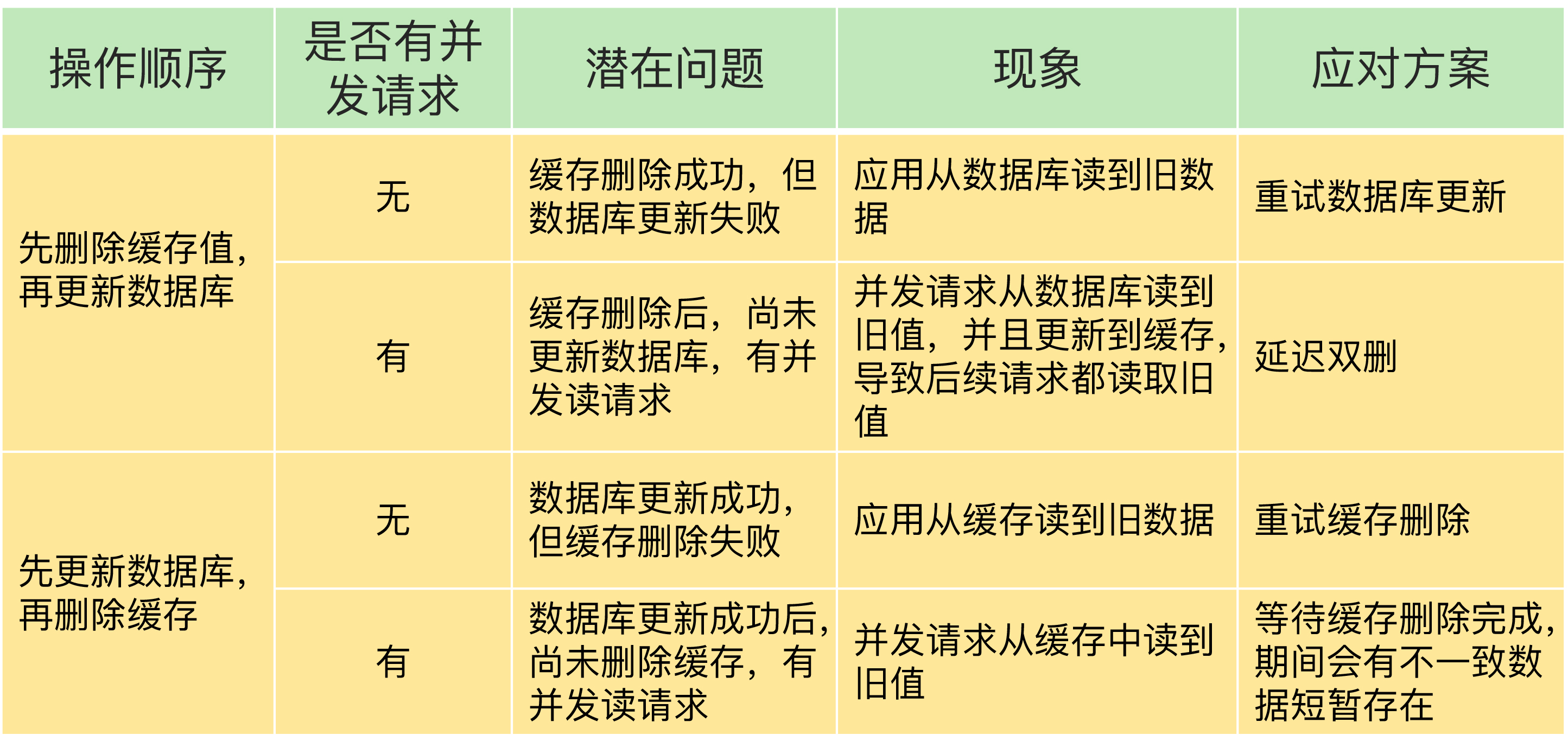
Redis总结
Redis
整体结构
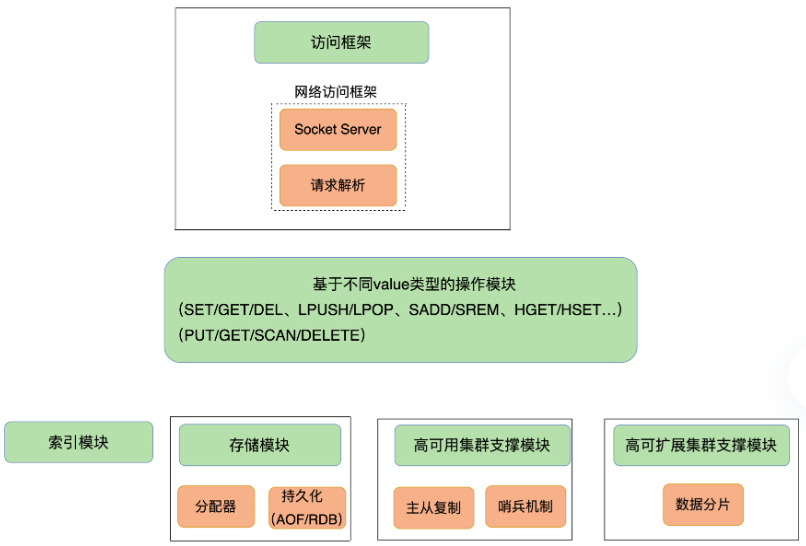
- 一个访问流程如下
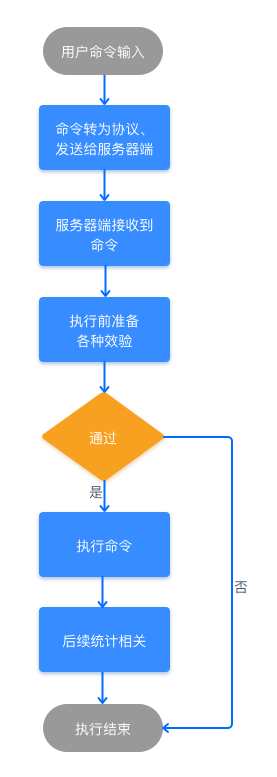
client发起命令
-> 命令被客户端socket封装成网络包, 通过TCP传输协议/RESP通讯协议发送到服务端
-> 在服务端, 访问框架的socket监听6379端口, 收到后使用多路复用框架框架, 将包转给handler验证并解析
-> 解析完命令后, 使用索引模块找到key对应的value
-> 操作模块对value的数据结构进行操作, 并统计操作数作为返回结果
-> 访问框架将结果封装为网络包, 发回客户端
五大底层数据结构
- 设计思想:
- 当数据量小, 通过数组实现压缩数据结构, 可以用下标访问, 更快
- 当数据量大, 维护数组的元数据占用空间随之增长, 所以使用普通存储
- redis支持键值对形式<string, value>, 其中value是由5种原子数据结构复合而成
| 复合结构 | 原子压缩存储 | 压缩条件 | 原子普通存储 | 备注 |
|---|---|---|---|---|
| string | int[] embstr[] raw[] |
纯数字 短字符串 长字符串 |
SDS | 基础数据类型, 也可作为key |
| list | ziplist quicklist |
1. 列表中保存的单个数据小于 64 字节 2. 列表中数据个数少于 512 个。 |
linkedlist | quicklist即分段的ziplist, 每个quicklistnode下都链接ziplist, node之间是双向链表 |
| hash | 压缩字典 | 1. 字典中保存的键和值的大小都要小于 64 字节 2. 字典中键值对的个数要小于 512 个。 |
散列表 | 1. 使用链表法解决冲突 2. 当装载因子>=1, 触发动态扩容, 大小约为原Entry[]的2倍 3. 当装载因子<0.1, 触发动态缩容, 大小约为装载Entry的2倍 4. 动态扩缩容耗时, 需要rehash, 使用渐进式扩缩容 |
| set | int[] | 1.存储的数据都是整数 2.存储的数据元素个数不超过 512 个 |
散列表 | 同上 |
| zset | ziplist | 1.所有数据的大小都要小于 64 字节 2.元素个数要小于 128 个 |
skiplist | --- |
-
对于不同的数据结构, 操作模块提供的接口也不同
-
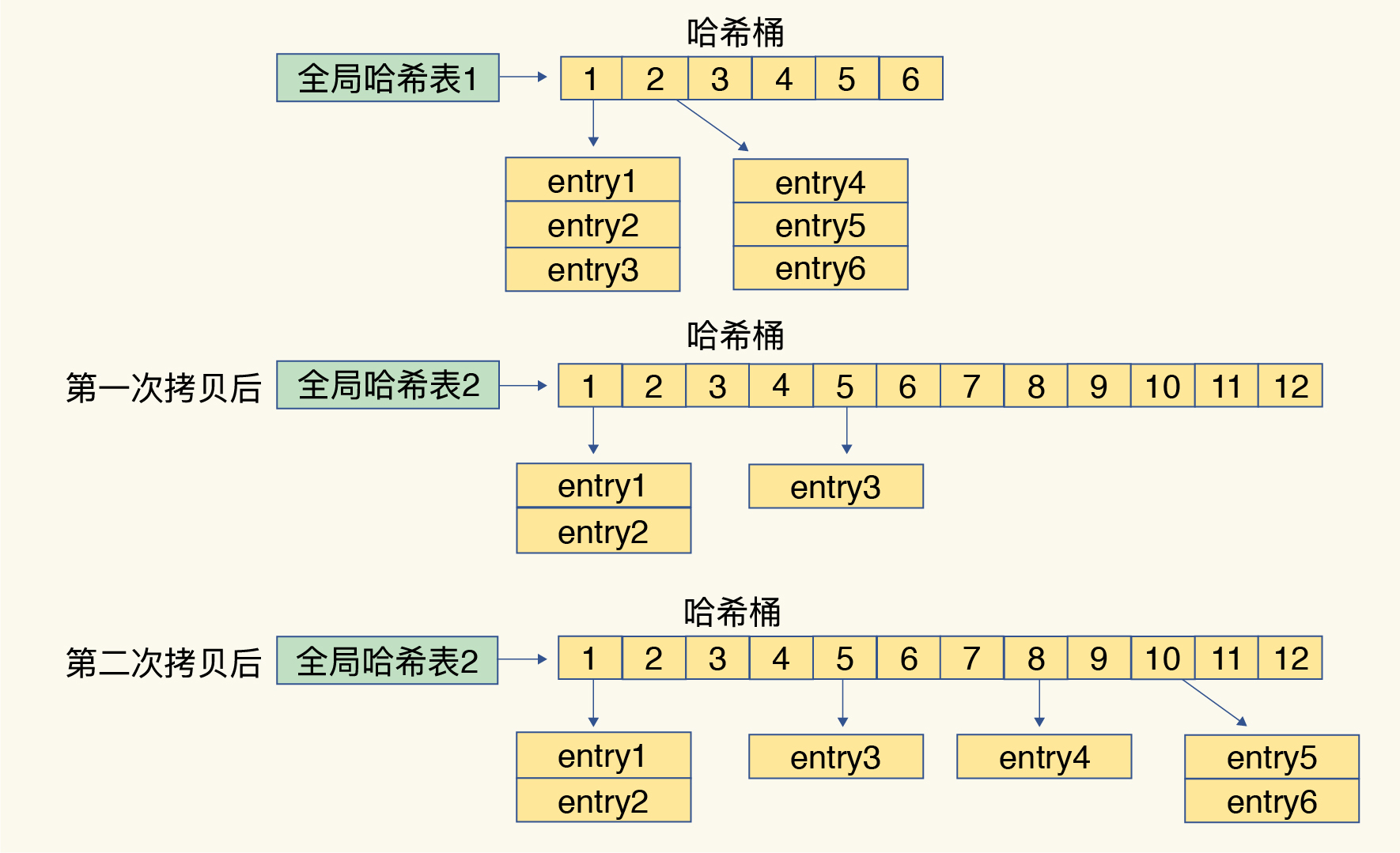
渐进式rehash
- 思想类似写时复制COW, 当达到阈值需要扩/缩容时, 准备一个更大/小的hash表, 在原表功能不变的情况下, 每一次写操作将一个slot上的所有entry拷贝到新表, 新插入的值也在新表
![img]()
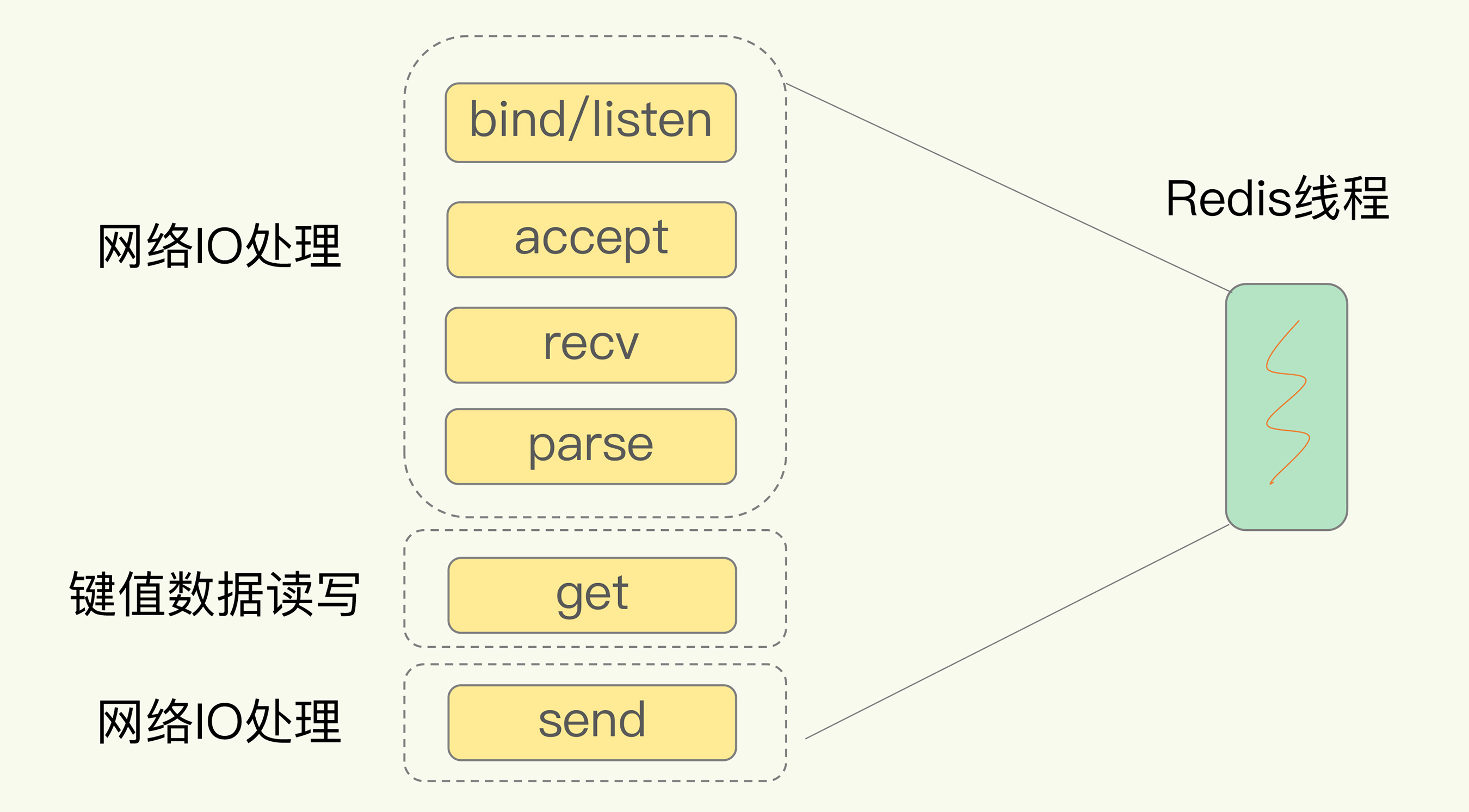
6.0以前单线程网络IO模型
- redis的单线程特指网络IO, 其他功能如持久化, 集群通信等还是依赖多子线程
- 假如socket队列与线程池一一对应, 则无法支撑大并发
- 而如果单线程处理多socket, 可能面临accept/recv/大键值对操作阻塞
![img]()
- 基于select/epoll/kqueue(具体视OS而定)的redis高性能IO, 这里的"事件处理队列", 即内核管理红黑树时, 同时维护的触发链表, 单线程只需要消费事件队列即可, 无需把时间浪费在轮询socket上
![img]()
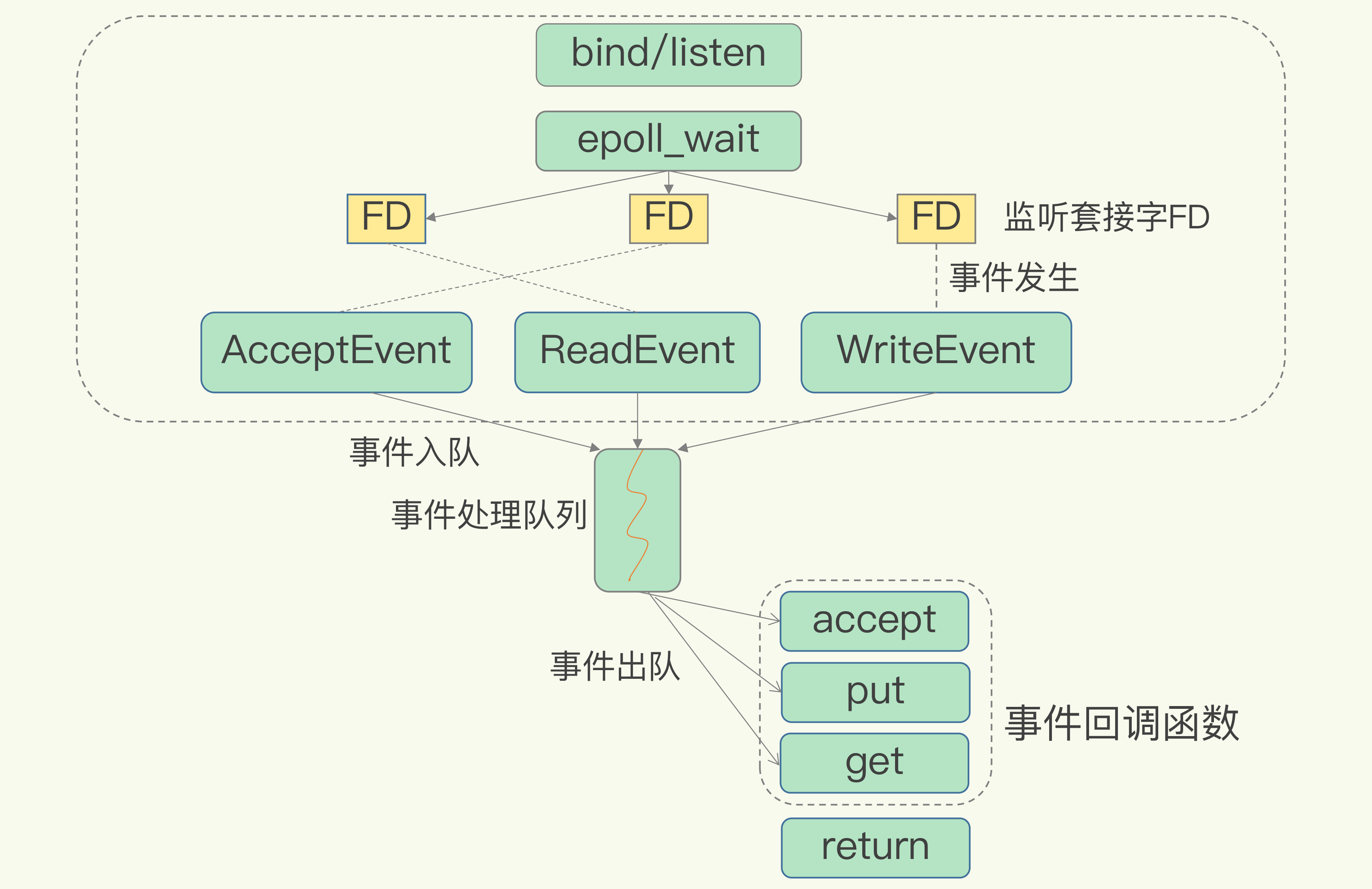
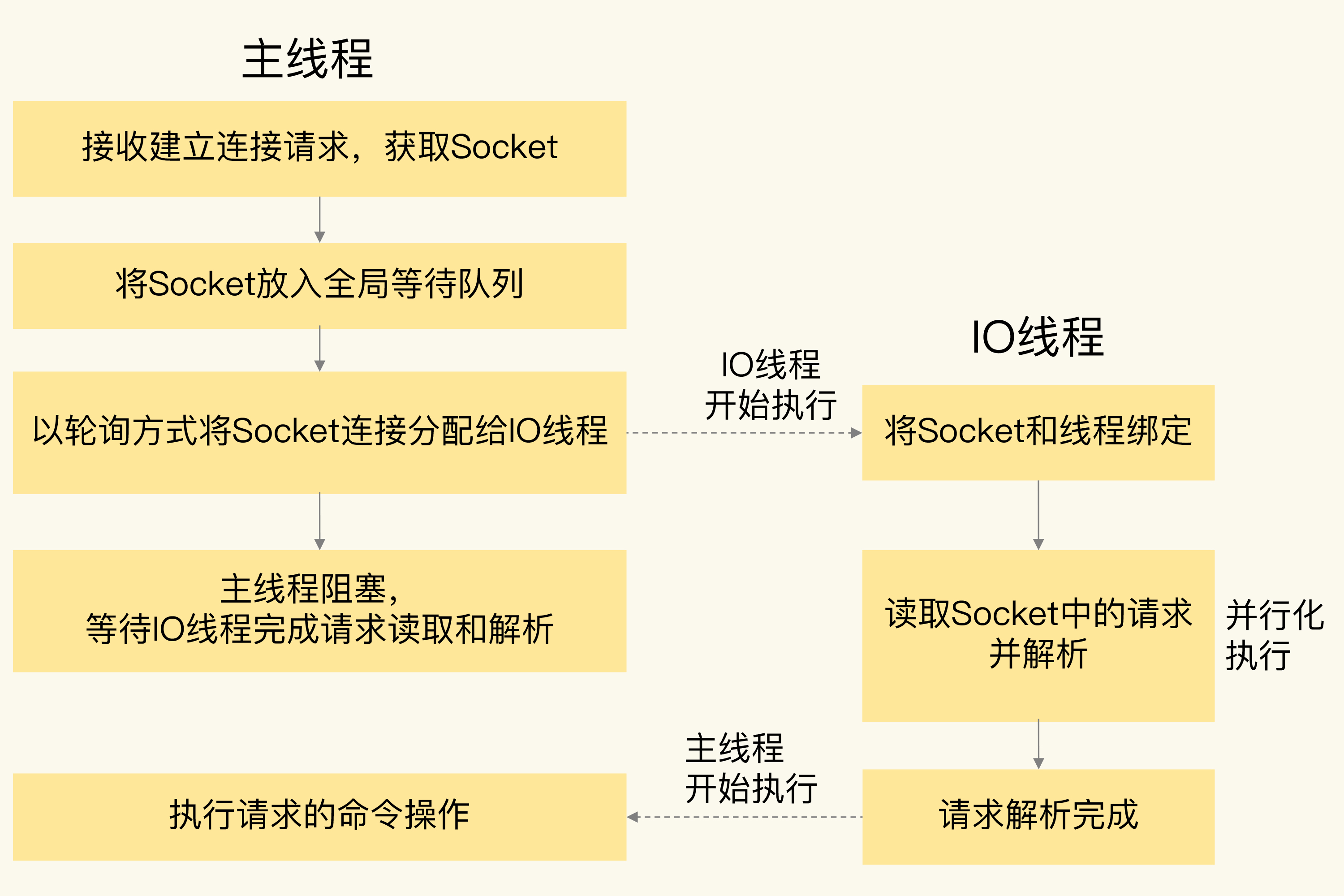
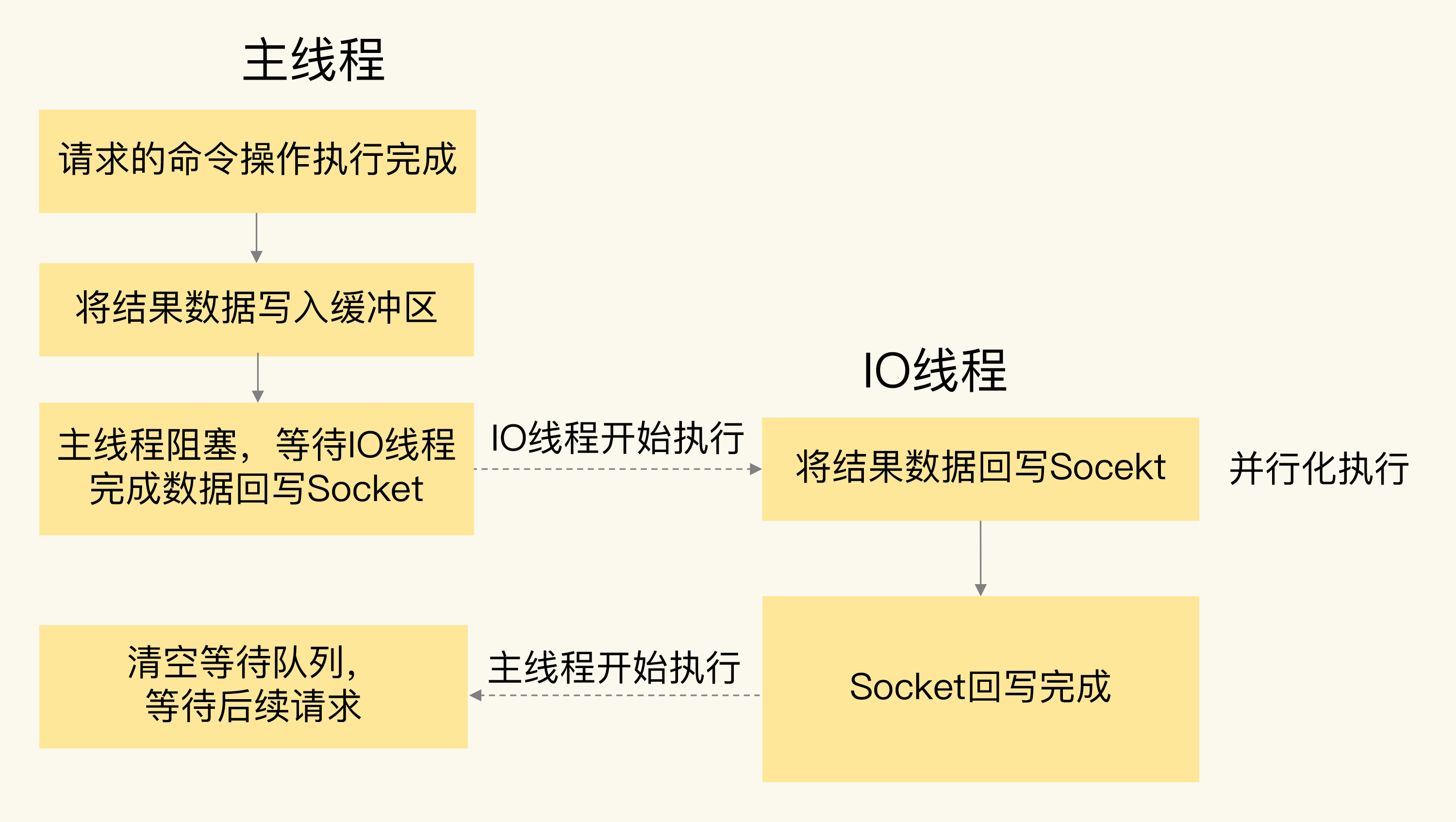
6.0以后多线程网络IO模型
- 多线程只体现在请求解析阶段, 操作模块仍然是主线程单独执行 -> 无需引入互斥同步机制
![img]()
![img]()
日志 & 持久化
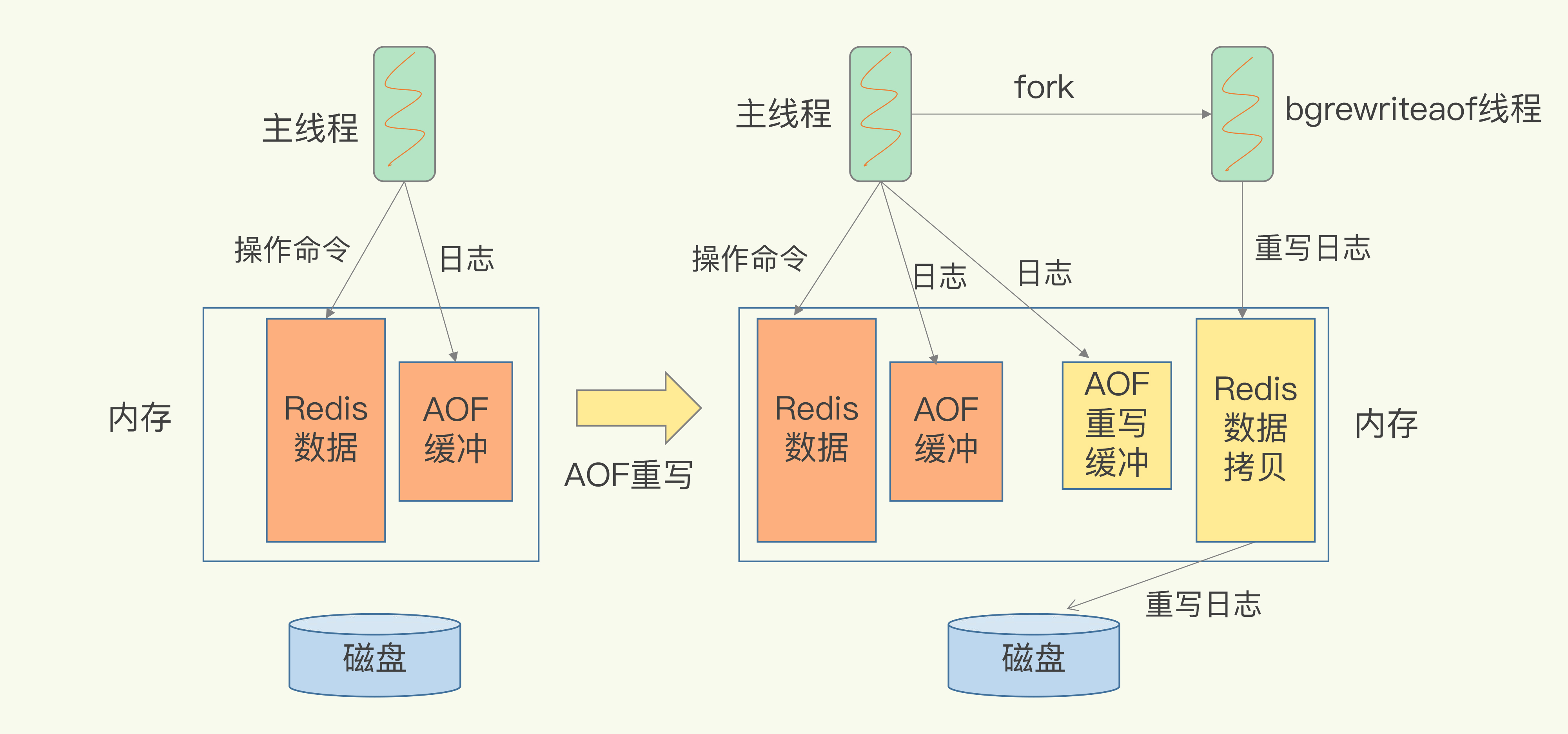
AppendOnlyFile
类似binlog:
- 记录的是全量写逻辑, 方式是追加写, 恢复的时候重放日志里的命令
- 先执行命令(事务)后写日志, 最后刷盘, 刷盘时机影响性能和一致性
不同于binlog:
- 由于多条操作可能最终结果等价于单条操作, 因此引入aof重写机制, 开启新线程压缩日志大小
![img]()
RDB
类似redolog:
- 记录的是内存二进制快照, 恢复时无需重放
不同于redolog:
- 没有ringbuffer的概念, 记录全量内存快照
- 快照时机不由ringbuffer的指针决定, 而是固定周期
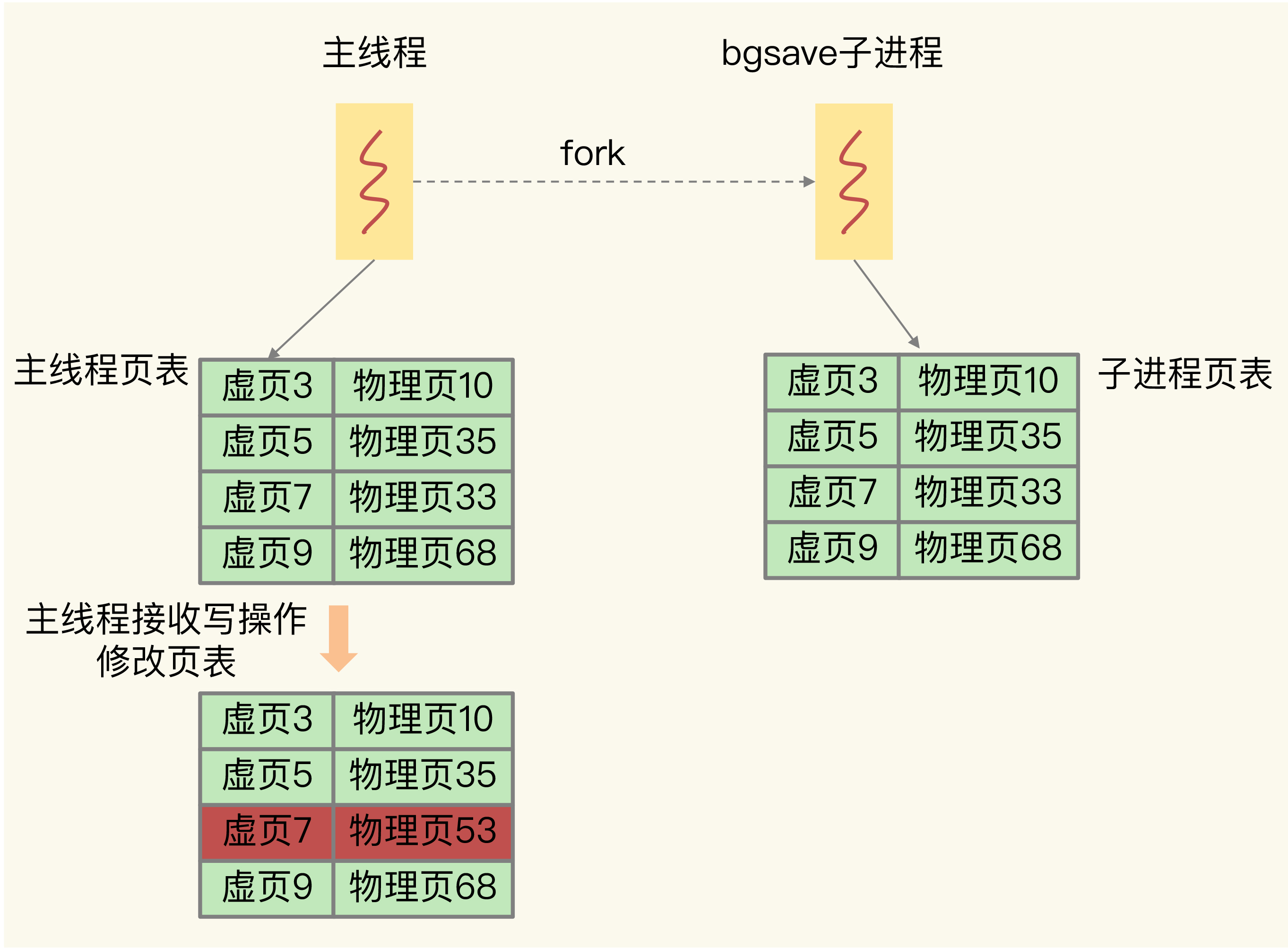
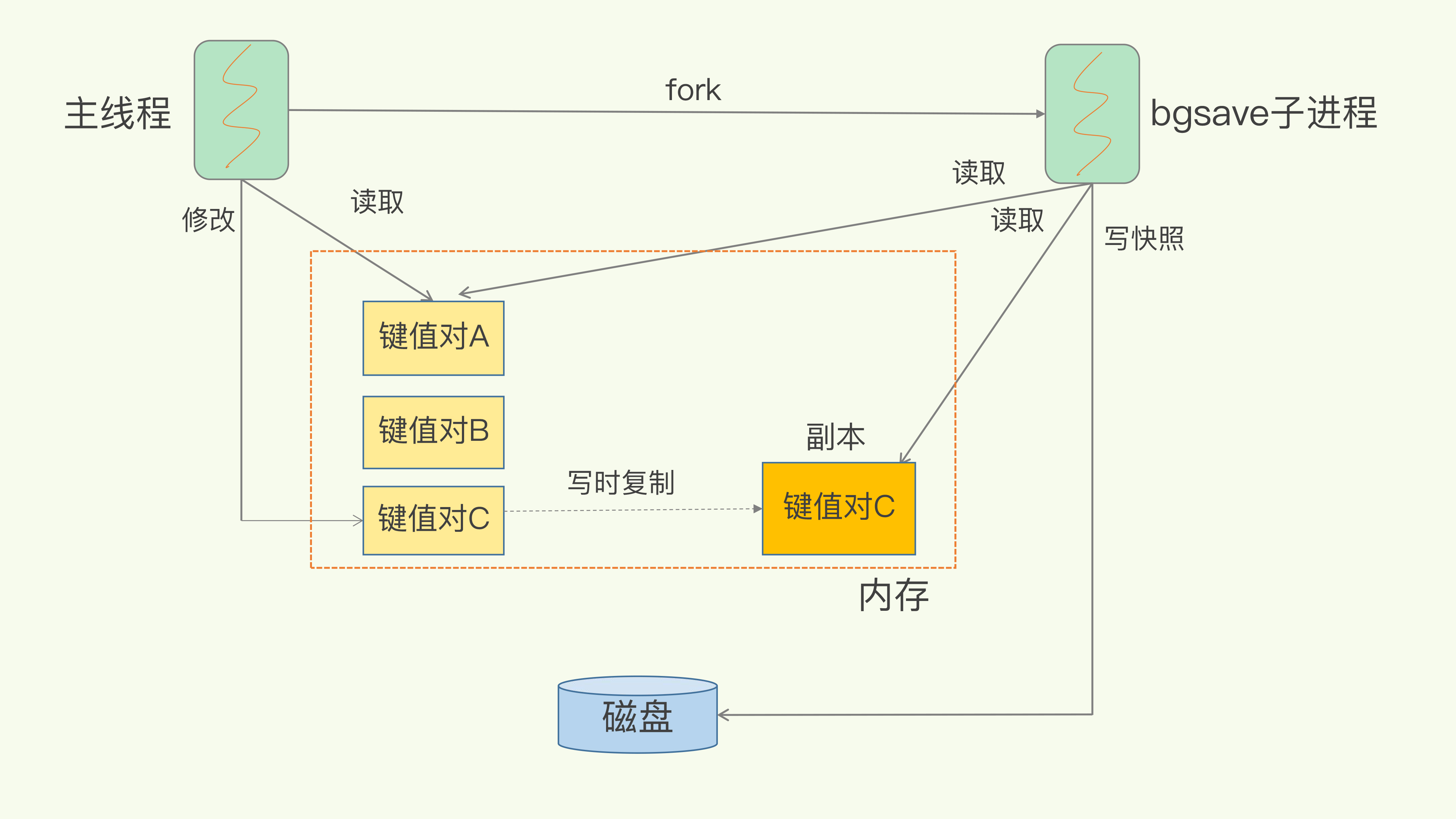
- 采用写时复制避免写操作造成的数据不一致
- 写时复制技术复制的是页表而不是真正的内存, 所以很快
![img]()
- 写时复制技术复制的是页表而不是真正的内存, 所以很快
MIXED
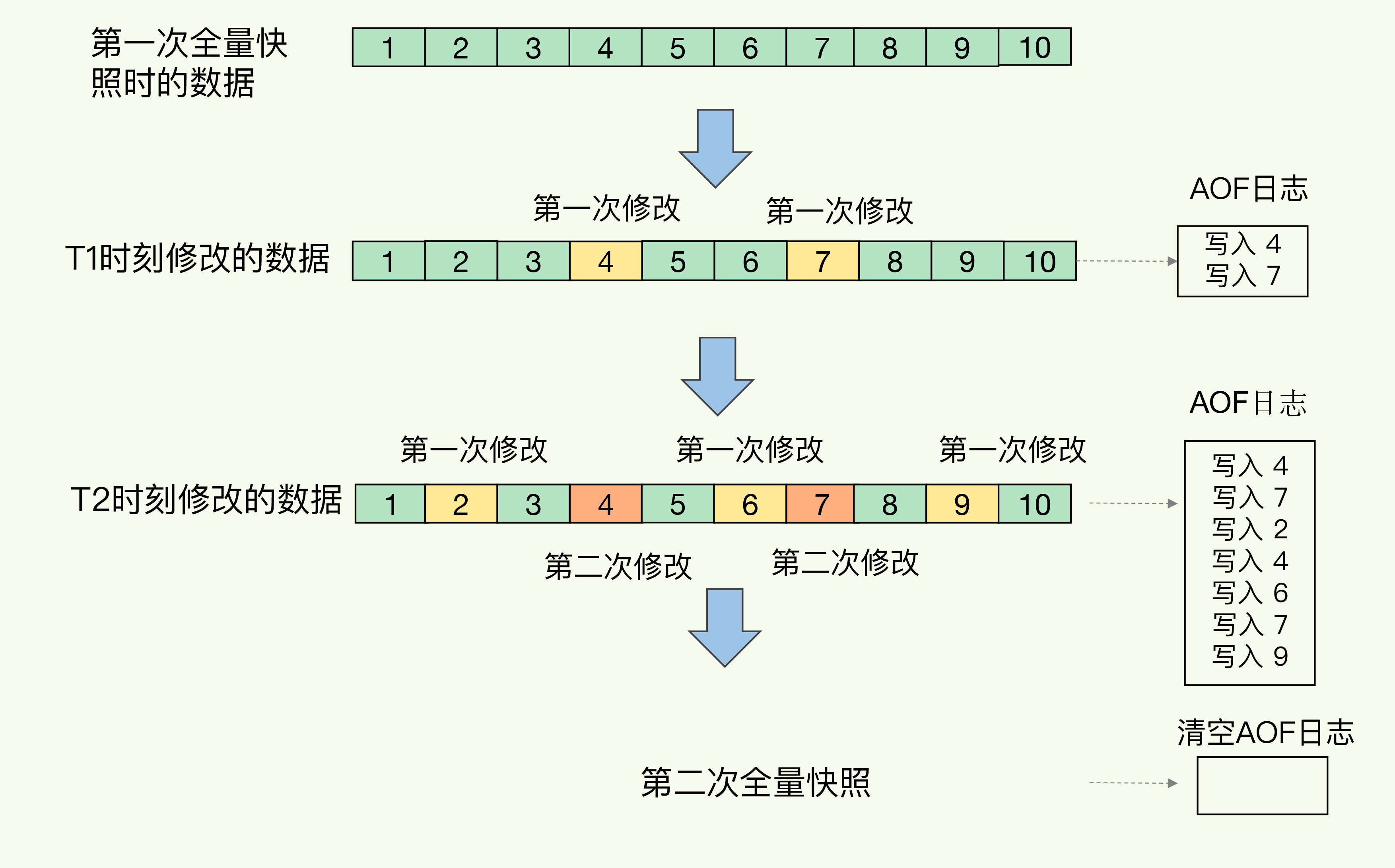
- RDB大周期全量 + 周期内增量, 增量用AOF记录
![img]()
主从架构
-
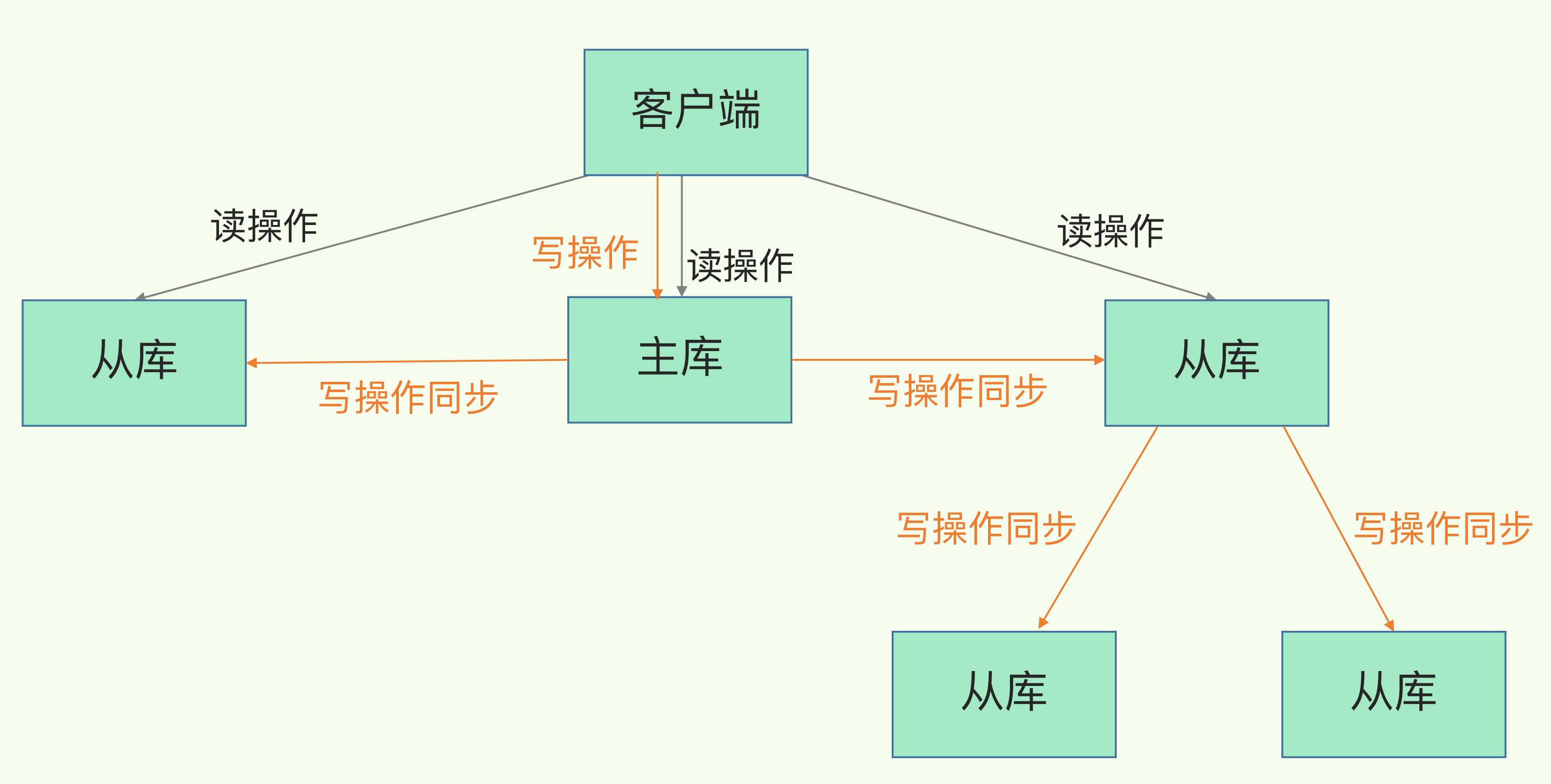
使用RDB快照文件保证主从一致性
-
从库太多会导致fork RDB快照线程次数变多, 而主线程fork时是不能提供服务的, 影响主库吞吐量, 因此可以让一部分从库承担同步操作
![img]()
-
主从连接中断时产生的脏数据, 通过ringbuffer同步到从库
- 主从指针的距离表示主从延迟
哨兵模式
-
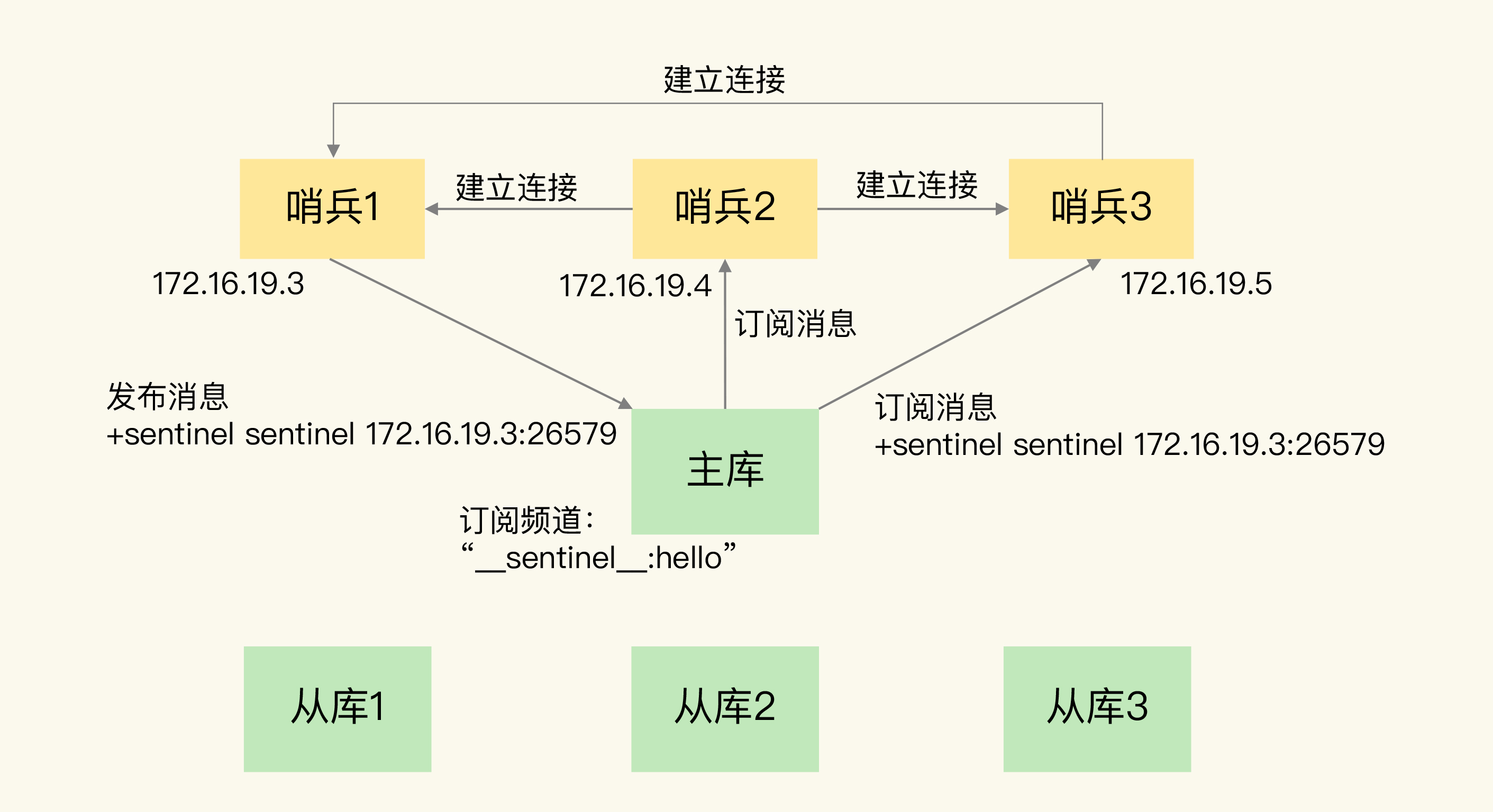
哨兵本质上是特殊的redis实例, 不对外提供读写能力, 只对集群内部开放通信和中转(MQ)的能力
-
哨兵集群通过发布/订阅主库的sentinel主题(本质是list)互相发现
![img]()
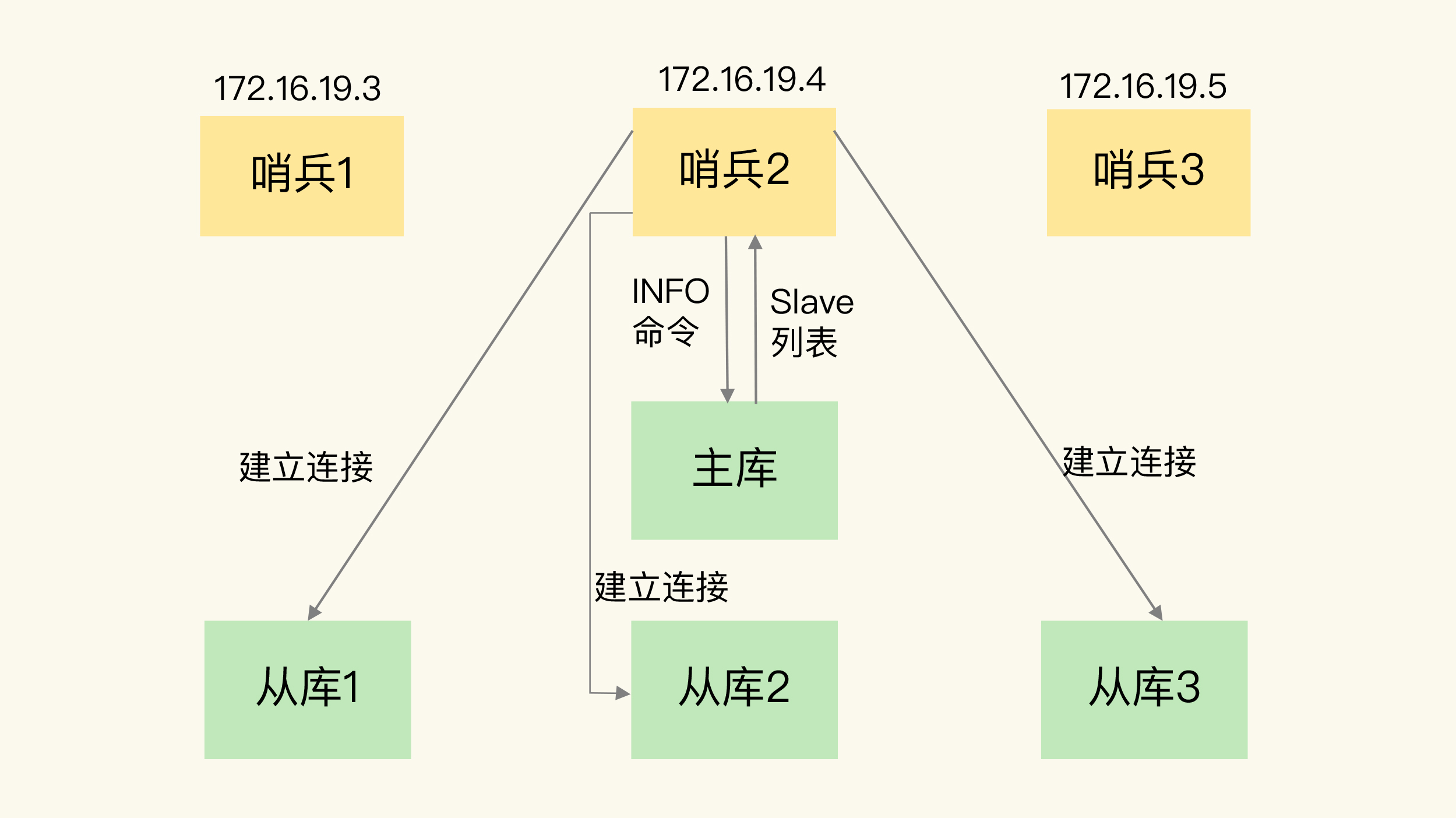
-
通过info命令向主库拉取从库列表
![img]()
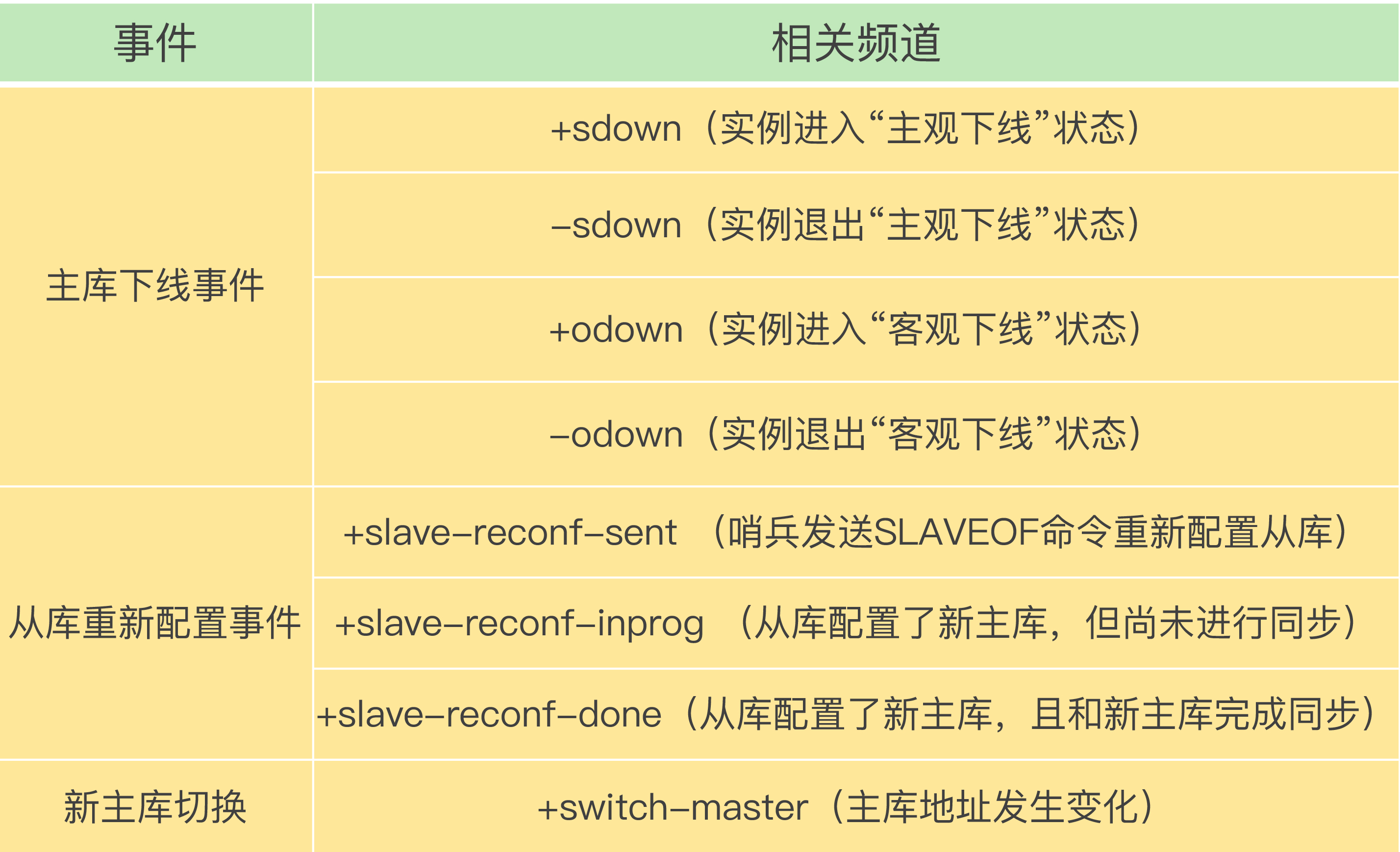
-
哨兵提供如下主题, 用于集群治理
![img]()
RAFT选举机制
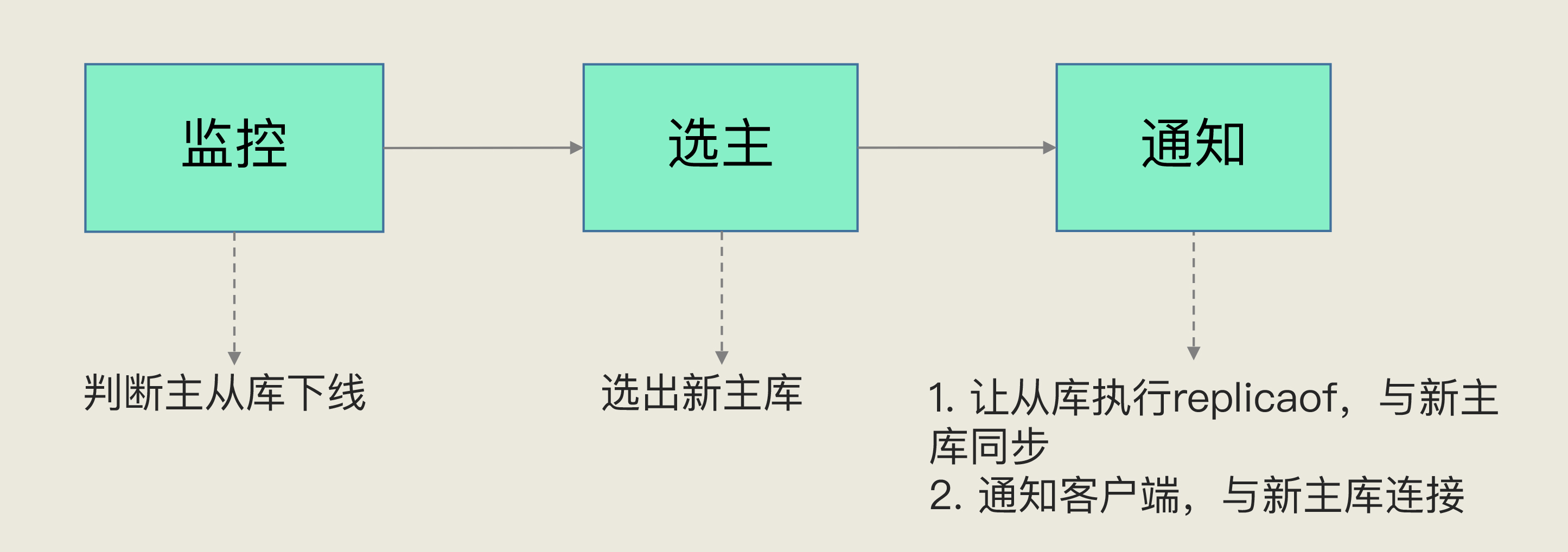
- 通过哨兵集群定期向所有库发心跳, 确认实例是否主观下线
- 第一个发现主观下线的哨兵, 会请求其他哨兵确认主库状态, 当超过一半哨兵认为主观下线, 则认定客观下线
- 接着哨兵内部竞选leader, 一般由发现者发起竞选(并给自己投票, 除非发现后哨兵立马挂了), 得票超过半数者主持主从切换
- 因此哨兵数量不能是偶数, 防止平局
- 如果由于拥塞导致没有超过半数的, 则等待后重试
- 如果哨兵故障, 且活跃哨兵数量少于一半, 则无法选出leader, 主从切换失败
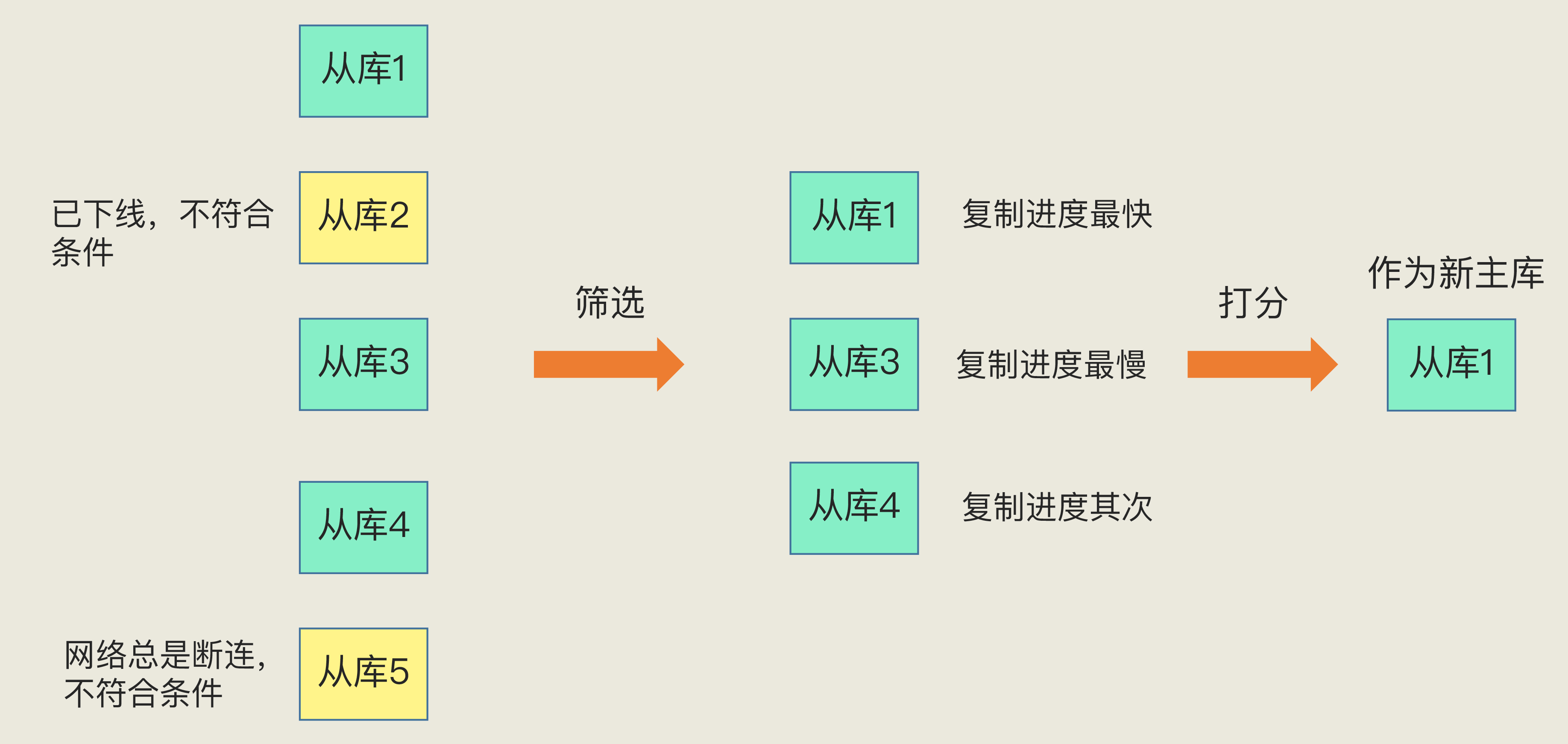
- 然后筛选从库(从库也可能客观下线), 并打分推举新主库
![img]()
- 打分规则经过3轮:
- 预设优先级
- 主从延迟低优先
- 小id优先
- 打分规则经过3轮:
分片集群(横向分表)
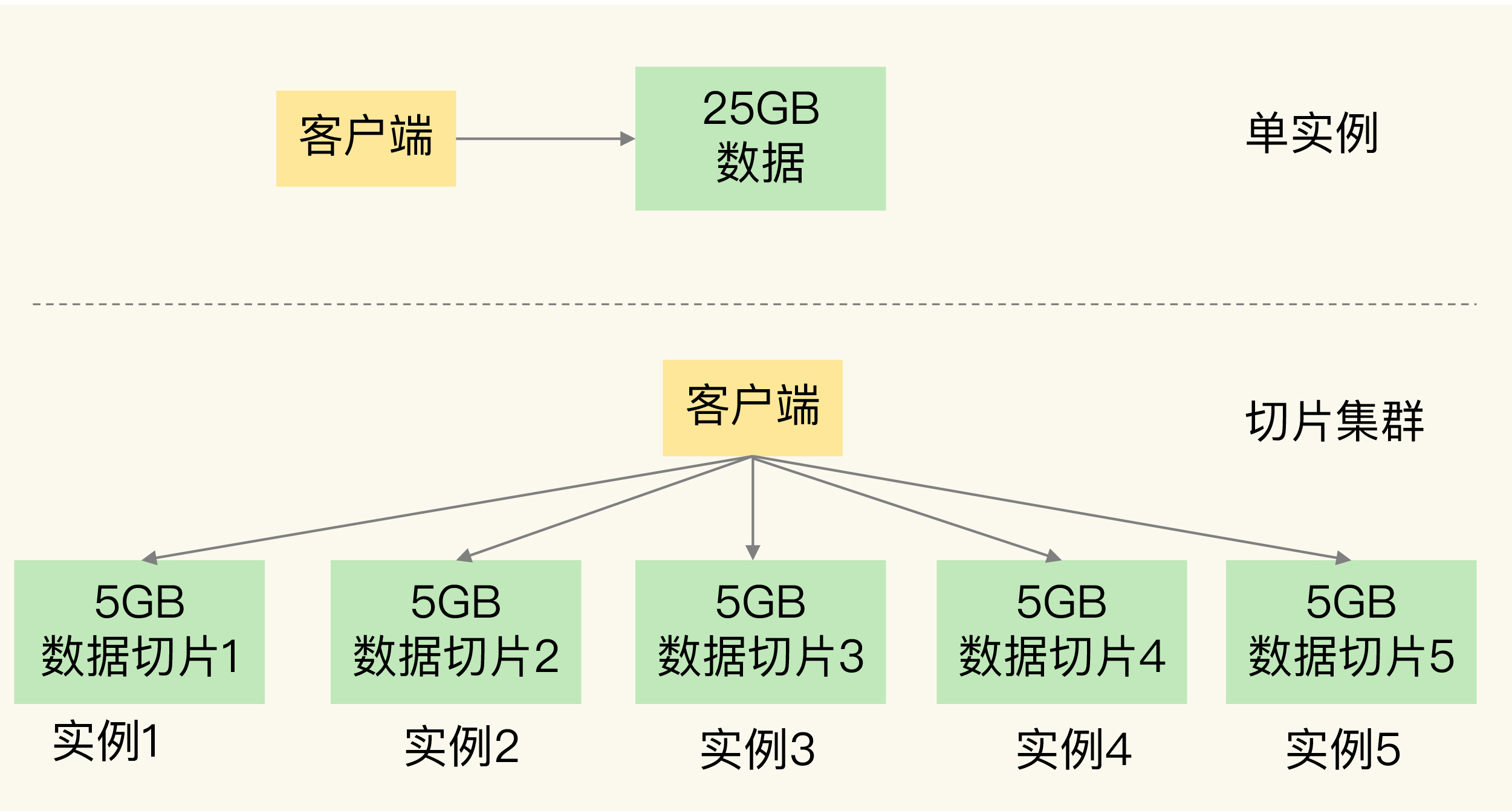
-
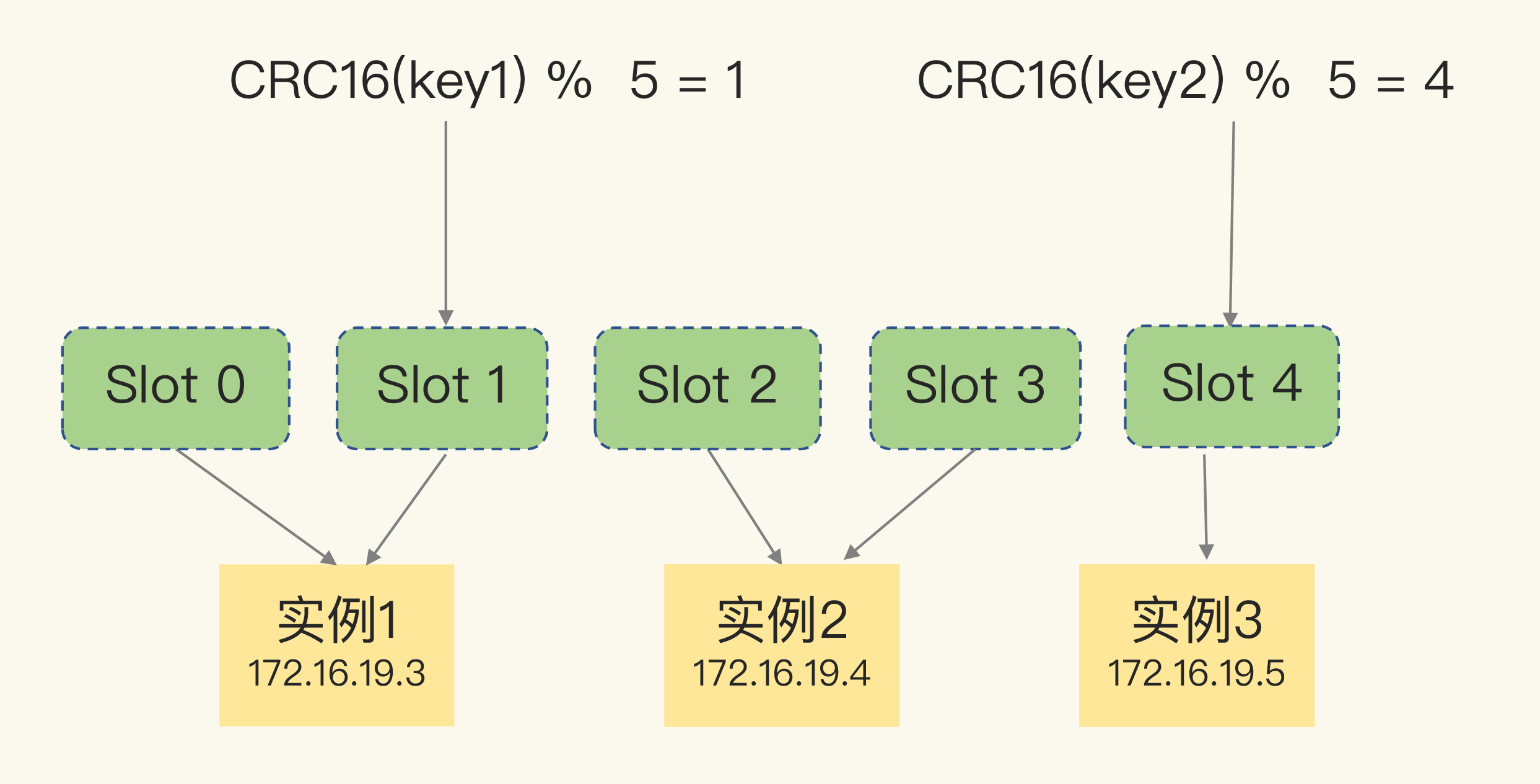
每个键值对到分片节点的映射使用哈希槽, 所有节点共16384个槽位
![img]()
-
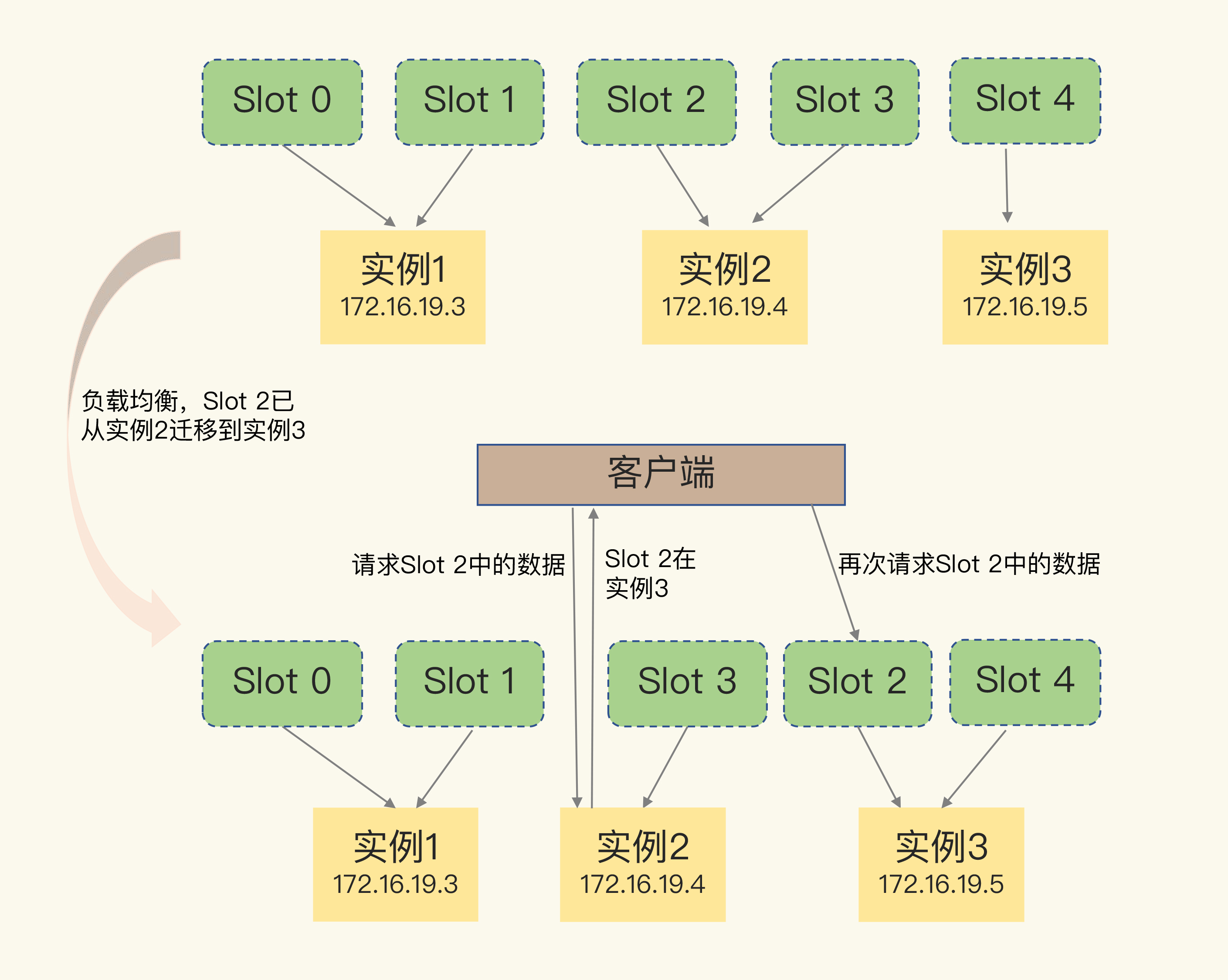
假如分片集群发生动态扩缩容, 槽位需要重新计算并消息广播
- 客户端对rehash不知情, 读写操作可能映射到错误的节点(节点上没有哈希槽), 需要错误节点返回重定向, 映射到正确节点(包含哈希槽)
![img]()
- 客户端对rehash不知情, 读写操作可能映射到错误的节点(节点上没有哈希槽), 需要错误节点返回重定向, 映射到正确节点(包含哈希槽)
消息队列
- 避免单点故障, 功能解耦
- 异步化处理, 消息队列可以充当缓存, 削峰填谷
- 类似DB的日志, 消息可以是全量结果, 也可以是操作快照
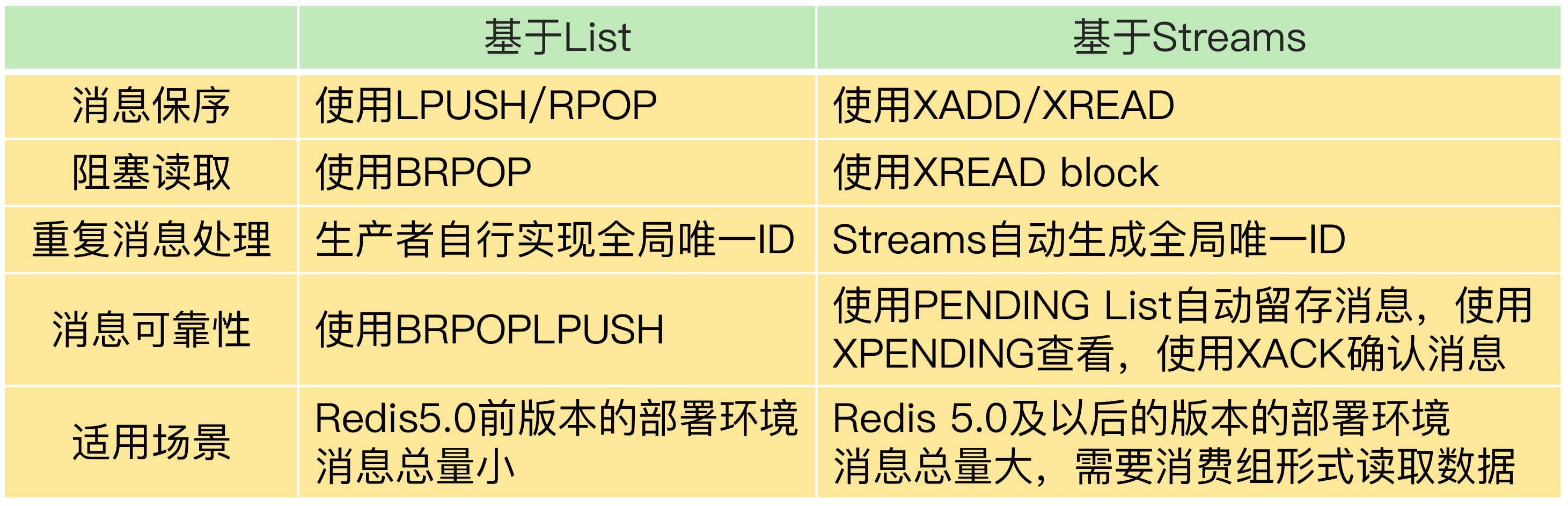
保序
- 如果消息存在逻辑关系, 那么消费者必须按生产者发送的顺序进行消费 -> fifo队列 -> list(lpush/rpop)
- 消费者要么自旋式rpop, 要么阻塞式brpop
去重
- 由于重试机制, 生产者可能生产多份消息, 消费者应具有幂等性 -> lpush前生成全局id
备份
- 消费者获取消息后, 如果挂了, 那么此消息就丢失了 -> brpoplpush原子操作, 消费者获取消息的同时将消息插入备份list, 直到消息被成功消费
堆积
- 生产者快, 消费者慢 -> 多消费者(消费者组) -> stream
![img]()
redis阻塞场景 & 异步化
redis是单线程的, 凡是大操作, 都有可能阻塞主线程
| 阻塞操作 | 异步化 |
|---|---|
| 解析命令 | Y(针对6.0以后版本) |
| rehash扩缩容 | N, 渐进式rehash |
| 过期key清理 | N, 采样删除 + 惰性删除 |
| 复合数据结构值的全量查询和聚合操作 | N |
| bigkey删除/主动清空数据库 | Y, 无需返回值 |
| AOF日志刷盘 | Y, 无需返回值 |
| 从数据库接收到RDB后被动清空数据库 | Y, 无需返回值 |
| 从库加载RDB | N |
-
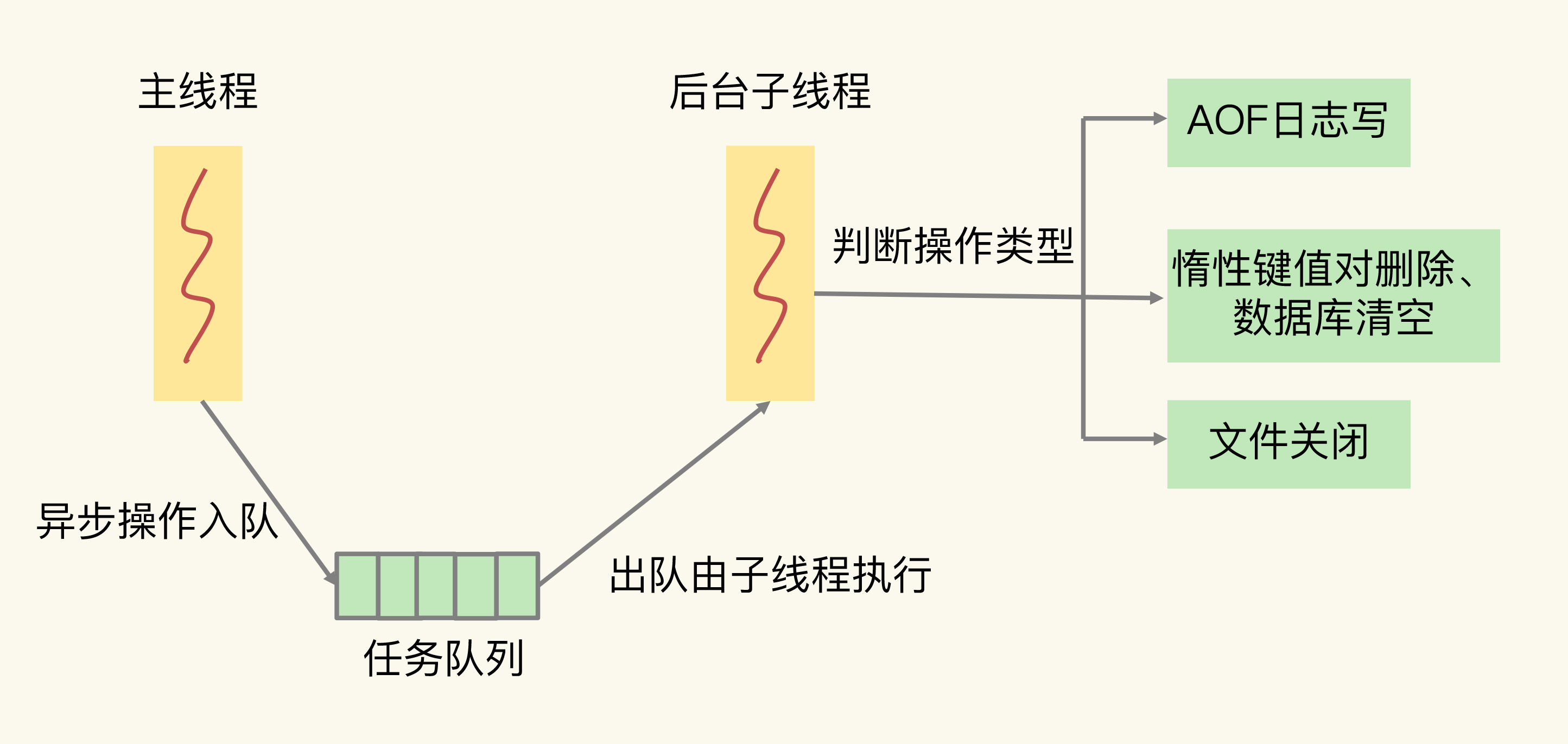
类似线程池, 使用任务队列组织可异步化任务的子线程
![img]()
-
UNLINK <key>命令开启子线程, 异步化后台删除大key, 主线程立即返回删除成功, 不会阻塞 -
对于定时删除, 使用懒删除策略
-
FLUSHXX ASYNC清库
绑核
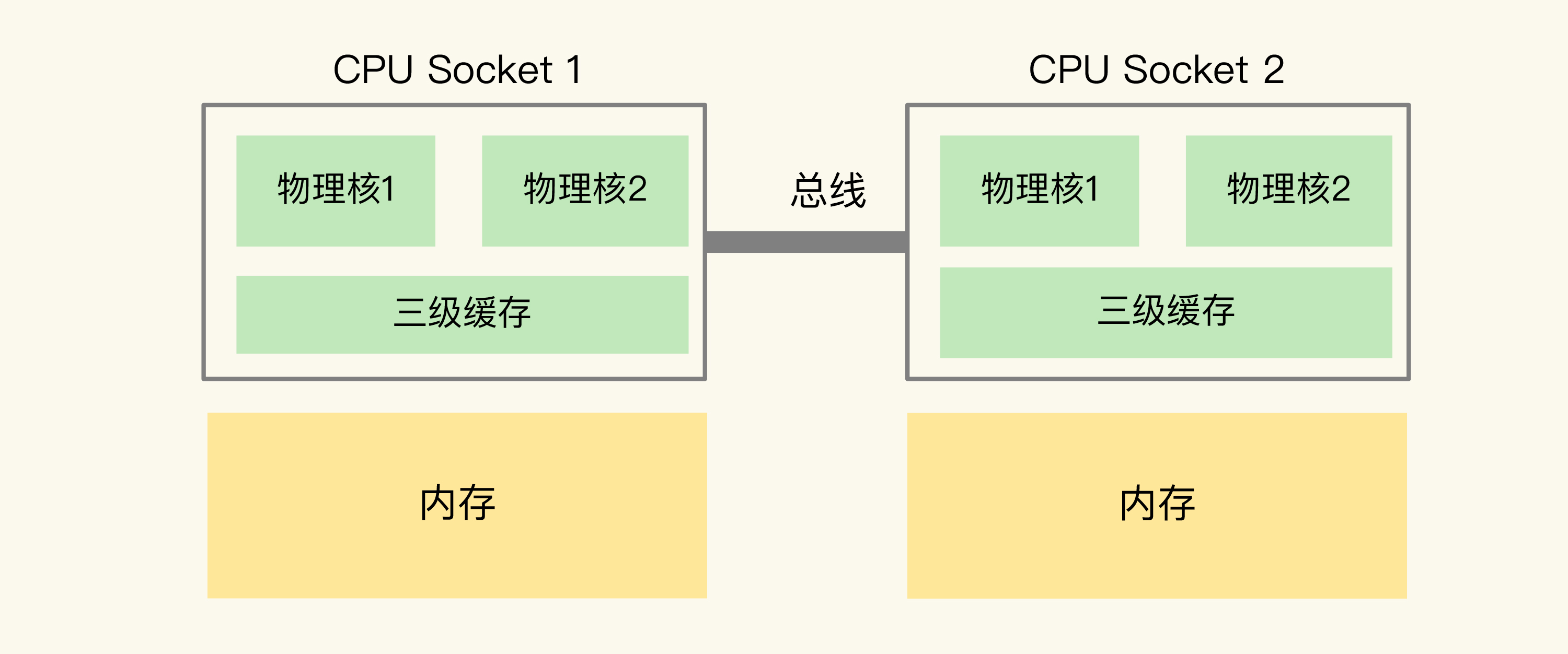
-
由于CPU的三级缓存结构, 如果redis主线程被调度到不同核上, 缓存和内存会失效, 需要花时间阻塞切换上下文
- 这会导致较高的尾延迟, 以及监控到CPU-context-switch频繁
![img]()
- 这会导致较高的尾延迟, 以及监控到CPU-context-switch频繁
-
使用命令或修改redis源码, 让一个实例始终绑定在一个物理核上, 让主子线程运行在逻辑核上
缓存
根据28原理, 缓存大小设置为内存的15%-30%, 即可满足80%的命中率
冷热方差越大, 缓存越小
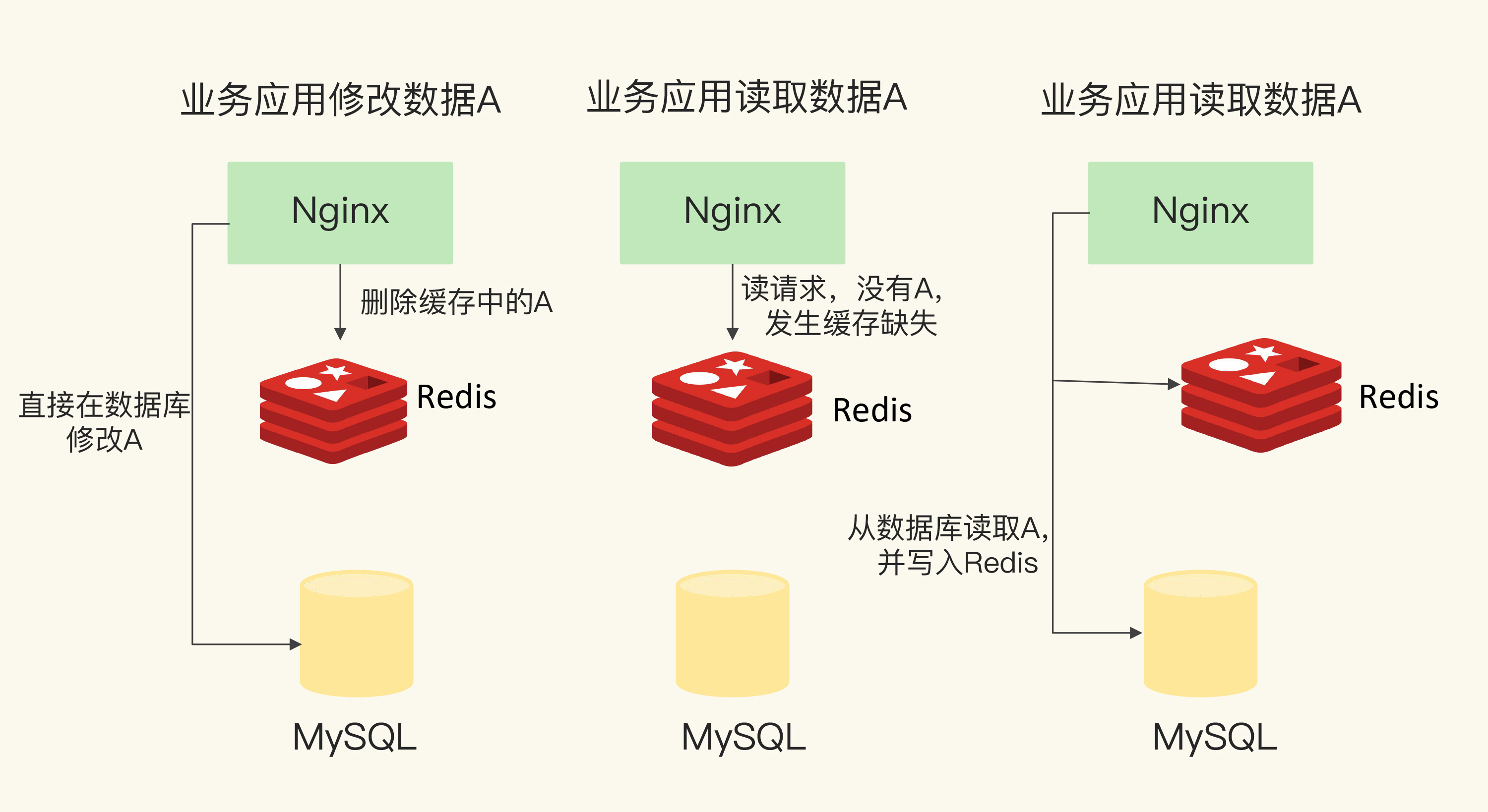
只读缓存
- redis只接受读请求, 增删改仍然交由DB处理
- 为了保证一致性, 删改DB后, 需要将redis缓存也删除, 等待下一次不命中后重新加载
- ACID由DB保障, redis只作为旁路缓存
![img]()
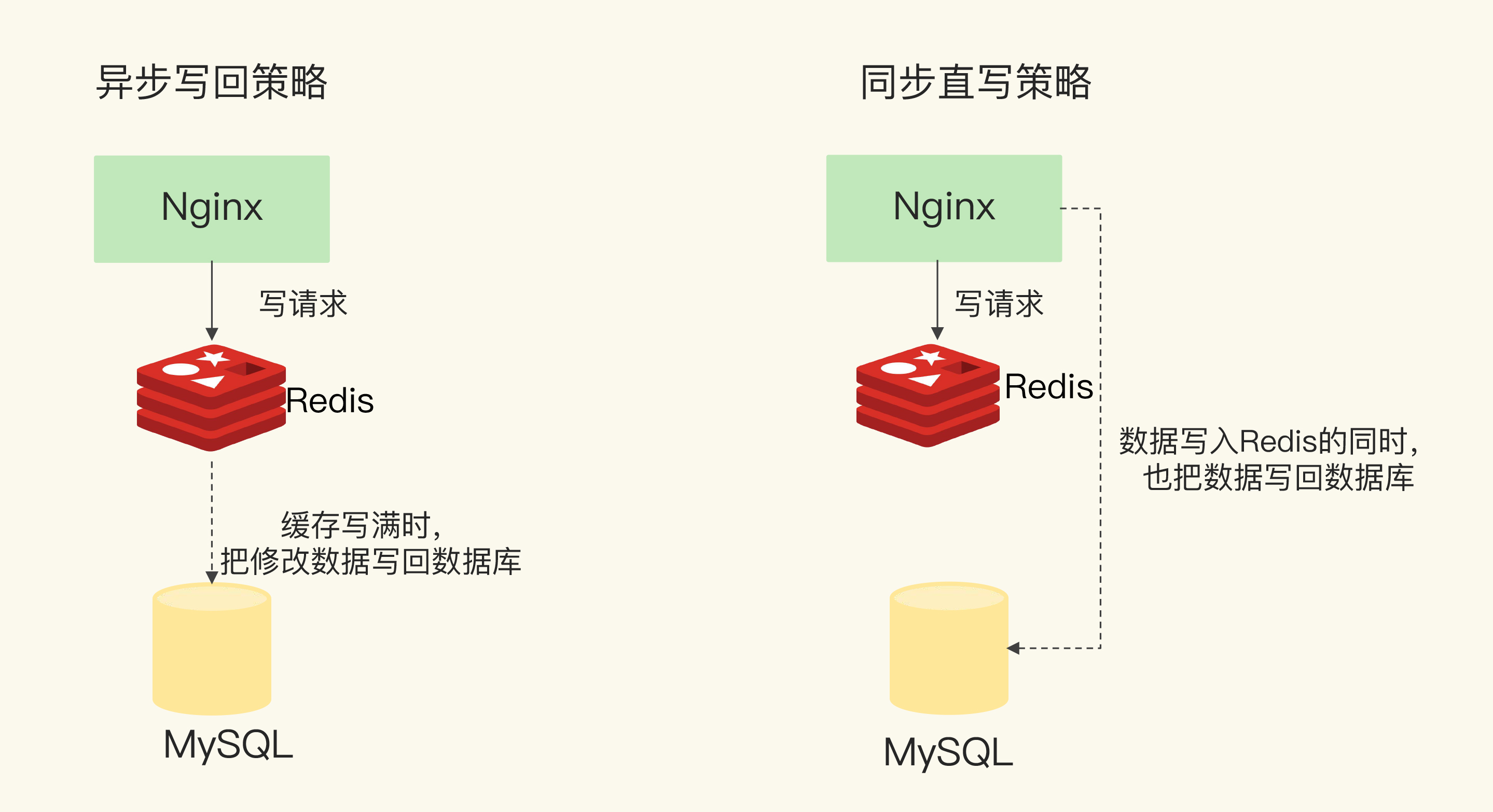
读写缓存
- redis接受CRUD
- ACID由redis缓存保障, 可能丢失
- 因此针对不同的业务场景, 提供:
![img]()
- 同步直写, 每一次写请求, 同步发送给redis缓存和DB, 两者都写入成功才ok, 否则回退
- 由DB保证一致性, 但性能差, 快缓存等慢DB
- 异步写回, 每当从缓存淘汰数据时, 才发送DB
- 联合保证一致性, 性能好, 但可能丢失
- 同步直写, 每一次写请求, 同步发送给redis缓存和DB, 两者都写入成功才ok, 否则回退
缓存淘汰
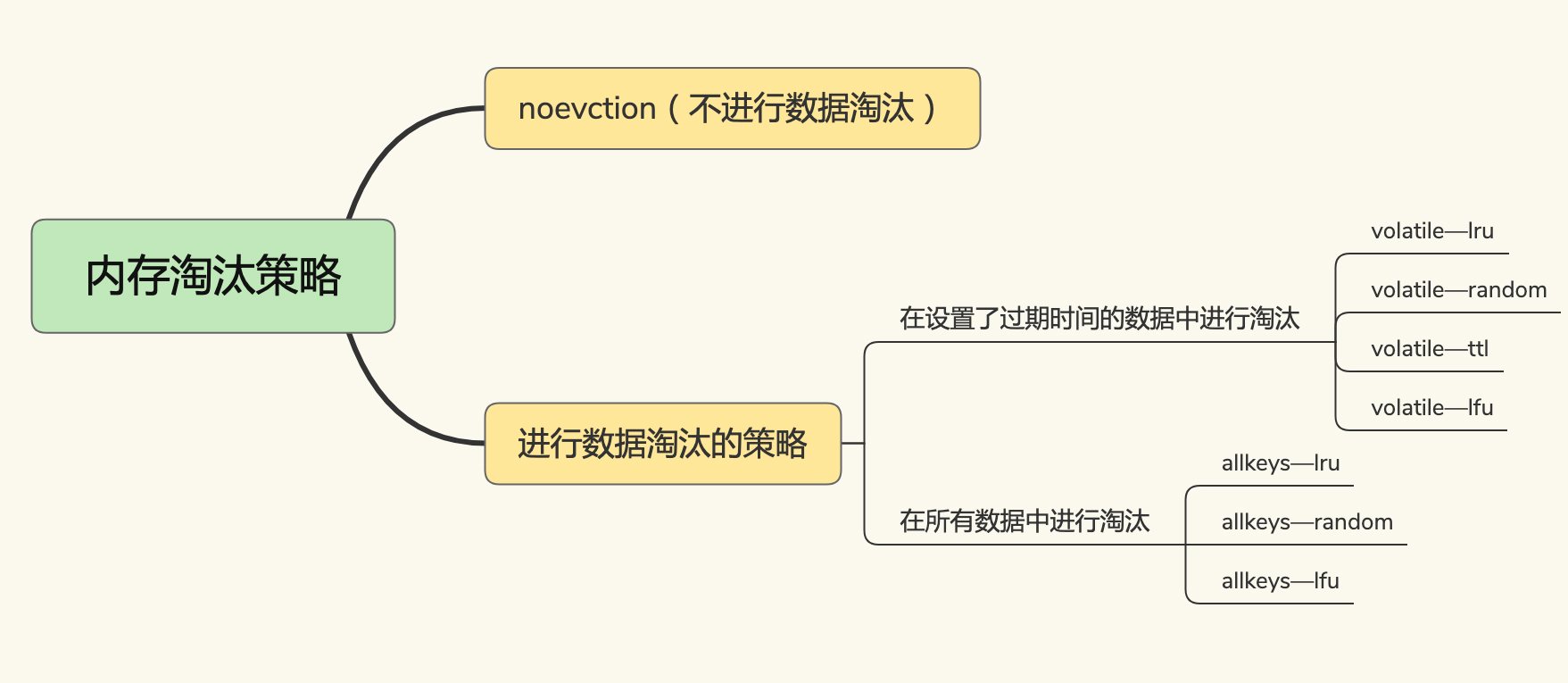
- no-evct, 写满就不再改变
- volatile, 缓存达到阈值, 或限时key即将过期
- ttl 越早过期越优先删除
- random 随机删除
- lru 最近最少访问删除, 递减采样版
- lfu
- allkeys, 缓存达到阈值
- random
- lru
- lfu
缓存一致性
以下针对对于只读缓存, 读写缓存, 一般用不到, 写操作走DB
-
读操作不会改变状态, insert只会让DB处于最新状态, 满足一致性
-
删改操作, 无论是先删缓存后刷DB, 还是先刷DB后删缓存, 如果无法保证两个操作的原子性, 就会造成不一致
-
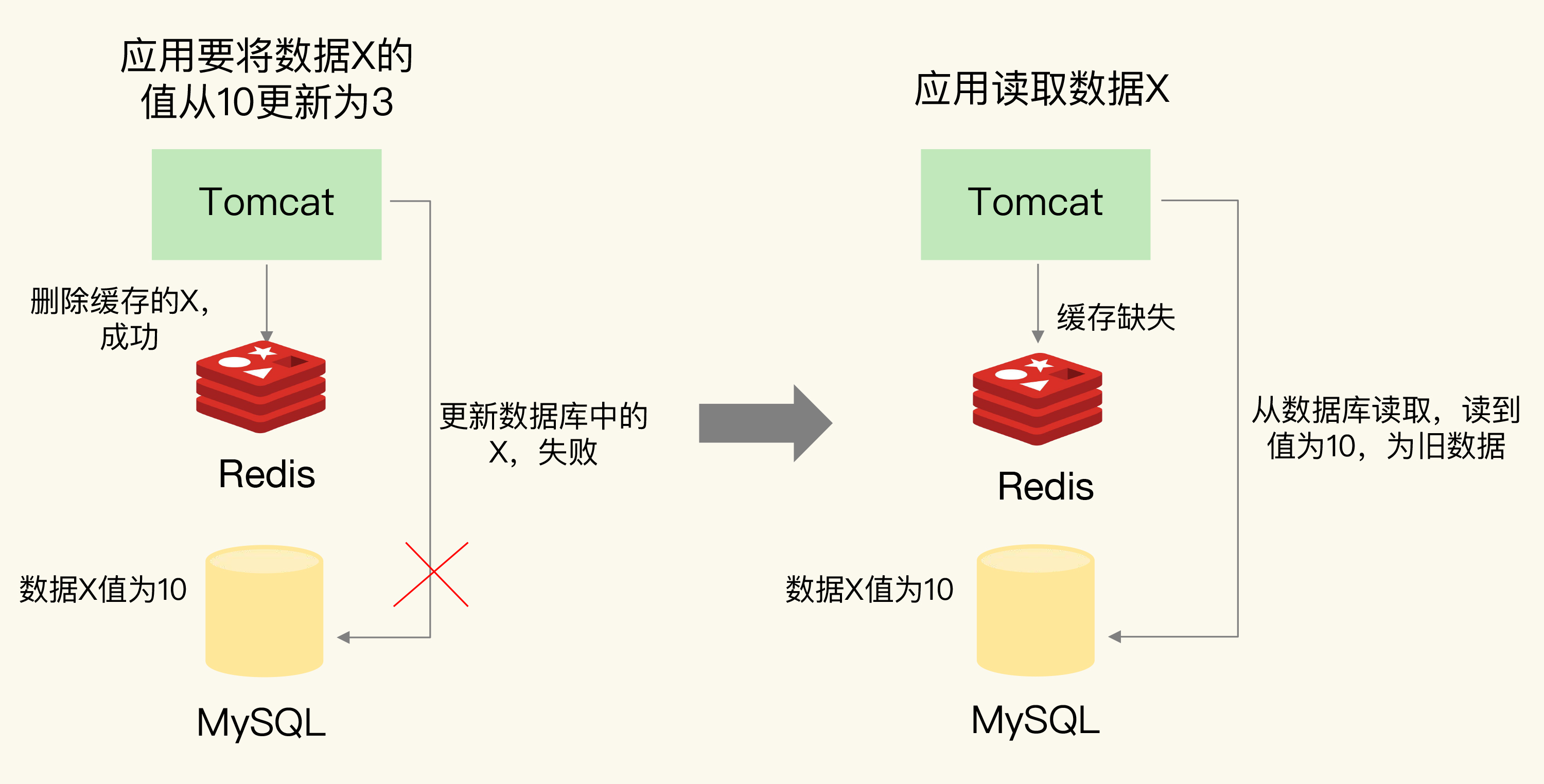
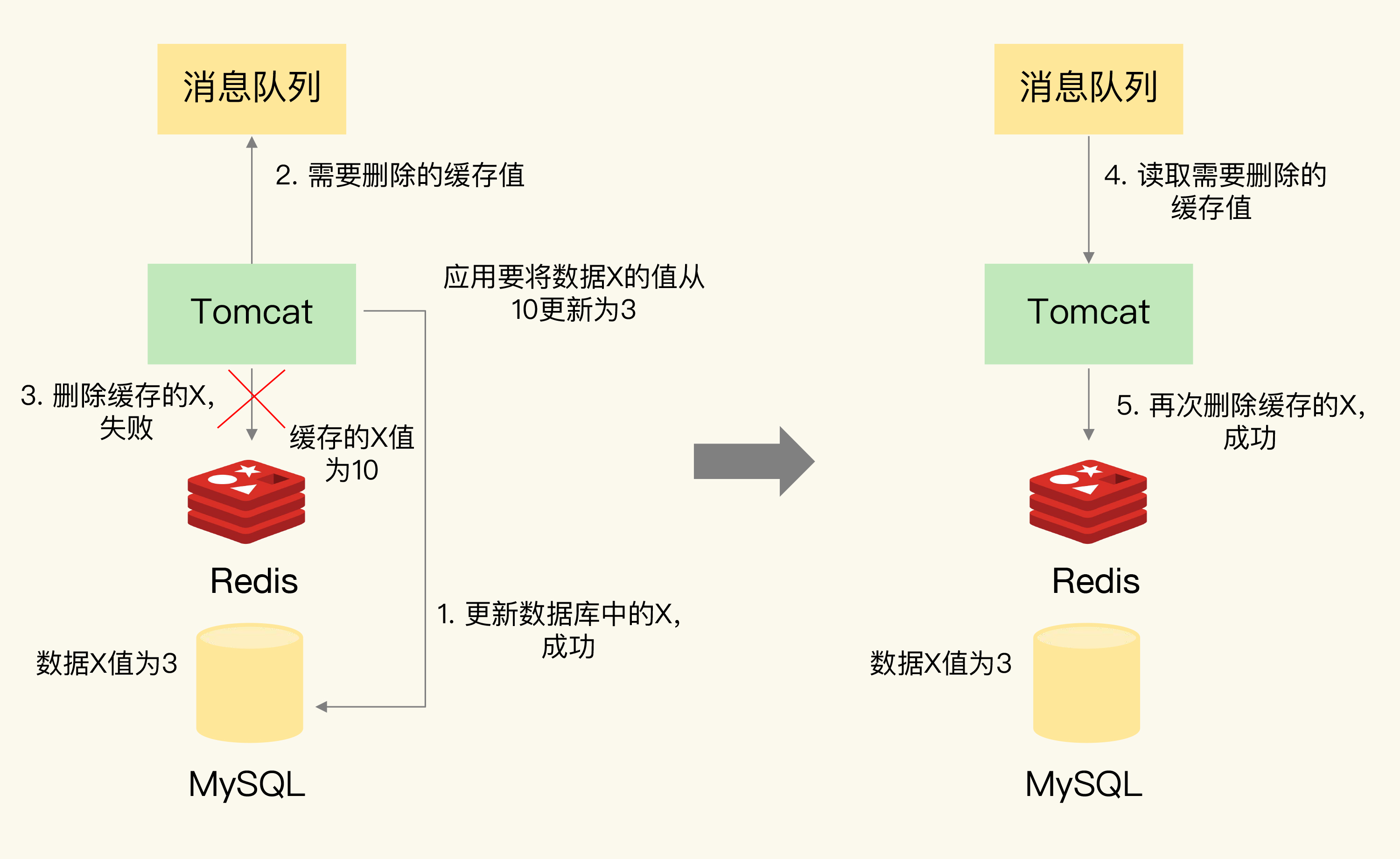
先删缓存, 后刷DB失败/延迟
- 会在DB读到旧值
- 读完旧值后还会覆盖缓存, 造成缓存污染(脏写)
![img]()
-
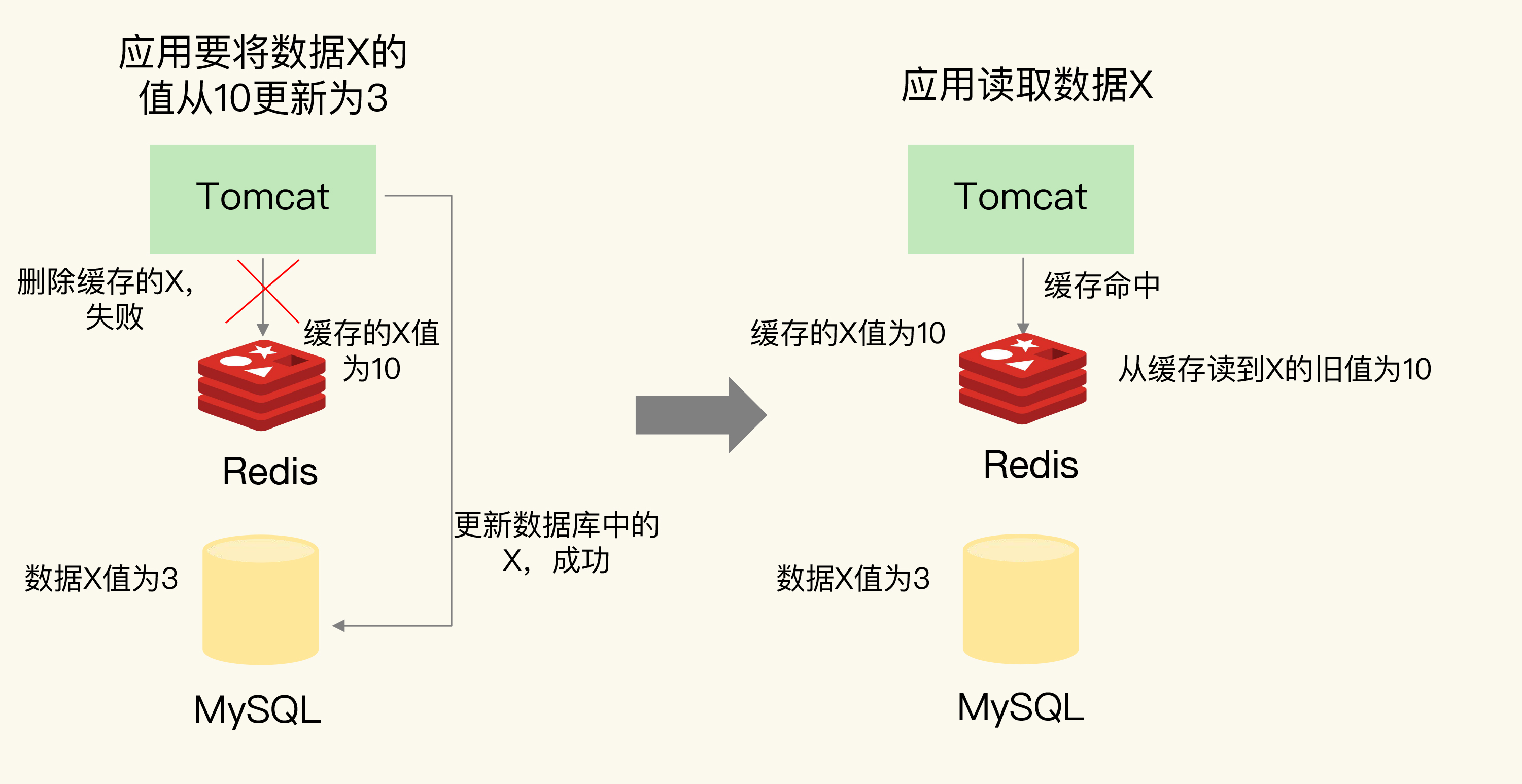
先刷DB, 后删缓存失败/延迟
- 缓存异常
![img]()
- 缓存异常
-
对策:
![img]()
-
针对先删缓存, 后刷DB失败 和 先刷DB, 后删缓存失败的情况, 使用消息队列重试 丢失的操作, 保证原子性
![img]()
-
针对先刷DB, 后删缓存延迟的情况, 只要删缓存延迟恢复, 缓存就会被更新为最新状态
- 因此可以先让请求走DB, 等待延迟恢复/DB净化缓存
-
针对先删缓存, 后刷DB延迟的情况, 即使刷DB延迟恢复, 将DB更新为最新值, 缓存也可能已经被污染(脏写)
- 延迟双删: 因此需要等DB污染缓存后(经验值), 再多删一次缓存, 去除脏数据, 主动让下次缓存不命中走DB来净化缓存
-
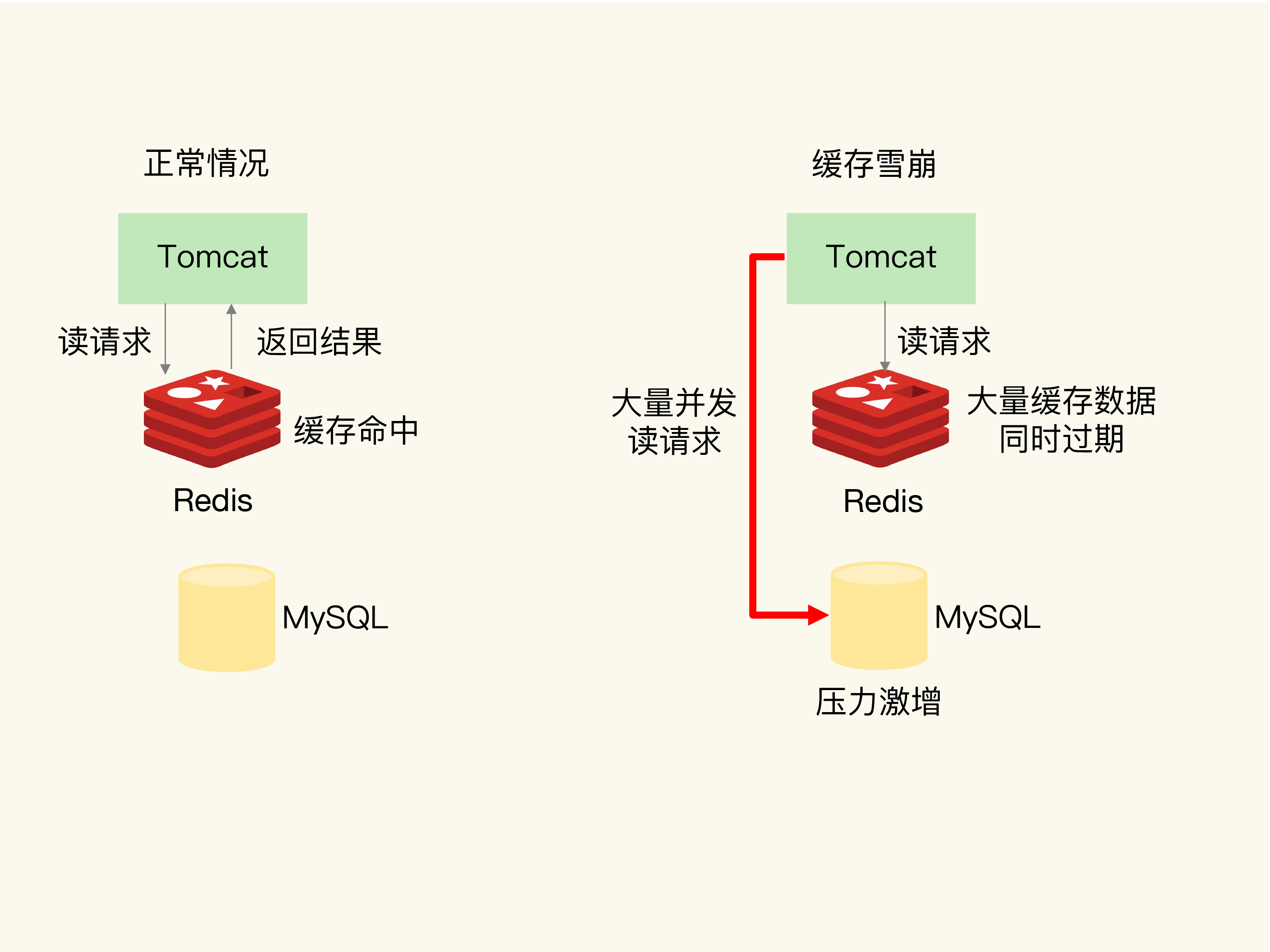
缓存雪崩
当监控系统发现redis参数异常, DB激增, 意味着发生了雪崩, 可能是大量限时key同时失效或redis实例宕机
- 搭冗余集群, 防止单点故障(无损)
- 限时key + 随机值
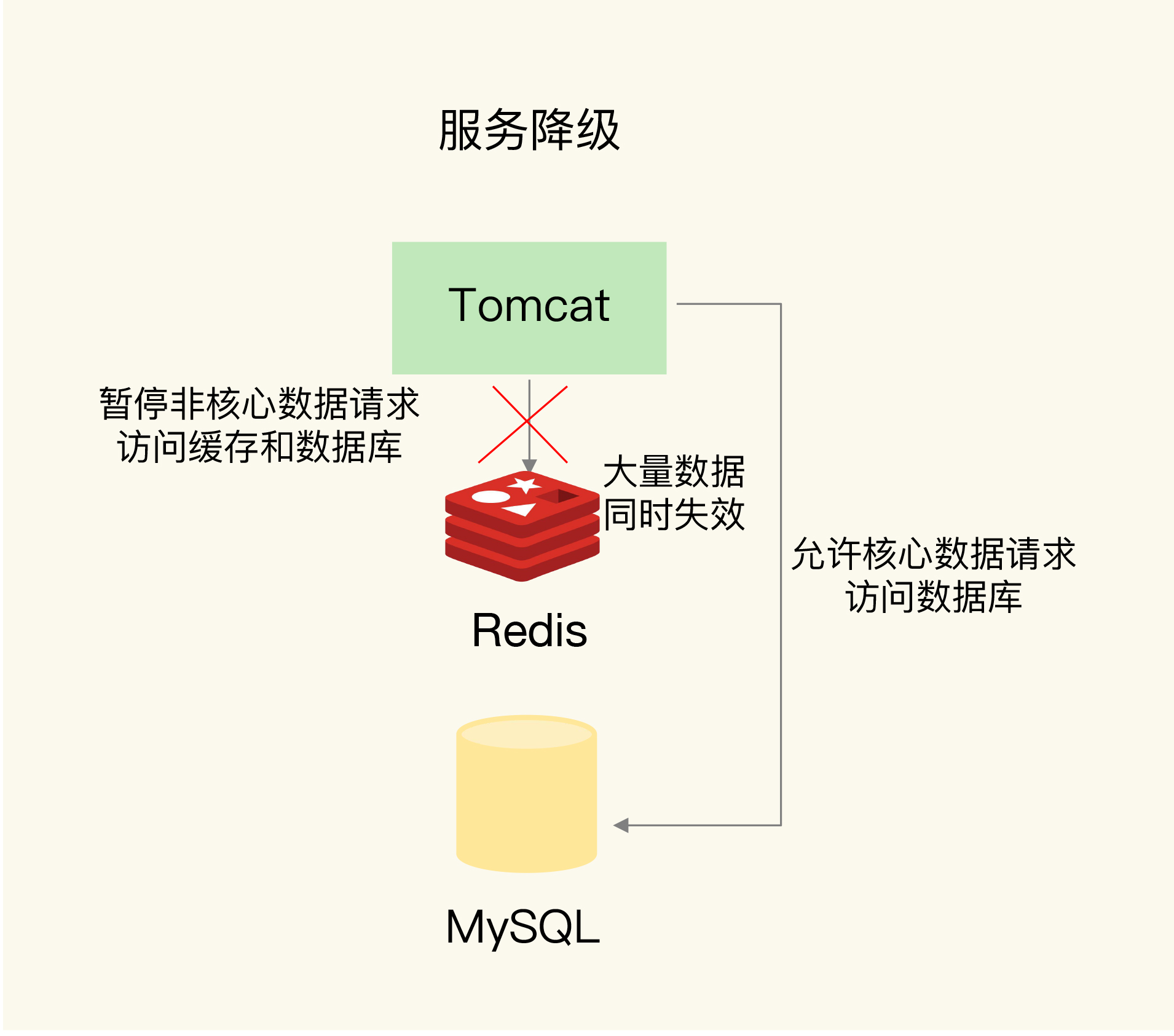
- 降级: 非核心数据返回预定信息/空值/错值, 核心数据走缓存和DB
![img]()
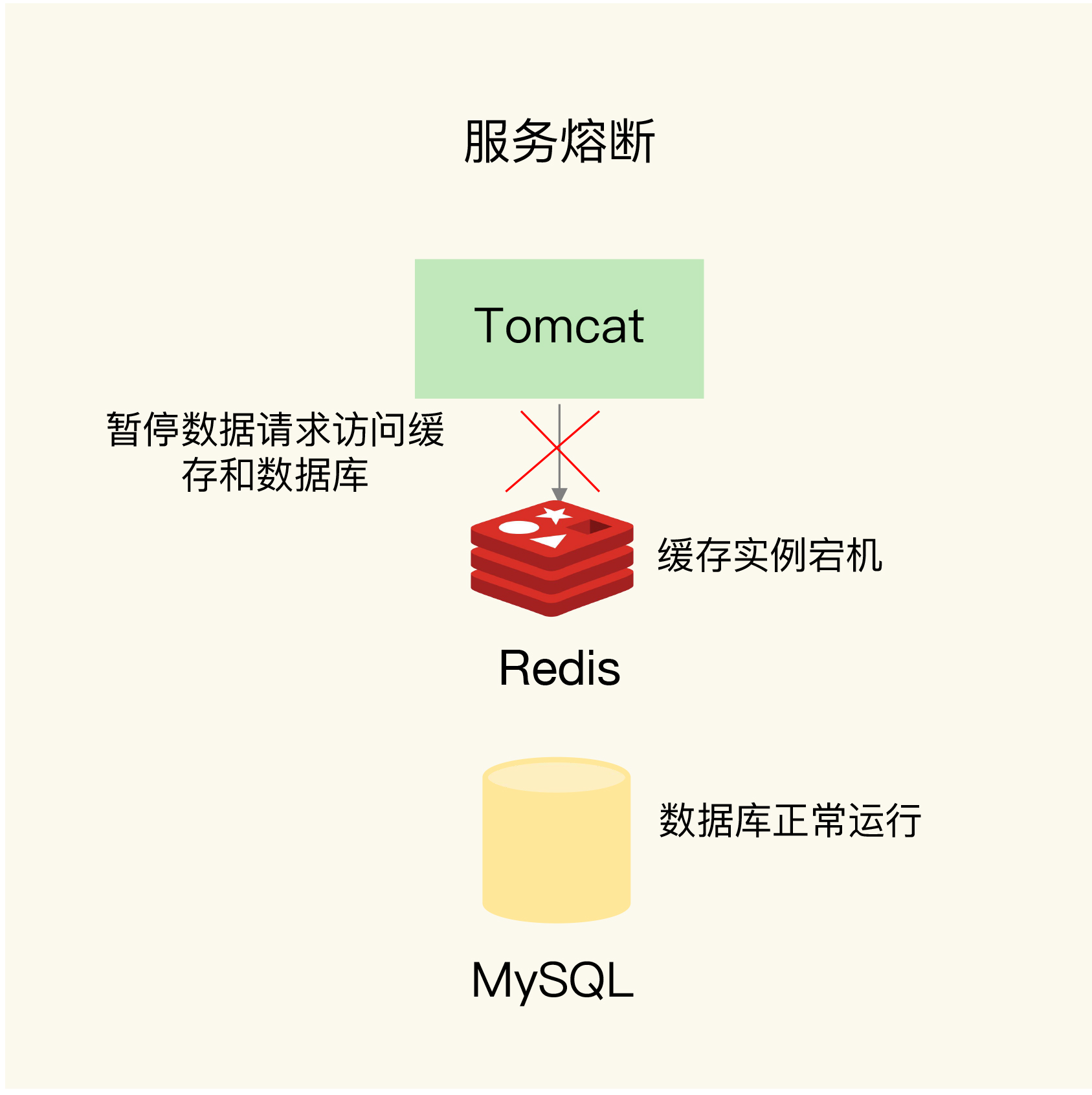
- 熔断保证DB绝对安全:
![img]()
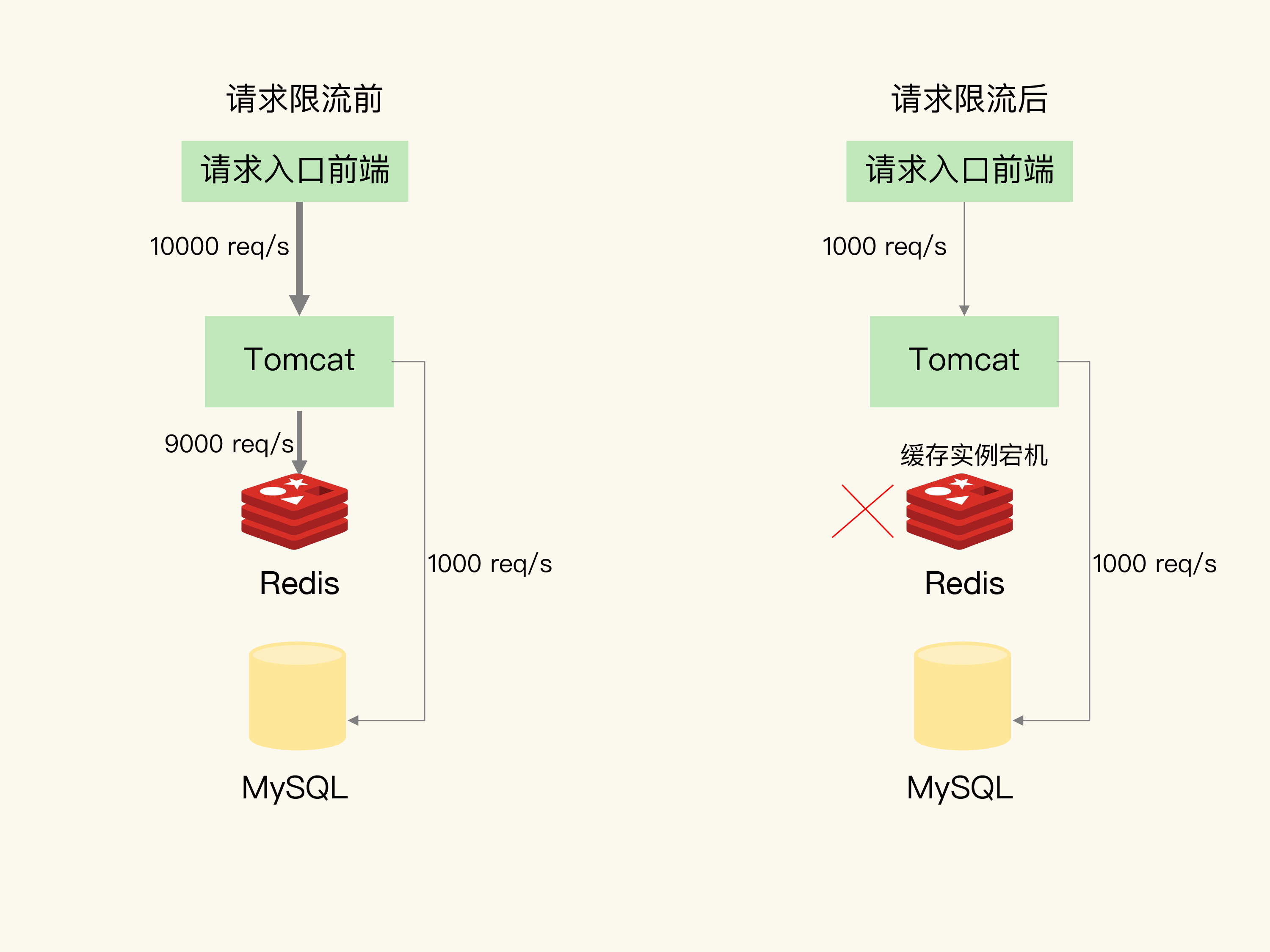
- 令牌桶限流, 保证业务可用
- 一般缓存的qps在10000, DB的qps在1000, 两者相差10倍, 则限流为1/10
![img]()
- 一般缓存的qps在10000, DB的qps在1000, 两者相差10倍, 则限流为1/10
缓存击穿
数据倾斜: 实例中热点数据过期, 或切片集群中热点切片宕机
- 热点数据不设过期时间(无损)
- 冷热切片分离 + 热切片备份
缓存穿透
缓存DB同时失效, 恶意读写不存在的数据
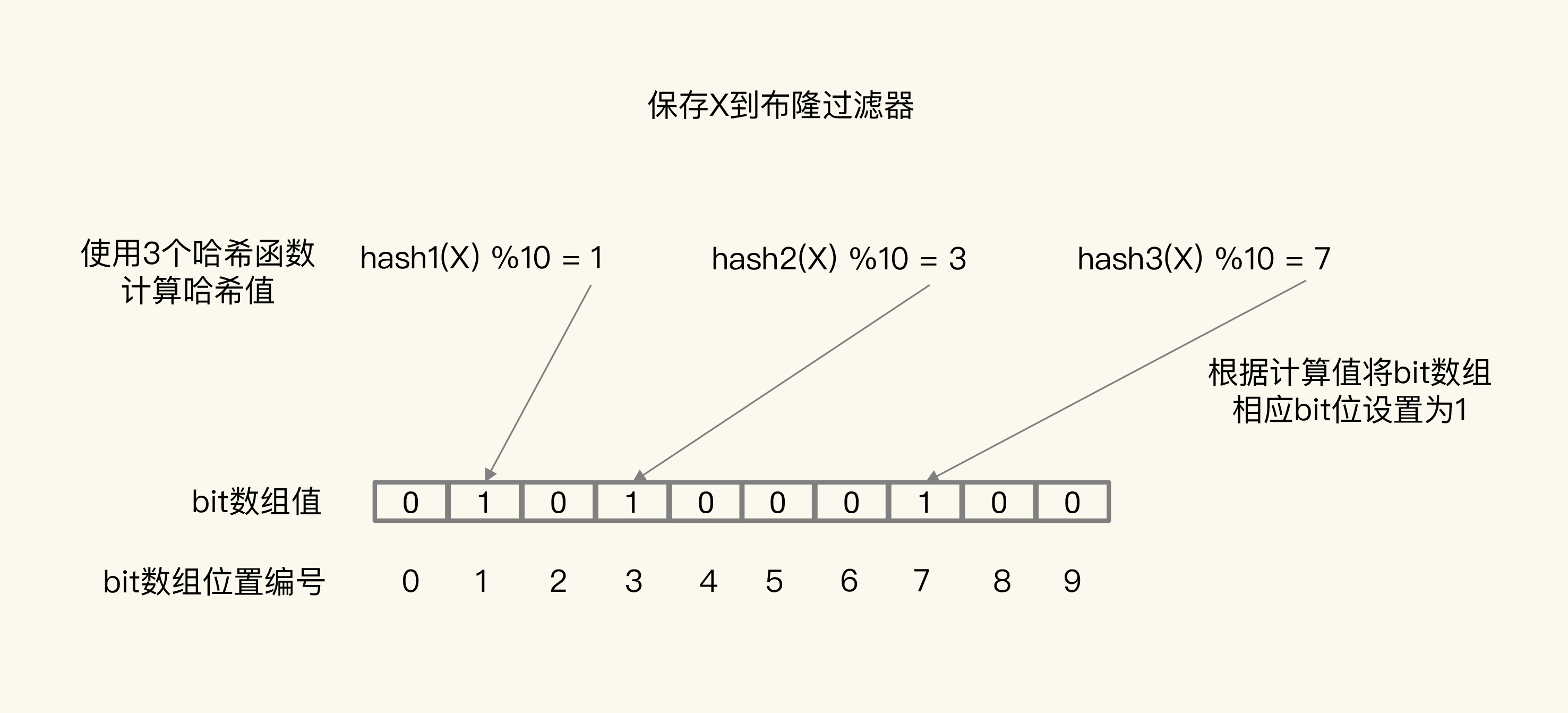
- 设置缺省返回值
- 写请求用布隆过滤器做标记, 读请求缓存不命中走DB时, 先用过滤器粗略判断数据是否存在, 拦截恶意请求(有损, 可能误判)
![img]()
- 前端拦截(无损)
缓存老化
大量冷数据充斥缓存, 缓存形同虚设
- LRU无法解决, 比如全表扫描 + 热点访问交替进行的场景, 冷数据不会被换出
- LFU按访问次数换出, 如果次数相同再按访问时间
- 记录访问次数的字段最大值255, 并且刚写入的数据可能被当做冷数据误伤 -> 次数非线性增加
- 假热数据, 热点过后不再被访问 -> 次数周期性衰减
本地缓存
- 6.0后在客户端开辟缓存空间, 无需访问redis实例, 但也要考虑缓存一致性问题
分布式锁
- 同步监视器本身也作为kv存储在单独的redis实例上, key是临界资源的特征值, value是锁状态
- 要保证读value, 改value, 写value操作的原子性 -> set nx + del + px或Lua脚本
# px防止执行业务逻辑阻塞始终占有锁
set KEY 1 px 3000 nx
...
del KEY
- 误删锁: 假如A加锁还未释放, B恶意释放锁, C就可以拿到锁与A竞争了 -> 设置锁状态value包含客户端特征, del时只允许对应客户端解锁
SET BIZ_KEY CLIENT_VAL PX 3000 NX
...
if redis.call("get", BIZ_KEY == CLIENT_VAL) then
return redis.call("del", BIZ_KEY)
else
return 0
end
-
要保证锁在的redis实例高可用, 否则锁失效 -> 锁集群 -> redlock
- 超过一半的锁实例加锁成功, 且总耗时不超过px生命周期 -> 加分布式锁成功
-
如果加锁后, 能预料到剩余生命px已不足以支撑完成业务逻辑, 则提前释放锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号