

Java 数据持久化系列之 HikariCP (一)
在上一篇《Java 数据持久化系列之池化技术》中,我们了解了池化技术,并使用 Apache-common-Pool2 实现了一个简单连接池,实验对比了它和 HikariCP、Druid 等数据库连接池的性能数据。在性能方面,HikariCP遥遥领先,而且它还是 Spring Boot 2.0 默认的数据库连接池。下面我们就来了解一下这款明星级开源数据库连接池的实现。
本文的主要内容包括:
- HikariCP 简介,介绍它的特性和现况。
- HikariCP 的配置项详解,分析部分配置的影响。
- HikariCP 为什么这么快,介绍其优化点。
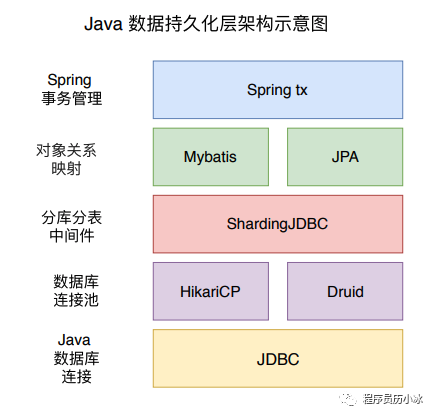
这里啰嗦两句,由于本系列会涉及很多开源项目,比如说 HikariCP、Druid、Mybatis等,所以简单聊一下我对学习开源项目的认识,这也是我自己行文或者组织系列文章顺序的思路,后续有时间再详细总结一下。
- 安装并检查提供的所有工具,比如 Redis 目录下的 redis-check-aof 等工具的作用,这些工具都是官方特意提供的,一般都是日常经常要使用的,了解其功能。
- 运行,学习所有配置项的功能,原理和优缺点,比如 Redis 的内存溢出控制策略 maxmemory-policy 的可选值都有哪些,分别对应的策略是什么含义,适用于哪些场景等。
- 原理研究,针对关键特性进行研究,比如 Netty 的异步 NIO 和零拷,HikariCP的高并发
- 优缺点对比,同类型开源产品对比,一般某一领域的开源项目往往有多个,比如说 Redis 和 Memcache,Kafka 和 RocketMQ,这些项目之间往往各有优劣,适用场景,了解了这些,也往往进一步加深了对项目关键特性和原理的研究。
- demo或者性能测试,按照自己的使用场景去进行 Demo 验证和性能测试
- 根据demo来查看调用栈,阅读关键源码,带着问题去阅读源码,比如阅读 Redis 如何进行 aof 持久化等。
- 试图修改源码,只是阅读源码其实很多时候无法体会到代码为什么实现成这样,在有余力的情况下修改源码,比较实现方案,可以更好的理解实现方案,并未后续成为 commiter 打下基础。
HikariCP 简介
Hikari 在日语中的含义是光,作者特意用这个含义来表示这块数据库连接池真的速度很快。官方地址是 https://github.com/brettwooldridge/HikariCP。
Hikari 最引以为傲的就是它的性能,所以作者也在贴下了很多性能数据和用户反馈。笔者也在上一篇文章中使用它的 benchmark 进行了性能对比。
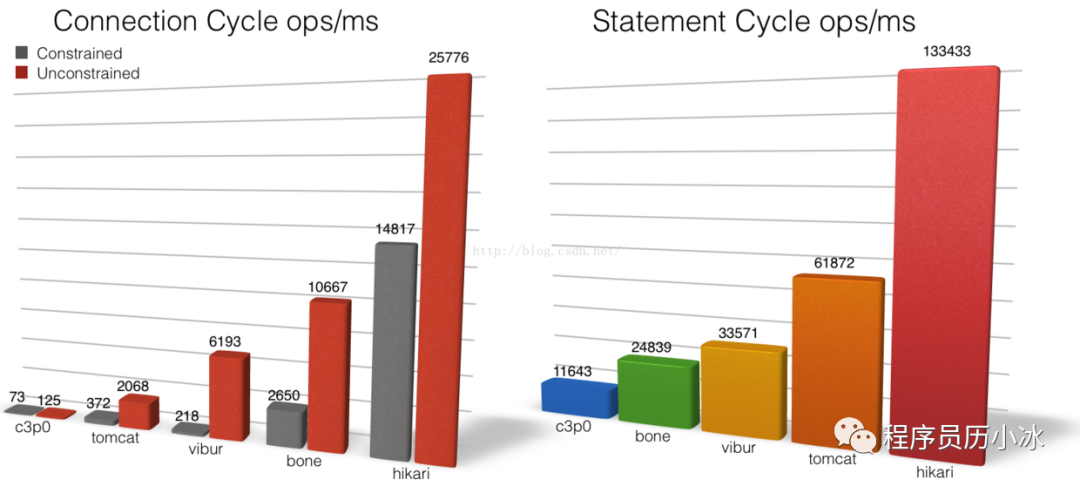
从上图中可以直观的看出,Hikari 在 获取和释放 Connection 和 Statement 方法的 OPS 不是一般的高,那是相当的高,基本上是碾压其他连接池,这里就不一一点名了。
除了 OPS 外,HikariCP 的稳定性也更好,性能毛刺更少。
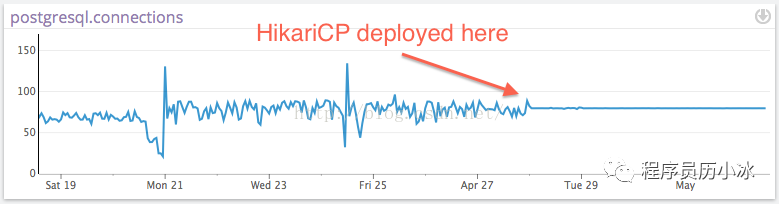
除了性能之外,HikariCP 在很多编码细节上也下了很多功夫。
比如说使用 JDBC4Connection 的 isValid 函数来检查 Connection 有效性,该函数使用原生的 ping 命令检查,比一般数据库连接池默认使用的 select 1 语句快一倍,性能更好。
更加遵循 JDBC 规范,在关闭 Connection 之前先关闭与之关联的 Statement 和ResultSet 等。对 JDBC 不了解的同学可以阅读本系列中第一篇文章。
对于数据库连接中断的情况,HikariCP 也处理的更加出色。作者做了实验,通过测试获取 Connection 的超时场景,各个数据库都设置了跟连接超时 connectionTimeout 类似的参数为 5 秒钟。其中 HikariCP 等待5秒钟后,如果连接还是没有恢复,则抛出一个SQLExceptions 异常,后续再获取 Connection 也是一样处理。其他数据库连接池的处理则不理想,要么是一直等到 TCP 超时才响应,比如 Dbcp2 和 C3PO,要么是需要修改默认配置,比如说 Vibur。

具体文章可以阅读 《Bad Behavior: Handling Database Down》一文(链接在文末)。
配置详解
下面,我们来详细了解一下 HikariCP 的相关配置。
首先,Spring Boot 2.0 的默认数据库连接池配置就是 HikariCP,所以你无需引入其他依赖,直接在 yml 文件中进行 HikariCP 的相关配置即可。基础配置如下所示。
spring:
datasource:
hikari:
minimum-idle: 20
maximum-pool-size: 100
pool-name: dbcp1
idle-timeout: 10000
### Driver 类名和 数据库 URL,用户名密码等 datasource 基础配置
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3300/test?rewriteBatchedStatements=true&autoReconnect=true&useSSL=false&useUnicode=true&characterEncoding=utf-8
username: ${AUTH_DB_PWD:root}
password: ${AUTH_DB_USER:test}
### 显示指定数据库连接池,默认也是 HikariDataSource,指定数据库连接池
type: com.zaxxer.hikari.HikariDataSource
HikariCP 的所有配置及其默认值可以在 HikariConfig 中查看,下面我们来依次介绍较为常用的配置。
- autoCommit:控制从数据库连接池返回的 Connection 是否默认事务自动提交行为,默认为 true。
- connectionTimeout:控制客户端在获取池中 Connection 的等待时间,如果没有连接可用的情况下超过该时间,则抛出 SQLException 异常,比如说 getConnection时连接数已经大于 maximumPoolSize 并且一直没有空闲的连接 。默认 30 s。
- idleTimeout:控制 Connection 闲置在池中的最大时间。当 minimumIdle 值大于 maximumPoolSize 小时才生效,而且只有当池中 Connection 数量大于 minimumIdle 时才根据该时间进行 Connection 剔除。默认为 600000 s(10 分钟)。
- maxLifetime:控制池中 Connection 的最大生命周期。处于使用中的 Connection 不会因为自身生命超出该时间而被剔除,只有等到被归还关闭后才会被剔除。HikariCP 作者强烈建议用户设置该值,并且它应该比任何数据库服务的连接事件限制短几秒。默认为 1800000 s(30分钟)。
- connectionTestQuery:控制数据库连接池借出 Connection 前对其进行检查,如果使用的 Driver 是 JDBC4 则不建议设置该属性。不配做会使用 ping 命令进行检查,其性能大致为 select 1 的1倍左右。默认为无。
- minimumIdle:控制池中维护的空闲 Connection 的最小数量。如果空闲连接数大小该数值,并且总连接数小于 maximumPoolSize,则 HikariCP 将尽力快速添加新的 Connection。默认等于 maximumPoolSize。
- maximumPoolSize:控制数据库连接池 Connection 的最大数量,包括空闲和正在使用的。
对于 minimumIdle 和 maximumPoolSize 对数据库连接数量的影响如下图所示,当 minimumIdle 小于 maximumPoolSize 时,连接数量会在该区间内变化,空闲时间超过 idleTimeout 的连接会被剔除,直到数量变为 minimumIdle 位置。
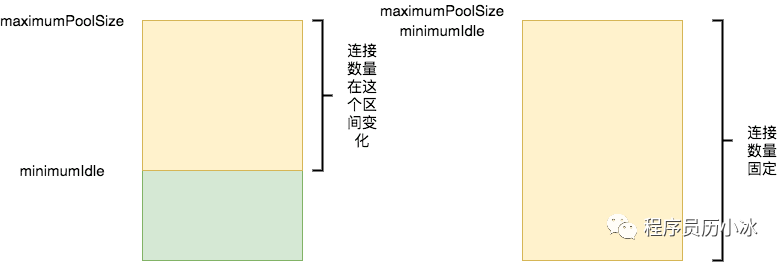
但是 HikariCP 的作者建议不设置 minimumIdle,或将其设置为maximumPoolSize 相同数值(默认也是如此),将 HikariCP 充当一个固定大小的连接池使用,这样可以最大限度提高性能和对突发流量的相应能力。
HikariCP 对于这些配置的默认值都进行最优配置,使用时往往不需要调整。但是使用场景千变万化,有些情况下还是需要根据自己的情况进行调整,后续文章会对较为重要的几个属性的影响和调整技巧做详细的说明。
为什么这么快
官网详细地说明了 HikariCP 所做的一些优化,总结如下:
- 字节码精简 :优化代码,直到编译后的字节码最少,这样,CPU 缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如 HikariCP 的 Statement proxy 只有100行代码,只有 BoneCP 的十分之一;
- 自定义的 FastList 代替 ArrayList:避免每次 get 调用都要进行 range check,避免调用 remove 时的从头到尾的扫描;
- 自定义集合类型 ConcurrentBag,提高并发读写的效率;
- 其他针对 BoneCP 缺陷的优化,比如对于耗时超过一个 CPU 时间片的方法调用的研究(但没说具体怎么优化)
HikariCP 具体的优化细节可以阅读作者写的《Down the Rabbit Hole》一文(地址链接在文末),Rabbit Hole 是指兔子洞,寓意是复杂奇艺且未知的境地,来自爱丽丝漫游奇境记中爱丽丝掉入兔子洞。
下面我们就简单说明一下几项优化。
使用 FastList 替代 ArrayList
HikariCP 通过分析 Connection 使用 Statement 的场景,提出了使用 FastList 代替 ArrayList 的优化方案。
FastList 是一个 List 接口的精简实现,只实现了接口中必要的几个方法。它主要做了如下几点优化:
- ArrayList 每次调用 get 方法时都会进行 rangeCheck 检查索引是否越界,其实只要保证索引合法那么 rangeCheck 就成为不必要的计算开销。因此,FastList 不会进行该检查。
- ArrayList 的 remove(Object) 方法是从头开始遍历数组,而 FastList 是从数组的尾部开始遍历,在 HikariCP 使用的场景下更为高效。
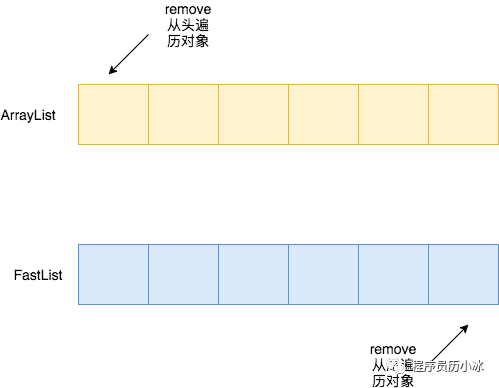
HikariCP 使用列表来保存打开的 Statement,当 Statement 关闭或 Connection 关闭时需要将对应的 Statement 从列表中移除。通常情况下,同一个Connection创建了多个 Statement 时,后打开的 Statement 会先关闭。所以 FastList在该场景下更加高效。
优化并精简字节码
这里需要声明一项误区,并不是使用字节码技术使得代码性能更好。HikariCP 使用字节码技术的目的是减少重复代码的编辑工作,生成统一的代码逻辑。但是在这个基础之上,HikariCP 优化并精简了生成的字节码,提高了性能。
HikariCP 使用 Java 字节码修改类库 Javassist 来生成委托实现动态代理。动态代理的实现在 ProxyFactory 类。Javassist 生成动态代理,是因为其速度更快,相比于 JDK Proxy 生成的字节码更少,精简了很多不必要的字节码。
HikariCP 还对项目进行了 JIT 优化。比如说 JIT 方法内联优化默认的字节码个数阈值为 35 字节,低于 35 字节才会进行优化。而 HikariCP 对自己的字节码进行研究,精简了部分方法的字节码,使用了诸如减少了类继承层次结构等方式,将关键部分限制在 35 字节以内,有利于 JIT 进行优化。
比如说 HikariCP 对 invokevirtual 和 invokestatic 两种字节码中函数调用指令的优化。
HikariCP 的早期版本使用单例工厂实例来生成 Connection、Statement 和 ResultSet 的代理。该单例工厂实例以全局静态变量 (PROXY_FACTORY) 的形式存在。
public final PreparedStatement prepareStatement(String sql, String[] columnNames) throws SQLException
{
return PROXY_FACTORY.getProxyPreparedStatement(this, delegate.prepareStatement(sql, columnNames));
}
使用这种方式,编辑出来的字节码如下所示 (可以使用 javap 等方式查看字节码)。下边有详细的注解,但更加详细字节码的含义还需大家自行学习一下。
public final java.sql.PreparedStatement
prepareStatement(java.lang.String, java.lang.String[]) throws java.sql.SQLException;
flags: ACC_PRIVATE, ACC_FINAL
Code:
stack=5, locals=3, args_size=3
0: getstatic #59 // 获取静态变量 PROXY_FACTORY,放入操作数栈
3: aload_0 // 本地变量0中加载值,放入操作数栈,也就是 this
4: aload_0 // 本地变量0中加载值,放入操作数栈,也就是 this
5: getfield #3 // 获取成员变量 delegate 放入操作数栈,使用操作栈中的 this
8: aload_1 // 将本地变量1放入操作数栈,也就是 sql 变量
9: aload_2 // 将本地变量1放入操作数栈,也就是 columnNames 变量
10: invokeinterface #74, 3 // 调用 prepareStatement 方法
15: invokevirtual #69 // 调用 getProxyPreparedStatement 方法
18: return
通过上边字节码发现,首先要调用 getstatic 指令获取静态对象,然后再调用 invokevirtual 指令执行 getProxyPreparedStatement 方法。
HikariCP 后续对此进行了优化,直接使用静态方法调用,如下所示。getProxyPreparedStatement 方法是 ProxyFactory 静态方法。
public final PreparedStatement prepareStatement(String sql, String[] columnNames) throws SQLException
{
return ProxyFactory.getProxyPreparedStatement(this, delegate.prepareStatement(sql, columnNames));
}
这些修改后,字节码如下所示。
private final java.sql.PreparedStatement
prepareStatement(java.lang.String, java.lang.String[]) throws java.sql.SQLException;
flags: ACC_PRIVATE, ACC_FINAL
Code:
stack=4, locals=3, args_size=3
0: aload_0
1: aload_0
2: getfield #3 // 获取 delegate 变量
5: aload_1
6: aload_2
7: invokeinterface #72, 3 // 调用 prepareStatement 方法
12: invokestatic #67 // 调用 getProxyPreparedStatement 静态方法
15: areturn
这样修改后不再需要 getstatic 指令,并且使用了 invokestatic 代替 invokevirtual 指令,前者 invokestatic 更容易被JIT优化。另外从堆栈的角度来说,堆栈大小也从原来的 5 变成了 4,方法字节码数量也更少了。
ConcurrentBag:更好的并发集合类实现
ConcurrentBag 的实现借鉴于C#中的同名类,是一个专门为连接池设计的lock-less集合,实现了比 LinkedBlockingQueue、LinkedTransferQueue 更好的并发性能。
ConcurrentBag 内部同时使用了 ThreadLocal 和 CopyOnWriteArrayList 来存储元素,其中 CopyOnWriteArrayList 是线程共享的。
ConcurrentBag 采用了 queue-stealing 的机制获取元素,首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再次从共享的 CopyOnWriteArrayList 中获取。此外,ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享 false sharing 的发生。
ConcurrentBag 的具体原理和实现将是下一篇文章的重点内容。
后记
按照文章开始的开源项目研究顺序,下一篇文章我们会着重了解 HikariCP 的关键特性及其源码实现,详细分析它为什么这么快,并通过 JMH 实验数据分析这些优化是如何影响性能的。

参考
- https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole
- https://github.com/brettwooldridge/HikariCP/wiki/Bad-Behavior:-Handling-Database-Down
- http://blog.didispace.com/Springboot-2-0-HikariCP-default-reason/
- https://blog.csdn.net/ClementAD/article/details/46928621
- http://www.timebusker.top/2019/02/15/JAVA杂记-Hikaricp源码解读/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号