一文入门Redis
一文入门Redis
一、Redis简介
Redis:REmote DIctionary Server(远程字典服务)。是一款使用C语言编写的、开源的、基于内存的、高性能的、可持久化的非关系型Key-Value数据库。
二、常用数据类型
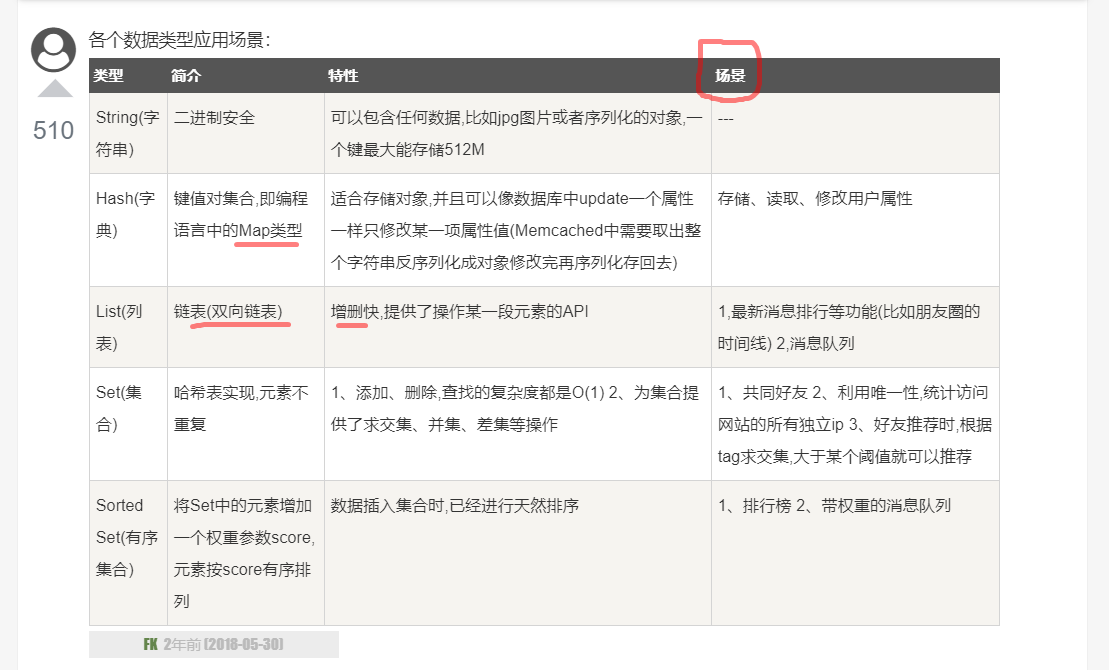
1、String(字符串)
string是redis最基本的数据类型,一个key对应一个value。string类型是二进制安全的,可以包含任何数据,包括图片、序列化的对象等,最大存储512MB。
常用命令:
| 命令 | 描述 | 用法 |
|---|---|---|
| SET | 1、将value关联到key;2、key已关联则覆盖;3、原本key带有TTL(生存时间),那么TTL被清楚 | SET key value |
| GET | 1、返回key所关联的字符串值;2、key不存在返回null; | GET key |
| SETEX | 1、将value关联到key;2、设置key生存时间为seconds,单位为秒;3、如果key已关联则覆盖;4、原子操作,关联与设置生存时间同时完成 | SETEX key seconds value |
| SETNX | 1、将value关联到key,当且仅当key不存在;2、若key已存在,不做任何动作 | SETNX key value |
2、Hash(哈希)
hash是一个string类型的field和value的映射表,key 还是key,但是value是多个键值对(key-value),比较适合存储对象。
常用命令:
| 命令 | 描述 | 用法 |
|---|---|---|
| HSET | 1、将key中的field值设为value;2、filed已存在,被覆盖 | HSET key field value |
| HGET | 1、返回key中给定域field中的值 | HGET key field |
| HDEL | 1、删除key中的一个或多个指定域;2、不存在的域被忽略 | HDEL key field |
| HEXISTS | 1、查看key中,给定域field是否存在,存在返回1,否,返回0 | HEXISTS key field |
| HGETALL | 1、返回key中所有的域和值 | HGETALL key |
| HLEN | 1、返回key中域的数量 | HLNE key |
3、List(列表)
list 列表,它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表。有序、可以重复。
常用命令:
| 命令 | 描述 | 用法 |
|---|---|---|
| LPUSH | 1、将一个或多个值value按顺序插入到key的表头;2、key不存在,则创建并插入;3、key存在但不是list类型,返回错误; | LPSUH key value |
| LPUSHX | 1、将value插入到key的头部,当且仅当key存在且为list类型;2、key不存在,什么都不做; | LPUSHX key value |
| LPOP | 1、移除并返回key的头元素; | LPOP key |
| LRANGE | 1、返回key中指定区间的元素;2、可使用负数下标,-1表示list最后一个元素;3、start大于list最大下标,返回空列表;4、stop大于list最大下标,stop=list最大下标; | LRANG key start stop |
| LSET | 1、将key下标为index的元素值设为value;2、index超出范围或list为空,返回错误; | LSET key index value |
| LINDEX | 1、返回key中,下标为index的元素; | LINDEX key index |
| LLEN | 1、返回key的长度;2、key不存在,返回0; | LLEN key |
| RPUSH | 1、将一个或多个值value按顺序插入到key的表尾; | RPUSH key value |
| RPUSHX | 1、将value插入到key的尾部,当且仅当key存在且为list类型; | RPUSHX key value |
| RPOP | 1、移除并返回key的尾元素; | RPOP key |
4、Set(集合)
set 是 string 类型的无序集合。无序、不可重复
常用命令:
| 命令 | 描述 | 用法 |
|---|---|---|
| SADD | 1、将一个或多个元素加入key中,已存在的元素将返回0;2、key不存在,则创建并添加;3、key不是集合类型时,返回错误 | SADD key member |
| SCARD | 1、返回key中对应的集合中的元素数量 | SCARD key |
5、Zset(有序集合)
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
| 命令 | 描述 | 用法 |
|---|---|---|
| ZADD | 1、将一个或多个元素及其score值加入key中;2、如果已存在元素,则更新score值并重新插入; | ZADD key score member |
| ZCARD | 1、返回key中元素个数 | ZCARD key |
| ZRANGE | 1、返回key中指定区间类的成员,按score从小到大排序;2、相同score值按字典序排序;3、从大到小排序,使用ZREVRANGE命令;4、可通过WITHSCORES选项让成员和它的score值一并返回 | ZRANGE key start stop [WITHSCORES] |
| ZRANK | 1、返回有序集中成员member的排名,按score从小到大排序;2、排名以0为底,score最小的排名0 | ZRANK key member |
三、持久化
Redis 是一个内存数据库将数据库中的内容保存在内存中,这与传统的MySQL等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统数据库要快的多(内存的读写效率远远大于硬盘的读写效率),这也是Redis如此之快的原因。但是保存在内存中也随之带来了一个缺点,一旦断电或者宕机,那么内存数据库中的数据将会全部丢失。
为了解决这个缺点,Redis提供了将内存数据持久化到硬盘,以及用持久化文件来恢复数据库数据的功能。Redis 支持两种形式的持久化,分别是RDB(Redis DataBase)和AOF(Append Only File)。
1、持久化流程
- 客户端向服务端发送写操作(数据在客户端的内存中)。
- 数据库服务端接收到写请求的数据(数据在服务端的内存中)。
- 服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
- 操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
- 磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
- Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
- 操作系统发生故障,必须上面5步都完成才可以。
2、RDB
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。即将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可回复数据,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
2.1、原理
把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。也是Redis默认的持久化方式。
2.2、触发方式
1、save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
“save m n”:表示m秒内数据集存在n次修改时,自动触发bgsave。
redis.conf中默认配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
2、bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
2.3、优缺点
-
优点
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
-
缺点
1.RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,如果不采用压缩算法(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2.RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3.在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
3、AOF
全量备份总是耗时的,AOF是一种更加高效的方式,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
3.1、原理
通过保存Redis服务器所执行的写命令来记录数据库状态。
比如对于如下命令
set str1 "123"
sadd str2 "1" "2" "3"
lpush str3 "1" "2" "3"
RDB 持久化方式就是将 str1,str2,str3 这三个键值对保存到 RDB文件中,而 AOF 持久化则是将执行的 set,sadd,lpush 三个命令保存到 AOF 文件中。
3.2、配置
在redis.conf中,
- appendonly:默认值no,也就是说redis 默认使用的是rdb方式持久化,如果想要开启 AOF 持久化方式,需要将 appendonly 修改为 yes。
- appendfilename :aof文件名,默认是"appendonly.aof"
- appendfsync:aof持久化策略的配置:
- no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快,但是不太安全;
- always表示每次写入都执行fsync,以保证数据同步到磁盘,效率很低;
- everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。通常选择 everysec ,兼顾安全性和效率。
3.2、优缺点
-
优点
1.AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
2.AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。例如,如果我们不小心错用了 FLUSHALL 命令,在重写还没进行时,我们可以手工将最后的 FLUSHALL 命令去掉,然后再使用 AOF 来恢复数据。
-
缺点
1.对于具有相同数据的的 Redis,AOF 文件通常会比 RDF 文件体积更大。(当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集)
2.RDB 使用快照的形式来持久化整个 Redis 数据,而 AOF 只是将每次执行的命令追加到 AOF 文件中,因此从理论上说,RDB 比 AOF 方式更健壮。官方文档也指出,AOF 的确也存在一些 BUG,这些 BUG 在 RDB 没有存在。
4、如何选择持久化方式?
如果可以忍受一小段时间内数据的丢失,毫无疑问使用 RDB 是最好的,定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,而且使用 RDB 还可以避免 AOF 一些隐藏的 bug;否则就使用 AOF 重写。但是一般情况下建议不要单独使用某一种持久化机制,而是应该两种一起用,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。Redis后期官方可能都有将两种持久化方式整合为一种持久化模型。
如果有学到东西,请点赞给予鼓励,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号