


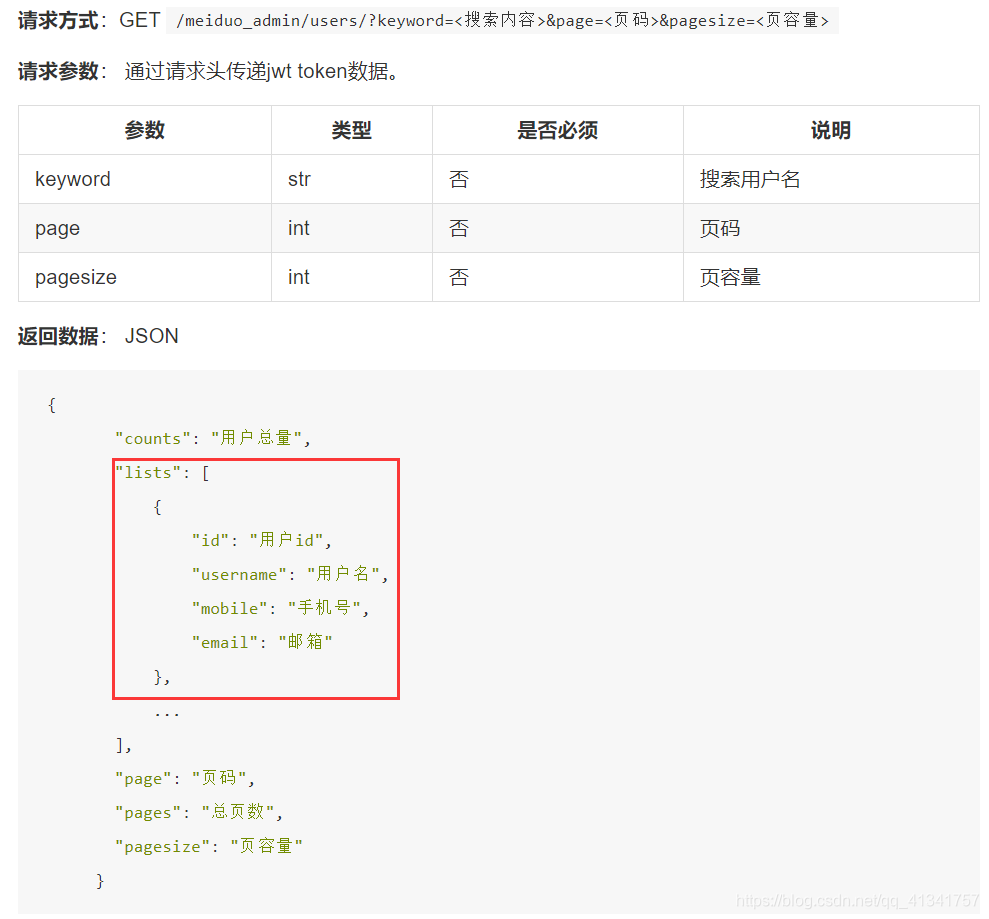
一:获取用户列表数据:
接口分析:首先,“lists”,要返回一个列表套字典的格式,需要序列化查询,所以要自定义一个序列化器。
1:定义一个序列化器:
新建并编辑apps/meiduo_admin/serializers/user_serializers.py
from rest_framework import serializers
from apps.users.models import User
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ["id", "username", "mobile", "email"]
2:定义一个视图:
新建并编辑apps/meiduo_admin/views/user_views.py
from rest_framework.generics import ListAPIView
from apps.meiduo_admin.serializers.user_serializers import UserModelSerializer
from apps.users.models import User
class UserView(ListAPIView):
queryset = User.objects.filter(is_staff=True)
serializer_class = UserModelSerializer
3:自定义分页器:
新建并编辑apps/meiduo_admin/paginations.py自定义分分页器
from rest_framework.pagination import PageNumberPagination
from rest_framework.response import Response
class MyPage(PageNumberPagination):
page_query_param = 'page' # ?page=1
page_size_query_param = 'pagesize' # ?pagesize=5
max_page_size = 10
page_size = 5
def get_paginated_response(self, data):
return Response({
'counts': self.page.paginator.count, # 总数量
'lists': data, # 查询集分页的子集(当前页数据)
'page': self.page.number, # 当前页
'pages': self.page.paginator.num_pages, # 总页数
'pagesize': self.page_size
})
在视图中指定分页器:
pagination_class = MyPage
4:对查询集进行过滤:
如果前端传入查询字符串参数keyword,那么我们要根据这个keyword进行过滤,如果前端没有传入我们要返回所有的数据。
需要提前解决的问题,我们自己定义的get_queryset()不是视图的get方法,也就是没有request参数,那么我们如何拿到我的keyword数据呢?????
答:在django/drf中,每次请求的时候,框架除了把请求对象request传入视图函数以外,还会把请求对象封装到self.request中(self指的是视图对象)。
from rest_framework.generics import ListAPIView
from apps.meiduo_admin.paginations import MyPage
from apps.meiduo_admin.serializers.user_serializers import UserModelSerializer
from apps.users.models import User
class UserView(ListAPIView):
queryset = User.objects.filter(is_staff=True)
serializer_class = UserModelSerializer
# 指定分页器
pagination_class = MyPage
def get_queryset(self):
keyword = self.request.query_params.get("keyword")
if keyword:
# 返回过滤后的数据---名字包含这个keyword的
return self.queryset.filter(username__contains=keyword)
else:
return self.queryset.all()
二:新建用户:
<一>分析:新建用户肯定是一个反序列化的过程,所以首先考虑我的当前的序列化器,能不能满足我们的反序列化呢?
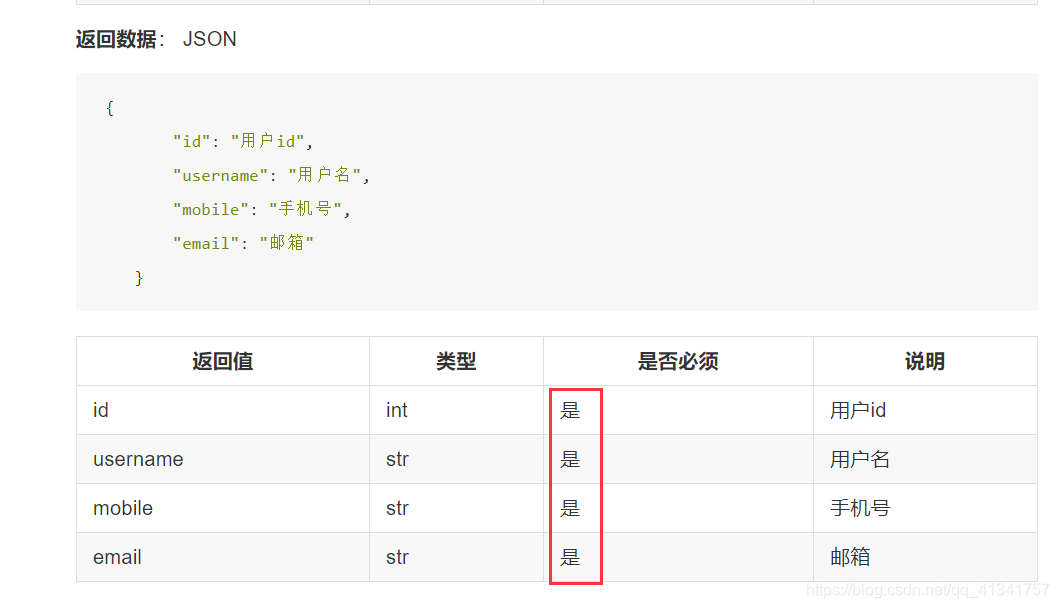
这个是当前的序列化器。
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ["id", "username", "mobile", "email"]
前端的需求:对比可以发现:id,mobile,email都需要设置必传,而 新建用户必须有密码,对于密码需要新增如fields ,并且密码只作用于反序列化。
所以:需要增加限制条件:
extra_kwargs = {
"password": {"write_only": True, "required": True},
"username": {"required": True},
"mobile": {"required": True},
"email": {"required": True}
}
<二>: 再次分析:对于前端视图,我们这个时候需要新建用户,所以要增加继承CretaeAPIView,由于之气那有一个ListAPIView,所以有一个他们的子类: ListCreateView,只需要继承这个就可以了。
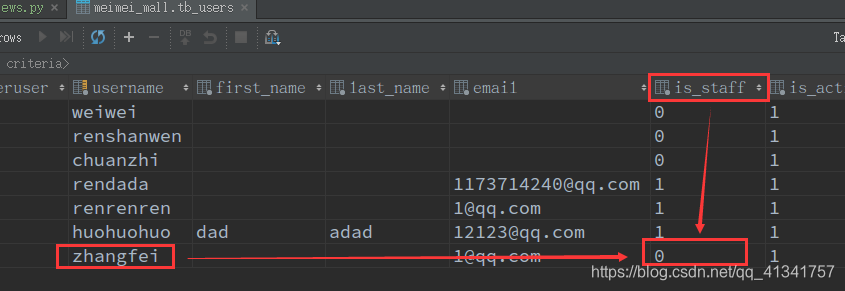
此时出现两个问题:
问题一:新建用户的密码在数据库中没有加密。
问题二:新建用户的的is_staff属性没有设置成True。
如下图:
<三>如何解决这两个问题???
分析:第一:谁负责用户密码的加密??—> 创建用户的函数—>序列化器的create方法。回顾整个反序列化的流程,我们可以发现,可以从cretae方法入手,自定义create方法。也可以在校验过程中,对有效数据中的明文密码加密,以及在返回的有效数据中添加is_staff=True —— 后续create方法完成新建对象就是使用调整之后的有效数据!
方案一:重写create方法:
一: 编辑apps/meiduo_admin/serializers/user_serializers.py
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ["id", "username", "mobile", "email", "password"]
extra_kwargs = {
"password": {"write_only": True, "required": True},
"username": {"required": True},
"mobile": {"required": True},
"email": {"required": True}
}
def create(self, validated_data):
# 原来create方法默认是false
validated_data["is_staff"] = True
return User.objects.create_user(**validated_data)

方案二:我在自定义校验的时候, 自定义validate方法,对密码进行加密,并且将is_staff设置成True。
问题:django如何对字符串进行加密的呢???
from django.contrib.auth.hashers import make_password
make_password方法进行加密
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ["id", "username", "mobile", "email", "password"]
extra_kwargs = {
"password": {"write_only": True, "required": True},
"username": {"required": True},
"mobile": {"required": True},
"email": {"required": True}
}
def validate(self, attrs):
password = attrs.pop("password")
password = make_password(password)
attrs['password'] = password
attrs['is_staff'] = True
return attrs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号