
Greenplum查询计划分析
这里对查询计划的学习主要是对TPC-H中Query2的分析。
1.Query的查询语句
select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment from part, supplier, partsupp, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and p_size = 6 and p_type like '%COPPER' and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AFRICA' and ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AFRICA' ) order by s_acctbal desc, n_name, s_name, p_partkey LIMIT 100;
2.查看查询计划
Greenplum中有语句可以查看查询计划,使用explain命令即可:
例:testDB=#explain select * from test1;
所以Query2的查询计划查看命令即Query2的语句之前加explain。
3.查询中涉及到的表
testdb=# \d part Append-Only Columnar Table "public.part" Column | Type | Modifiers ---------------+-----------------------+---------------------------------------------------------- p_partkey | bigint | not null default nextval('part_p_partkey_seq'::regclass) p_name | character varying(55) | p_mfgr | character(25) | p_brand | character(10) | p_type | character varying(25) | p_size | integer | p_container | character(10) | p_retailprice | numeric | p_comment | character varying(23) | Checksum: t Distributed by: (p_partkey) testdb=# \d partsupp Append-Only Columnar Table "public.partsupp" Column | Type | Modifiers ---------------+------------------------+----------- ps_partkey | bigint | not null ps_suppkey | bigint | not null ps_availqty | integer | ps_supplycost | numeric | ps_comment | character varying(199) | Checksum: t Indexes: "idx_partsupp_partkey" btree (ps_partkey) "idx_partsupp_suppkey" btree (ps_suppkey) Distributed by: (ps_partkey, ps_suppkey) testdb=# \d supplier Append-Only Columnar Table "public.supplier" Column | Type | Modifiers -------------+------------------------+-------------------------------------------------------------- s_suppkey | bigint | not null default nextval('supplier_s_suppkey_seq'::regclass) s_name | character(25) | s_address | character varying(40) | s_nationkey | bigint | not null s_phone | character(15) | s_acctbal | numeric | s_comment | character varying(101) | Checksum: t Indexes: "idx_supplier_nation_key" btree (s_nationkey) Distributed by: (s_suppkey) testdb=# \d nation Append-Only Columnar Table "public.nation" Column | Type | Modifiers -------------+------------------------+-------------------------------------------------------------- n_nationkey | bigint | not null default nextval('nation_n_nationkey_seq'::regclass) n_name | character(25) | n_regionkey | bigint | not null n_comment | character varying(152) | Checksum: t Indexes: "idx_nation_regionkey" btree (n_regionkey) Distributed by: (n_nationkey) testdb=# \d region Append-Only Columnar Table "public.region" Column | Type | Modifiers -------------+------------------------+-------------------------------------------------------------- r_regionkey | bigint | not null default nextval('region_r_regionkey_seq'::regclass) r_name | character(25) | r_comment | character varying(152) | Checksum: t Distributed by: (r_regionkey)
上面是查询中涉及到的5个表。
可以看到Greenplum使用的是列存储。
Append-Only意思是不断追加的表,不能进行更新和删除,压缩表必须是Append-Only表。我理解Greenplum主要是处理OLAP,为了能够有更大的吞吐量,使用列存储的表结构,而列存储就可以压缩,而压缩表又必须是Append-Only表,所以表的标题都使用Appen-Only Columnar Table XXX。
每个表最后都有Distributed by:(XXX),是表的分布键,即表是按照这个键值分布在不同的segment上的。
4.数据库连接图

5.查询分析结果
QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Limit (cost=46881.43..46881.53 rows=5 width=198) -> Gather Motion 4:1 (slice10; segments: 4) (cost=46881.43..46881.53 rows=5 width=198) Merge Key: public.supplier.s_acctbal, public.nation.n_name, public.supplier.s_name, part.p_partkey -> Limit (cost=46881.43..46881.44 rows=2 width=198) -> Sort (cost=46881.43..46881.44 rows=2 width=198) Sort Key (Limit): public.supplier.s_acctbal, public.nation.n_name, public.supplier.s_name, part.p_partkey -> Hash Join (cost=42481.34..46881.39 rows=2 width=198) Hash Cond: "Expr_SUBQUERY".csq_c0 = part.p_partkey AND "Expr_SUBQUERY".csq_c1 = public.partsupp.ps_supplycost -> HashAggregate (cost=23828.08..25828.08 rows=40000 width=40) Group By: public.partsupp.ps_partkey -> Redistribute Motion 4:4 (slice4; segments: 4) (cost=18228.08..21428.08 rows=40000 width=40) Hash Key: public.partsupp.ps_partkey -> HashAggregate (cost=18228.08..18228.08 rows=40000 width=40) Group By: public.partsupp.ps_partkey -> Hash Join (cost=423.08..17428.08 rows=40001 width=16) Hash Cond: public.partsupp.ps_suppkey = public.supplier.s_suppkey -> Append-only Columnar Scan on partsupp (cost=0.00..11805.00 rows=200000 width=24) -> Hash (cost=323.08..323.08 rows=2001 width=8) -> Broadcast Motion 4:4 (slice3; segments: 4) (cost=9.08..323.08 rows=2001 width=8) -> Hash Join (cost=9.08..223.08 rows=501 width=8) Hash Cond: public.supplier.s_nationkey = public.nation.n_nationkey -> Append-only Columnar Scan on supplier (cost=0.00..149.00 rows=2500 width=16) -> Hash (cost=8.83..8.83 rows=6 width=8) -> Broadcast Motion 4:4 (slice2; segments: 4) (cost=4.16..8.83 rows=6 width=8) -> Hash Join (cost=4.16..8.58 rows=2 width=8) Hash Cond: public.nation.n_regionkey = public.region.r_regionkey -> Append-only Columnar Scan on nation (cost=0.00..4.25 rows=7 width=16) -> Hash (cost=4.11..4.11 rows=2 width=8) -> Broadcast Motion 4:4 (slice1; segments: 4) (cost=0.00..4.11 rows=2 width=8) -> Append-only Columnar Scan on region (cost=0.00..4.06 rows=1 width=8) Filter: r_name = 'AFRICA'::bpchar -> Hash (cost=18623.96..18623.96 rows=489 width=214) -> Redistribute Motion 4:4 (slice9; segments: 4) (cost=4340.29..18623.96 rows=489 width=214) Hash Key: part.p_partkey -> Hash Join (cost=4340.29..18584.88 rows=489 width=214) Hash Cond: public.partsupp.ps_suppkey = public.supplier.s_suppkey -> Redistribute Motion 4:4 (slice6; segments: 4) (cost=4092.22..18287.96 rows=2443 width=58) Hash Key: public.partsupp.ps_suppkey -> Hash Join (cost=4092.22..18092.59 rows=2443 width=58) Hash Cond: public.partsupp.ps_partkey = part.p_partkey -> Append-only Columnar Scan on partsupp (cost=0.00..11805.00 rows=200000 width=24) -> Hash (cost=3970.11..3970.11 rows=2443 width=34) -> Broadcast Motion 4:4 (slice5; segments: 4) (cost=0.00..3970.11 rows=2443 width=34) -> Append-only Columnar Scan on part (cost=0.00..3848.00 rows=611 width=34) Filter: p_size = 6 AND p_type::text ~~ '%COPPER'::text -> Hash (cost=223.08..223.08 rows=501 width=172) -> Hash Join (cost=9.08..223.08 rows=501 width=172) Hash Cond: public.supplier.s_nationkey = public.nation.n_nationkey -> Append-only Columnar Scan on supplier (cost=0.00..149.00 rows=2500 width=154) -> Hash (cost=8.83..8.83 rows=6 width=34) -> Broadcast Motion 4:4 (slice8; segments: 4) (cost=4.16..8.83 rows=6 width=34) -> Hash Join (cost=4.16..8.58 rows=2 width=34) Hash Cond: public.nation.n_regionkey = public.region.r_regionkey -> Append-only Columnar Scan on nation (cost=0.00..4.25 rows=7 width=42) -> Hash (cost=4.11..4.11 rows=2 width=8) -> Broadcast Motion 4:4 (slice7; segments: 4) (cost=0.00..4.11 rows=2 width=8) -> Append-only Columnar Scan on region (cost=0.00..4.06 rows=1 width=8) Filter: r_name = 'AFRICA'::bpchar Settings: enable_nestloop=off Optimizer status: legacy query optimizer (60 rows)
下面对于查询分析中的一些参数做一些说明:
slice:Greenplum在实现分布式执行计划的时候,需要将SQL拆分成多个切片,每个slice是单裤执行的一部分SQL,每一个广播或者重分布会产生一个切片,每一个切片在每一个数据结点上都会对应的发起一个进程来处理该slice负责的数据,上一层负责该slice的进程会读取下级slice广播或重分布的数据,之后进行相应的计算。
segment:这里使用的是1个mdw、2个sdw,每个sdw中设置两个primary(greenplum安装时gpinitsystem使用的文件中设置),所以看到的segment是4。
cost:数据库自定义的消耗单位,通过统计信息来估计SQL消耗。(查询分析是根据analyze的固执生成的,生成之后按照这个查询计划执行,执行过程中analyze是不会变的。所以如果估值和真是情况差别较大,就会影响查询计划的生成。)
rows:根据统计信息估计SQL返回结果集的行数。
width:返回结果集每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。
6.对查询计划的结果进行分析
1.逻辑架构图
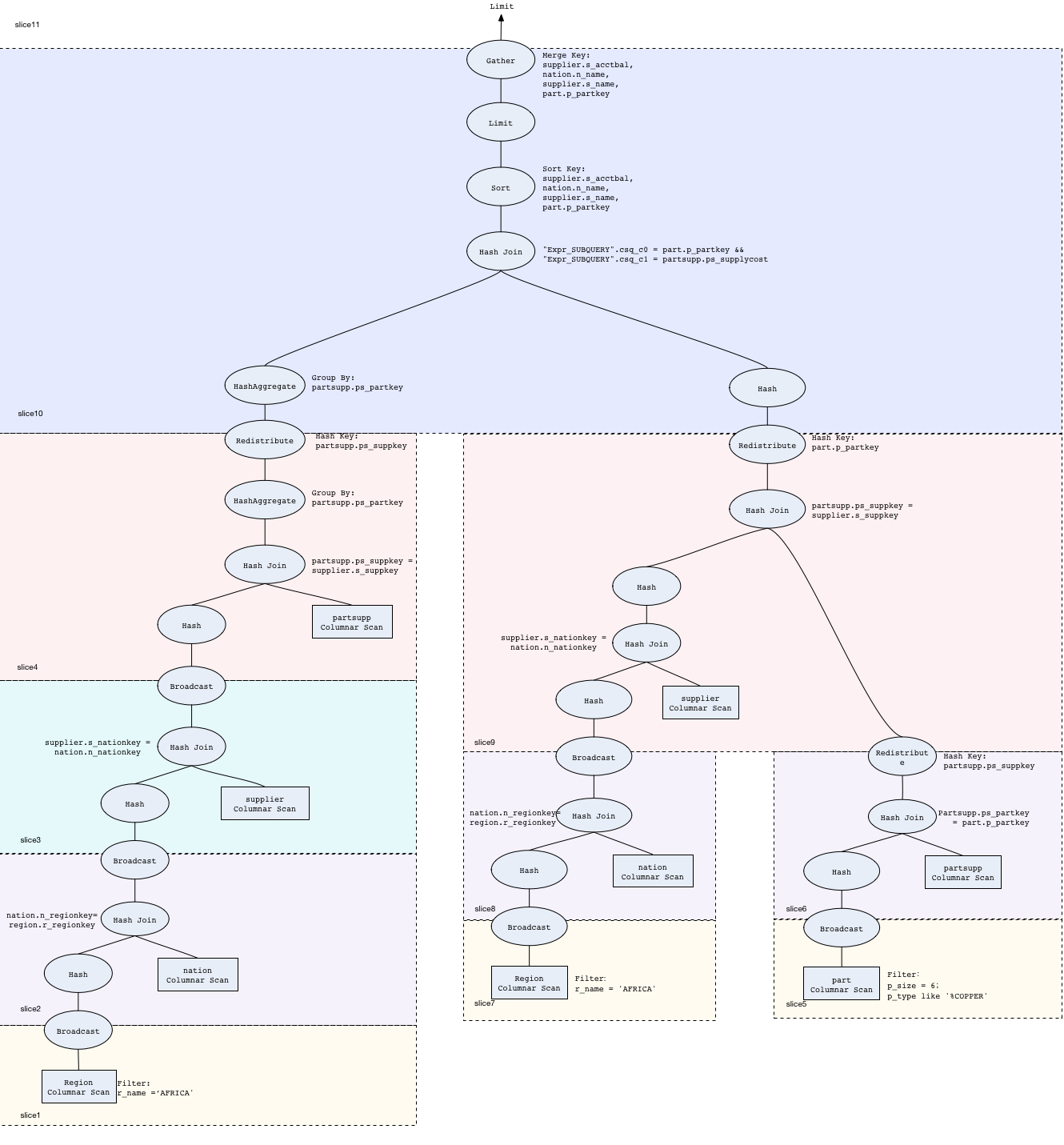
根据这个查询分析,画出查询的逻辑架构图:
2.对上图做一些补充
上图中我只画出了一个节点的逻辑架构,并没有表现出广播和重分布,下面用例子说明广播和重分布
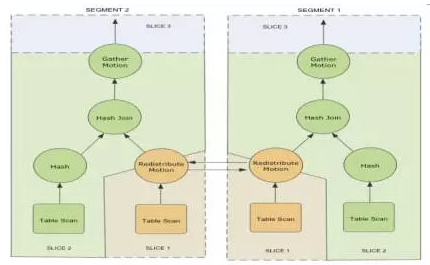
上面这个图是两个节点数据重分布的例子,这个图要完成的任务是两个表的Hash Join,由于某种原因(之后会讲述到)要将其中一个表的数据重分布到其他结点上去,以完成连接的任务。橘色部分是slice1,绿色部分是slice2,slice1中的表重分布之后到了slice2中,在slice2中做Hash Join,对连接之后的结果收集到master上。下图说明重分布时数据在slice之间传输的过程
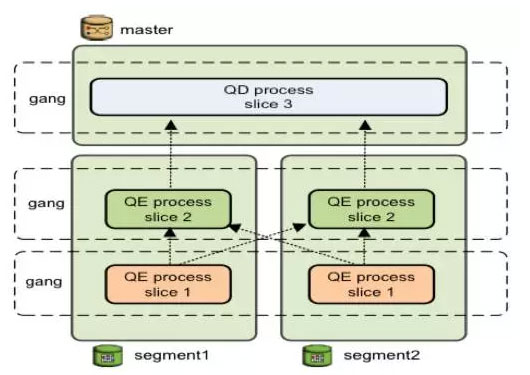
所以这也是为什么在逻辑图中,redistribution和broadcast的椭圆处于两个slice的交界处,并且同时属于两个slice。
3.能够产生slice的操作是redistribution、broadcast和gather
1.gather、broadcast和redistribution的介绍
gather:聚合,在master上讲子节点所有的数据聚合起来。一般的聚合规则是哪一个子节点的数据先返回到master上就将该节点的数据先放在master上。
broadcast:广播,发生在两表关联的时候。将每个节点上的某个表的数据全部发送到所有节点,这样每个节点都相当于有全量数据。一般,小表的时候采用广播的方法。(注:的是不论大表还是小表,最初都是分散在所有子节点上的)
redistribution:重分布,发生在两表关联的时候和group by的时候。当不满足广播的条件或者代价太大的时候,选择重分布,即按照新的分布键将各个节点上的数据重新打散到各个节点。
下面着重介绍broadcast和redistribution
2. join的时候的广播和重分布
两表连接的时候可能广播可能重分布那么什么时候使用广播,什么时候使用重分布呢?在Query中使用到的都是Hash Join,所以我们暂时只讨论这种情况下的广播和重分布。
通俗的讲,两表连接,如果是其中一个是小表,则将其广播,因为小表广播代价不会很大;如果两个表都是大表可能要重分布。分三种情况讨论:
默认情况,我们认为主键id即为分布键
①select * from A,B where A.id = B.id 分布键就是关联键,两表可以在本结点直接连接
②select * from A,B where A.id = B.id2 A的分布键就是关联键,B的分布键不是关联键。所以不能将A重分布,有两种解决方案:
a.将A广播(如果A是小表)
b.将B重分布(如果A是大表)
最终权衡取代价最小的方案
③select * from A,B where A.id2 = B.id2 A和B的分布键都不是关联键。
a.将A或B都按照id2重分布
b.将min(A,B)广播(如果较小的表是小表)
最终权衡取代价最小的方案
这里只讲述了Hash Join的情况,除此之外还有left join和full outer join,需要了解在书中135页有详解。
3.group by时候的重分布
在group by的时候也可能会产生重分布,下面介绍一下group by时重分布的原理:
group by时时先在本机上进行一个group by,然后重分布,用group by时使用的字段作为分布键重分布,重分布之后再做一次group by,所以group by操作在分布式的环境下其实是做两次group by的。书上119页图有例子说明group by的数据重分布情况。
4.分析Query2的查询计划
下面按照每个切片的方式分析Query2的查询计划。
slice1~4,包括slice10左分支的部分,是Query中的子查询部分;
slice5~9是父查询中where子句中除了ps_supplycost = (子查询)的部分;
slice10是ps_supplycost = (子查询)和父查询中的order by和limit。
①slice1和slice2:region表和nation表的hash join,数据库连接图可以看出应该属于上述第二种情况region.id=nation.id2,这里采用将region广播,说明相比重分布nation,广播region的代价更小;hash join的时候将region表hash,说明region表是个小表,这与广播region代价更小相吻合。
②slice3:hash join的原理同①
③slice4:hash join的原理同①,三次hash join实现了四个表的连接。之后做了聚合操作,对应子查询中min的操作,min的时候需要使用到group by,根据上面的介绍,知道group by在分布式环境下其实是做两次的,中间是一次重分布,这里可以在slice4和slice10的左子树看到有两次hashAggregate。
④slice5和slice6:hash join的原理同①
⑤slice7和slice8:hash join的同①
⑥slice9:左子树的hash join与slice3中的一样,不同的是连接之后,slice3进行了广播,slice9是进行了hash映射,造成这种差别的原因是这个连接表将要连接的表不同:
slice3中hash join的中间表与partsupp连接,是hash join中的第二种情况,中间表.id=partsupp.id2,由于中间表是小表,所以将中间表广播;
slice9中hash join的中间表1与slice6的中间表2连接,是hash join中的第二种情况,中间表1.id=中间表.id2,虽然中间表1是小表,但是没有广播中间表1,而是将中间表2重分布,因为中间表1广播到4个节点的代价总和大于将中间表2重分布。
⑦slice10,hash join之后,对每个子节点的数据按照四个键值排序,每个节点舍弃掉一部分数据(排序比较靠后,不可能包含在最后的limit结果中),将排序靠前的数据输出给master,这个过程叫做gather,使用排序时的四个键值作为merge key
取排序之后的一部分(这部分一定包含最终结果)输出给master,另一部分舍弃掉,不输出给master。master得到最终聚合的数据,再进行一次limit操作,这次limit得到的是query需要的100条数据。
以上就是对Query2的查询计划结果的分析,还有一些问题尚未弄清楚:
1.关联键是否默认是主键?是(书上201页)
2.列存储是否有主键,是否有完整性约束?应该是有的,因为列存储取到相应属性之后还要将他们组合成行表。
3.在查询计划的结果中,为什么query中的min(ps_supplycost)体现在查询计划中是group by(ps_partkey)而非group by(ps_supplycost)
4.书上讲的hashAggregate和groupAggregate的原理不是很清楚
5.slice10中的hash join的hash key不明白
6.order by多个键值是怎么排序的
心得:
1.觉得画图写东西有点浪费时间,但是发现不画出来写出来,其实有些东西理解的不够,或者有偏差。记录下来有助于深入理解知识
2.写东西相当于对知识体系的一次整合,没整理的时候,所有东西在大脑不是混沌的,真理之后知识变得逻辑、有序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号