意图识别
意图识别
-
基础概念
识别文本中蕴含的主题和意图,是偏向于应用层的自然语言理解任务。篇章级别的意图识别,将其认为是一个模式识别(机器学习)的分类问题,意图分类。
| 文本类型 | 常用建模方法 | 应用举例 |
|---|---|---|
| 短语/句子 | 文法、关键词、深度神经网络 | 搜索引擎、多轮对话 |
| 段落 | LDA、SVM、聚类、深度神经网络等 | 主题建模、阅读理解 |
-
流程
-
意图定义
定义的意图类别具有客观描述性、唯一性,标注规范方便理解,同一个模型中不同类别的意图不应该具有交叉、包含等关系,应该具有独立性,比如性别(男、女),比如新闻报道的主题性质(体育、经济、政治、军事) -
数据收集和标注
按照定义的意图范围进行数据标注 -
数据预处理
英文——词干提取(cats转换为cat,effective转换为effect);词性归并(eat,ate,eatein,eating)
中文——分词;偏旁部首拆分;
其他——去除噪声数据、停顿词(stopwords)、低频词、语气词 -
特征提取
以LDA(Latent Dirichlet Allocation)概率主题模型为例,
LDA 在主题-类别层的表示上,采用了一个Dirichlet概率分布。这是一个连续分布,可以给未知文本分配属于某个主题集的概率,一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语,p(w|d)=p(w|t) x p(t|d)
LDA生成过程
对每篇文档,从主题分布中抽取一个,输入:文档集合 + 主题topic数量T;
从抽取的主题对应的单词分布中,抽取一个单词,重复至遍历文档中的每一个单词;
输出:每篇文档在T个topic上的分布概率
word embedding
embedding英文有栽种、嵌入的意思,在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective和structure-preserving的。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
injective——就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然;
structure-preserving ——结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2
1)One-hot Representation:eg.“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...],问题1、维数灾难,2、词汇鸿沟:两个词之间是孤立的;
2)Distributed Representation:eg.[0.792, −0.177, −0.107, 0.109, −0.542, ...],最大的贡献是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量;
3)Word2vec:常用的模型有CBOW模型、Skip-Gram模型。Word2vec是 Google 在 2013 年开源的一款将词表征为实数值向量的高效工具,1、使用 Distributed representation 的词向量表示方式,2、采用的是n元语法模型(n-gram model),构建了一个多层神经网络,然后在给定文本中获取对应的输入和输出,在训练过程中不断修正神经网络中的参数,最后得到词向量;
![image]()
4)CBOW模型:continuous bag-of-words model,能够根据某个词周围n-1个词来预测出这个词本身;
5)Skip-Gram模型:能够根据某个词本身来预测该词周围n-1个词的词向量 -
模型训练
1)SVM支持向量机:
试图把分界线放在最佳位置,好让在分界线的两边有尽可能大的间隙;
2)神经网络LSTM(Long Short-Term Memory)长短时记忆模型,:
属于rnn(Recurrent Neural Networks)的一种,控制着信息输入对细胞状态的改变程度。模型输入为文本词向量序列(X0,X1,X2…),依次通过LSTM网络,得到对应的隐含层向量(h0,h1,h2…),对这些量求平均,得到文本的特征向量h,最后用logistic回归进行分类,输出结果。池化层max pooling用的很多,全连接层softmax常用于多分;
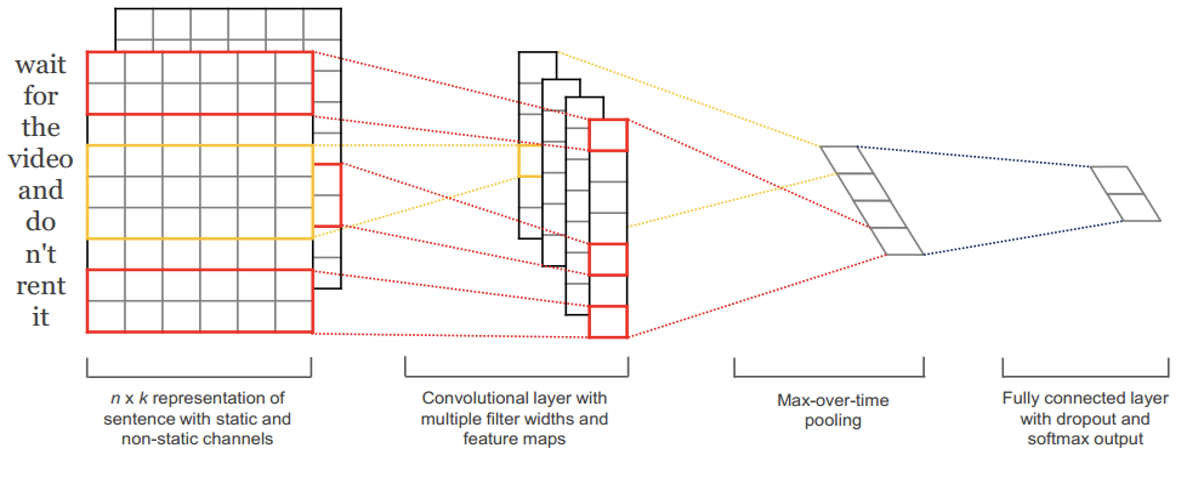
3)神经网络CNN:
输入层:用word embedding或随机赋值的方式,表征一个需要输入的句子;这里采用了双通道的输入,一个输入矩阵保持不变,一个输入矩阵会随着反向传播对自身做调整;
卷积层:对输入矩阵用一组滤波器做卷积运算,再将双通道结果合并;文章中窗函数的高度取值为3、4、5;
池化层:同基础结构,用max-pooling得到句子的特征向量;
全连接层:最后,以全连接+softmax的方式计算要输出的分类结果;这里regularization还使用了dropout的方法
![image]()
4)文法+后处理规则:
文法:用一定规则来对自然语言进行描述,类似于正则表达式,可以用文法规则覆盖业务中的句子集合。
ABNF:扩充的巴科斯范式,规则符号集,文法的实现形式。所以我们的文法文件,也称为abnf文件,以abnf为扩展名。例如 话费查询.abnf -
模型预测
-
效果分析
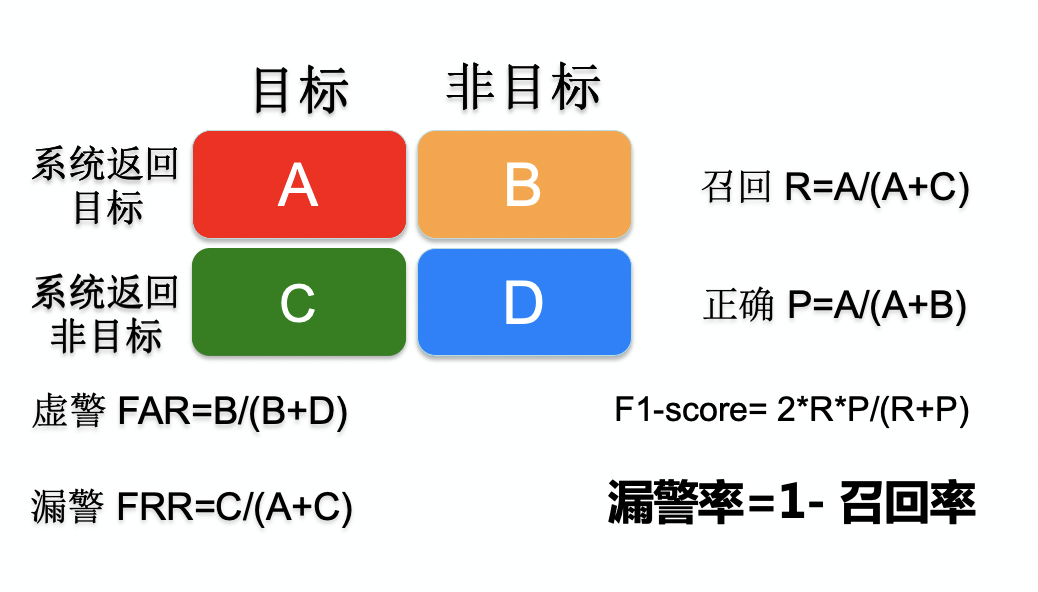
准确率、召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate,Acc),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的目标文件 / 系统所有目标的文件总数
准确率(Precision) = 系统检索到的目标文件 / 系统所有检索到的文件总数
![image]()
关注内容:
1、业务数据分析,关注核心指标上限水平;
2、是否可以通过其他方法降低虚警,提高正确率;
3、调节得分门限,在不同的得分段分析召回率和正确率,给出排序,提高用户的正确率感受
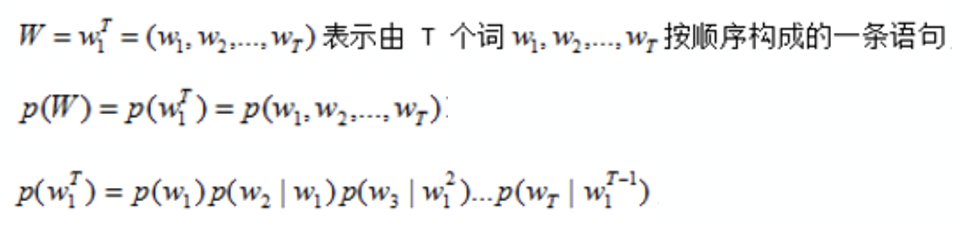
识别性能≈难度×特征×模型×数据:
1.意图定义的区分性强弱
2.建模方法的合理性
3.训练数据集合的质量(训练样本的规模、对各种场景覆盖度、标注正确性、与测试集合的匹配度)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号