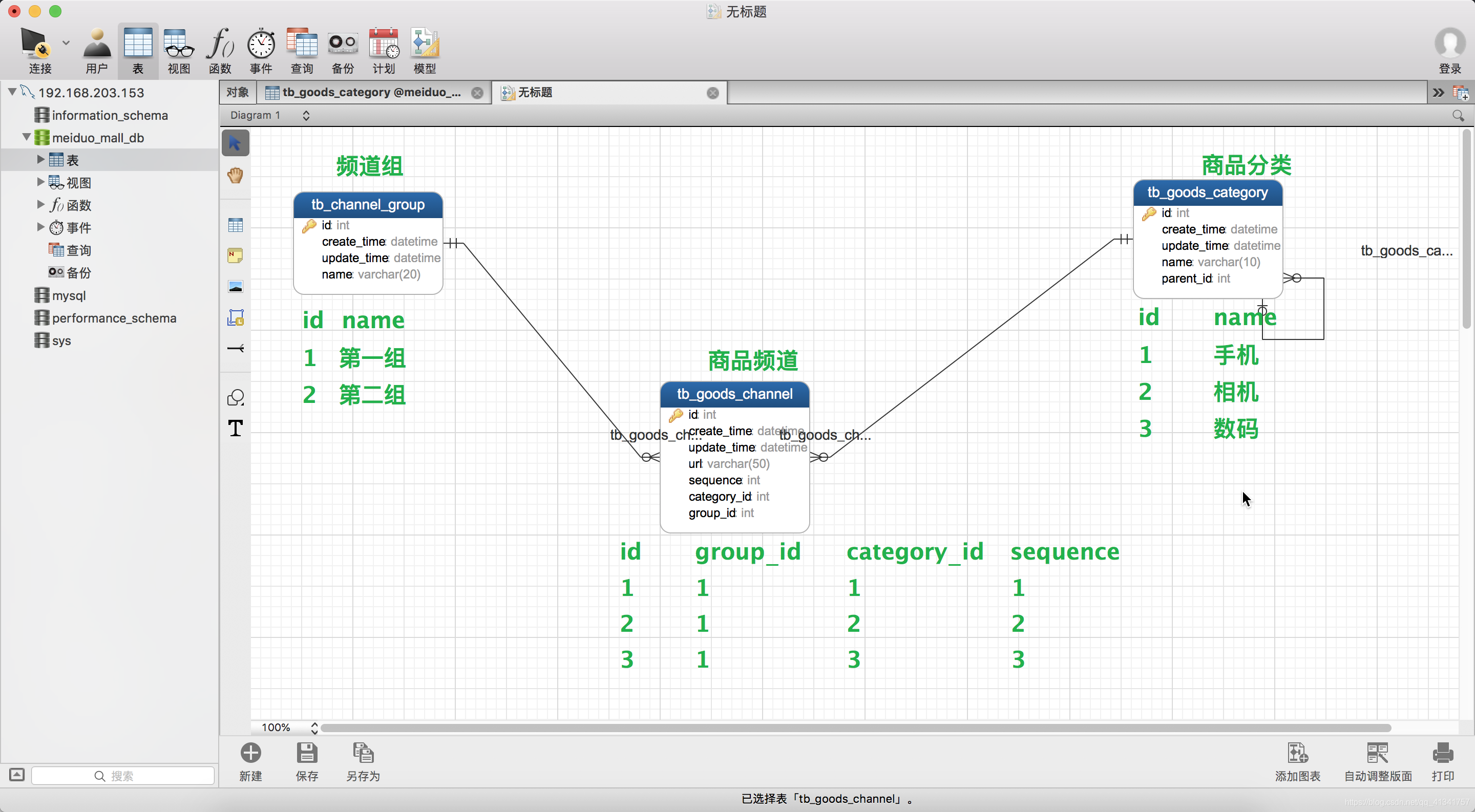
2:apps.contents.crons中定义get_categories函数。
def get_categories():
# 模版参数categories是首页分类频道,里面包含所有频道数据以及商品分类的信息
# 1:首先分析前段页面最外层是个字典数据,所以先定义一个字典,以后向里面增加数据。
categories = {}
# 获取首页所有的分类频道数据
# 获取商品频道集
# 先按频道组分类,如果频道相同,就按照sequence(商品分类所在频道组的位置)分类
channels = GoodsChannel.objects.order_by(
'group_id',
'sequence'
)
# 遍历所有的商品频道,构建以组号作为key的键值对 channels :商品频道集 channel:某个商品频道
for channel in channels:
# channel: GoodsChannel对象
# 如果该商品频道的频道组没有在(最外层)频道字典中
if channel.group_id not in categories:
# 将这个频道的频道组id,作为频道字典的一个键
categories[channel.group_id] = {
'channels': [], # 当前分组中的分类频道(一级分类)
'sub_cats': [] # 二级分类
}
# (1)、填充当前组中的一级分类
# 某个商品频道的category属性获的商品分类对象:例如 : 手机 数码等
cat1 = channel.category
# 给一级分类追加数据
categories[channel.group_id]['channels'].append({
'id': cat1.id,
'name': cat1.name,
'url': channel.url
})
# (2)、填充当前组中的二级分类
# 商品分类表对象获得二级商品分类(父亲是一级商品分类的)
cat2s = GoodsCategory.objects.filter(parent=cat1)
for cat2 in cat2s:
# cat2:二级分类对象
cat3_list = [] # 每一次遍历到一个二级分类对象的时候,初始化一个空列表,用来构建三级分类
cat3s = GoodsCategory.objects.filter(parent=cat2)
# (3)、填充当前组中的三级分类
for cat3 in cat3s:
# cat3;三级分类对象
cat3_list.append({
'id': cat3.id,
'name': cat3.name
})
#将三级分类列表加入二级分类中
categories[channel.group_id]['sub_cats'].append({
'id': cat2.id,
'name': cat2.name,
'sub_cats': cat3_list # 三级分类
})
return categories
3:三级之间的关系图片:

二:构建模板参数:
1:前端需要的格式:
contents = {
"index_lbt": [
<Content模型类对象>,
...
],
"index_1f_ssxp": [
<Content模型类对象>,
...
]
}
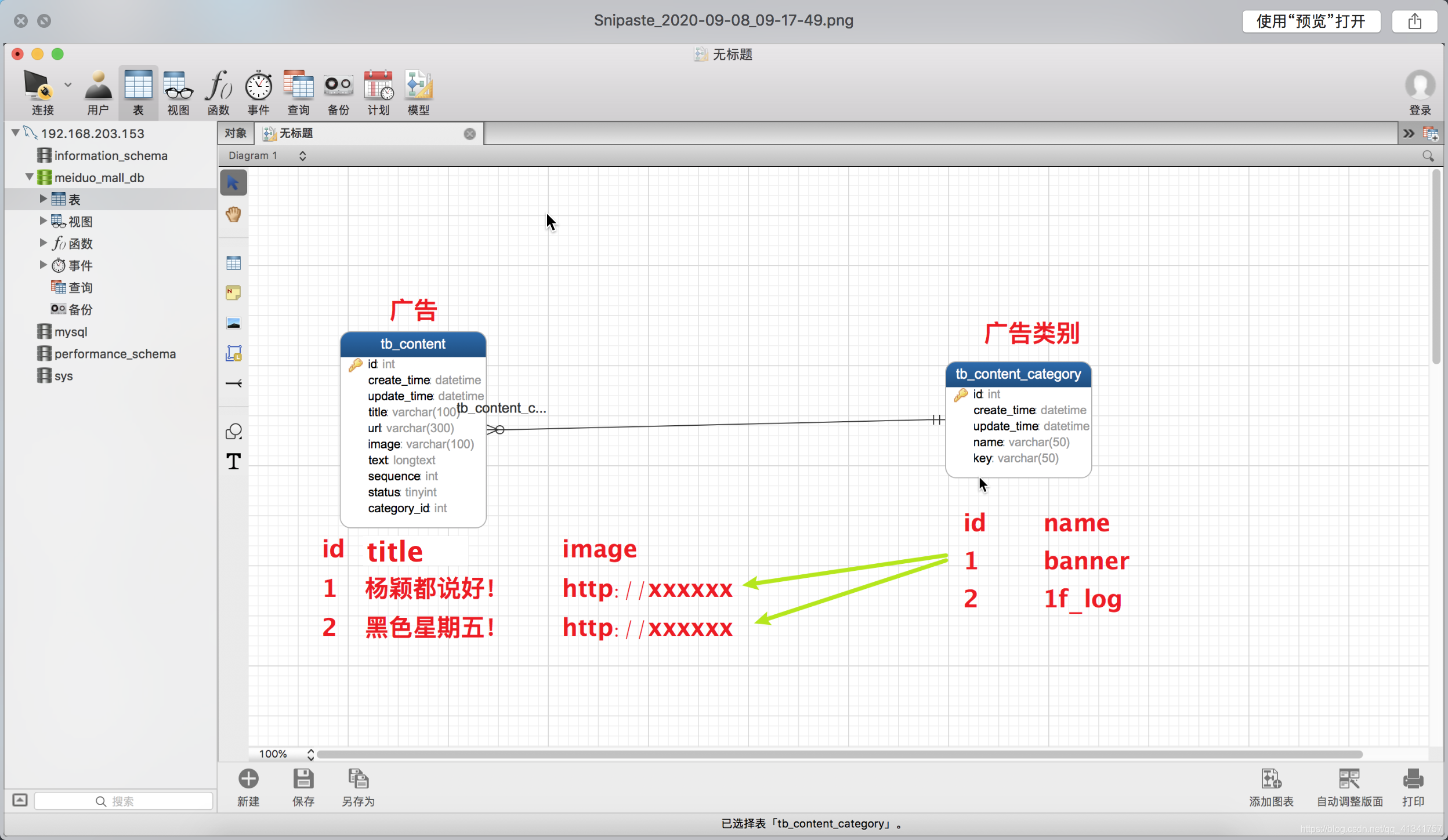
2:apps.contents.crons中定义get_contents函数。
def get_contents():
contents = {}
# 所有广告分类
# 用广告分类表对象获取所有的广告分类
content_cats = ContentCategory.objects.all()
# 遍历所有的广告分类,获取其中一个广告分类。
for content_cat in content_cats:
# content_cat: 每一个分类如:轮播图
# 当前广告分类关联的所有广告加入列表中
# contents['index_lbt'] = [<美图M8s>, <黑色星期五>...]
# 广告分类表中有个key字段,这个字段表示是哪个广告分类。
contents[content_cat.key] = Content.objects.filter(
#广告表中的category_id等于广告分类表的id
category=content_cat,
status=True # 正在展示的广告
).order_by('sequence')
return contents
3:两个表关系示例图:
三:路径的修改:
问题:下面代码中写入的路径是我的电脑的路径,这样一旦移动到别人电脑就不能用了,所以要拼接路径。
def generate_static_index_html():
# 获取分类频道
categories = get_categories()
contents = get_contents()
# 1:构建首页模板文件对象
template = loader.get_template("index.html")
# 2:构造动态数据
content = {
"categories": categories,
"contents": contents,
}
# 3:渲染完整的页面数据
page = template.render(content)
# 4:写入静态web服务器
with open("/home/python/Desktop/meimei_project/front_end_pc/front_end_pc/index.html", "w") as f:
f.write(page)
3.1:修改配置文件dev.py:
# 静态文件路径:
# 基础路径向上两层:就是我们的meimei_project路径,然后拼接上front_end_pc就是我们静态文件路径。
STATIC_FILE_PATH = os.path.join(
os.path.dirname(os.path.dirname(BASE_DIR)),
'front_end_pc/front_end_pc'
)
3.2:修改apps/contents/crons.py:
file_path = os.path.join(settings.STATIC_FILE_PATH, 'index.html')
with open(file_path, "w") as f:
f.write(page)
3.3:测试:
1:cd 到外层目录
2:python manager.py shell
3:导包
>>> from apps.contents.crons import *
4:执行函数
>>> generate_static_index_html()
四:使用定时任务执行首页静态化函数:
1:安装django定时模块:
pip install django-crontab -i https://pypi.tuna.tsinghua.edu.cn/simple
2:在dev.py中注册应用:
'django_crontab',
3:在dev.py指定制定定时任务规则
# 定时任务规则:
# 五颗星分别代表 分钟,小时,日,月,年
# 前面加斜杠表示每分钟,每小时,每个月,每年
# 'apps.contents.crons.generate_static_index_html'表示定时任务函数的路径
# '>> ' + os.path.join(BASE_DIR, 'logs/crontab.log'),表示重定向到指定的日志文件。
CRONJOBS = [
# 每1分钟生成一次首页静态文件
('*/1 * * * *', 'apps.contents.crons.generate_static_index_html', '>> ' + os.path.join(BASE_DIR, 'logs/crontab.log'))
# 每月的23日12点1分0秒执行一次
# ('1 12 23 * *', 'apps.contents.crons.generate_static_index_html', '>> ' + os.path.join(BASE_DIR, 'logs/crontab.log'))
]
如果出现报错:
# 如果定时任务执行报编码错误,加入以下2项配置
# ubuntu
# CRONTAB_COMMAND_PREFIX = 'LANG_ALL=zh_cn.UTF-8'
# mac
# CRONTAB_COMMAND_PREFIX = 'LANG=zh_cn.UTF-8'
4:通过命令添加、查看和删除任务
4.1:首先 cd 到外层目录
添加任务(根据配置文件自动查找任务):python3 manage.py crontab add
查看当前活跃的任务: python3 manage.py crontab show
删除任务: python3 manage.py crontab remove
(django_env) python@ubuntu:~/Desktop/shopping-mall-project/shopping_mall$ python3 manage.py crontab add
adding cronjob: (5d142e437b77cb4ae9cf608d3aaa76cc) -> ('*/1 * * * *', 'apps.contents.crons.generate_static_index_html', '>> /home/python/Desktop/shopping-mall-project/shopping_mall/shopping_mall/logs/crontab.log')
(django_env) python@ubuntu:~/Desktop/shopping-mall-project/shopping_mall$ python3 manage.py crontab show
Currently active jobs in crontab:
5d142e437b77cb4ae9cf608d3aaa76cc -> ('*/1 * * * *', 'apps.contents.crons.generate_static_index_html', '>> /home/python/Desktop/shopping-mall-project/shopping_mall/shopping_mall/logs/crontab.log')
五:渲染SKU商品详情页静态文件:
5.1:将utils.py放入apps/goods应用目录里面。
5.2:将detail.html详情页静态化模版文件拷贝到templates模板文件夹中。
5.3:了解前端需要的模板参数:
context = {
'categories': categories, # 商品频道分类
'goods': goods, # 当前sku从属的spu
'specs': specs, # 规格和选项信息
'sku': sku # 当前sku商品对象
}
5.4:在外层目录新建scripts目录,然后在目录里面新建regenerate_detail_html.py文件。
import os
import sys
# 如果我想要在终端以脚本的方式启动这个文件,而这个脚本需要django的环境
# 1:所以需要提前加载django环境,但是有个问题,'meiduo_mall.settings.dev'这个目录默认在这个文件下找meiduo_mall
# 所以需要指定基准目录
# 以当前目录为基准找到外层目录:
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, BASE_DIR)
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'meiduo_mall.settings.dev')
# 2:手动加载django环境
import django
django.setup()
from django.template import loader
from django.conf import settings
# 需要一个参数sku_id ,也就是传入哪个sku就生成哪个商品详情页面。
def generate_static_sku_detail_html(sku_id):
# 功能:生成商品的详情页
# 1:使用get_template函数获得模板页面对象
template = loader.get_template("detail.html")
# 2:构造模板参数
context = {
"categories": None,
"goods": None,# 当前sku从属的spu
"specs": None,# 规格和选项信息
"sku": None,# 当前sku商品对象
}
# 3:使用render函数渲染模板页面
page = template.render(context)
# 4:将页面写入静态文件目录
file_path = os.path.join(
settings.STATIC_FILE_PATH,
"goods/%d.html" % sku_id,
)
with open(file_path, "w") as f:
f.write(page)
if __name__ == '__main__':
generate_static_sku_detail_html(1)
然后执行指令:
(django_env) python@ubuntu:~/Desktop/meimei_project/meiduo_mall/scripts$ python3 regenerate_detail_html.py
发现重新生成模板文件,此时还没有填充内容。
# 如果我想要在终端以脚本的方式启动这个文件,而这个脚本需要django的环境
# 1:所以需要提前加载django环境,但是有个问题,'meiduo_mall.settings.dev'这个目录默认在这个文件下找meiduo_mall
# 所以需要指定基准目录
# 以当前目录为基准找到外层目录:
import os, sys
from django.template import loader
# /Users/weiwei/Desktop/meiduo_mall_sz39/meiduo_mall/
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, BASE_DIR)
# 由于当前脚本依赖django环境,所以需要提前加载django环境
# 1、设置django环境变量指定配置文件路径
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'meiduo_mall.settings.dev')
# 2、手动加载Django环境
import django
django.setup()
from django.conf import settings
from apps.goods.utils import *
def generate_static_sku_detail_html(sku_id):
categories = get_categories()
goods, sku, specs = get_goods_and_spec(sku_id)
# 1:使用get_template函数获取模板页面对象
template = loader.get_template('detail.html')
# 2:构造动态数据
context = {
'categories': categories,
'goods': goods, # 当前sku从属的spu
'specs': specs, # 规格和选项信息
'sku': sku # 当前sku商品对象
}
# 3:渲染页面
page = template.render(context)
# 4:将页面重新写入静态文件
# settings.STATIC_FILE_PATH --> 是front_end_pc文件夹路径
file_path = os.path.join(
settings.STATIC_FILE_PATH,
'goods/%d.html' % sku_id, # 'goods/1.html'
)
with open(file_path, 'w') as f:
f.write(page)
if __name__ == '__main__':
from apps.goods.models import SKU
# 在SKU表中查看所有没有过期的sku
skus = SKU.objects.filter(is_launched=True)
# 循环遍历skus
for sku in skus:
generate_static_sku_detail_html(sku.id)
六:执行脚本的几种方式:
6.1:指定解释器解释并运行脚本文件:
(django_env) python@ubuntu:~/Desktop/meimei_project/meiduo_mall/scripts$ python3 regenerate_detail_html.py
6.2:直接执行这个脚本文件:./regenerate_detail_html.py
1:给这个文件增加可执行权限:
2:在脚本文件开头指定解释器(脚本文件的首行#不是注释)
1:chmod +x ./regenerate_detail_html.py
2:#! /home/python/.virtualenvs/django_env/bin/python
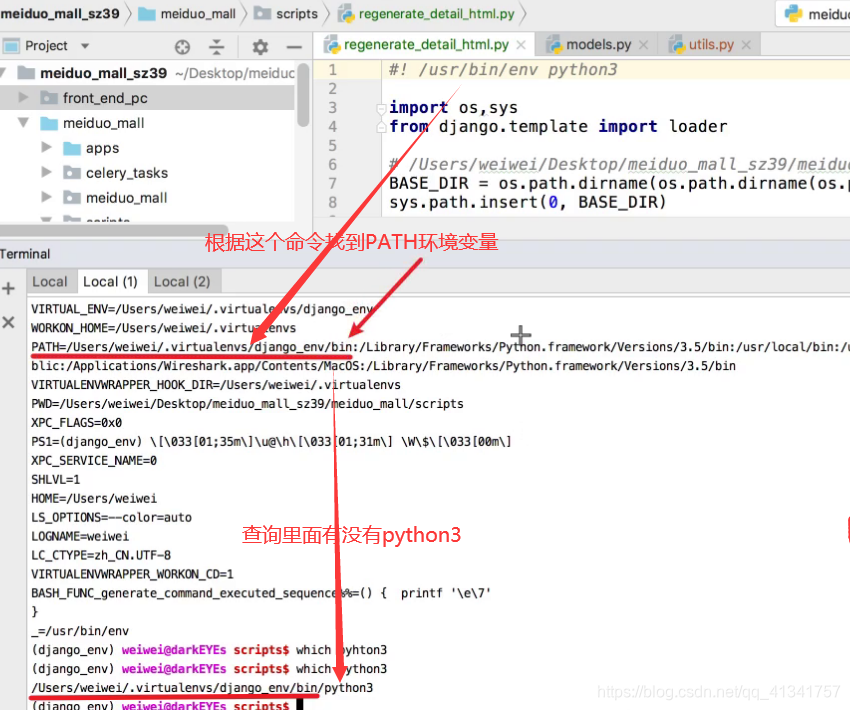
3:这个路径太麻烦,能不能让他自己推到出解释器路径呢??
注意:/user/bin/env 里面存储着path环境变量。
那么在脚本文件开头指定:
#!/user/bin/env python3
他就会自动根据这个命令找这个文件的Path ,看path中有没有python3解释器,如果有就找到了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号