ocr 深入
第一阶段
一 OCR技术概览
基本情况
应用场景
文本识别
车牌识别
拍照搜题
自然场景文本识别
视频内容审核
内容理解
常见难点
复杂板式
扭曲形变 角度
手写干扰
光的影响 反光,弱光,摩尔纹,模糊

二值化方法
基本流程
预处理
降噪
滤波,光照处理
增强
回复拉伸
二值化
灰度图转二值图
方案
OTSU 大津二值化

MSER (MAXIMALLY STABLE EXTERMAL REGIONS)


倾斜矫正
HOUGH变换、投影法
版面分析
文本行定位
字符分割识别
后处理
事例子
1 通用文本
二值化: 彩色转灰度转黑白 只有(0,255)

连通域分析: 字符框分析
论文中找方法 子向上分析

像素值 1--> 连通域 2--> 合成文本行 3---> 文本
1 像素临近关系 四临近 八 临近
2 这步最复杂
连通域分析间的关系
MRL 左右两个像素点最近的距离
ECC 两个中心的欧式距离
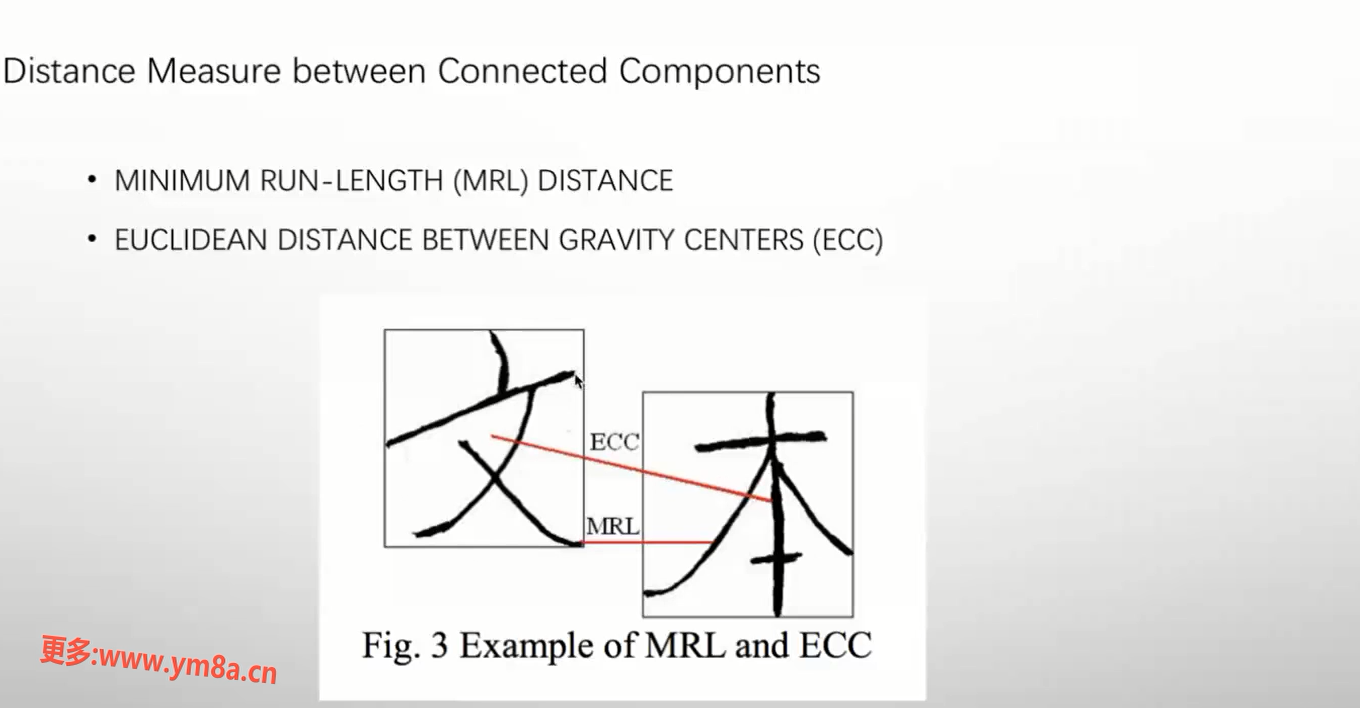
根据公式求 值,得到权重值合并文本行

得到结果

最小生成树之类的算法减去不必要的连接线

先得到行片段
计算分割点置信度,在粗分割后,递归地以置信度最大点进行分割
投影法 :有干扰额的话不能直接用

2 车牌检测与识别
竖直纹理卷积法
车牌有固定的特征 根据这些分析垂直纹理

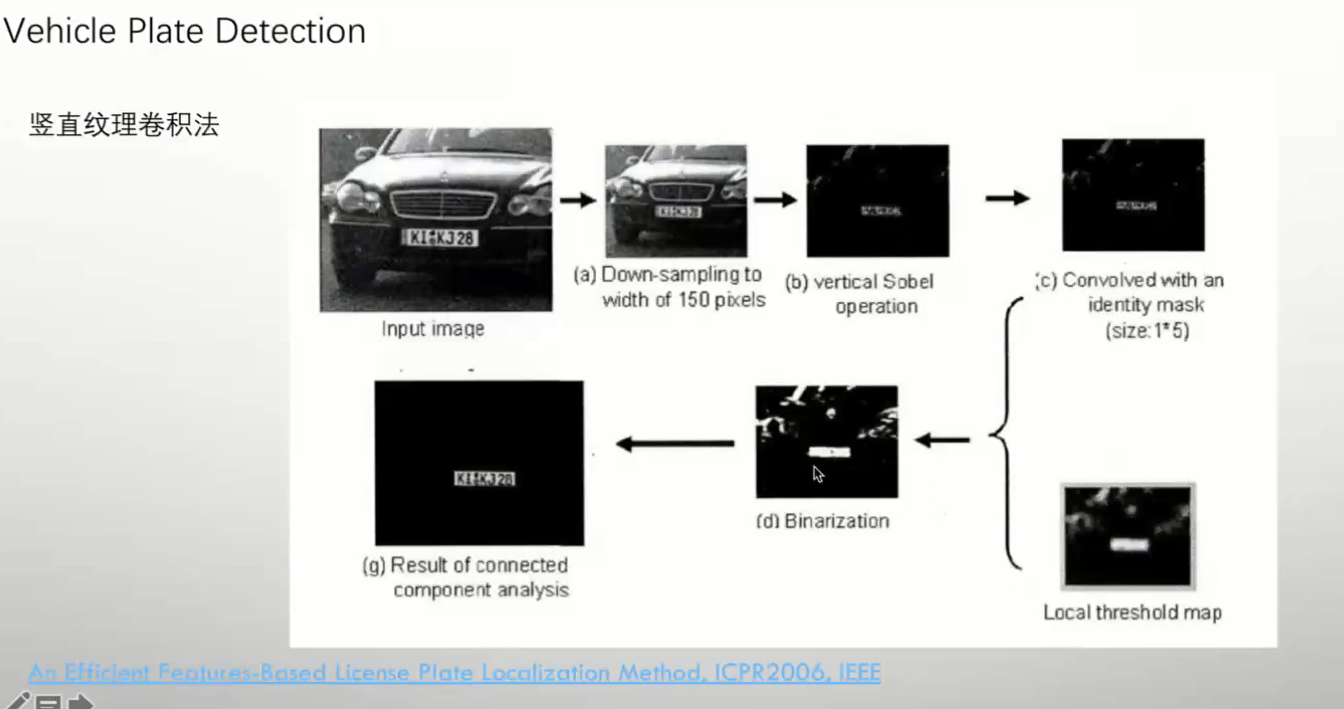
边缘信息

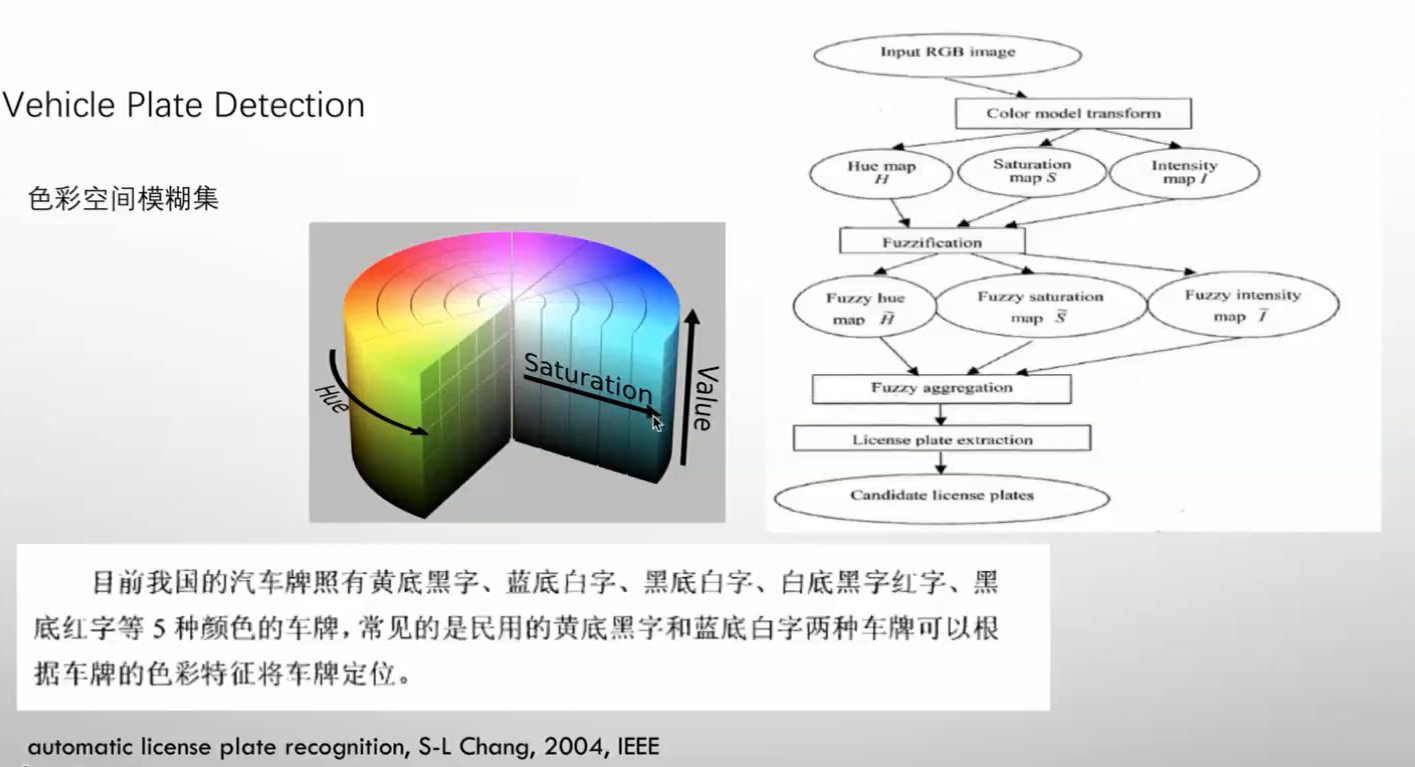
色彩收集
RGB 转HSI (剔除颜色中的一些亮度信息)
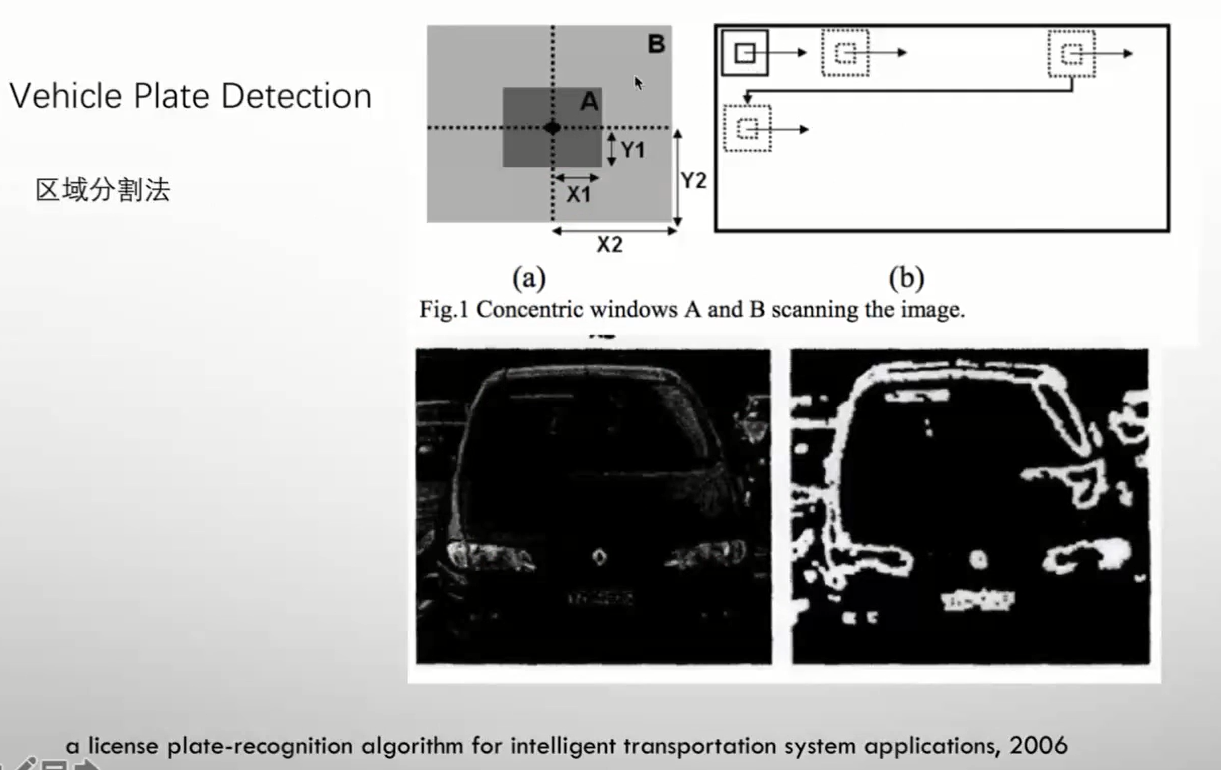
区域分割
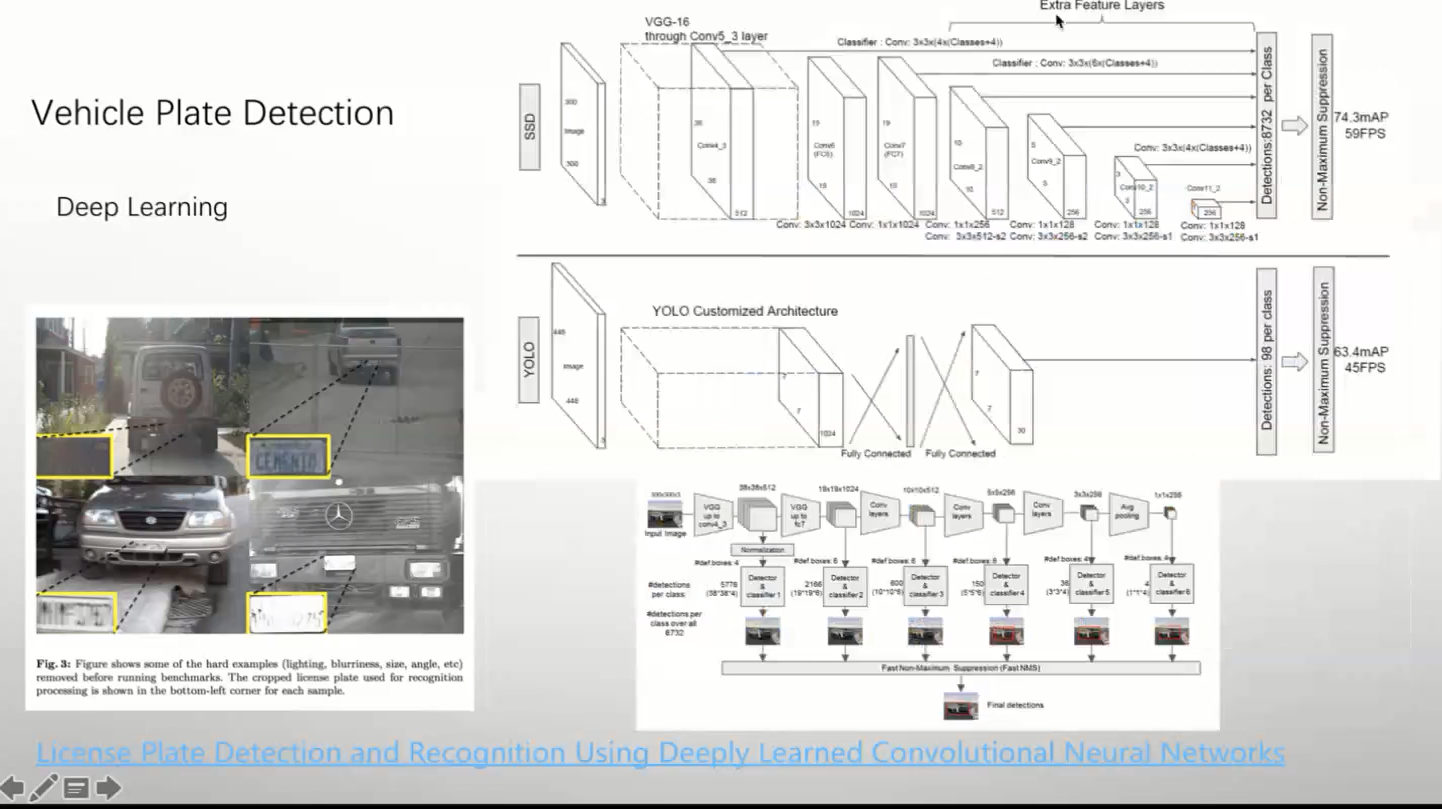
直接上模型
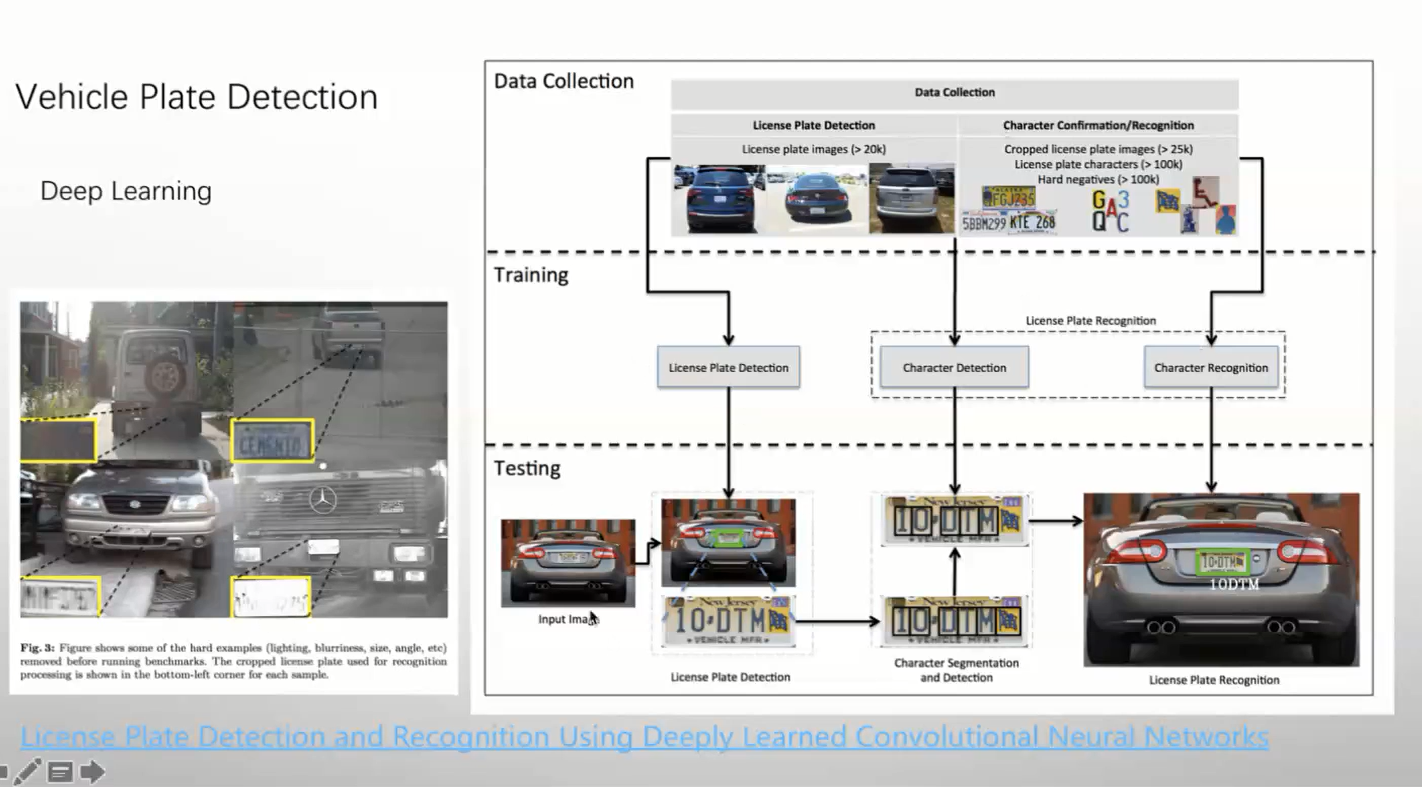
yolo
demo程序
TESSERACT OCR
二 单字符分割与识别
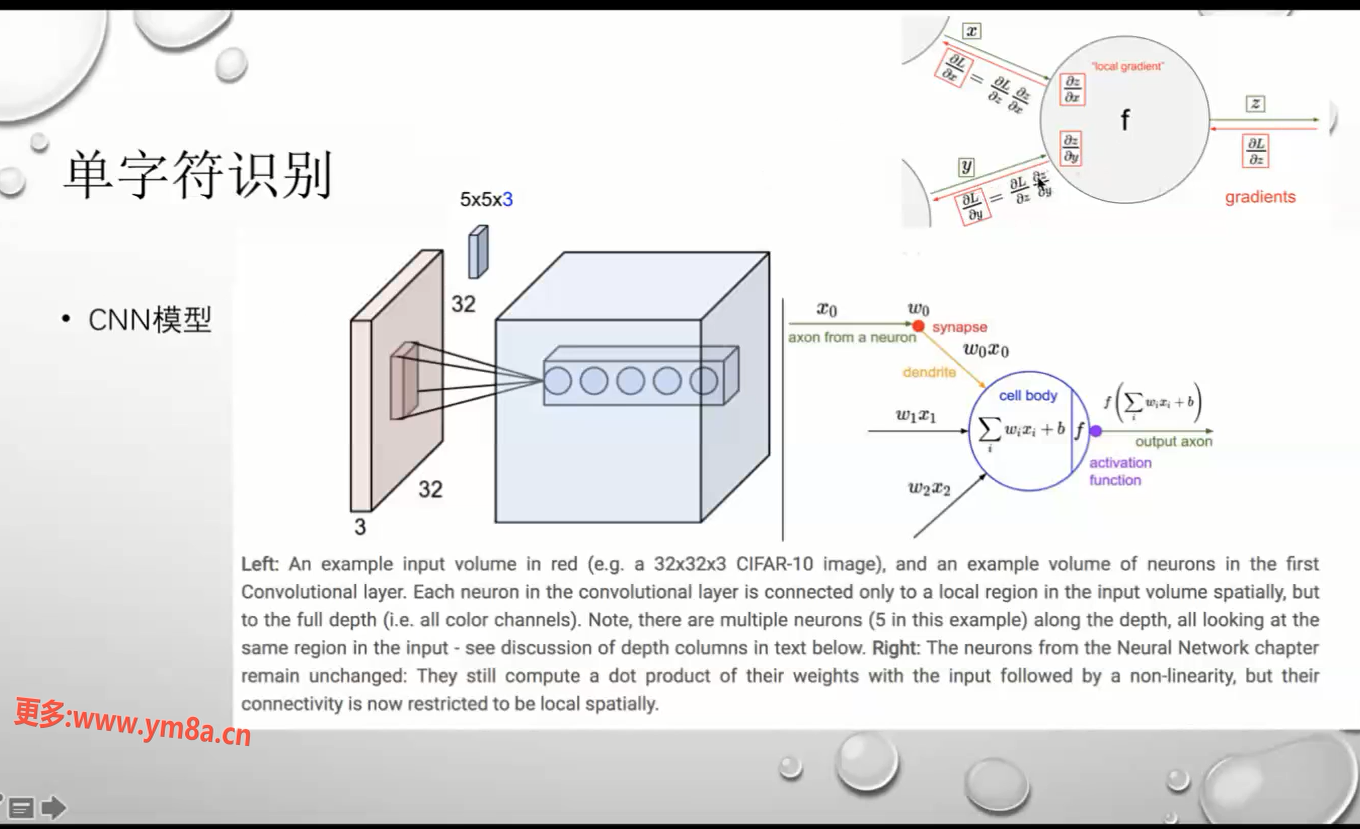
单字符识别
模板匹配

问题 计算量 图片预处理
特征提取 + 传统分类器
特征提取
位图
垂直/水平投影
孔洞/穿刺/占空比
方向/弧度
传统分类器
SVM
MLP
CNN模型 (强的一批)
过切分的路径选择
字符分割
viterbi 算法 + Beam search 离线识别
viterbi 算法 --> 动态规划算法
Beam search --> 剪枝算法去不必要的
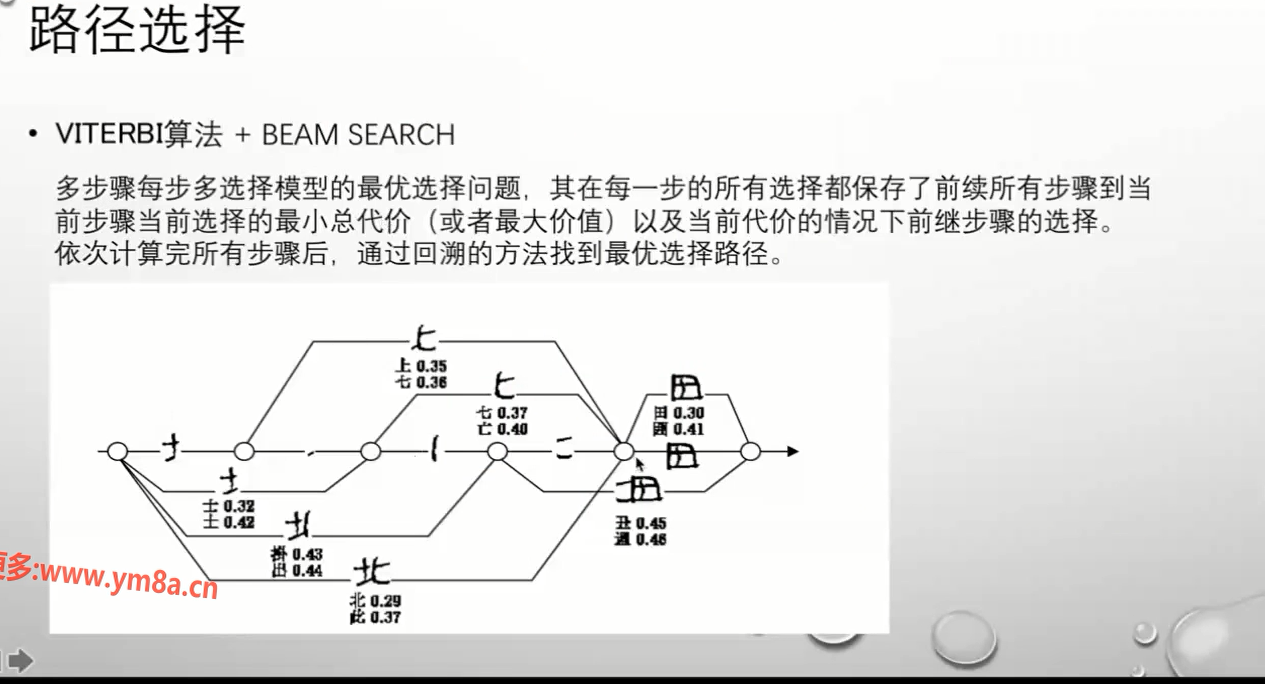
HMM+ viterbi 在线手写

语言模型
N-GRAM

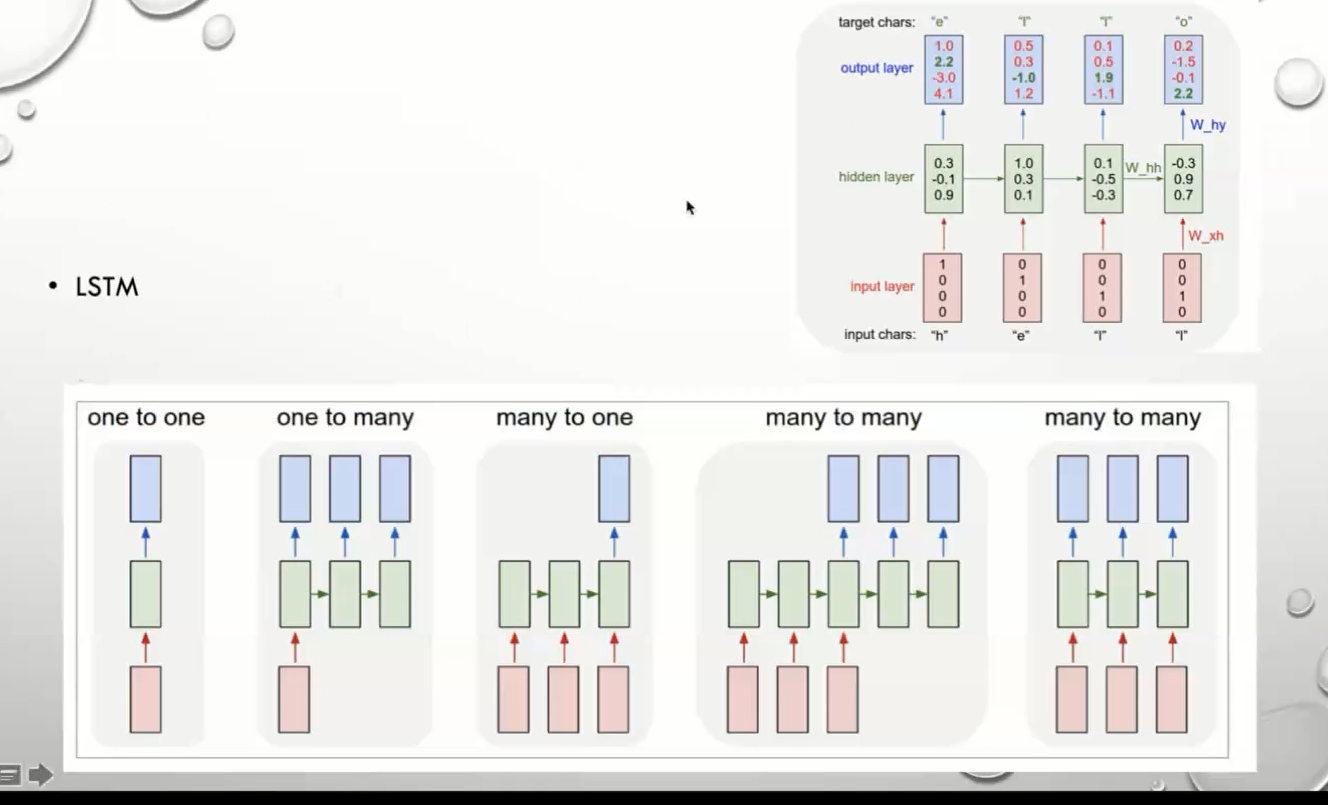
lLSTM rnn变种
记忆因子 数据关联
PCFG 带一个概率的 但没有上面用的多
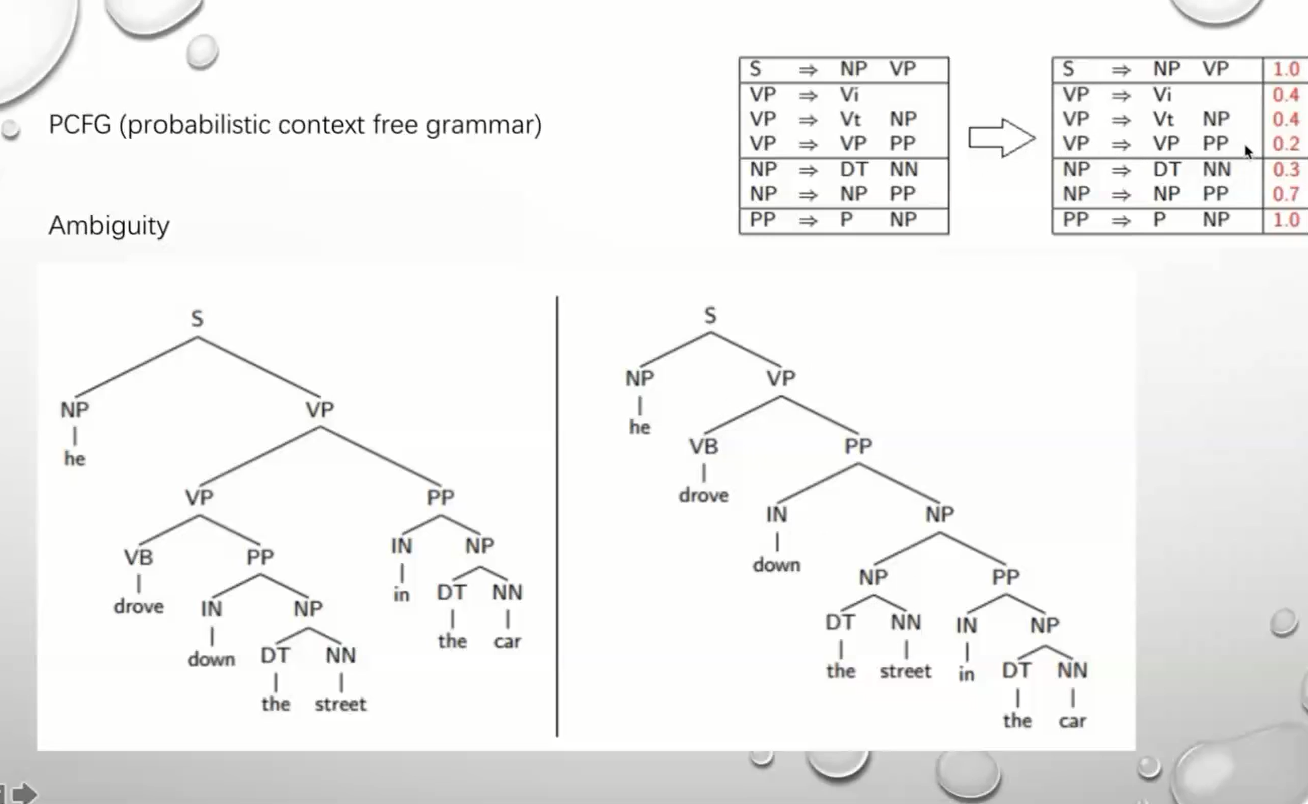
公式识别很有难度
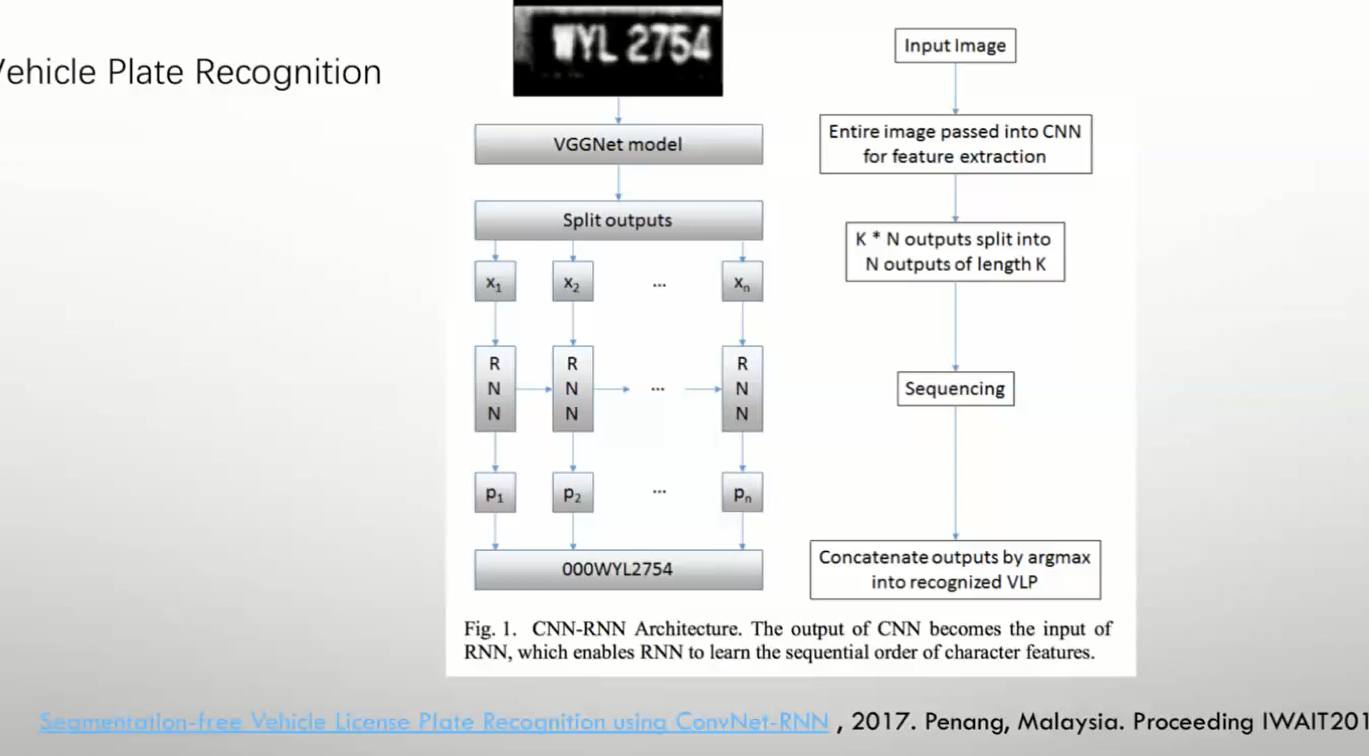
三 字符序列识别
RNN
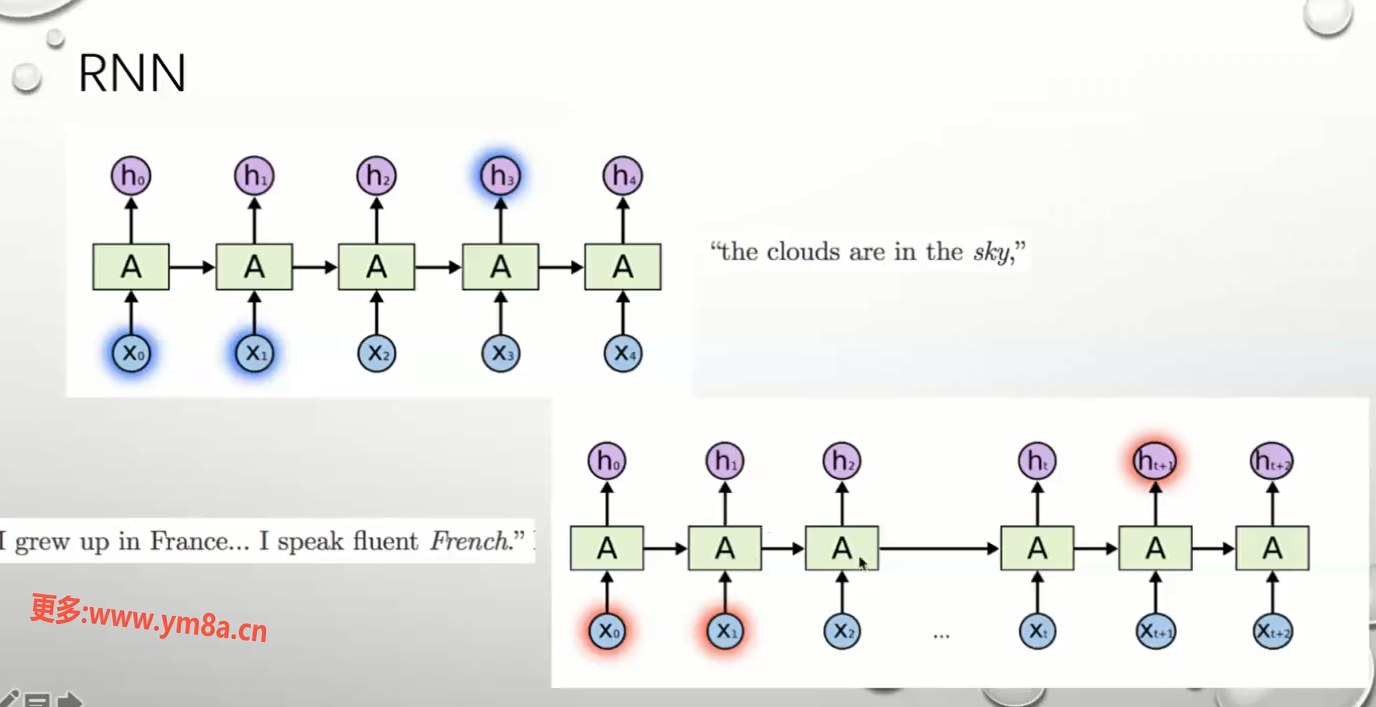
信息串联 : 存在问题 句子长的时候前面的无法传递到后面去 梯度消散
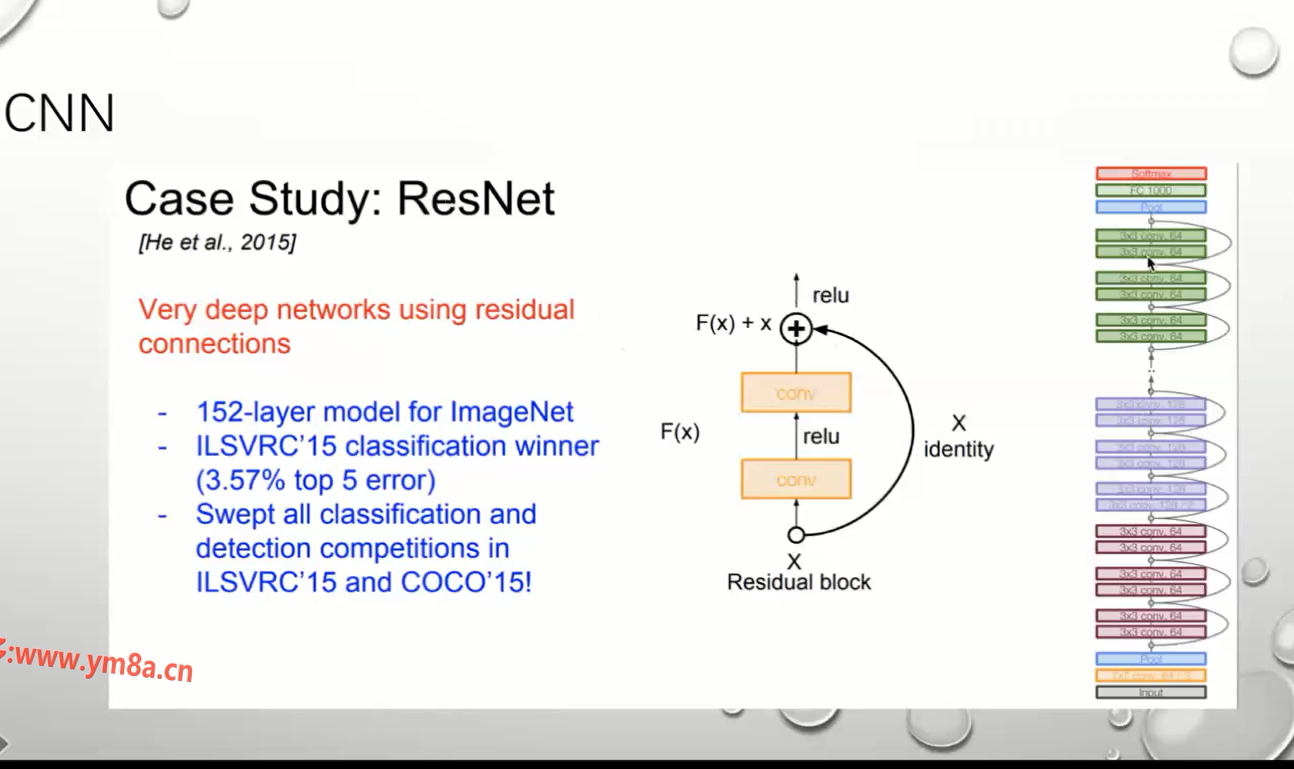
CNN 中解决梯度消散方案: ResNet 残差网络 加一个跳边
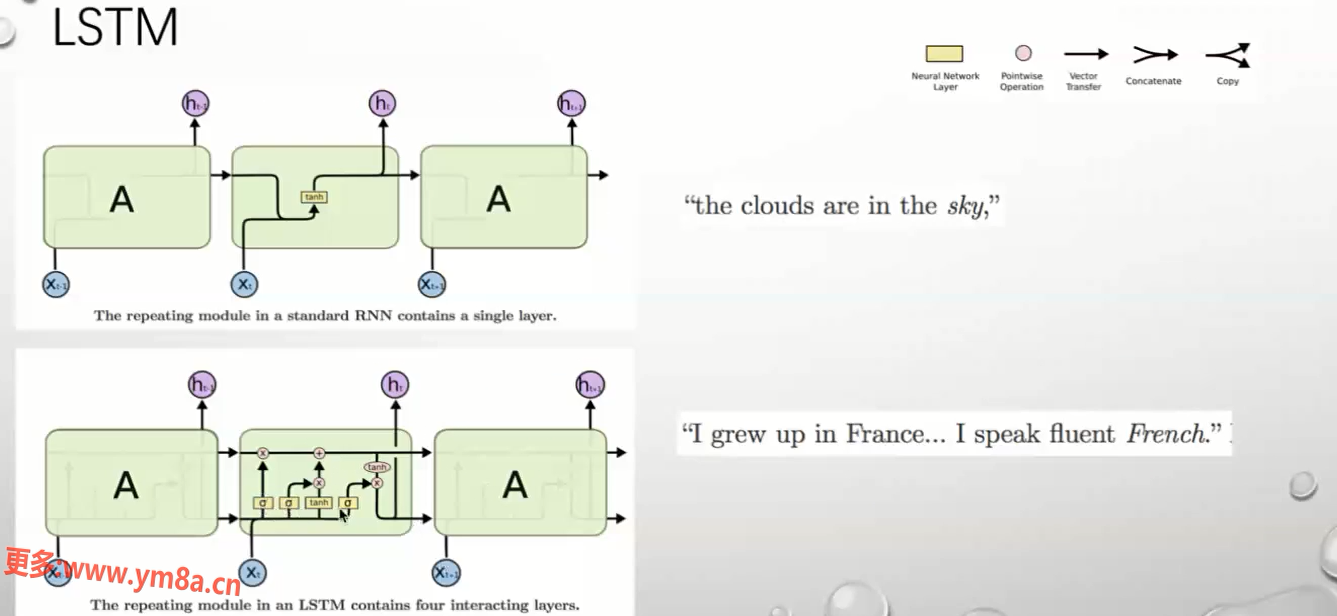
LSTM
RNN 中解决方案 LSTM 三门方案 类似加跳边 根据加门遗忘一些信息
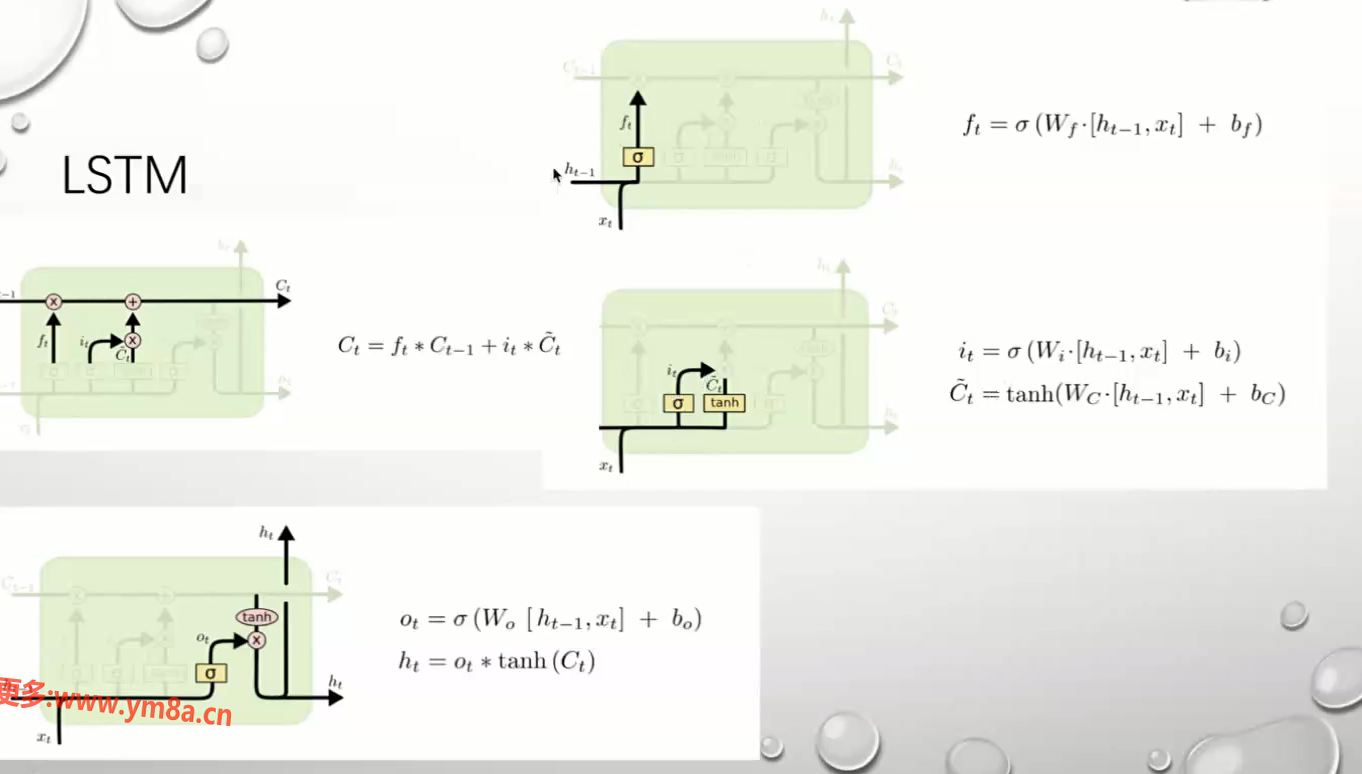
三个门,三个开关 避免梯度消散
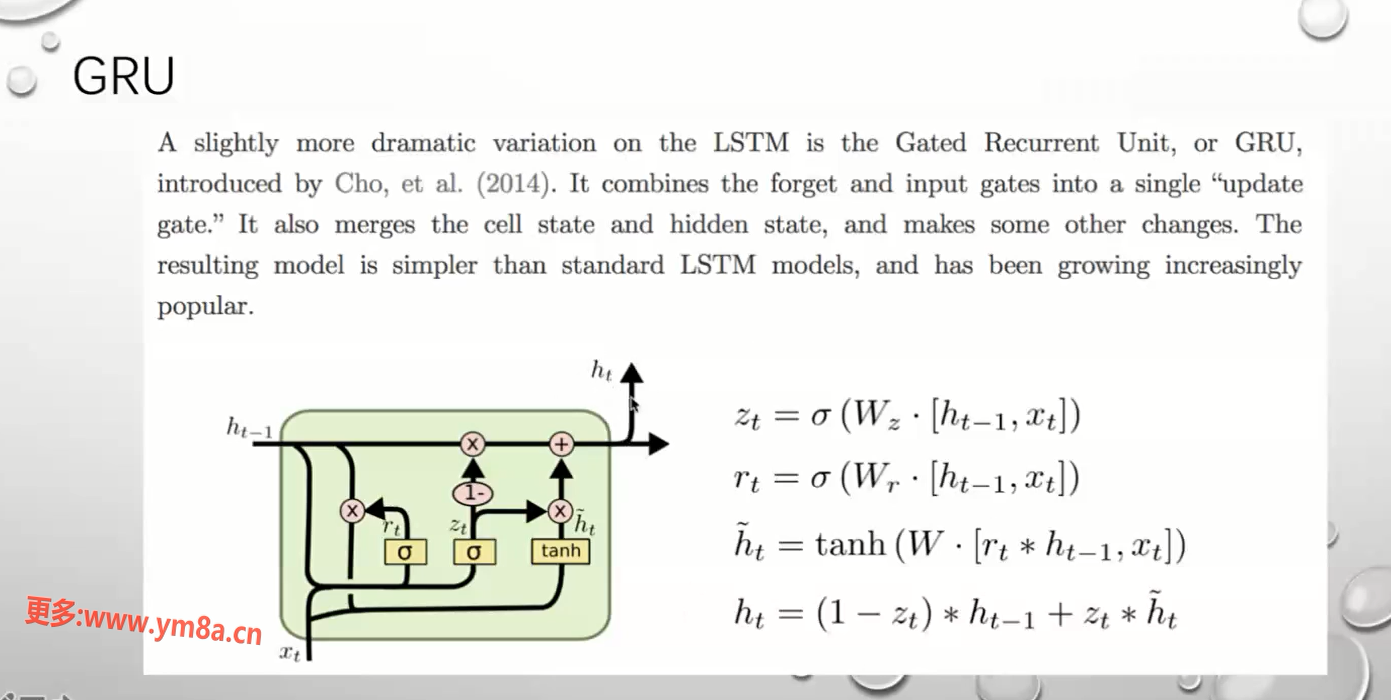
GRU
两个门 三门的简化
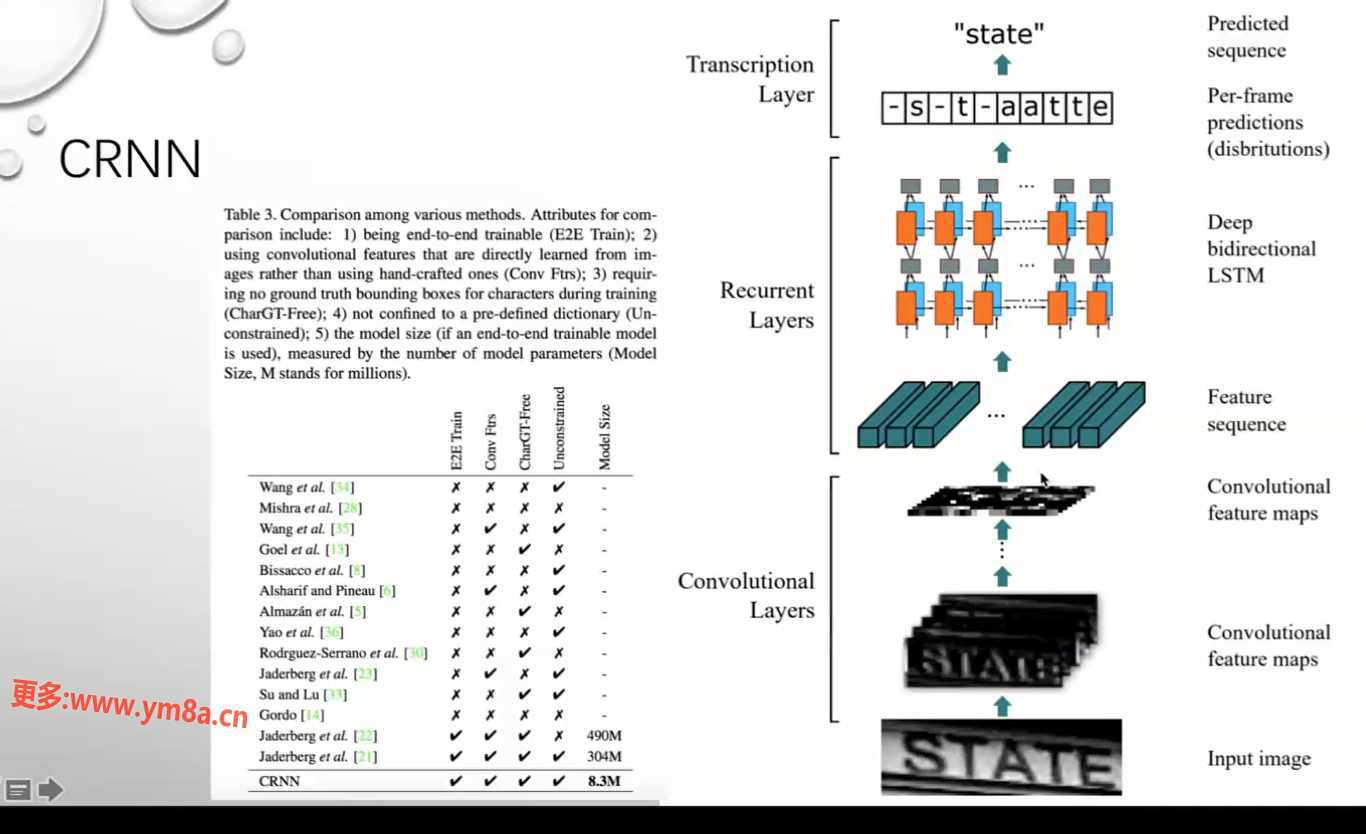
CRNN
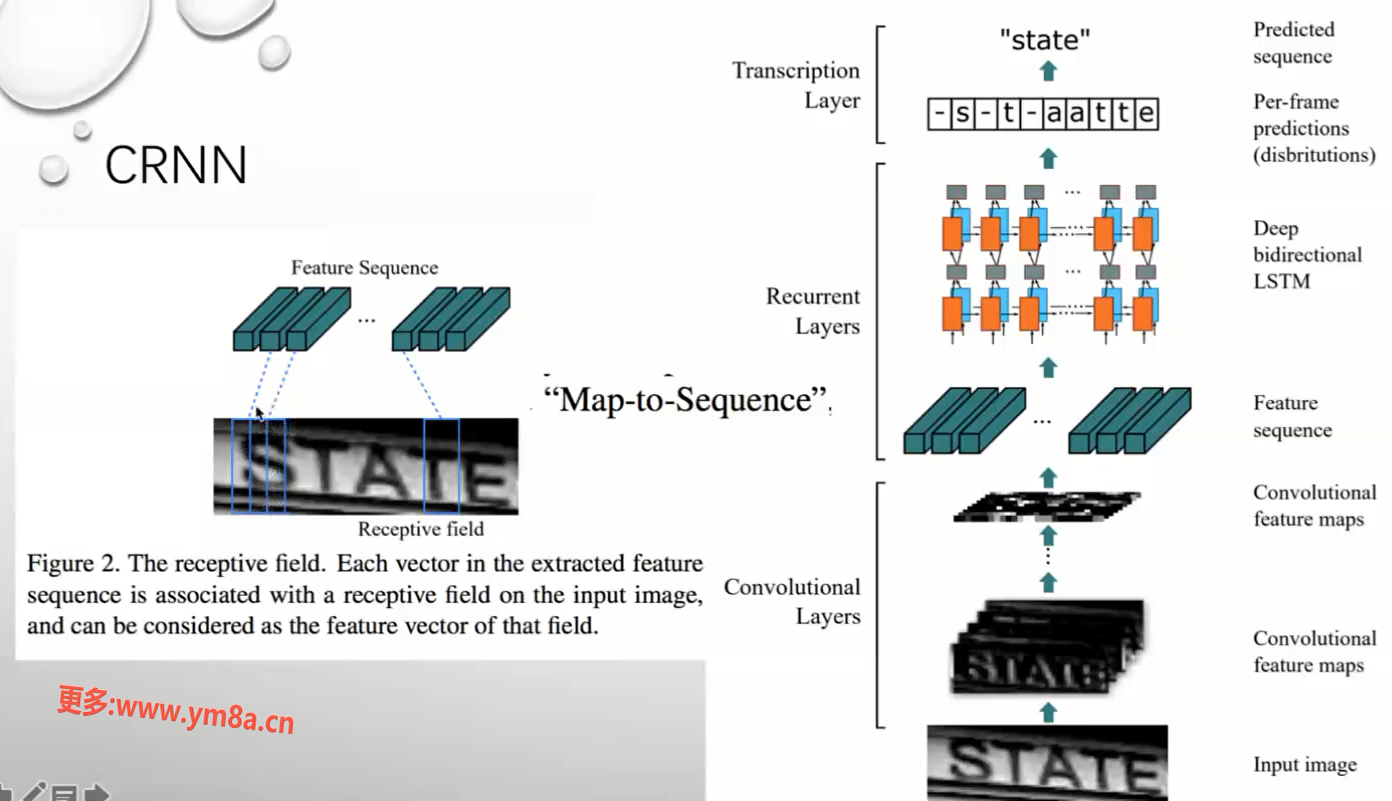
用这个结构拼贴 CNN 和RNN
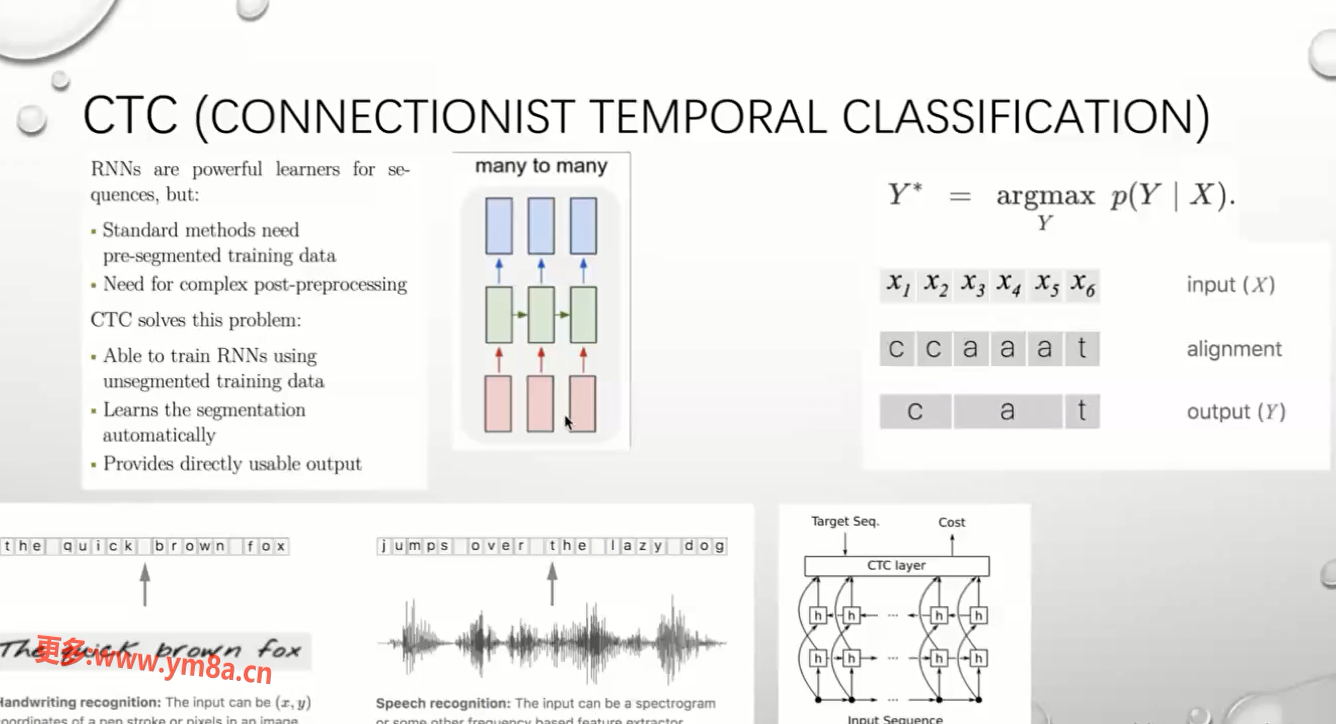
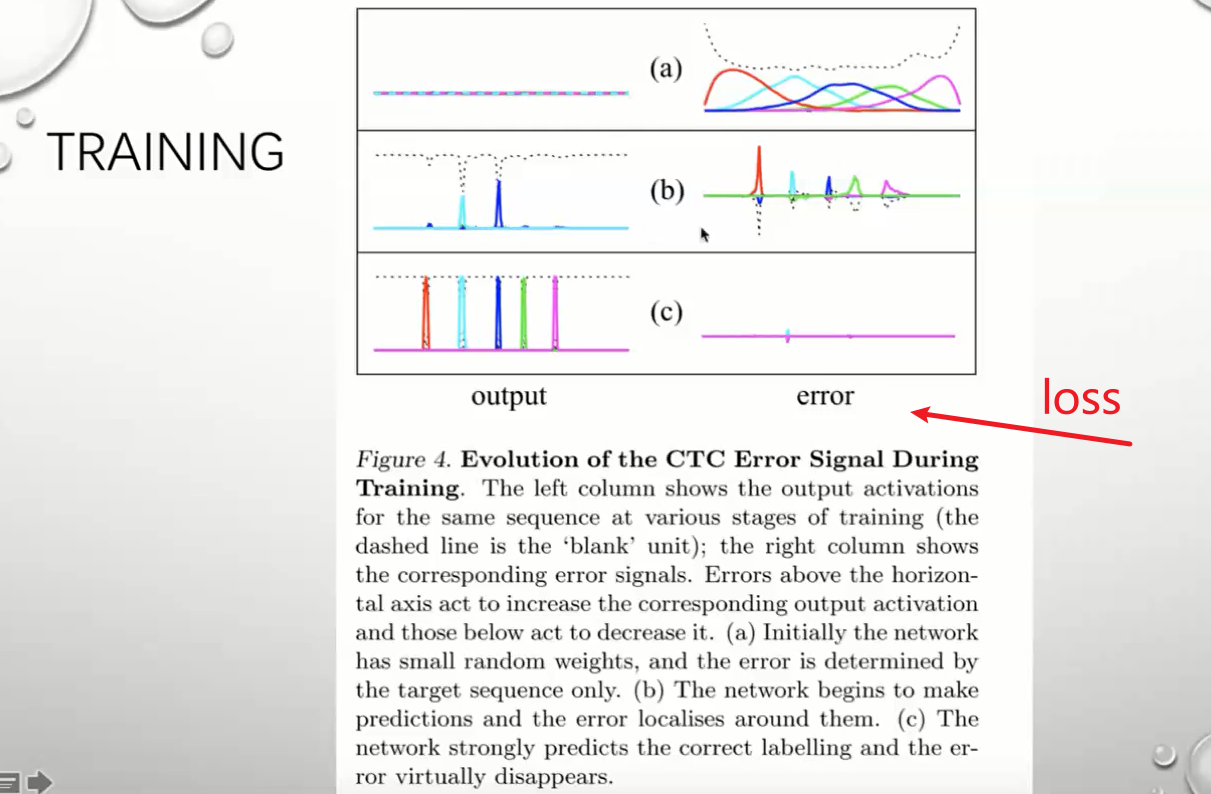
CTC
CONNECTIONIST TEMPORAL CALSSIFICATION 连接时态分类


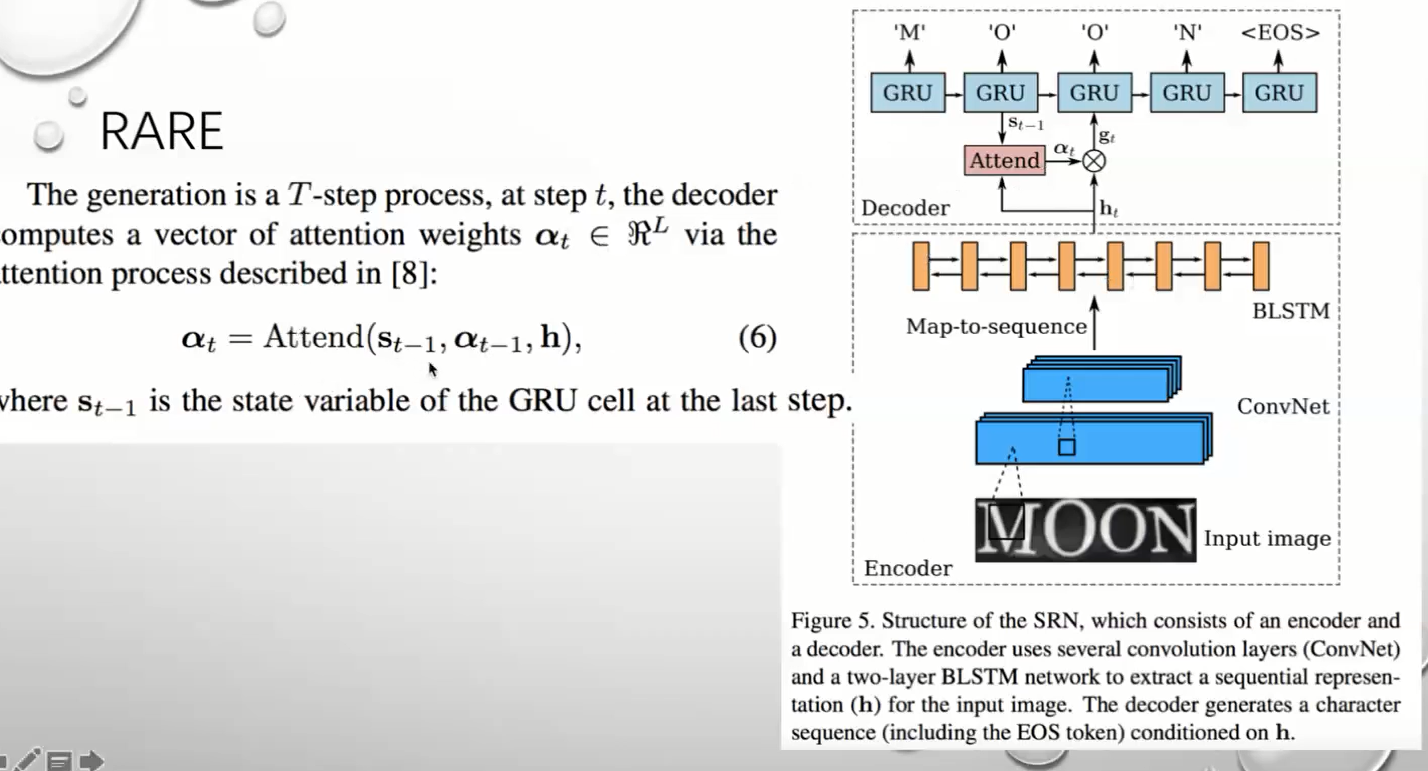
RARE
ATTENION 注意力机制
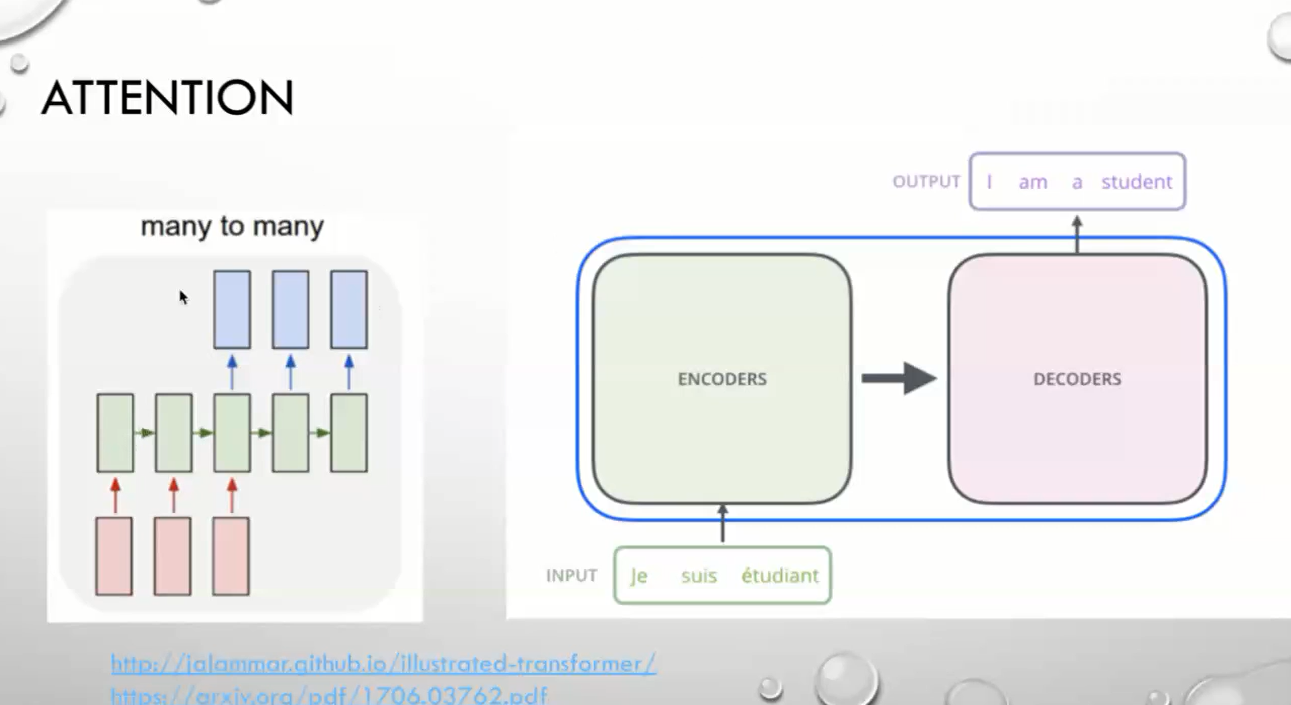
TransmFormer
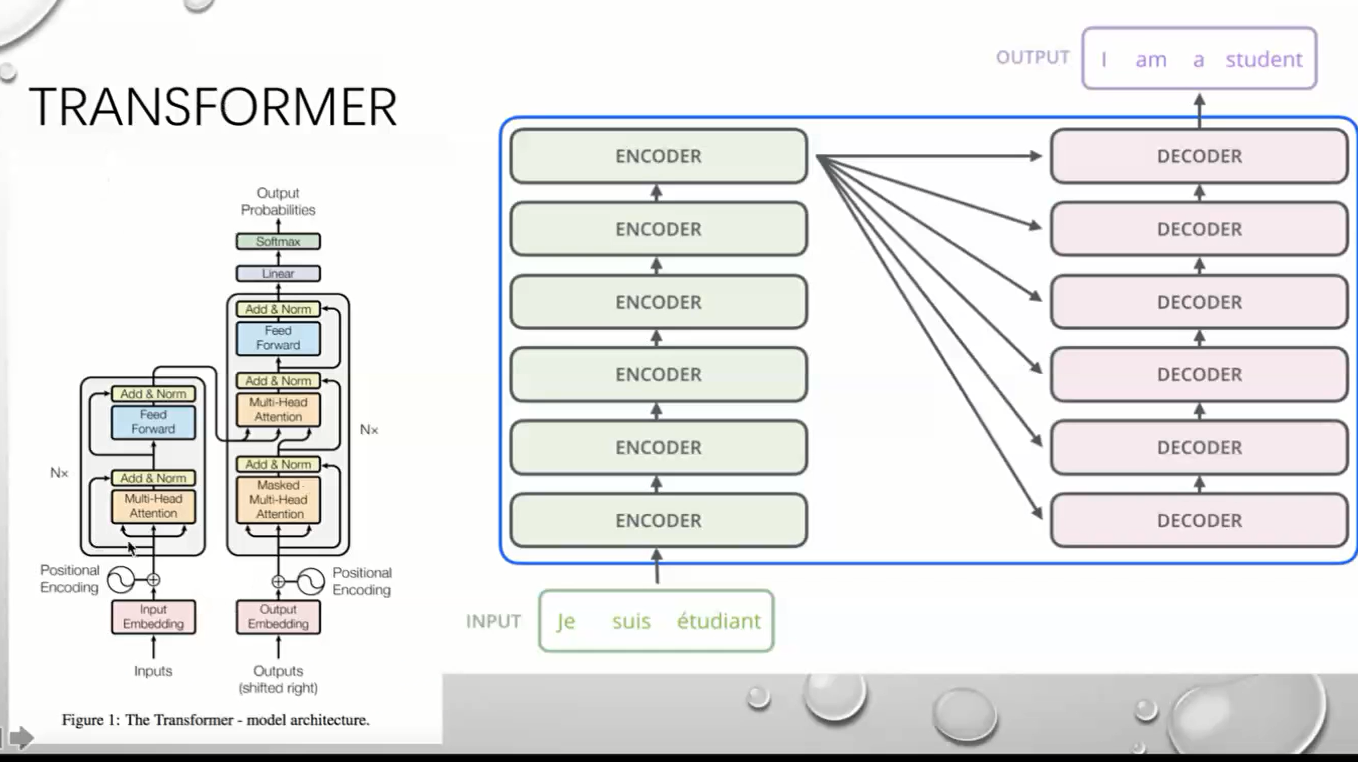
编码解码
两个Attention
feed Attention
self Attention
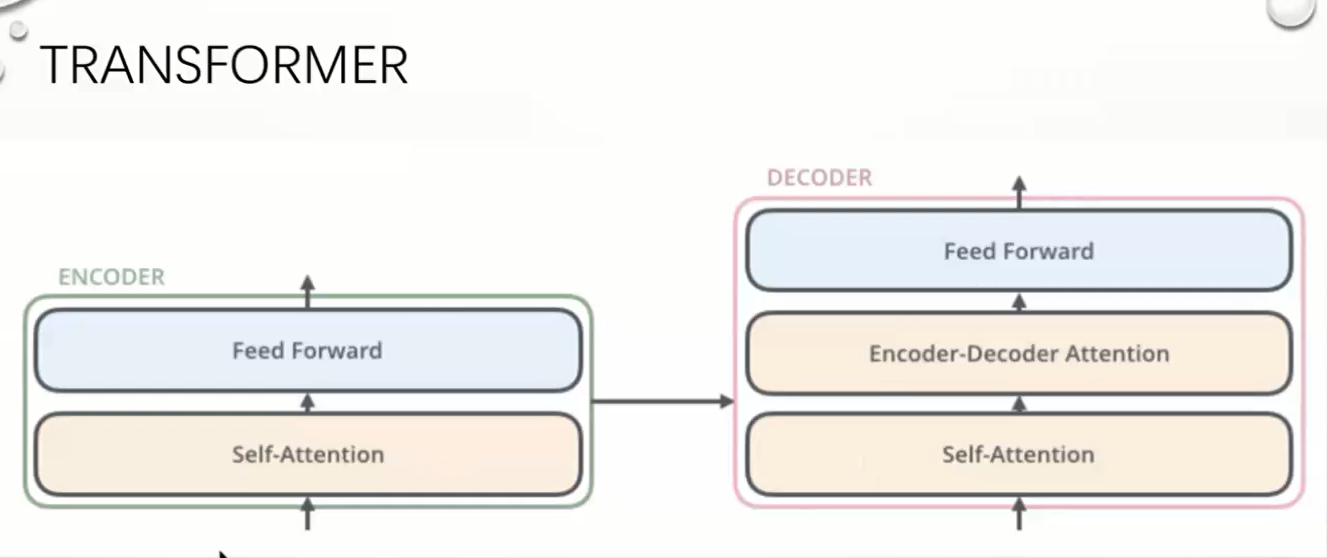
self Attention
相关性
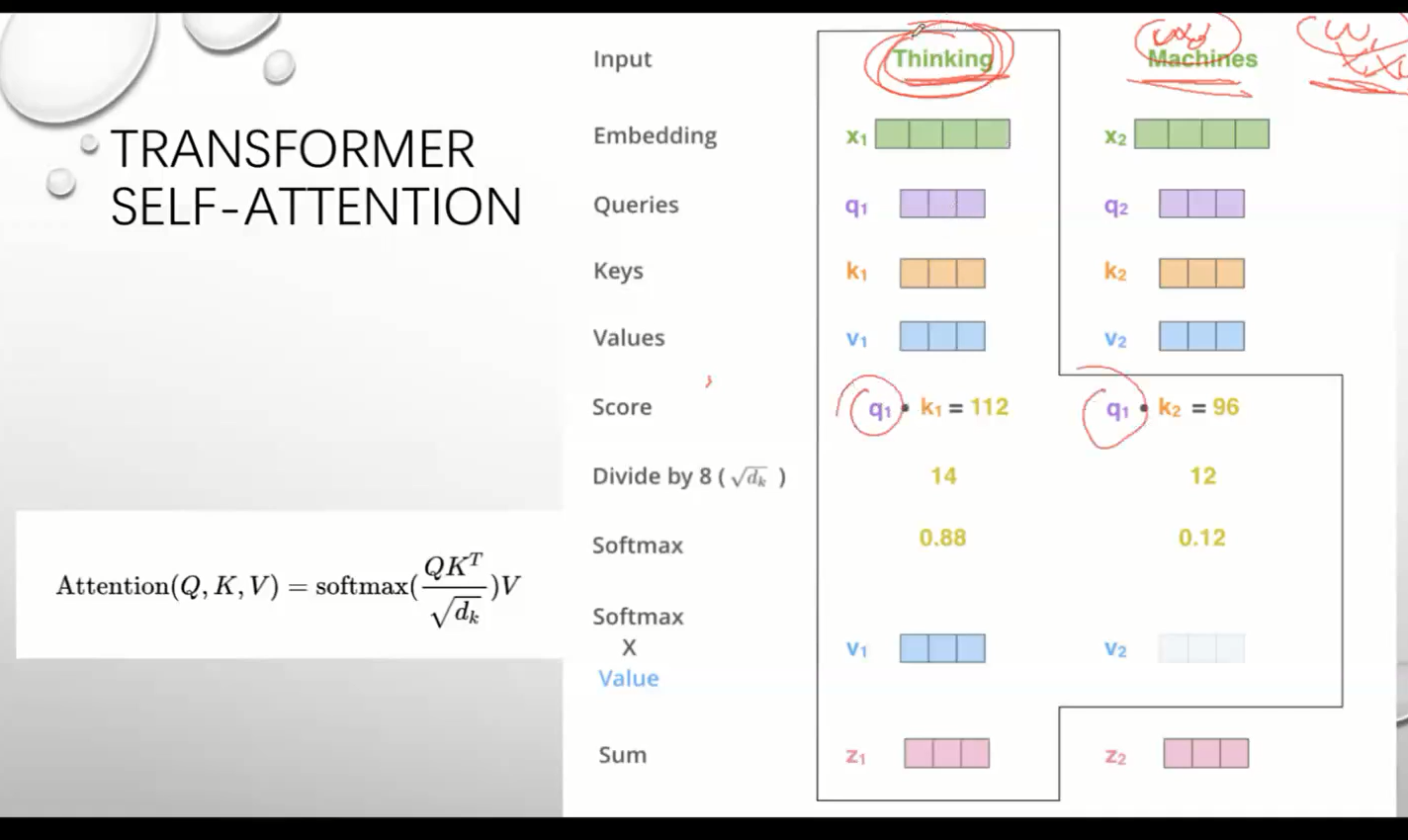
RARE 中Attention

第二阶段
四 文本行定位
文本检测方法分析
1 文本检测面临的挑战

2 anchor-based 检测算法分析
文本检测通常分为两个流派,分别是pixel-based和anchor-based的方式。
基于anchor-based 检测算法合集
基础概念
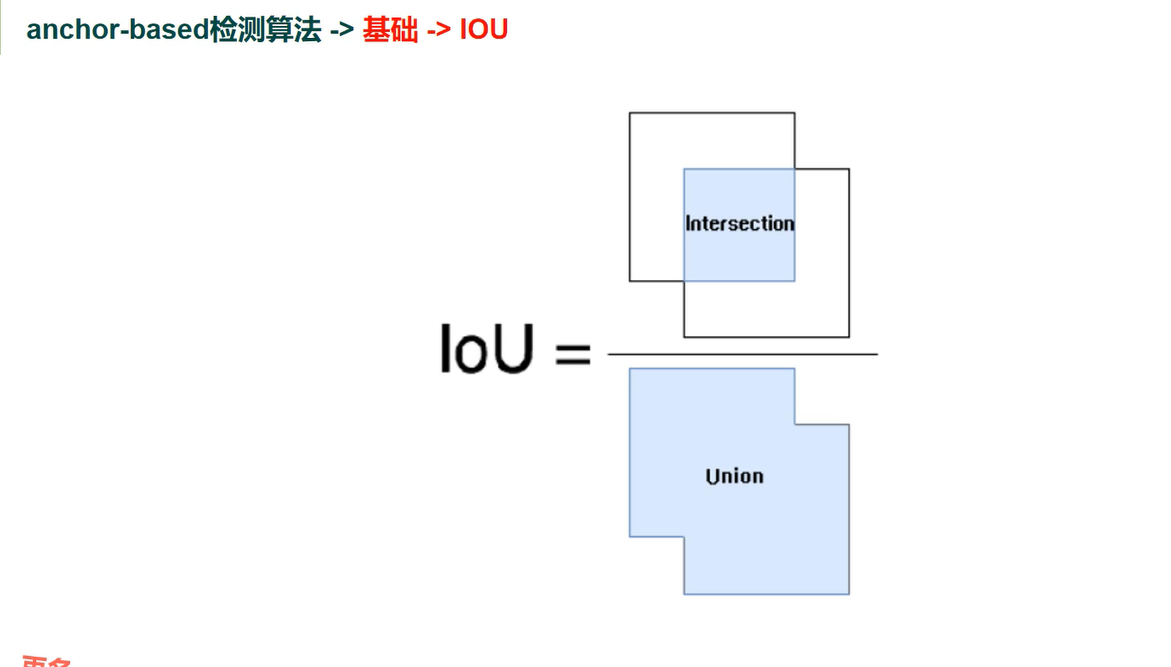
IOU 交并比
NMS 去冗余框

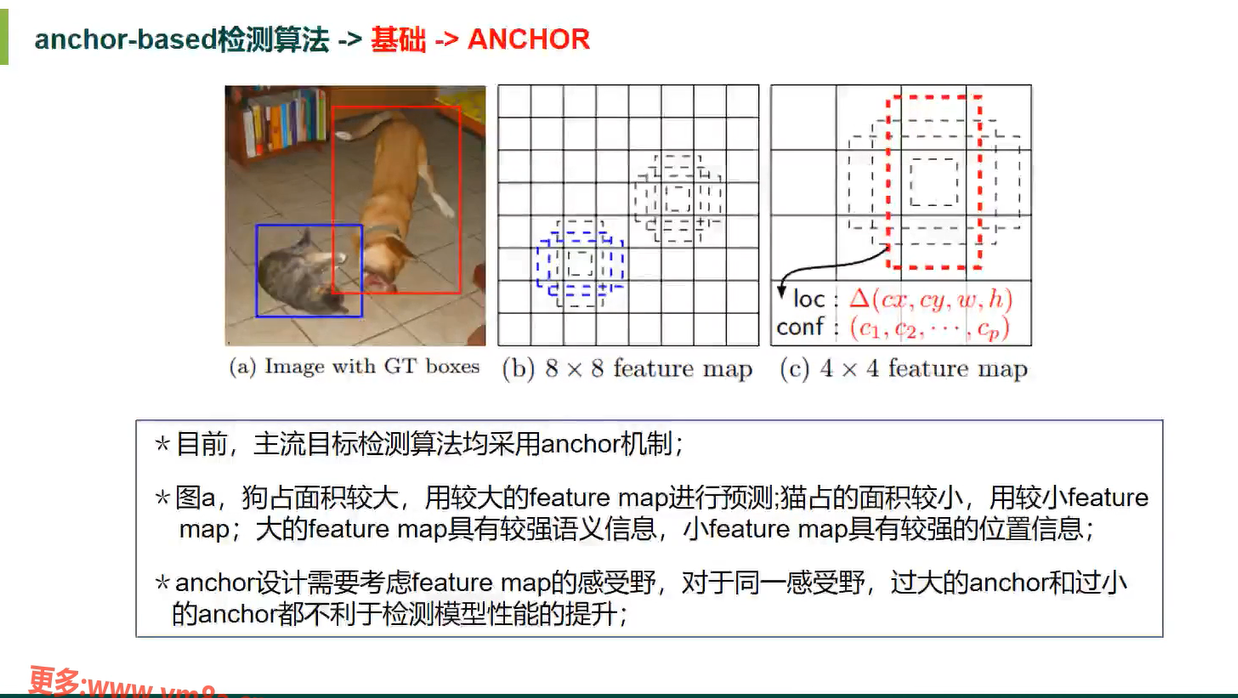
ANCHOR 检测算法
优点
1 密集的Anchor boxes 可有效提高检测模型的召回率
2 给定合适的anchor 可以实现较大目标和较小目标的有效检测
缺点
1 需要人为设计超参(scale、aspect ratio),需要先验性,不同的数据集和方案需要调参
2 冗余anchor boxes 过多并且多数anchor 为背景区域,对proposal 提取或目标检测五积极作用
3 预先定义好的anchor 超参不一定能同时满足极端scale 和aspect ratio 悬殊的物体 如火车
VGG16 检测网络
很成熟了 预训练直接用都可以

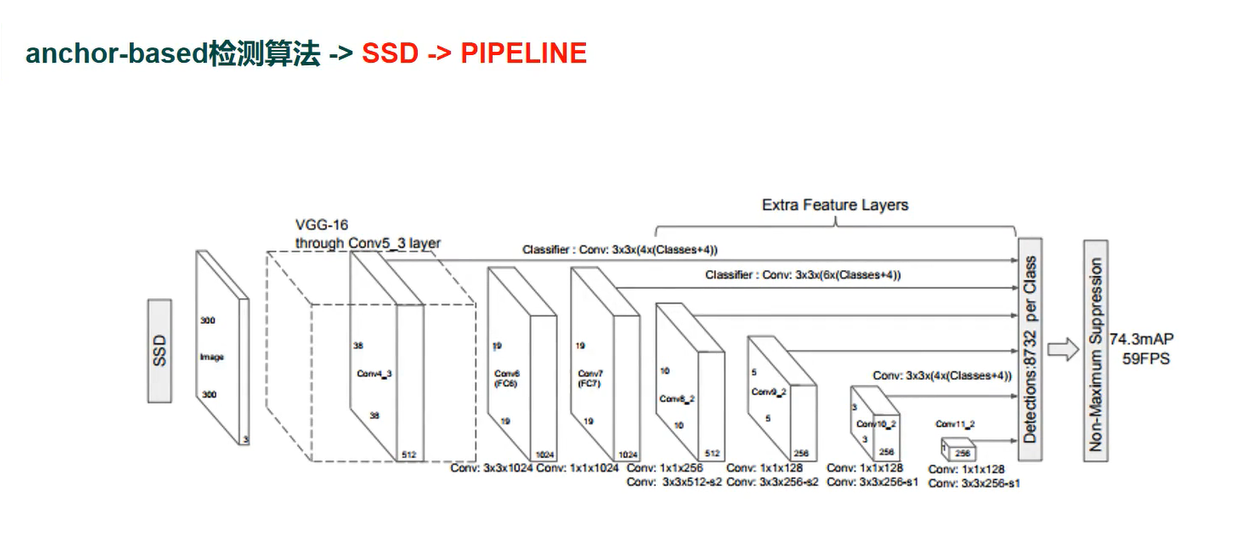
SSD检测算法 (高频使用)
高频使用 和YOLO 因为性能高
one-stage 算法
结构简单,计算量低
多scale结构,即多个不同大小的FEATUURE MAP 参与预测
性能优于但阶段算法YOLO、双阶段算法FasterRCNN
基于VGG16
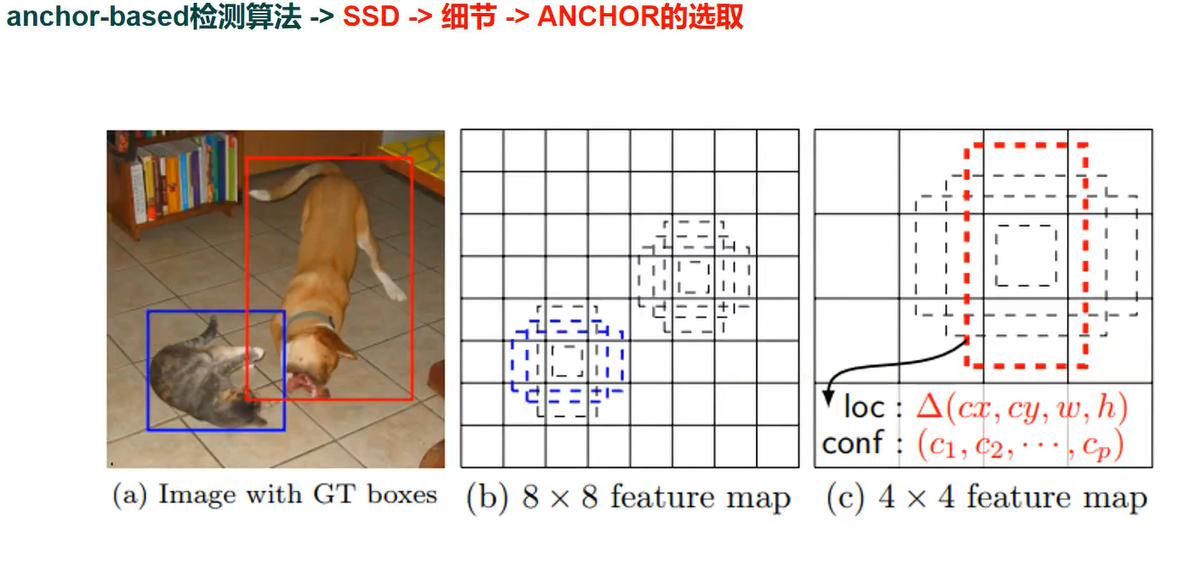
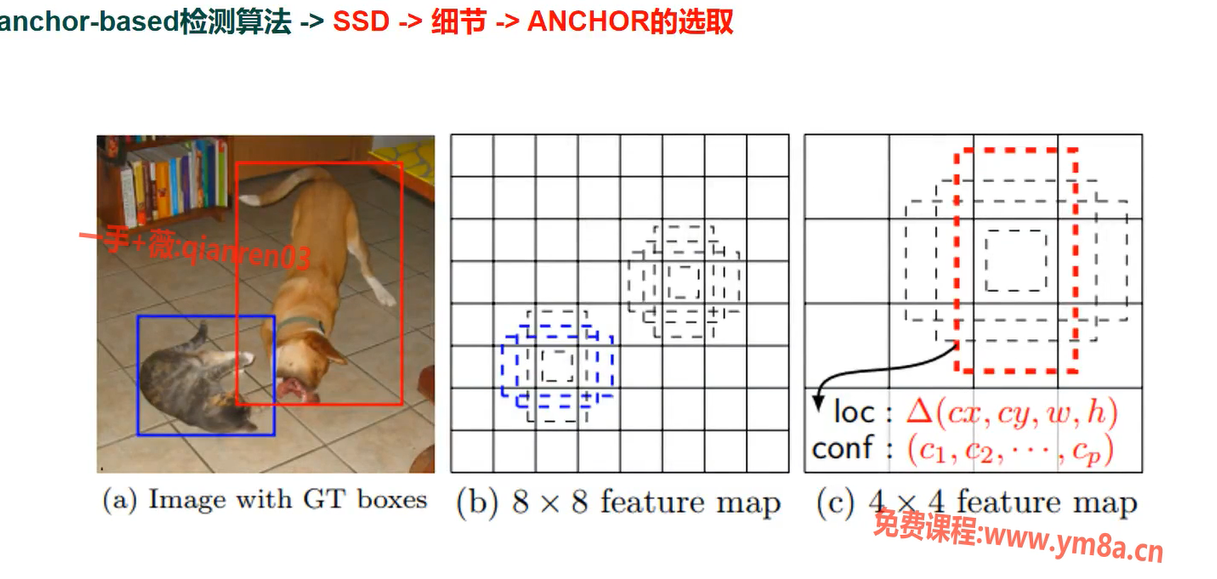
SSD 中 ANCHOR 选取
多 feature map 预测 不能改设置
HARD NEGATIVE MINING (SSD 中的样本选取机制)
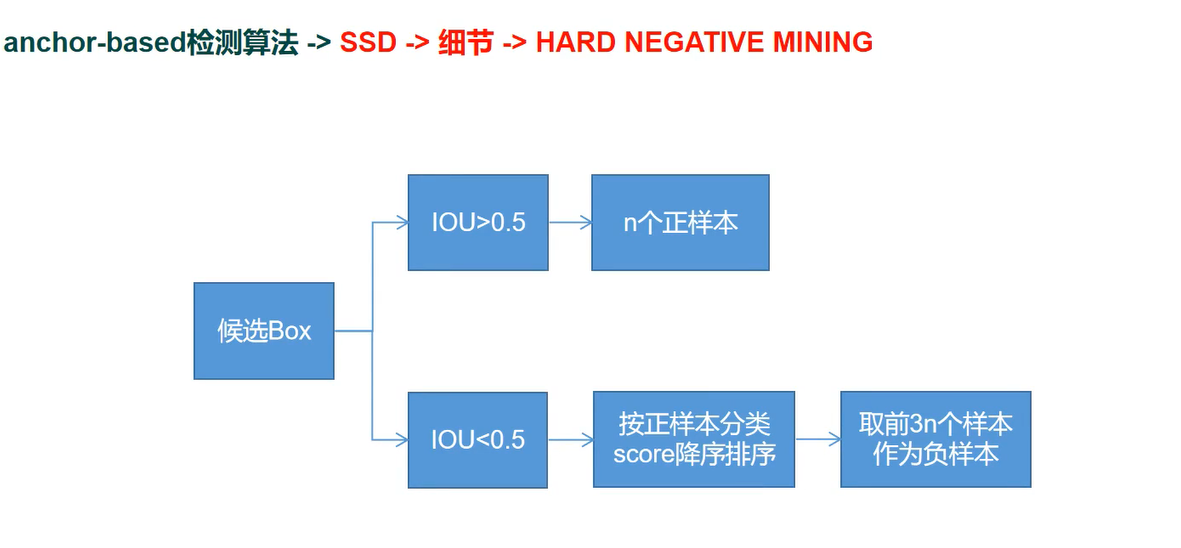
正负样本 1:3
标分类和目标检测中的正负样本是两种不同的概念:
目标分类中,如果是简单的二分类问题,正样本就是你要检测的样本,样本标签标为1,负样本就是其他任意不是正样本的,都为0。
样本不均衡会导致:对比例大的样本造成过拟合,也就是说预测偏向样本数较多的分类。这样就会大大降低模型的范化能力。
目标检测中中正负样本指的是模型自己预测出来的框与GT的IoU大于你设定的阈值即为正样本,因为我们目标分类是给整幅图像标签,而检测是给你的GT标注类别标签,所以目标检测中的分类通常来说是非常简单的,但是因为检测中的背景更复杂,而且是多分类,所以最终影响检测的精度还是分类。
性能分析

缺点
1 anchor 的scale 、aspect raio 是经验值 不好调节
2 小目标的检测效果不好SSD最大的feature map 为Conv4_3 对于一下小的物体Conv4_3 的视野过大位置特征弱
TextBoxes (升级版的SSD)
基于SSD 框架进行改进,结构简单运行速度快 适用于文本检测
检测与识别end-to-end 模型,利用识别提升检测性能
TextBoxes PIPELINE
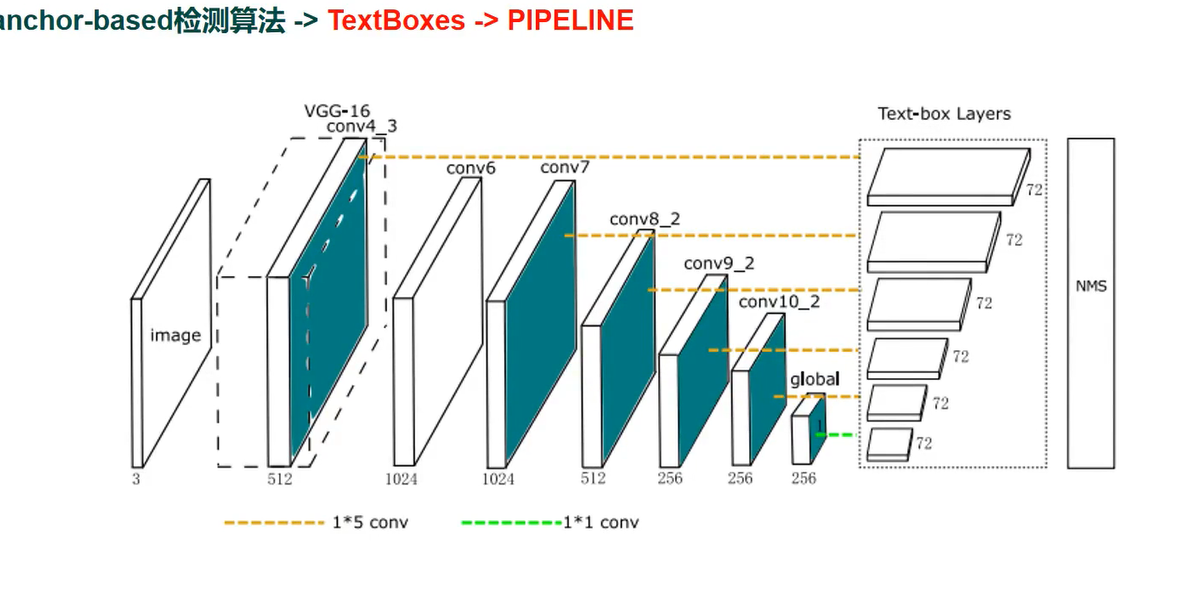
1 TextBoxes Backbone 为VGG16 ,替换其全连接层为卷积层,星辰盖全卷积wangluo;
2 为了适应长宽比悬殊的文本,anchor的aspest ratio 分别设置为[1 2 3 5 6 10]
3 为了增加X 方向的视野感受 避免Y方向引入文本噪声,提出了text-box层,其中classifier 卷积核为1*5(SSD为3x3)
4 CNN + RNN 端到端 的训练框架 训练时输入图像多尺度
5 加入文本识别模块提升检测性能
TextBoxes LAYERS

TextBoxes 中 ANCHOR offset
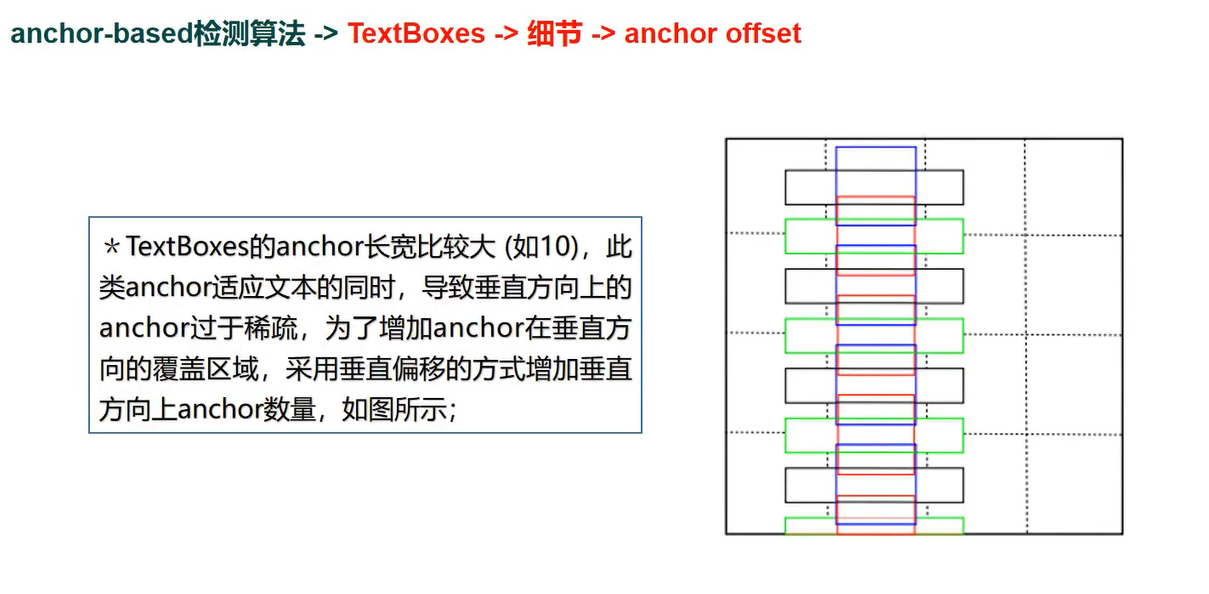
TextBoxes 中 多尺度训练

缺点
1 无法处理特殊情况,如遮挡 文字间距过大,过度光照
2 无法有效检测多方向文本
3 一些非文字区域被检测
4 一些文字区域无法检测

TextBoxes++
1 类似SSD 的scale结构,简单快
2 直接在feature map 上进行回归和分类
3 直接回归到四边或带角度的矩形,可支持多角度文本检测
TextBoxes++ Pipline
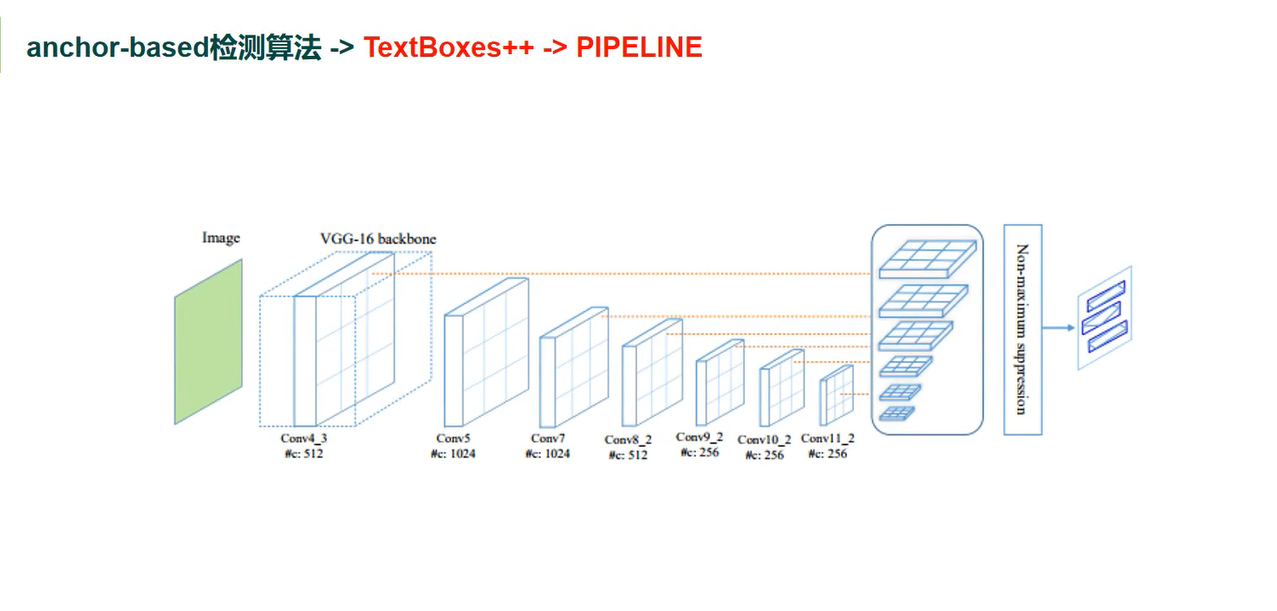
特点
1 识别与检测结合,通过识别提升检测性能
2 提出了系变形和带角度的矩形物体的描述方法
3 与SSD相同使用6个scalse 进行预测回归
4 anchor 的长宽比为[1 2 3 5 1/3 1/3 1/5]
5 采用3X5 过滤器 加大横向感受野,适应长文本检测
6 网络的输出与TextBoxes 不同,支持多方向文本检测
7 hard examplemining 采用两个阶段分别是 1:3 和1:6 (正负样本)
ANCHOR OFFSET
解决细长anchor 问题加入偏移量
目标描述

CASCADED NMS
NMS即non maximum suppression即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值
相较于矩形NMS 四边形 和带角度矩形的NMS 更为耗时
步骤1 先对四边形的带角度矩形的最小外接矩形进行NMS,以较大的IOU阈值:0.5 提出一些候选框
步骤2 对剩余的候选四边形和带教的矩形候选框进行NMS,以较小的IOU阈值0.2提出一些候选框
不足
1 无法处理 遮挡间距过大
2 纵向的检测效果不好
3 非文字区域被检测 (规律的条纹)
4 一些文字区域无法检测 (形变的)
CTPN
特点
和TextBoxes 采用完全不同的策略
anchor boxes的概念可以用于预测固定数量的框
CTPN 的anchor 的宽的固定为16 高度可变,大量小proposal 通过后处理合并成文本行;克服通用目标检测框架对长度剧烈变化敏感的缺陷
CNN和RNN结合同时学习空间特征和序列特征;空间特征可有效描述CTPN检测到的小的问字段;序列特征可有效学习到小蚊子段间的关联性
pipeline
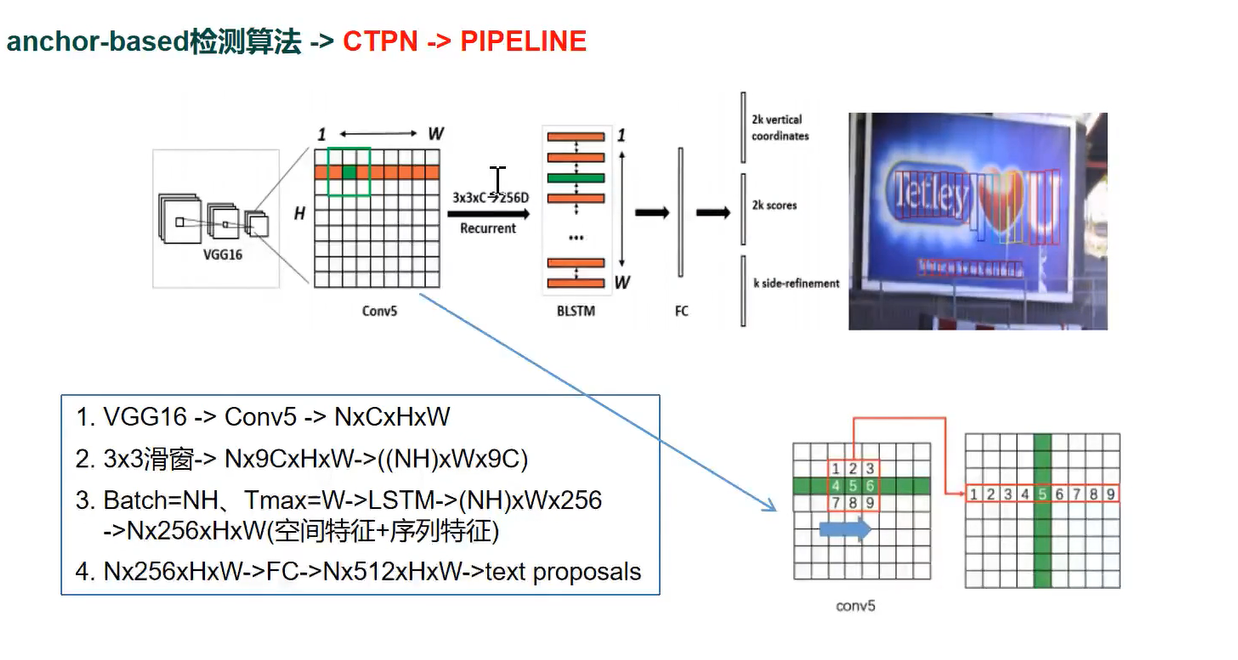
FINE-SCALE
1 与RPN不同CTPN引入了微分思想,即检测文本行的局部区域然后合并,
2 CTPN 的anchor 宽度固定16,高度从11-273 每次乘以1.4 feature map 每个点对应10 个anchor
3 Fine-scale 机制使得CTPN可以检测长宽比悬殊的文本
CNN+RNN
文本线构造
核心构想: 相近的proposal 组合成一个pair ,合并不同pair 直到无法合并位置
两个proposal (Bi Bj)组合条件

SIDE- REFINEMENT
水平方向,文本被分为等宽16 可能导致两侧变宽不够 可能少一点或者多了一点无法贴合检测对象
解决方案 增加一个偏移量来修正
LOSS

不足
无法检测竖直 形变 曲线文本 倾斜样本检测较差
横向文本两边定位精度较低
存在基于策略的合并环节,导致CTPN无法处理一些复杂环境的样本
SEGLINK 片段链接
特点
1 结合CTPN局部片段预测和SSD 多尺度预测,同时预测不同scale 下的segment和link
2 可以处理多方向(倾斜)和任意长度的文本
pipeline
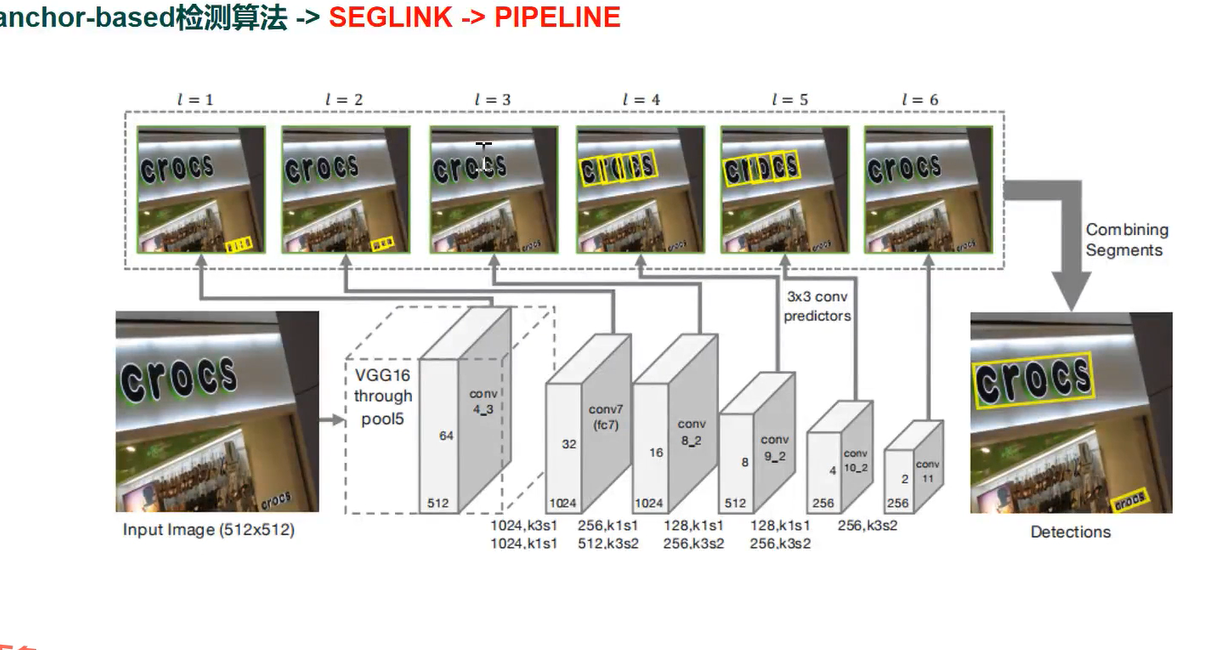
和CTPN合并方式不一样它是学习的CTPN是规则
细节
1 增加方向预测
2 超参改变
3 数据增强
4 scalse 是自动感知设置的 SSD是人工设置的

link 检测
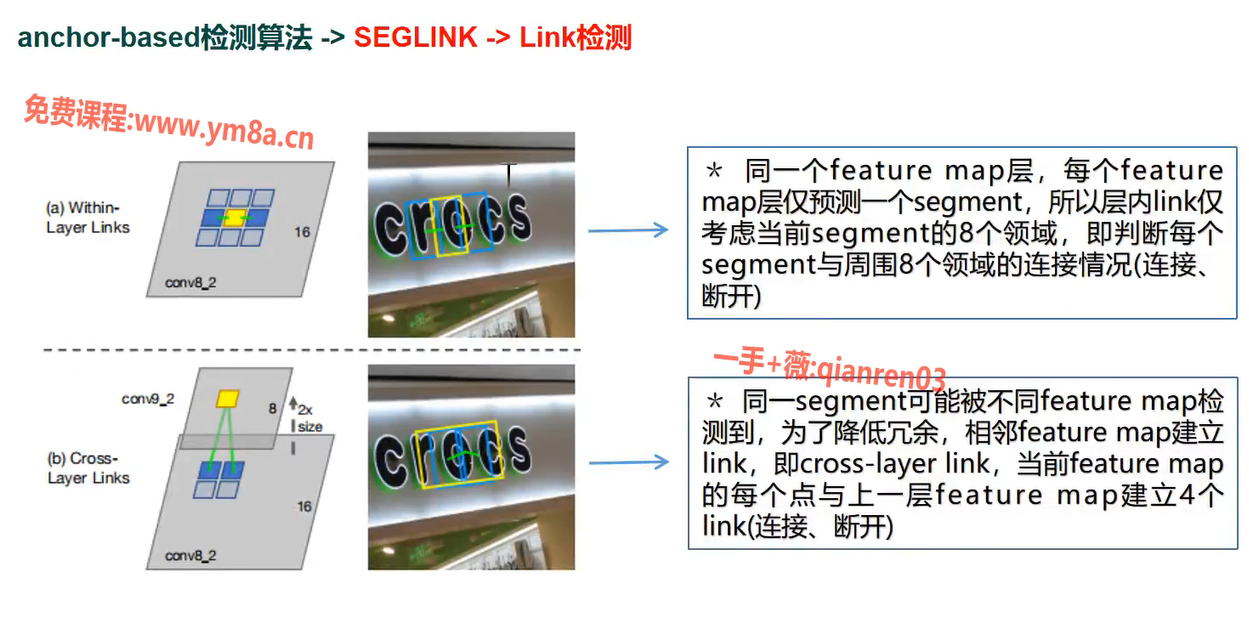
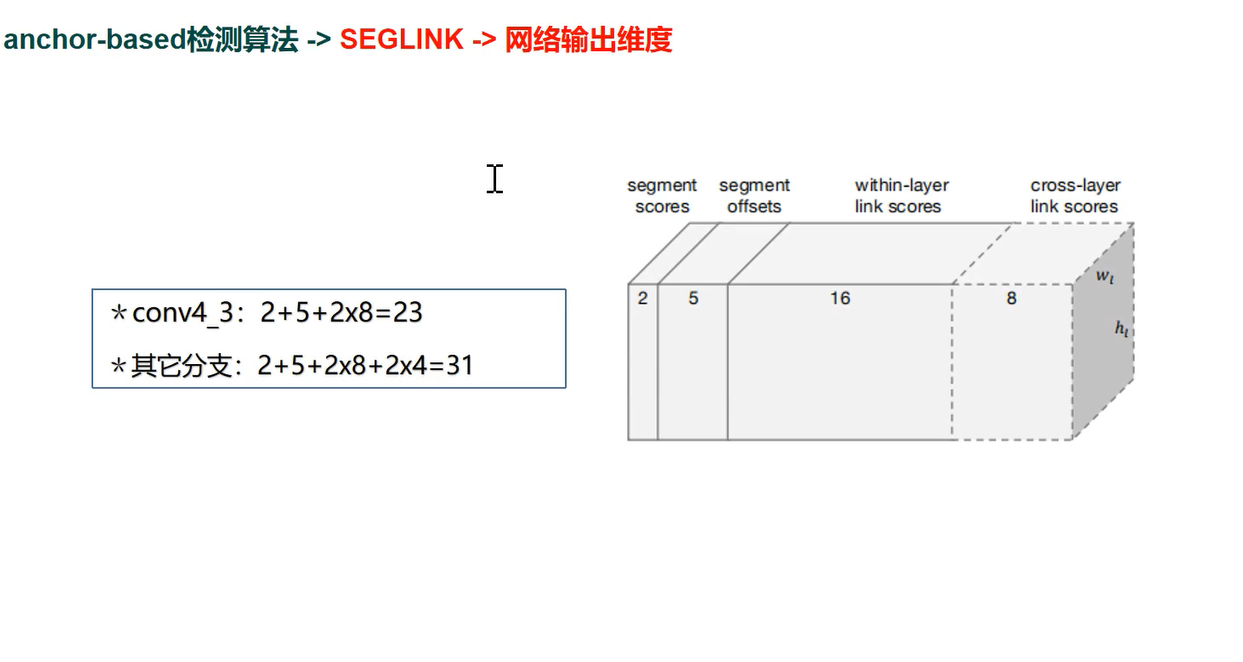
网络输出维度
segment 合并
上面输出的是片段 ,现在合并为文本行

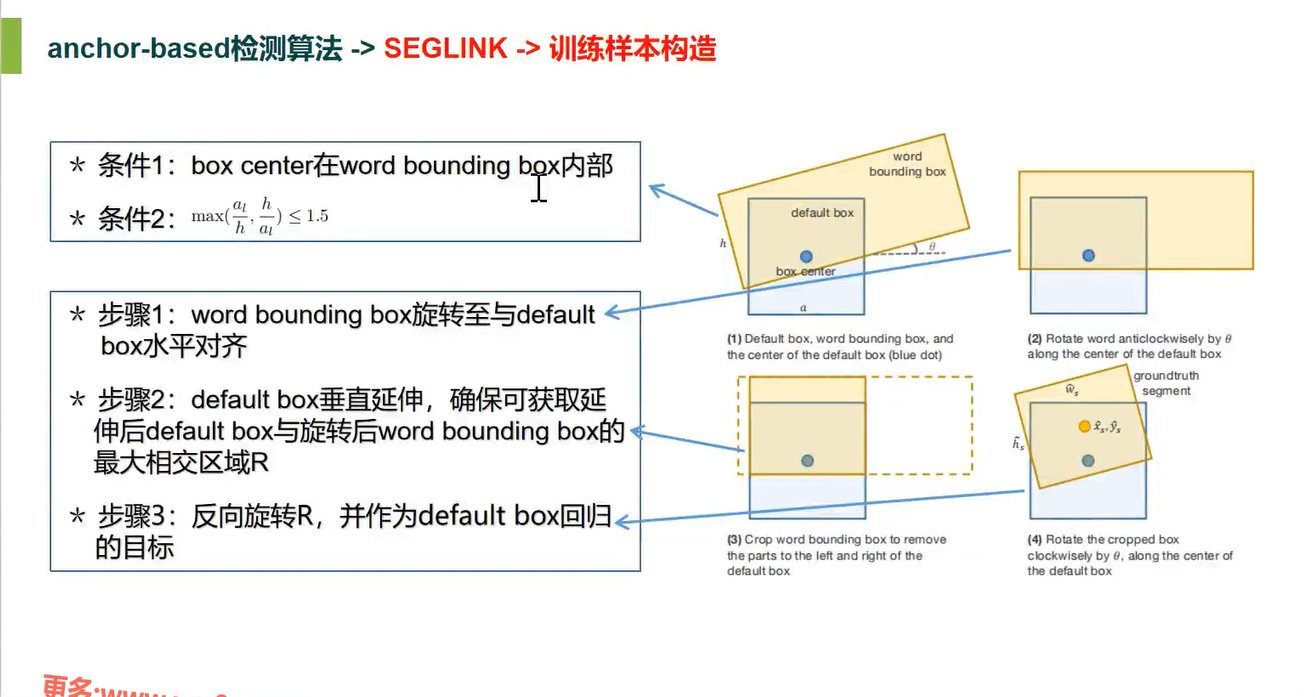
训练样本构造
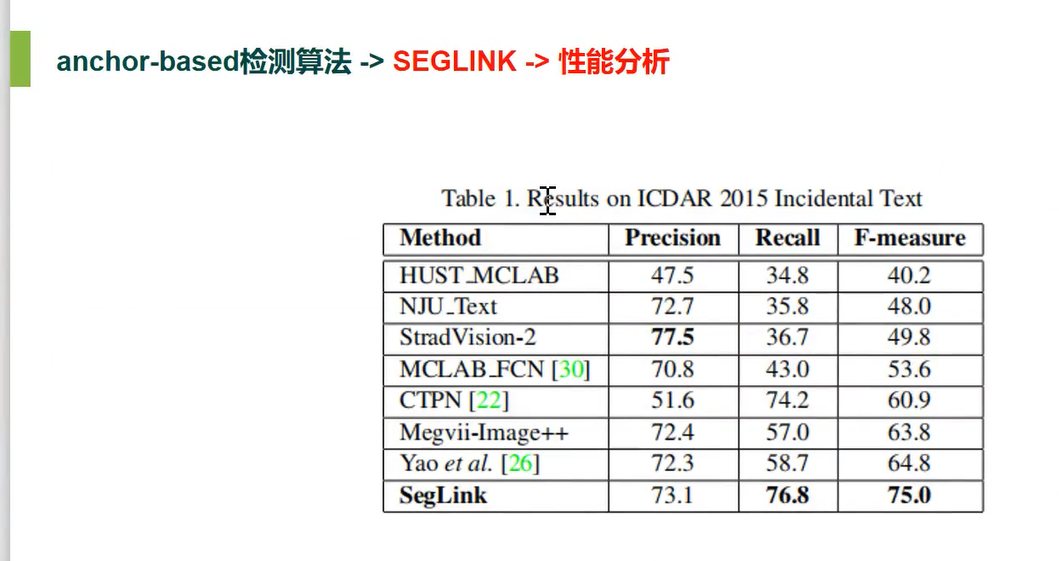
性能
不足
1 合并时采用了直线拟合,无法检测形变或曲线文本
2 link 仅考虑相邻的segment 无法检测较大的文本
3 segment 的连接存在两个超参需要调节
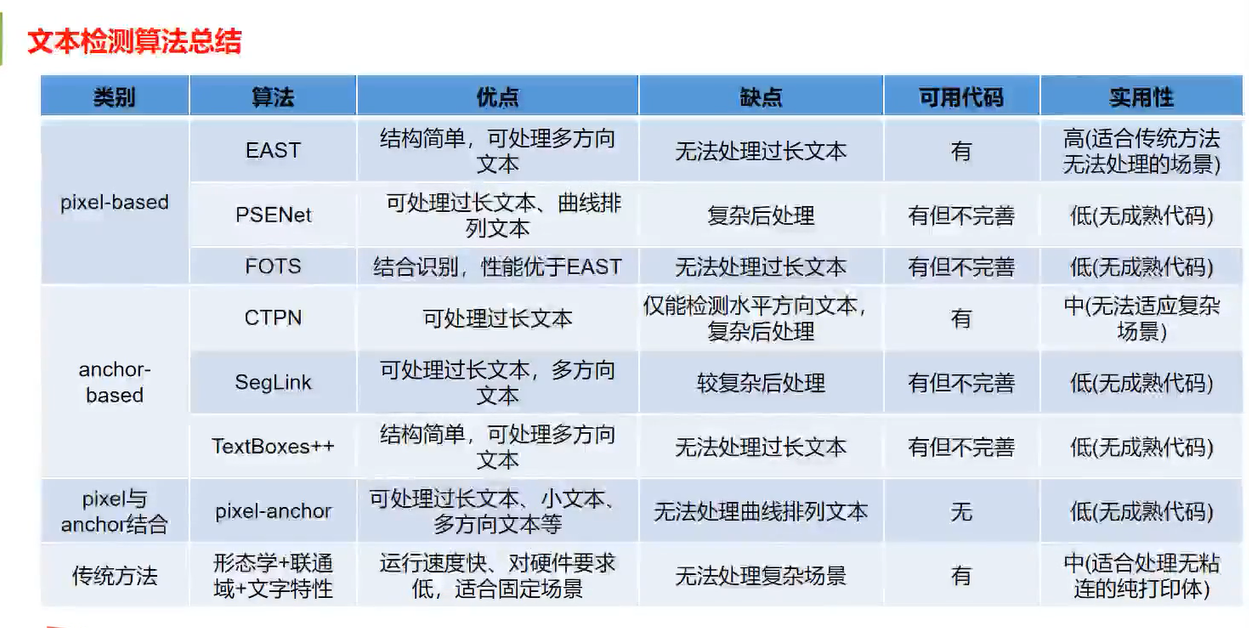
总结
1 textBoxes 系列算法优点是结构简单、处理速度快缺点是无法有效处理长宽比悬殊的文字
2 TextBoxes 系列算法与anchor 自动生成 算法相结合 可一定程度上提升算法对目标尺度变化的鲁棒性
3 CTPN优点是可以处理长宽比悬殊的文字,去欸但是存在基于策略的后处理环节,无法适用于复杂场景
4 SegLink优点与CTPN类似,同时一定程度与上克服了CTPN的缺点,对于长和宽比悬殊的文字检测是个不错的选择
5 检测模块与识别模块相结合,可有效提升检测模块的性能
3 实战-> 复杂背景下的视频字幕识别系统
传统方法实现的
目的:实时检测视频字幕出现的位置信息和字幕持续时间,并进行识别
意义:可辅助视频资料检索与管理、历史视频资料强救,视频节目制作等领域,满足市场对大规模视频数据库进行自动查询和检索系统的迫切需求
难点
要求
1 处理复杂背景下的视频字幕
2 系统具有强实时性、高准确率
难点分析
1 系统需要给每条字幕准确的时码信息,需要对每帧高清图像进行处理,并且系统运行再CPU上,同时需要具有强实时性
2 复杂背景存在类似文字的信息,对定位和分割造成严重干扰
pipline
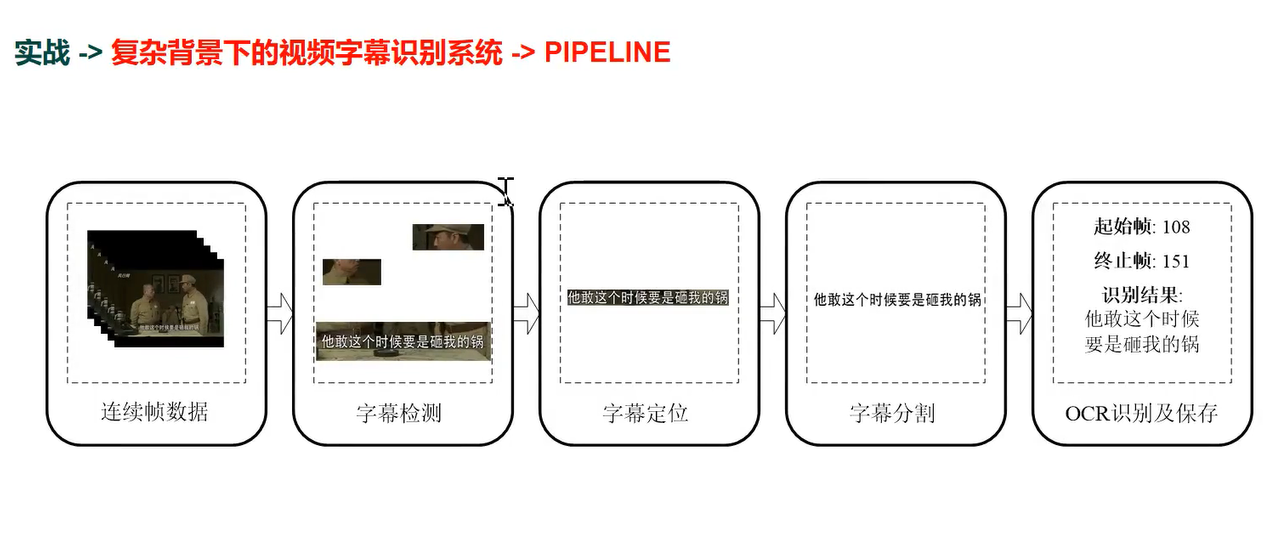
多帧融合 ---> 字幕的像素值相对稳定
字幕定位(传统)

字幕定位pipeline
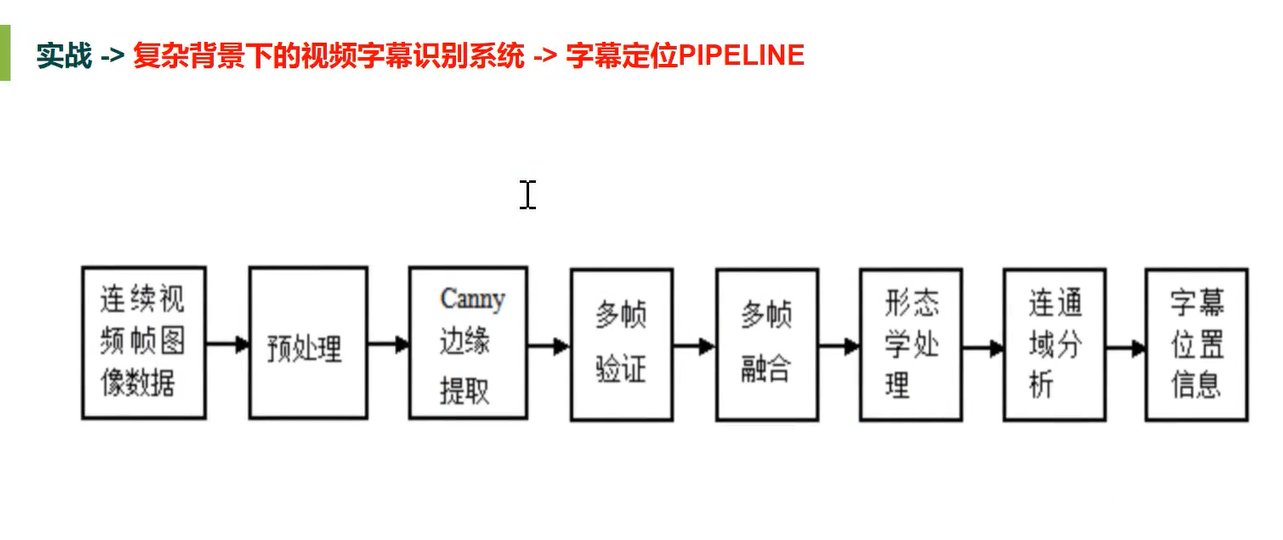
字幕定位
多帧验证 字幕大小位置不会变 会长时间存在多帧

多帧融合 字幕大小位置不会变 会长时间存在多帧 融合之后背景模糊字幕清晰

形态学处理
基于文本的边缘性很强

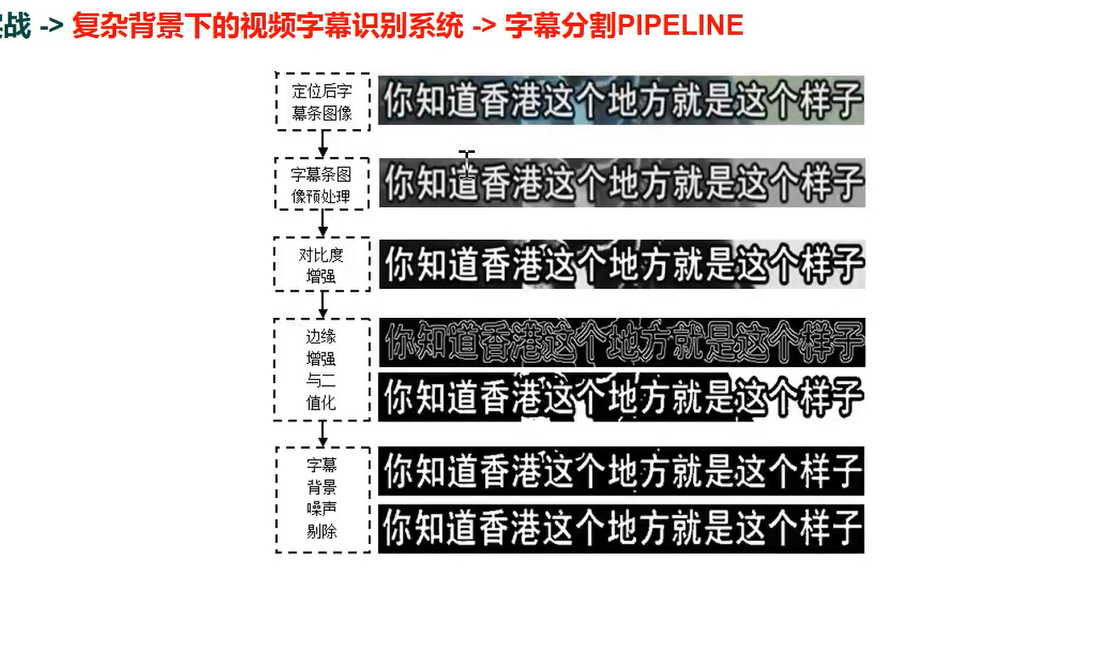
字幕分割 pipeline
系统性能


五 自然场景中的文本检测
1 pixel-based 检测算法分析
文本检测通常分为两个流派,分别是pixel-based和anchor-based的方式。
pixel-based是基于分割的思想
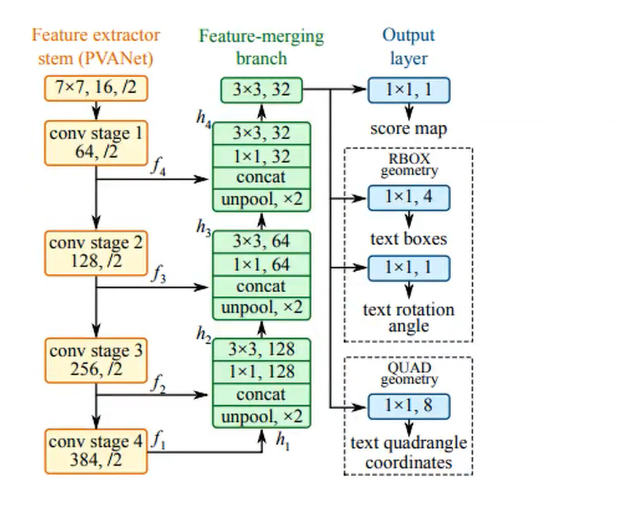
EAST
特点
1 FCN+NMS ,FCN直接进行预测、回归,除NMS无其他环节
2 EAST 的检测形状可为四边形、带角度矩形,可处理单词级别的文本行级别的文本
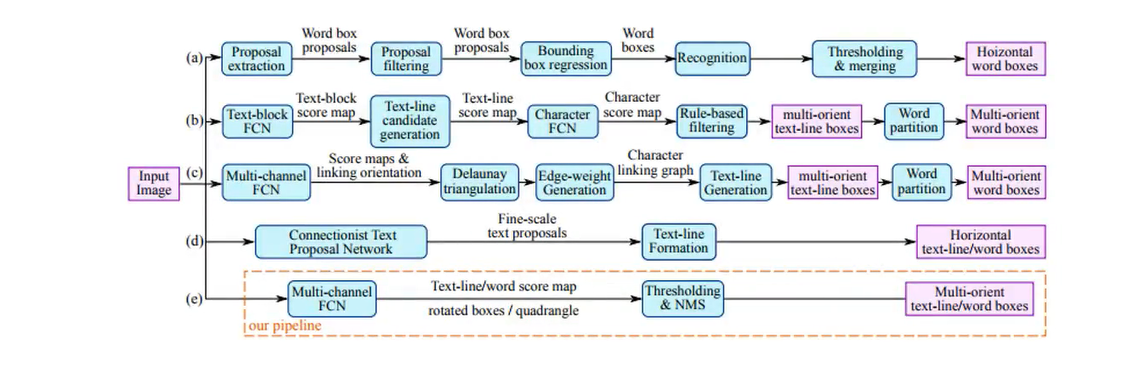
PIPELINE
关键信息

感受视野(receptive field):CNN中,某一输出层feature map中一个元素点(这里我们还是称之为像素点)对应的输入层区域的大小,被称作感受视野(receptive field)。例如,feature map2的一个像素点对应feature map1的一个5*5像素区域,其坐标取决于卷积核滤波的坐标位置。
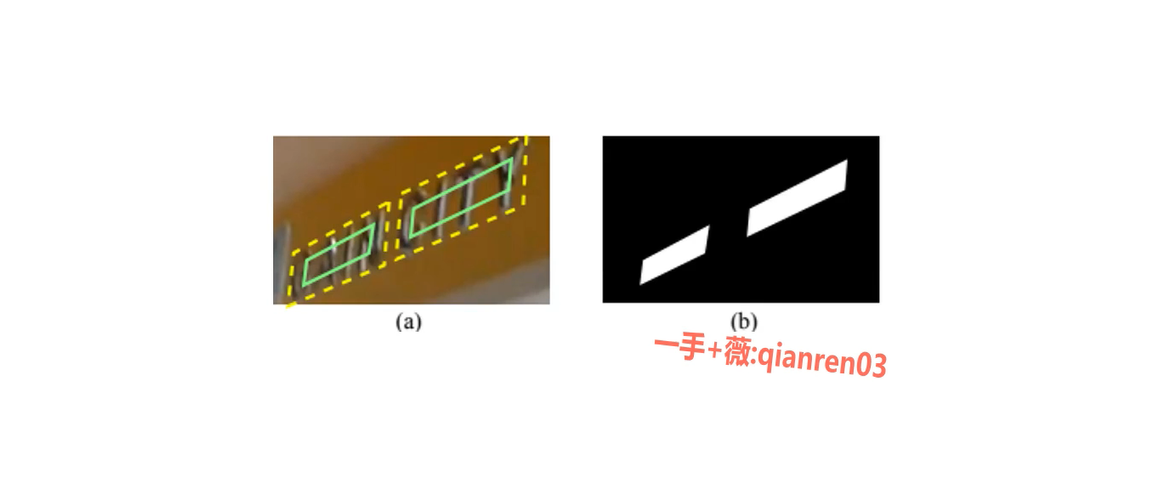
样本生成
score map
将标注框向内平移
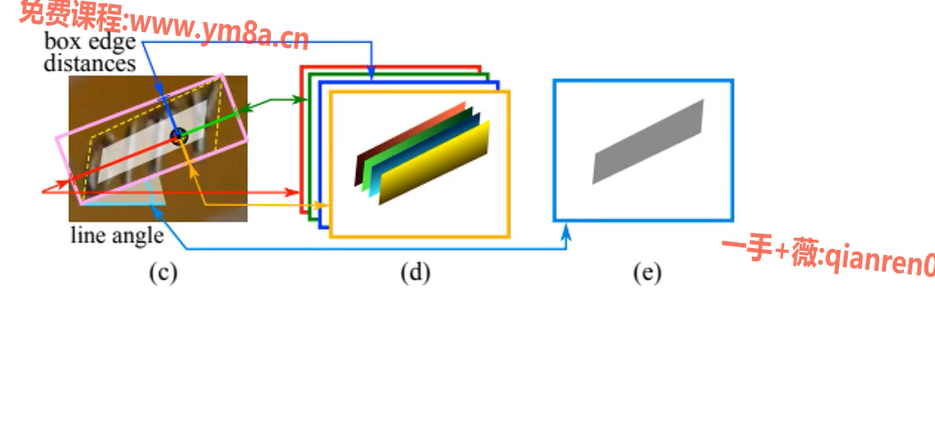
RBOX、QUAD GEOMETRY
LOCALITY-AWARE NMS(LNMS)
局部感知NMS

性能分析
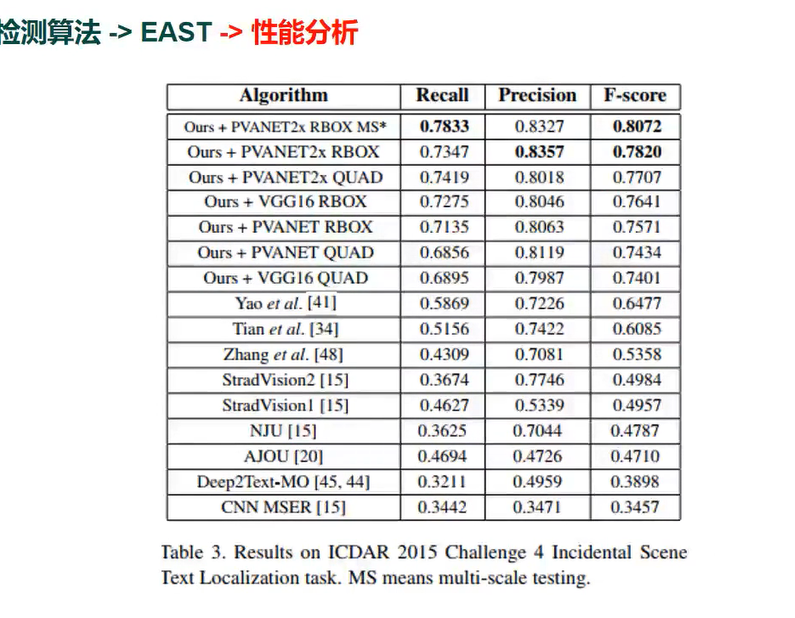
可以应对各种复杂场景
不足
1 无法有效检测垂直的文本,主要原因是无足够样本
2 受限与backbone 的感受野 无法处理长宽比悬殊的文本
3 受限于 backbone 的感受野,两边边框回归的较差
AdvancedEAST
PIPELINE
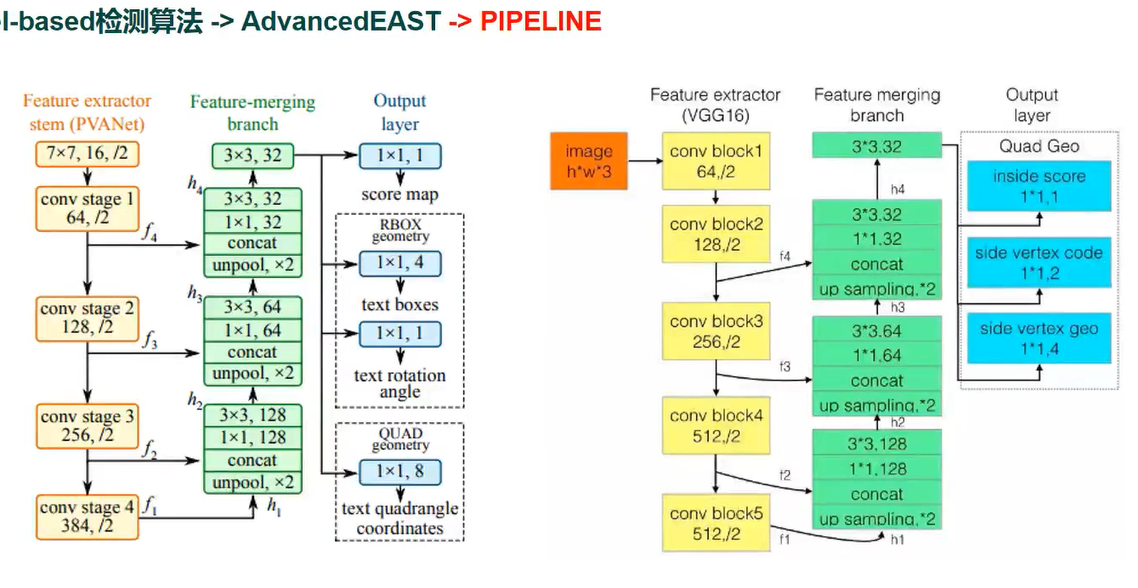
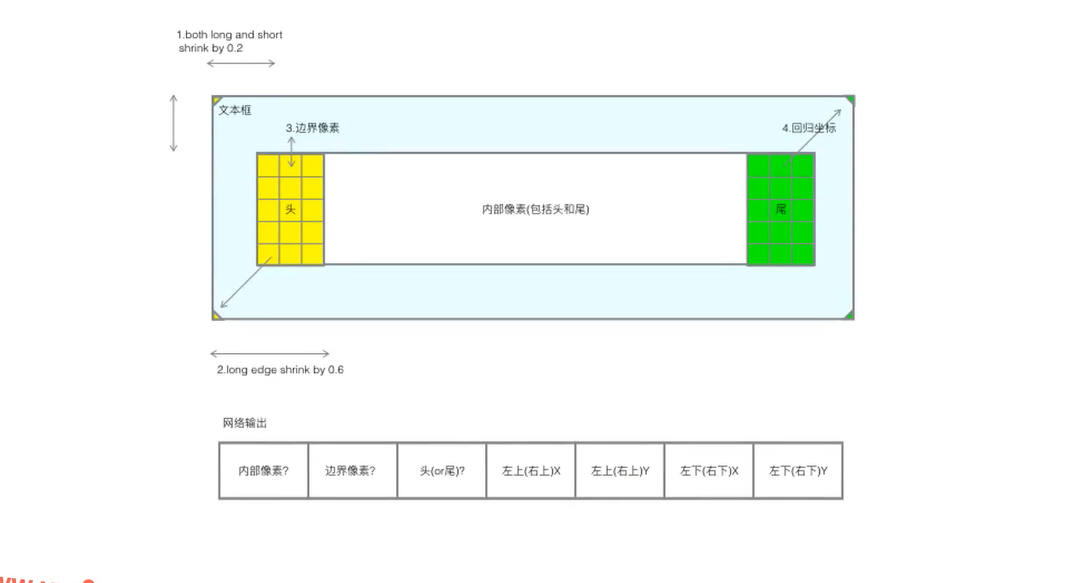
原理
不足
1 相对EAST AdvancedEAST 的预处理会更加复杂 需要确定头尾区域
2 AdvancedEAST 头尾区域大小的设定会严重影响模型的性能 如高6 的文本取短边的0.6 头的区域的宽为4 参与回归分类的像素点太少
2 pixel与anchor结合的检测算法分析
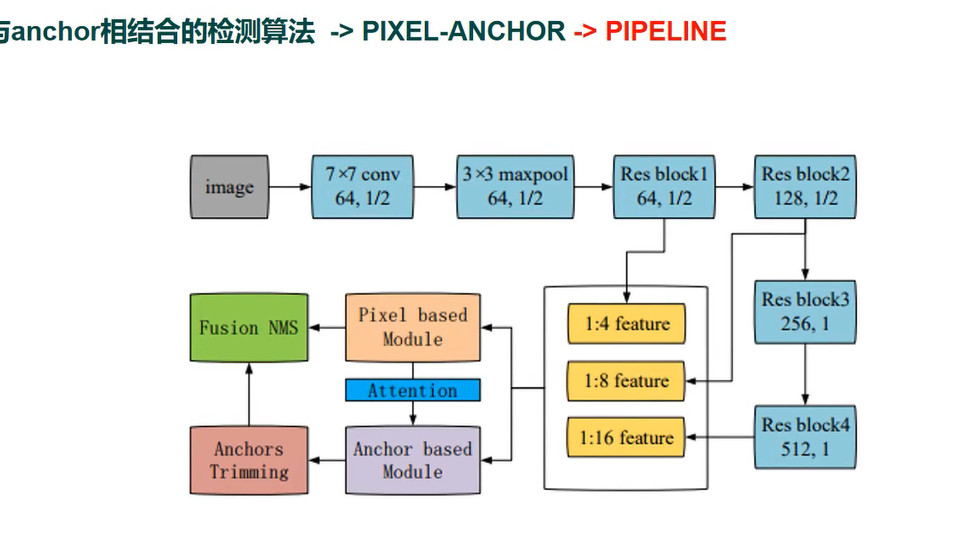
PIXEL-ANCHOR
特点
1 结合了pixel-based和anchor-based 方法的优点
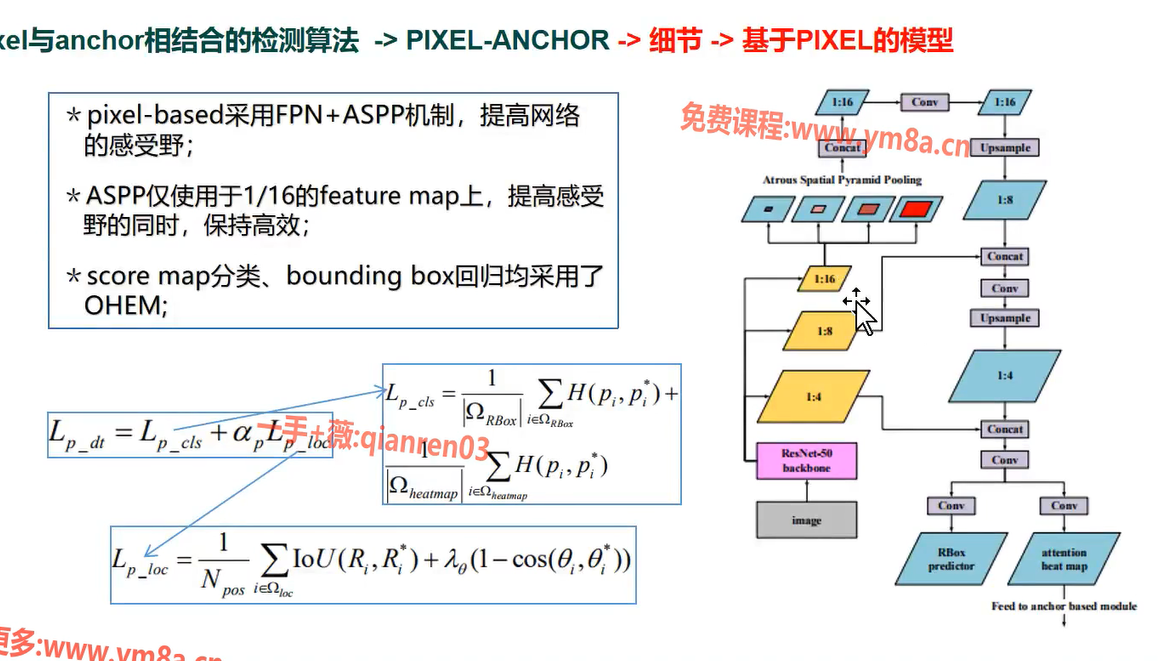
2 通过ASPP和OHEM 提升了pixel-based 方法的性能
3 提出了APL机制,使得SSD的文本检测算法可以处理长宽比、尺寸变化剧烈的文本
PIPELINE
关键信息
1 ASPP可以显著提升尺寸feature map 的感受野,EAST +ASPP 会有较大的竞争力
2 APL 可以改善SSD同时检测小目标和大目标性能
3 pixel-based 算法precision 较高、recall 较低,anchor-based 算法precisin 较低、recall 较高
4 pixel- anchor 算法中,pixel- based 负责检测中等大小文本,anchor-based负责检测小文本和大文本
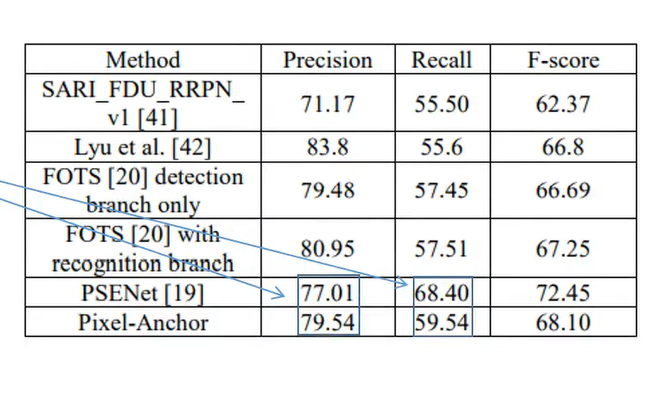
5 PSENet 在ICDAR2017上性能优于pixel-anchor,主要优于PSENet支持曲线排列的文本,因此其recall 更高
6 文本检测的2难点在于如何处理前光照、遮挡、长宽比玄珠、尺寸和方向变化剧烈的情况
7 ICDAR2017 训练集7200张测试集1800张9种语言任意方向的文本
基于PIXEL模型
基于anchor 的模型
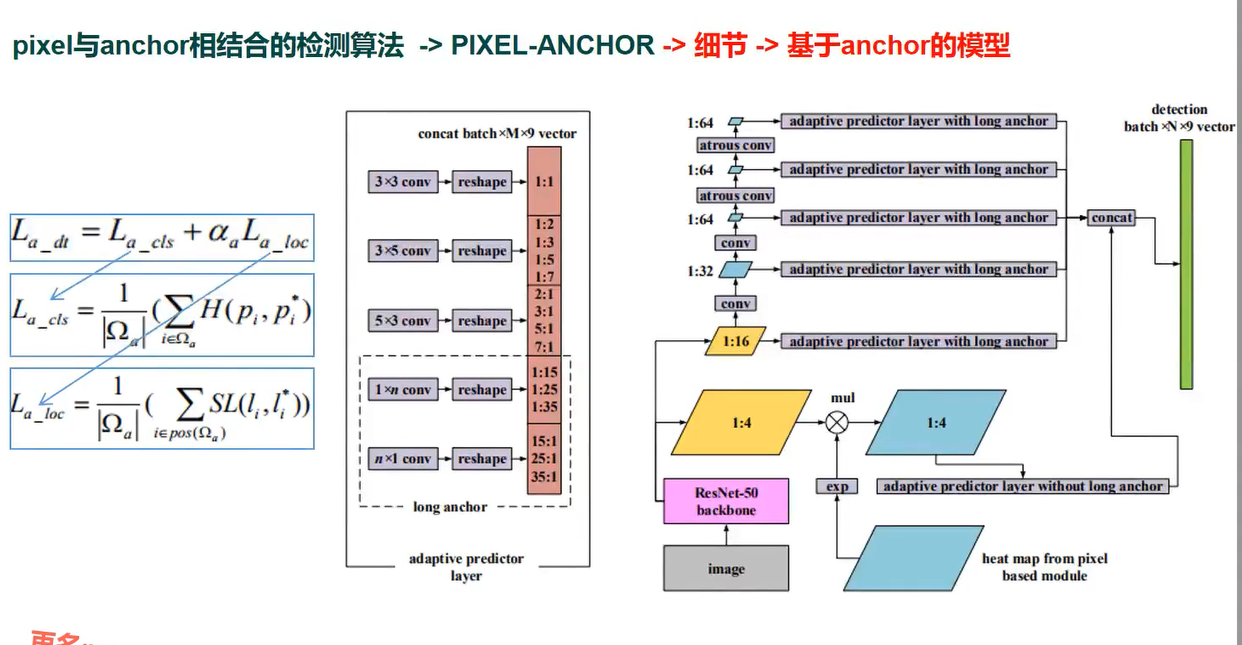
pixel + anchor 就很强
不足
1 无法检测形变文本 曲线排列文本,导致pixel-anchor 在ICDAR2017 的表现不如PSENst
2 无可用复现代码
文本检测总结
3 实战-> 文本检测之CTPN
预处理很重要
预处理阶段一定可视化
六 图像增强和预处理
1 图像增强

UNWARPING 去弯折
SUPER-RESOLUTION 超分辨率
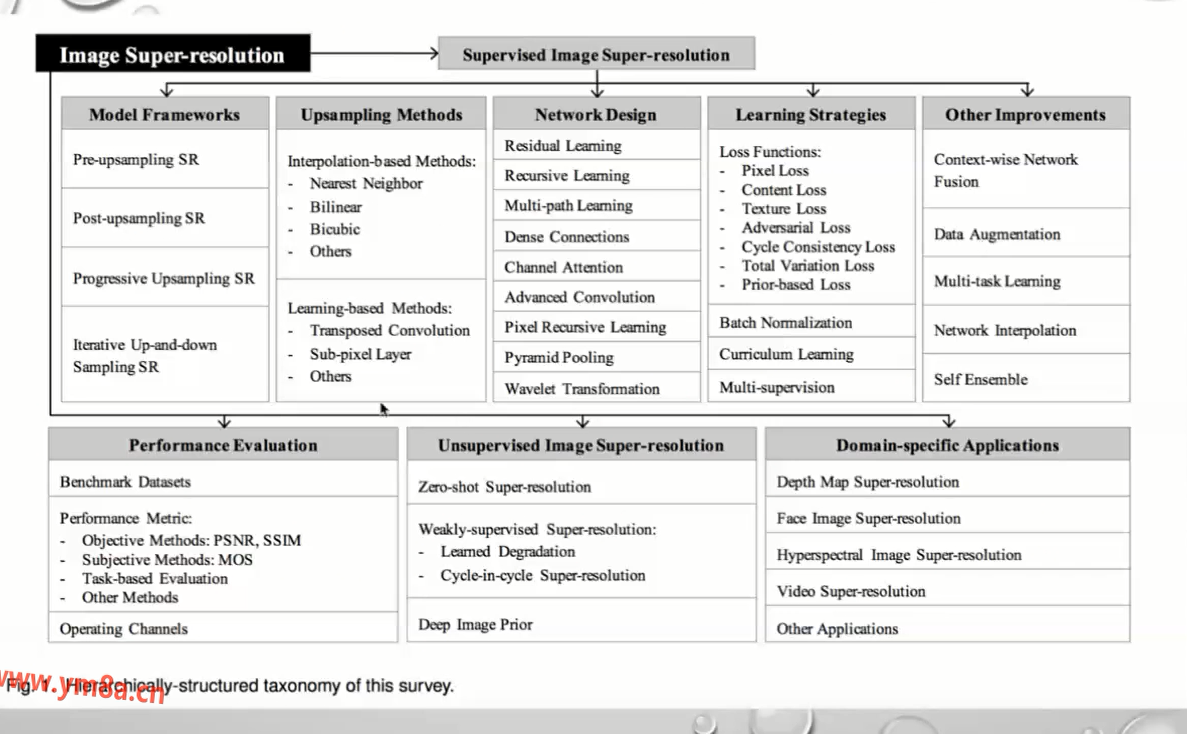
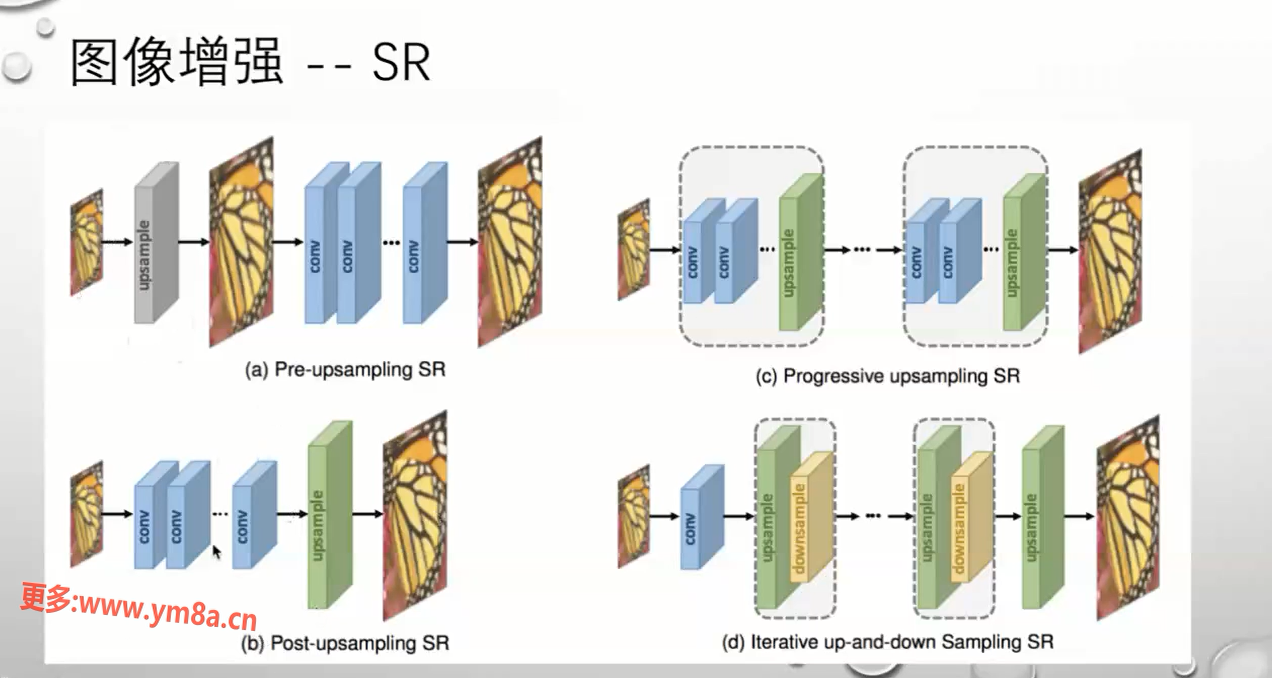
上采样
内近邻
双线性插值
卷积增大

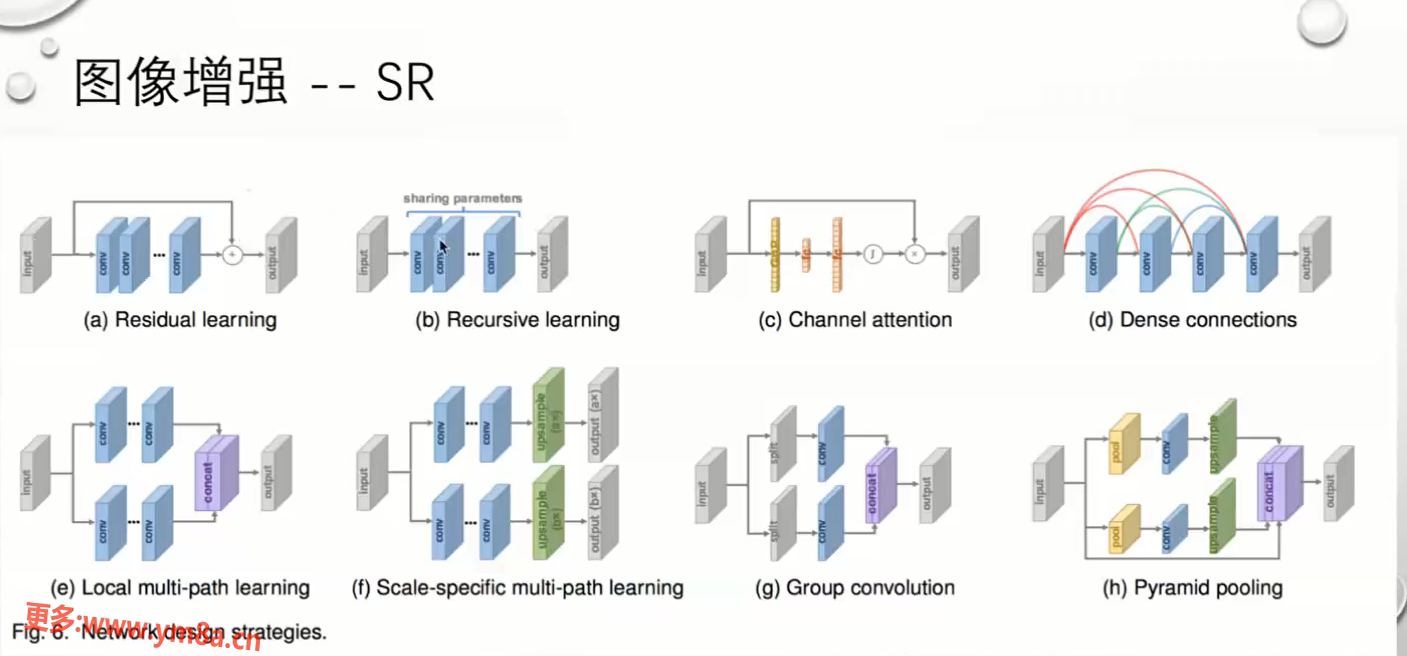

SR GAN
生成模型

2 自然场景文字检测
PIXEL LINK
PSE NET


 浙公网安备 33010602011771号
浙公网安备 33010602011771号