
Python——正则
简介
正则:用模式匹配字符串
元字符下的匹配字符和量词组成
匹配字符
单字符串
[ 任意字符组合 ]:匹配中括号内其中之一
():分组。在python内,用(?P<键值>)标记分组内匹配的字符串
\d:任意数字
.:除换行符外任意字符
[\s\S]:任意字符
量词:
{n,m}:匹配至少n次,至多m次。正则默认贪婪模式,向m次靠近
{n}:匹配固定n次
*:{0,m}
+:{1,m}
贪婪模式:
正则默认开启贪婪模式,在量词后加?可取消
Python内:
(?P<键值>[\s\S]*?),用分组标记需要提取的数据
使用:
匹配思路:
举例子,我要匹配下面这张图片里的 漫画名、漫画作者、漫画图片链接、漫画分类
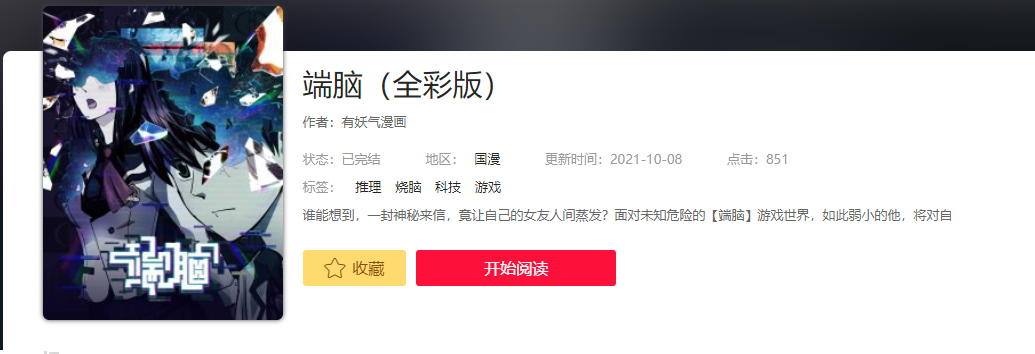
1. 开头匹配包裹所有数据的标签
2. 通过[\s\S]*?跳到需要数据标签开头。
3. 用分组提取该数据
4.写上此标签结尾
5.重复第二步到需要的数据都被分组包裹
<div class="banner_detail_form"> <div class="cover"> <img src="https://img.acgzone.net/images/cover/202006/1592986867QvvH0yVfTECZ7SEi.jpg" alt="端脑(全彩版)"> </div> <div class="info"> <h1>端脑(全彩版)</h1> <p class="subtitle">作者:有妖气漫画</p> <p class="tip"> <span class="block">状态:<span>已完结</span></span> <span class="block ticai">地区:<a href="/booklist/?area=1" target="_blank">国漫</a></span> <span class="block">更新时间:2021-10-08</span> <span class="block">点击:851</span> </p> <p class="tip" style="margin-top:10px;"> <span class="block">标签: <a href="/booklist/?tag=推理" target="_blank">推理</a> <a href="/booklist/?tag=烧脑" target="_blank">烧脑</a> <a href="/booklist/?tag=科技" target="_blank">科技</a> <a href="/booklist/?tag=游戏" target="_blank">游戏</a> <a href="/booklist/?tag=" target="_blank"></a> </span> </p> <p class="content" style="position: relative;overflow : hidden;text-overflow: ellipsis;display: -webkit-box;-webkit-box-orient: vertical;"> 谁能想到,一封神秘来信,竟让自己的女友人间蒸发?面对未知危险的【端脑】游戏世界,如此弱小的他,将对自 </p> <div class="bottom" style="width: 850px;bottom: 30px;"> <a href="javascript:void(0);" id="addfavor" class="btn-1 btn_collection"><i class="icon icon-fav2"></i>收藏</a> <a href="/chapter/575710" class="btn-2">开始阅读</a> </div> </div> <script> $('#addfavor').click(function () { var val = $(this).attr('data-val'); $.post({ url:`/addfavor`, data:{'book_id' : 26027, 'val' : val }, success: function (res) { if (res.err == 1){ ShowDialog(res.msg); } else { if (res.isfavor == 1){ //表示收藏了,将控件状态改为已收藏 $('a.btn-1').html('<i class="icon icon-fav2-full"></i>已收藏</a>').attr('data-val',1).addClass('active'); ShowDialog('收藏成功'); } else { //更改为未收藏 $('a.btn-1').html('<i class="icon icon-fav2"></i>收藏</a>').attr('data-val',0).removeClass('active'); ShowDialog('取消收藏'); } } }, }) }) </script> <div style="clear: both;"></div> </div>
# 超链接 https://zhwsxx.com/book/26027
<div class="banner_detail_form">[\s\S]*?<h1>(?P<cName>[\s\S]*?)</h1>[\s\S]*?<p class="subtitle">作者:(?P<cAuthor>[\s\S]*?)</p>[\s\S]*?<span class="block">点击:(?P<cClick>[\s\S]*?)</span>
思路二
根据最近标识符进行开头
问题1:正则本身就是匹配,匹配中写分组再匹配有什么意义?
标记数据取值、在python中括号标注的匹配用于提取该分组数据
问题2:在正则思路中。为什么分组取得数据后,不直接跳到下一个需要取数据的开头。
[\s\S]*?分组标记的数据是在范围内取得,有范围必定有上下限。
没有下限会和后面跳过代码重合,导致数据范围变大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号