Python攻克之路-re模块
re模块
描述:正则表达式(或RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,产通过re模块实现,正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行.正则提供是模糊匹配.
字符串提供的方式是完成匹配,如ll就是对应ll
In [19]: s='hello world'
In [20]: s.find('ll')
Out[20]: 2 #不是个数,是位置
In [21]: s.find('llo')
Out[21]: 2
In [22]: s.find('h')
Out[22]: 0
In [23]: s.replace('ll','vv')
Out[23]: 'hevvo world'
字符匹配(普通字符、元字符)
普通字符:大多数字符和字母都会和自身匹配
In [28]: re.findall('reid','aljflsdjreiddsfjls') ##完全匹配,可以不使用正则
Out[28]: ['reid']
1.元字符:. ^ $ * + ? [] {} | () \
正则提供模糊匹配
In [26]: import re
In [27]: re.findall('w\w{2}l','hello world') #规则 内容 flags(标志位,可以修改默认规则,如不匹配换行符这个规则,可以修改)
Out[27]: ['worl']
.点:通配符,指匹配单个所有字符,不把匹配换行符\n
In [29]: re.findall('w..l','hello world')
Out[29]: ['worl']
^尖括号:以最开始的位置匹配
In [5]: re.findall('he..o','hjsdflhello')
Out[5]: ['hello']
In [6]: re.findall('^he..o','hjsdflhello')
Out[6]: []
In [8]: re.findall('^h...o','hjsdolhello')
Out[8]: ['hjsdo']
$:以结尾位置来匹配
In [10]: re.findall('r..d','lkjlkfjsdlkjfreidljlkj')
Out[10]: ['reid']
In [11]: re.findall('r..d$','lkjlkfjsdlkjfreidljlkj')
Out[11]: []
In [12]: re.findall('r..d$','lkjlkfjsdlkjfreidljlkjreid')
Out[12]: ['reid']
*:重复匹配(.*点表示任意多个字符,*重复前面任意多次,重复任意字符多次,0到无穷)
In [15]: re.findall('b*b','youbbbbbbblsdjflajf')
Out[15]: ['bbbbbbb']
In [18]: re.findall('jf*','youbbbbbbblsdlajf') #*可以匹配0次
Out[18]: ['jf']
In [16]: re.findall('.*','youbbbbbbblsdjflajf')
Out[16]: ['youbbbbbbblsdjflajf', ''] #匹配所有,而且空的也是一个
+:重复匹配前一个字符(1到无穷,不能是0次)
In [21]: re.findall('jb+','youbbbbbbblsdlajf') #至少有一个b,0个匹配不上
Out[21]: []
In [22]: re.findall('jb+','youbbbbbbblsdlajbbbbbbbbbbf')
Out[22]: ['jbbbbbbbbbb']
In [24]: re.findall('j+f','youbjjjjjjflsdlajf')
Out[24]: ['jjjjjjf', 'jf']
?:指[0,1]闭区间的0到1,意思只能取前面一个元素的0次到1次
In [25]: re.findall('a?b','aaaabhghabfb')
Out[25]: ['ab', 'ab', 'b'] #aaaab的ab,hab只的ab,最的fb是匹配0个a
{}: 定义匹配范围(至少n次)
In [30]: re.findall('a{5}b','ab')
Out[30]: [] #0个不行
In [31]: re.findall('a{5}b','aaaab')
Out[31]: [] #4个不行
In [32]: re.findall('a{5}b','aaaaab')
Out[32]: ['aaaaab'] #5个可以
In [33]: re.findall('a{5}b','aaaaaab')
Out[33]: ['aaaaab'] #6个可以,不包括第1个
范围{1,3}(至少n次,最多n+1次)
In [34]: re.findall('a{1,3}b','b') #0次
Out[34]: []
In [35]: re.findall('a{1,3}b','ab') #1次
Out[35]: ['ab']
In [36]: re.findall('a{1,3}b','aab') #2次
Out[36]: ['aab']
In [37]: re.findall('a{1,3}b','aaab') #3次
Out[37]: ['aaab']
In [38]: re.findall('a{1,3}b','aaaab') #4次,先锚定b,是按最大次数匹配,贪婪匹配
Out[38]: ['aaab']
Summary:
(1)、*等于{0,正无穷}
(2)、+等于{1,正无穷}
(3)、?等于{0,1}
[]: 字符集:可以带内容代表范围
多选一:
In [61]: re.findall('a[c,d]x','ax') #没有一个
Out[61]: []
In [62]: re.findall('a[c,d]x','acx') #有一个c
Out[62]: ['acx']
In [63]: re.findall('a[c,d]x','adx') #有一个d
Out[63]: ['adx']
In [64]: re.findall('a[c,d]x','acdx') #有cd
Out[64]: []
In [65]: re.findall('a[c ,d]x','acx') #在字符后面可有空格
Out[65]: ['acx']
In [66]: re.findall('[a-z]','adx') #所有的小写字母都匹配,每次只匹配一个
Out[66]: ['a', 'd', 'x']
In [6]: re.findall('a[b,c]d','abcd') ##实际不用逗号区分
Out[6]: []
In [7]: re.findall('a[bc]d','abcd')
Out[7]: []
In [8]: re.findall('a[b,c]d','a,d')
Out[8]: ['a,d']
取消元字符的特殊功能(例外\ ^ -)
In [68]: re.findall('[w,*]','adx') #*是特殊的元字符,在这里只表示*
Out[68]: []
In [69]: re.findall('[w,*]','awdx')
Out[69]: ['w']
In [70]: re.findall('[w,*]','awdx*') #*的显示
Out[70]: ['w', '*']
In [71]: re.findall('[w,.]','awdx.')
Out[71]: ['w', '.']
In [73]: re.findall('[a-z1-9A-Z]','awA14') #匹配所有数字和字母
Out[73]: ['a', 'w', 'A', '1', '4']
In [74]: re.findall('[a-z1-9A-Z]','ay23BD') #写法不一样,效果一样
Out[74]: ['a', 'y', '2', '3', 'B', 'D']
In [75]: re.findall('[a-z,1-9,A-Z]','ay23BD')
Out[75]: ['a', 'y', '2', '3', 'B', 'D']
[^ ]: 取反
In [2]: re.findall('[^t]','ijdkdkty') #除了t
Out[2]: ['i', 'j', 'd', 'k', 'd', 'k', 'y']
In [3]: re.findall('[^5,3]','id3jdkdkty')
Out[3]: ['i', 'd', 'j', 'd', 'k', 'd', 'k', 't', 'y']
In [4]: re.findall('[^5,3]','id3jdkdk5ty') #非3或非5
Out[4]: ['i', 'd', 'j', 'd', 'k', 'd', 'k', 't', 'y']
\ : 反斜杠
反斜杠后面接元字符去除特殊功能
反斜杠后面接一部分普通字符实现特殊功能
与普通字符的结合:
\d 匹配任何十进制数,它相当于类[0-9] \D 匹配任何数字字符,它相当于[^0-9] \s 匹配任何空白字符,它相当于[\t\n\r\f\v] \S 匹配任何非空白字符,它相当于[^ \t\n\r\f\v] \w 匹配任何字母数字字符,它相当于[a-zA-Z0-9] \W 匹配任何非字母数字字符,它相当于[^ a-zA-Z0-9] \b 匹配一个特殊字符的边界
\d
In [5]: re.findall('\d{11}','dslfj201920930293029032039302') #匹配11个数字
Out[5]: ['20192093029', '30290320393'] ##匹配完第1个11个数字放进列表,再匹配第2个11个数字
\s
In [8]: re.findall('\slfj','dslfj')
Out[8]: []
In [9]: re.findall('\slfj','ds lfj') ##空白
Out[9]: [' lfj']
\w
In [10]: re.findall('\wlfj','ds lfj') #空白不行
Out[10]: []
In [11]: re.findall('\wlfj','dslfj')
Out[11]: ['slfj']
In [12]: re.findall('\w','dslfj')
Out[12]: ['d', 's', 'l', 'f', 'j']
\b
In [13]: re.findall('I','I am LINDA')
Out[13]: ['I', 'I'] #可能有时的需求是要取第一个I,I后面有一个空格,\b可以捕捉到,但是它不代表空白
In [14]: re.findall('I\b','I am LINDA')
Out[14]: []
In [15]: re.findall(r'I\b','I am LINDA')
Out[15]: ['I']
In [16]: re.findall(r'I\b','I am LI$NDA') #与任何各特殊字符的边界都可以捕捉,第二个I后是$
Out[16]: ['I', 'I']
In [19]: re.findall(r'\bI',' Iam LI$NDA') #可以在不同位置捕捉
Out[19]: ['I']
\:去除特殊功能
In [22]: re.search('a.','ajd').group()
Out[22]: 'aj'
In [23]: re.search('a\.','ajd').group()
AttributeError: 'NoneType' object has no attribute 'group' #加了\就变成点,没有匹配成功,而search没有匹配成功不能调用group,因为没有对象
In [24]: re.search('a\.','a.jd').group()
Out[24]: 'a.'
消除\特殊功能
In [26]: re.findall("\\","ddd\de")
error: bad escape (end of pattern) at position 0 #报错
In [27]: re.findall("\\\\","ddd\de")
Out[27]: ['\\']
In [28]: re.findall(r"\\","ddd\de") #使用r,或者使用4个斜杠,但是显示两个斜杠
Out[28]: ['\\']
分析:代码是在Python的解释器中进行解释的,现在在python解释器引用re模块来使用正则表达式,re里面封装了语法规范,re中的\是有特殊功能的,所以在re里要使用\\来匹配一个\,但是第一步是使用python解释器来解释的,在python里的\也是有特殊意义的,在re本来使用\\来解释,在python里还要每个\使用两个\\来解释,所以在python解释器时使用4个\\\\\来解释一个\
另一种做法是加个r,也就是告诉python这是原生的字符器,不需要转译,直接两个\\就可以
() |或
In [30]: re.search('(as)+','adfdkasas').group() ##as作为一个整体来重复匹配
Out[30]: 'asas'
In [31]: re.search('(es)|4','es').group()
Out[31]: 'es'
In [40]: re.search('(es)|4','4es').group()
Out[40]: '4'
与findall()结合的效果
注:findall()方法与()一起使用时,是把()组里面的内容取出来的
In [10]: re.findall('www.(\w+).com','www.shoyou.com')
Out[10]: ['shoyou']
?:取消组的权限
In [11]: re.findall('www.(?:\w+).com','www.shoyou.com')
Out[11]: ['www.shoyou.com']
分组实例
描述:(?P<id>\d{3})一个括号代表一个整体分组,?P固定写法给组命名,<>存放组的名字,\d{3}就是匹配的内容,\d{3}是匹配3个数字,这3个数的名字是id,\w{3}三个字母的名字是name
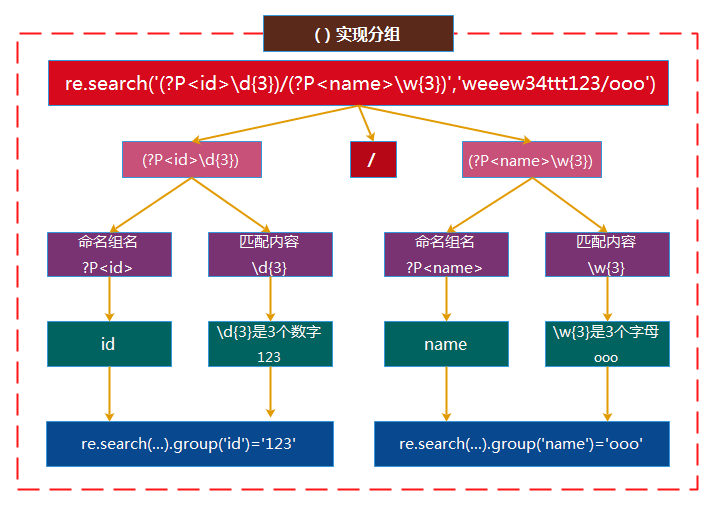
In [43]: re.search('(?P<id>\d{3})/(?P<name>\w{3})','weeew34ttt123/ooo')
Out[43]: <_sre.SRE_Match object; span=(10, 17), match='123/ooo'>
In [44]: re.search('(?P<id>\d{3})/(?P<name>\w{3})','weeew34ttt123/ooo').group()
Out[44]: '123/ooo'
In [45]: re.search('(?P<id>\d{3})/(?P<name>\w{3})','weeew34ttt123/ooo').group('id')
Out[45]: '123'
In [46]: re.search('(?P<id>\d{3})/(?P<name>\w{3})','weeew34ttt123/ooo').group('name')
Out[46]: 'ooo'
2.与正则结合的常用方法
search: 匹配到第一个就不往下匹配
In [20]: re.search('zk','ljdflszklskdjfzk')
Out[20]: <_sre.SRE_Match object; span=(6, 8), match='zk'> #返回是一个对象
In [21]: re.search('zk','ljdflszklskdjfzk').group() #通过group方法取得结果
Out[21]: 'zk'
match
In [4]: import re
In [5]: lin=re.match('you','lkjfldsjyouds')
In [6]: print(lin)
None
In [7]: lin=re.match('you','youlkjfldsjyouds') ##从开始匹配
In [8]: print(lin)
<_sre.SRE_Match object; span=(0, 3), match='you'>
In [9]: lin=re.match('you','youlkjfldsjyouds').group()
In [10]: print(lin)
you
split
In [11]: re.split('y','aaylklj')
Out[11]: ['aa', 'lklj']
In [12]: re.split('[y,k]','aaylklj') ##注:先使用y分成aa,lklj,再使用k把已经分开的分,aa,l,lj
Out[12]: ['aa', 'l', 'lj']
In [14]: re.split('[y,a]','auylklj') #有空,y先分成au,lklj,a在分在a前面空格和u
Out[14]: ['', 'u', 'lklj']
sub(): 与字符串的replace相似
In [15]: re.sub('t.m','jerry','alsdfkjtomsdlf') #规则 替换成什么内容 替换前的内容 替换次数
Out[15]: 'alsdfkjjerrysdlf'
In [13]: re.sub('\d','great','reid3you4',1) #查找数字,然后替换
Out[13]: 'reidgreatyou4'
In [14]: re.subn('\d','great','reid3you4') #subn提醒替换次数
Out[14]: ('reidgreatyougreat', 2)
complie():
描述:有一种规则可能要引用多次
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象.第二个参数flag是匹配模式,取值可以使按位或运算'|‘表示同时生效,比如re. | re.M
可以把正则表达式编译成一个正则表达对象. 可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率
一般情况:匹配多次,写多次
In [17]: re.findall('\.com','sdfkljds.comslk')
Out[17]: ['.com']
In [18]: re.findall('\.com','sdfewfsdasdfds.comslk')
Out[18]: ['.com']
使用complie实现
In [22]: obj=re.compile('\.com') #直接编译对象,只编译一次,这里的参数是规则
In [23]: obj.findall('sdfkljds.comslk') #调用多次时会效率稍微高点
Out[23]: ['.com']
In [24]: obj.findall('seaeerws.comslk')
Out[24]: ['.com']
finditer: 返回迭代器
In [15]: re.finditer('\d','reid3you4')
Out[15]: <callable_iterator at 0x7fba9a1420f0>
In [16]: next(re.finditer('\d','reid3you4'))
Out[16]: <_sre.SRE_Match object; span=(4, 5), match='3'>
In [17]: next(re.finditer('\d','reid3you4')).group()
Out[17]: '3'
Summary:
a. findall() : 所有结果都返回一个列表
b. search(): 返回匹配到第一个对象(object),对象可以调用group()返回结果
c. match(): 只在字符串开始匹配,也返回匹配到第一个对(object),对象调用group返回结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号