结对作业二
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 结对学号 | 221801431 291800139 |
| 这个作业的目标 | 1.实现论文查询网站 2.部署项目到云服务器 3.结对编程 |
| 其他参考文献 | Echarts Echarts |
一、Github仓库地址
二、PSP表格
| PairProject PSP | Double Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| • Analysis | • 需求分析 | 120 | 90 |
| • Discussion | • 结对讨论 | 180 | 450 |
| • Learning | • 学习新技术 | 360 | 300 |
| • Design Spec | • 生成设计文档 | 180 | 120 |
| • Design Review | • 设计复审 | 40 | 30 |
| • Coding Standard | • 代码规范 | 30 | 40 |
| • Database Design | • 数据库设计 | 30 | 180 |
| • UI Design | • 界面设计 | 180 | 120 |
| • Front-end Coding | • 前端编码 | 1260 | 900 |
| • Back-end Coding | • 后端编码 | 1080 | 840 |
| • Code Review | • 代码复审 | 360 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 420 | 500 |
| • Deployment | • 部署 | 300 | 100 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 120 | 100 |
| • Size Measurement | • 计算工作量 | 60 | 45 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 4790 | 4005 |
三、部署链接
(国内云服务商域名没备案的话链接请给出IP的,否则过几天链接会因为未备案被封禁 )
四、成品展示
(提供10张以上的图片,或者采用GIF或者视频嵌入的方式)
-
爬取跳转
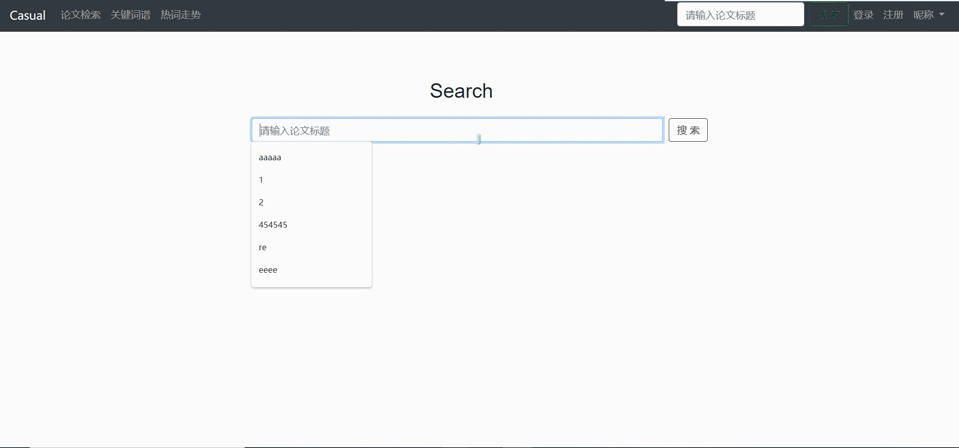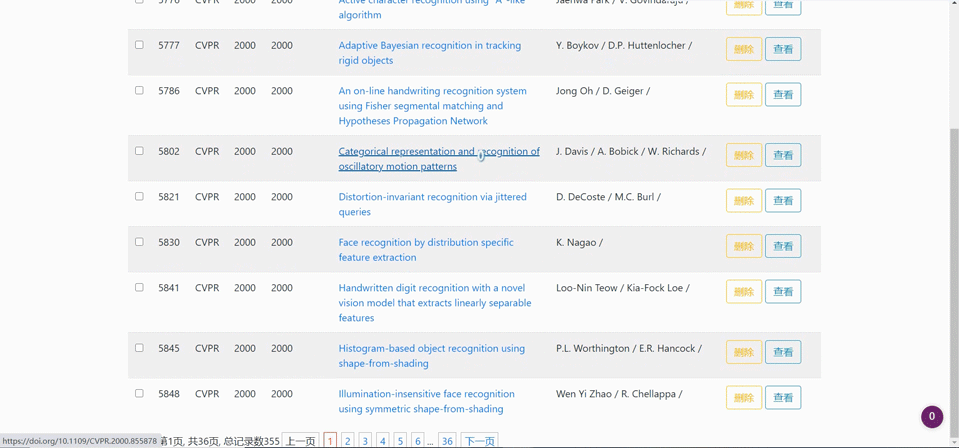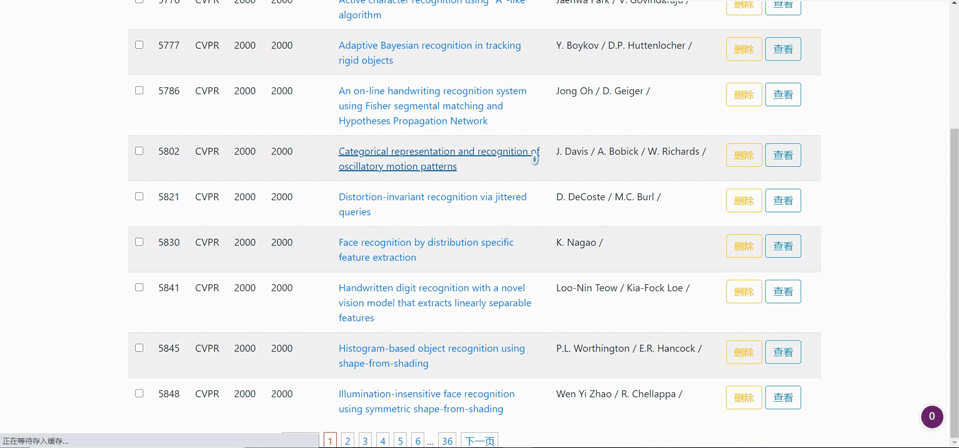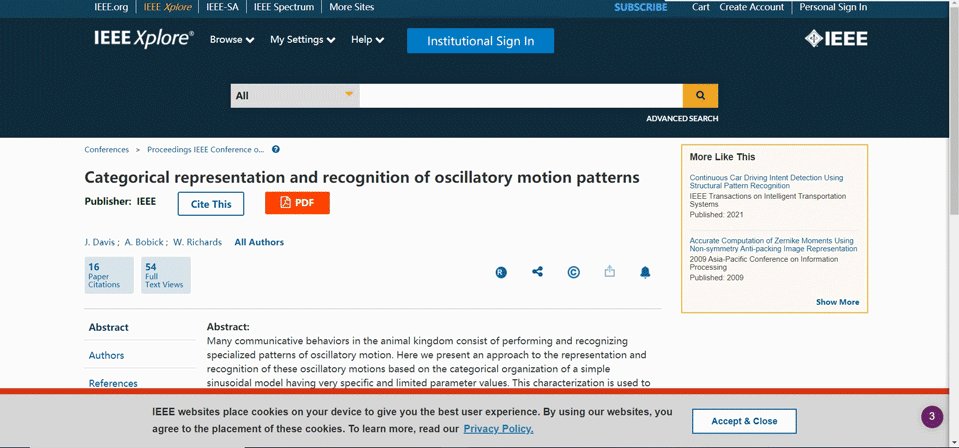
-
对已爬取地论文列表进行删除(可以单项删除、多选批量删除)

-
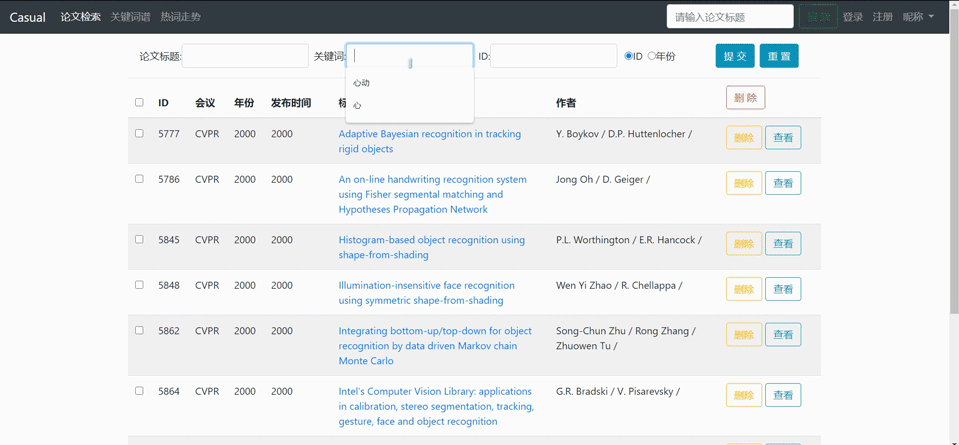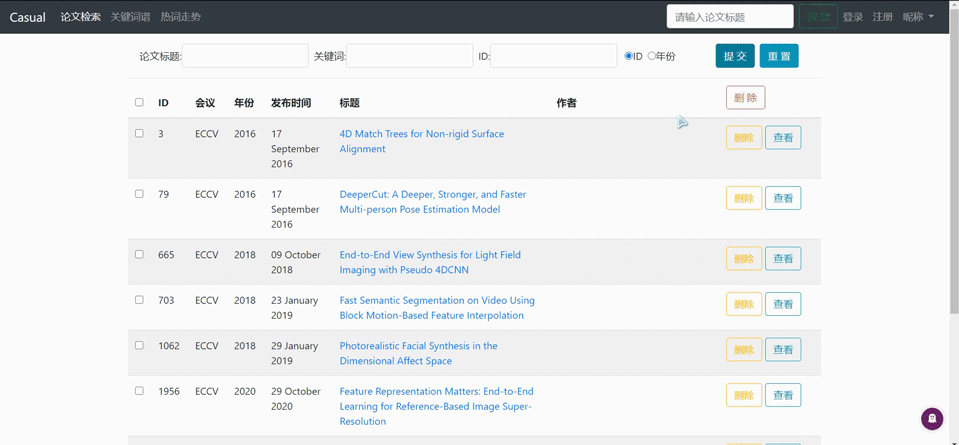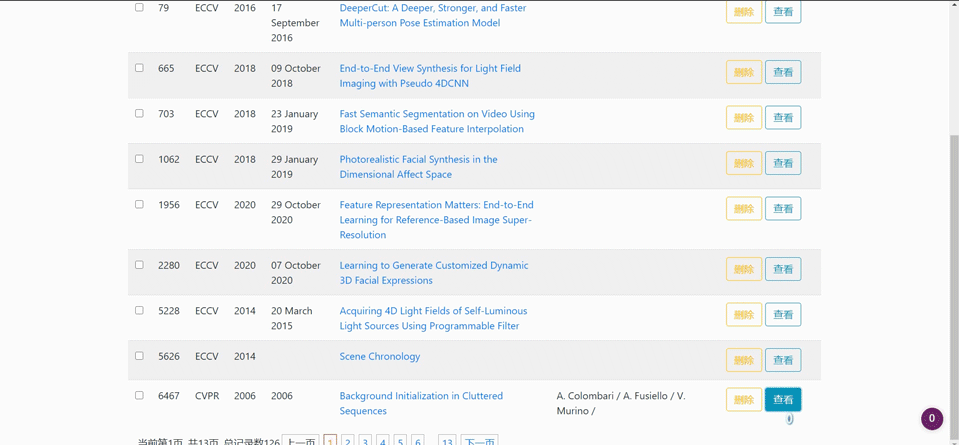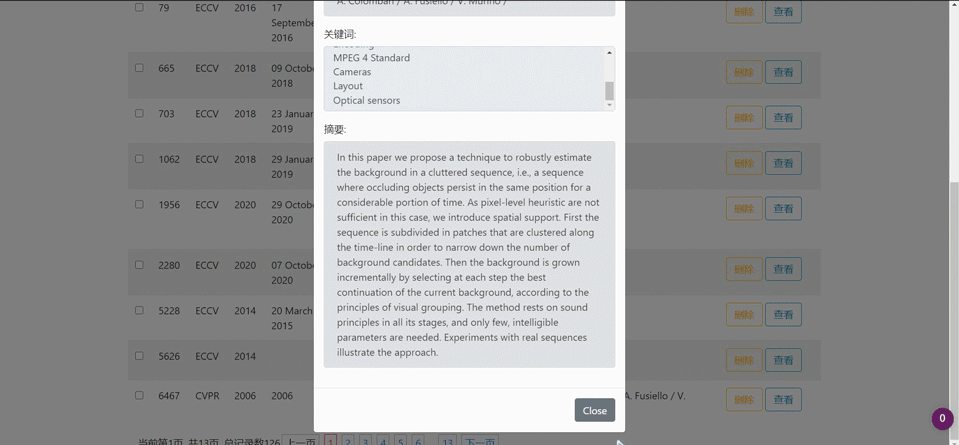
单个论文查看详情
-
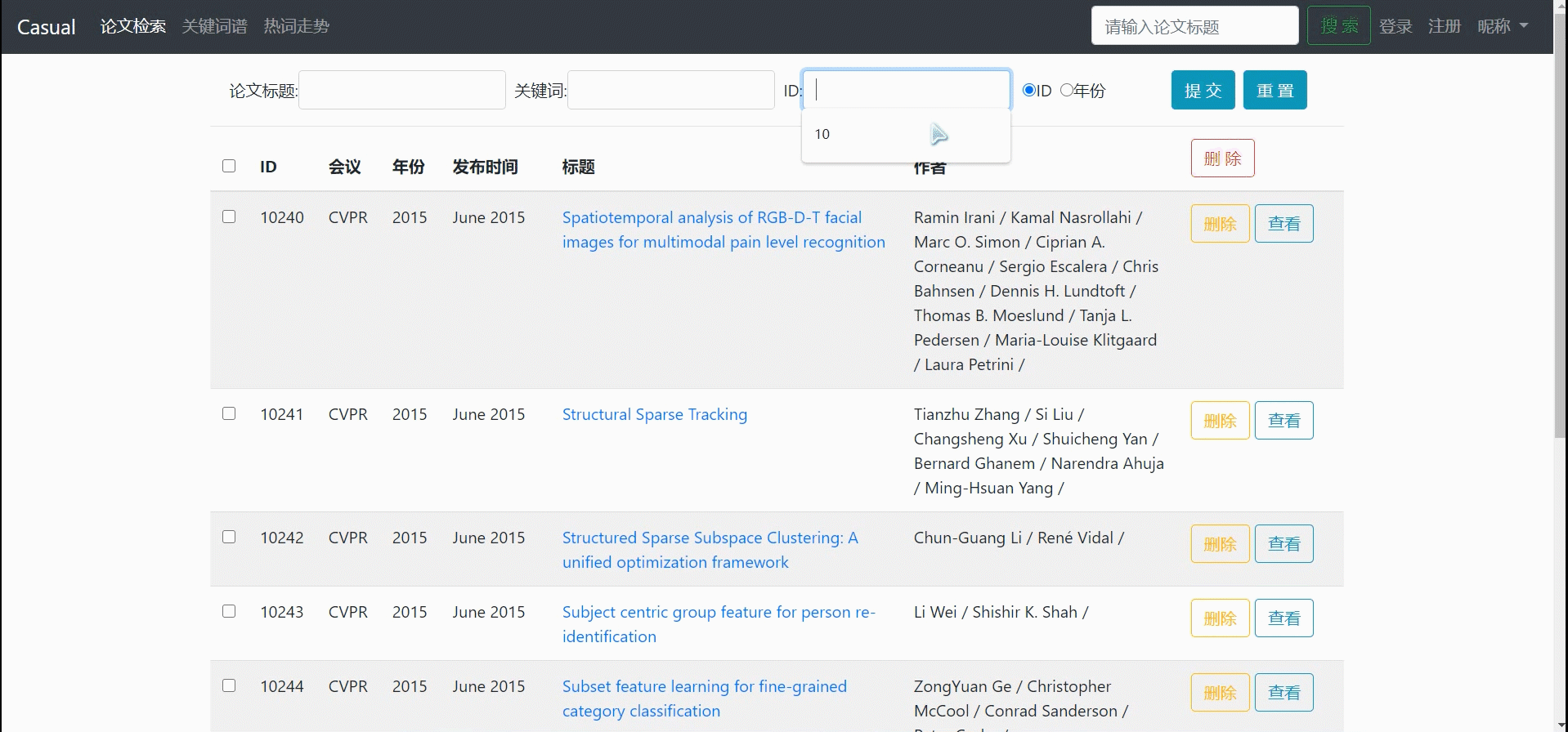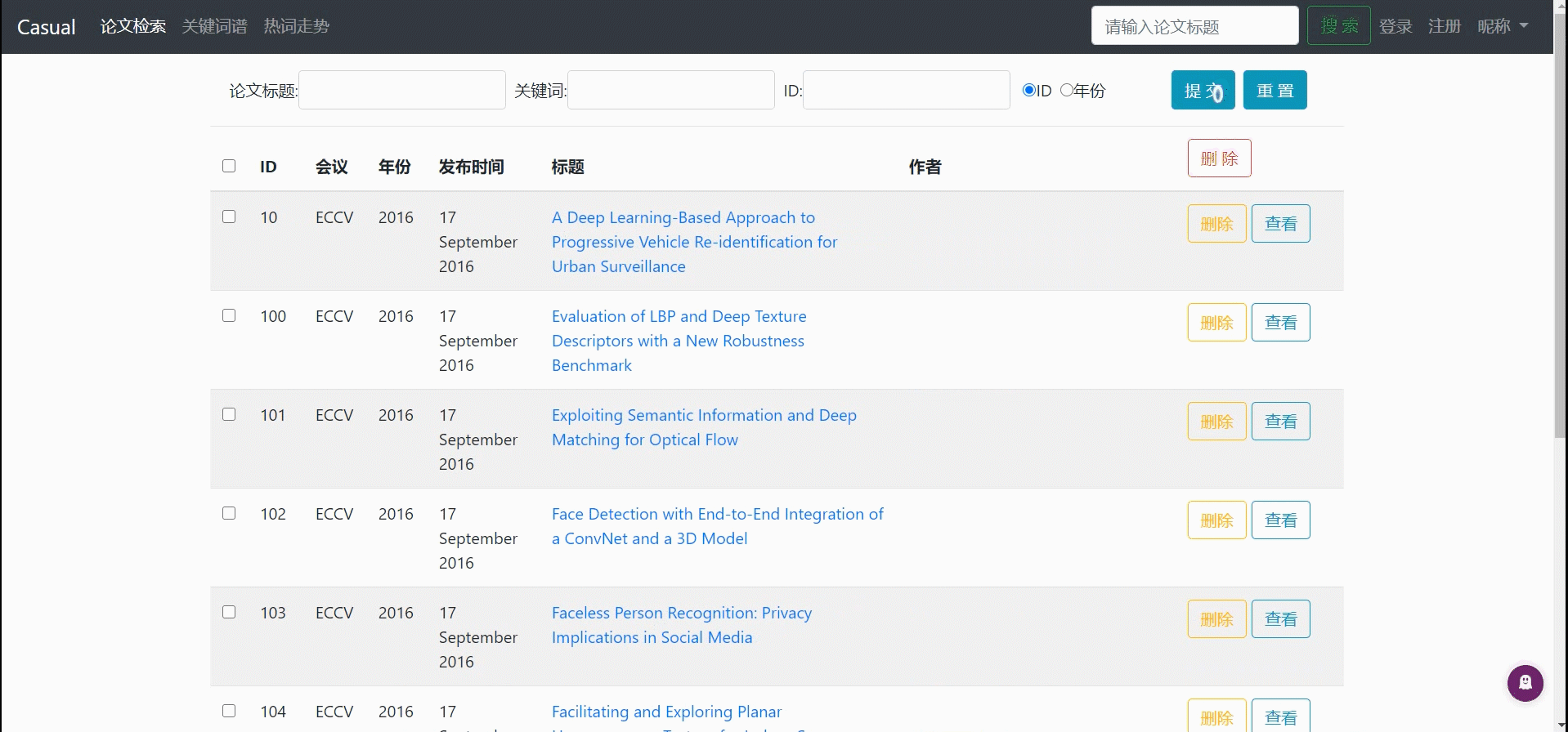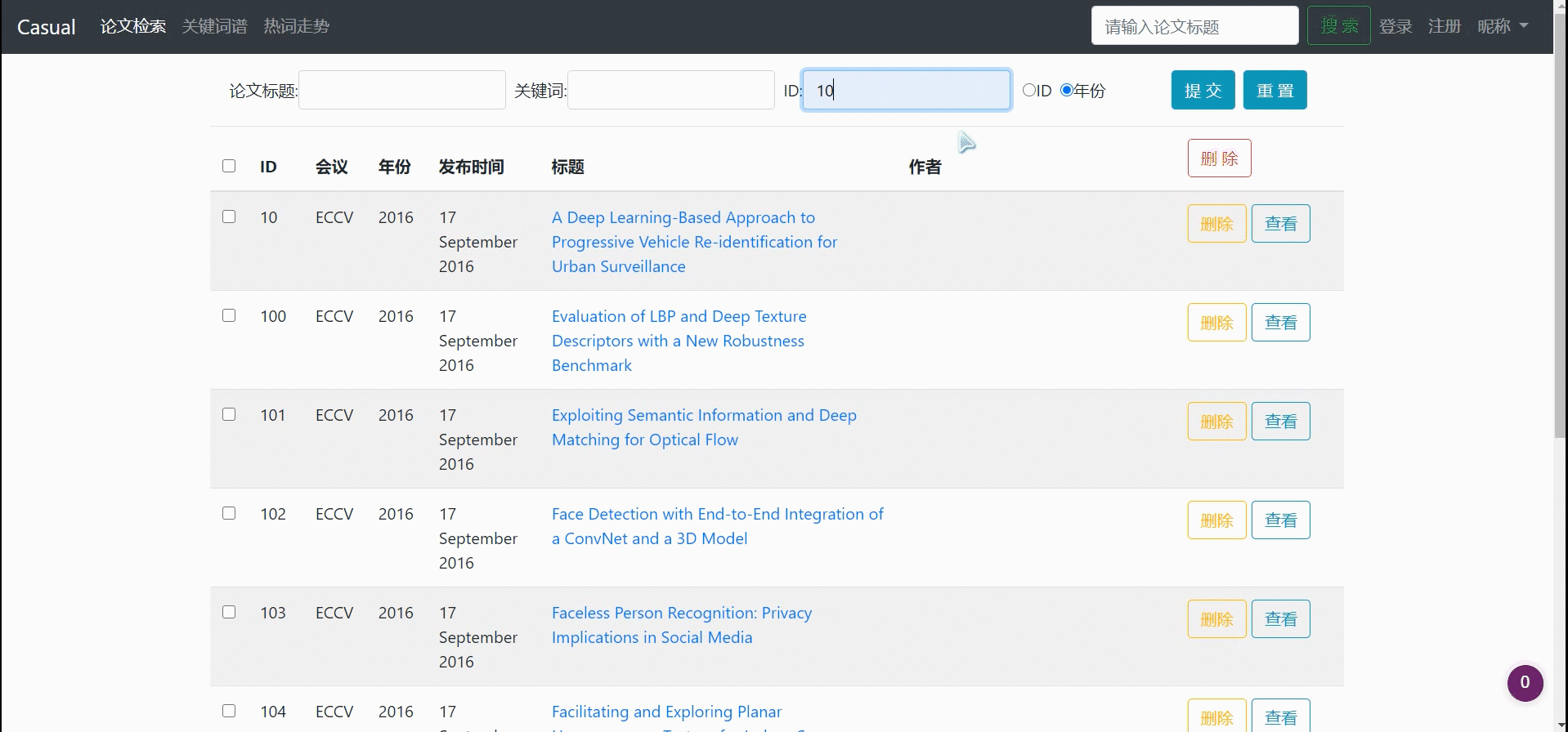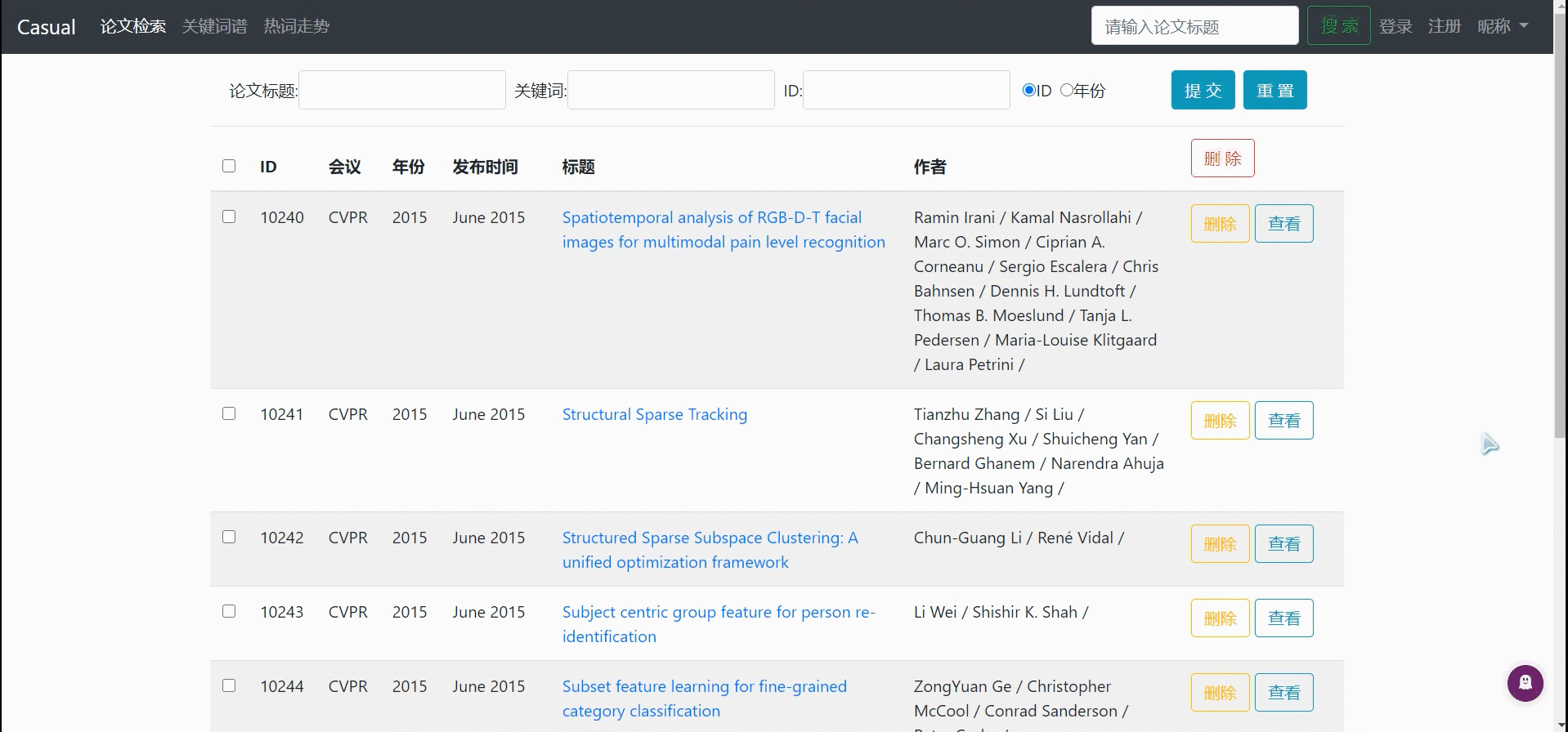
对论文列表进行模糊查询(可多种选项联合模糊查询:论文标题、关键词、ID)
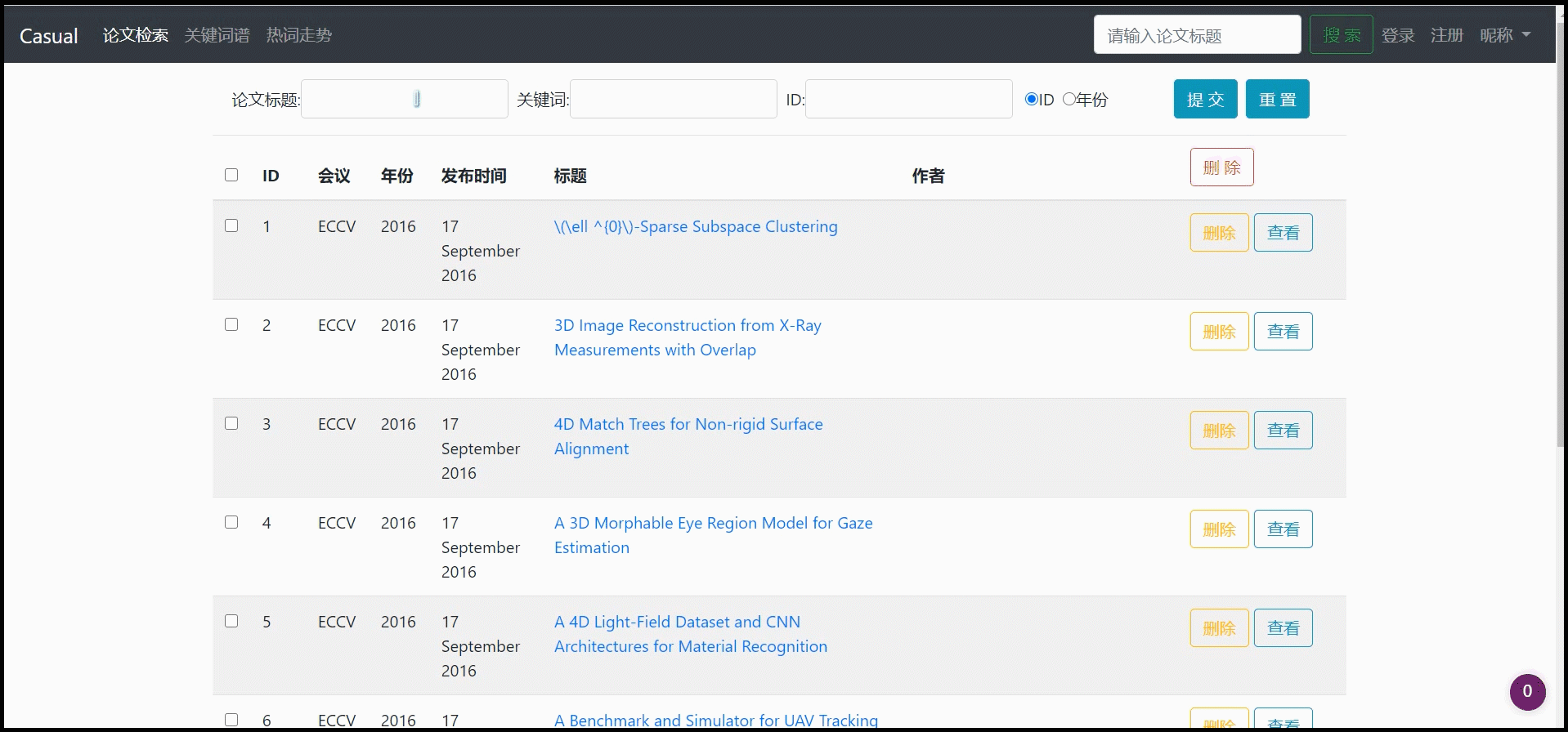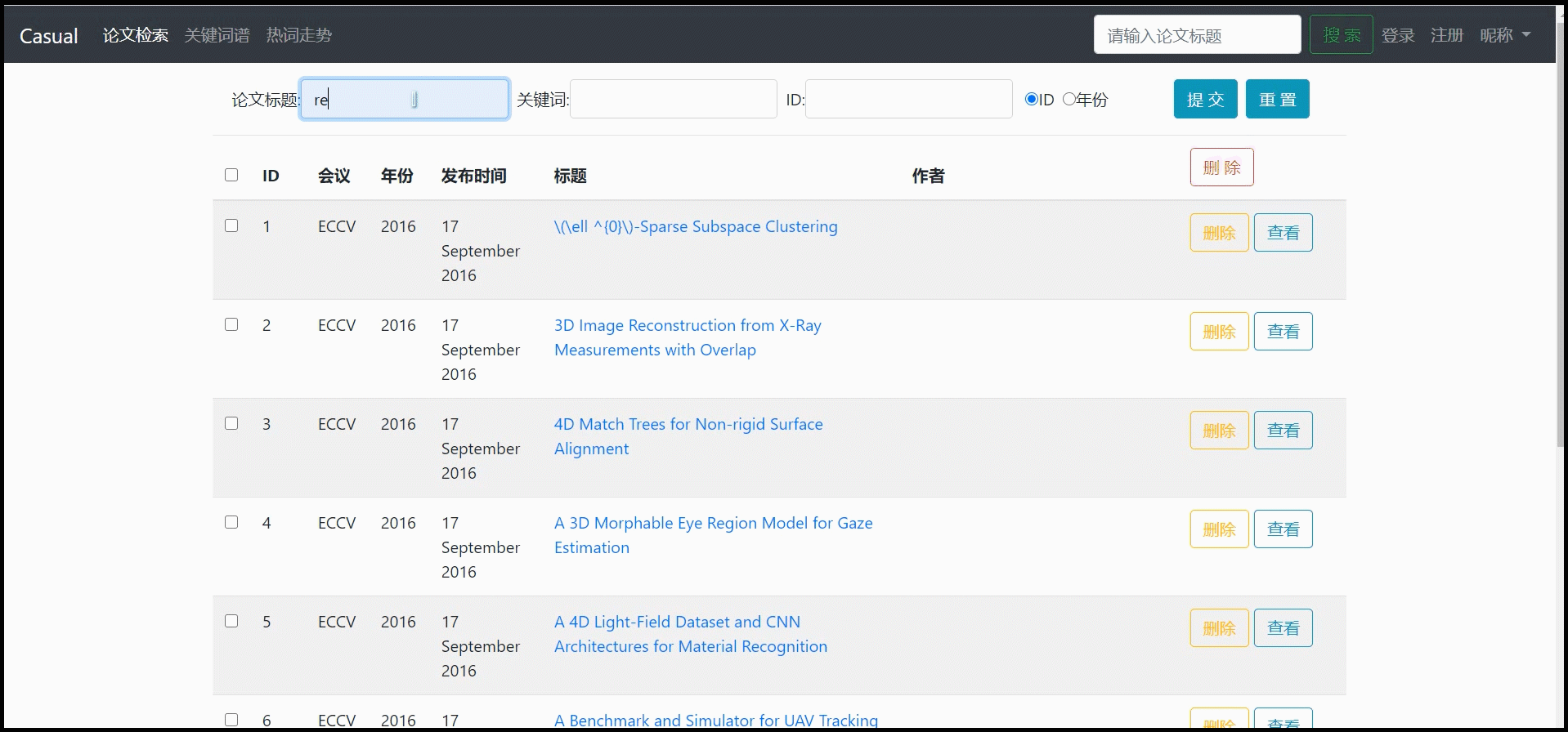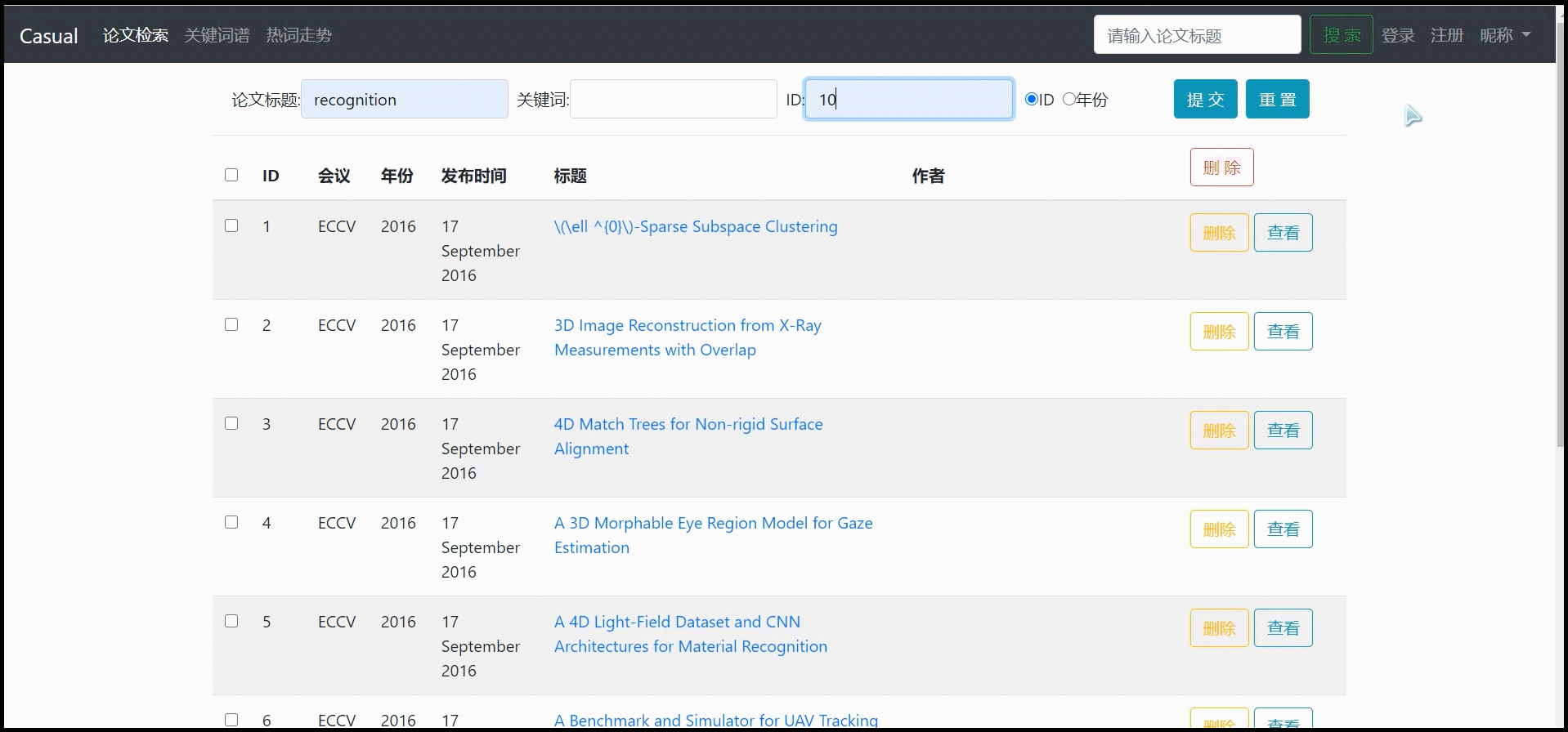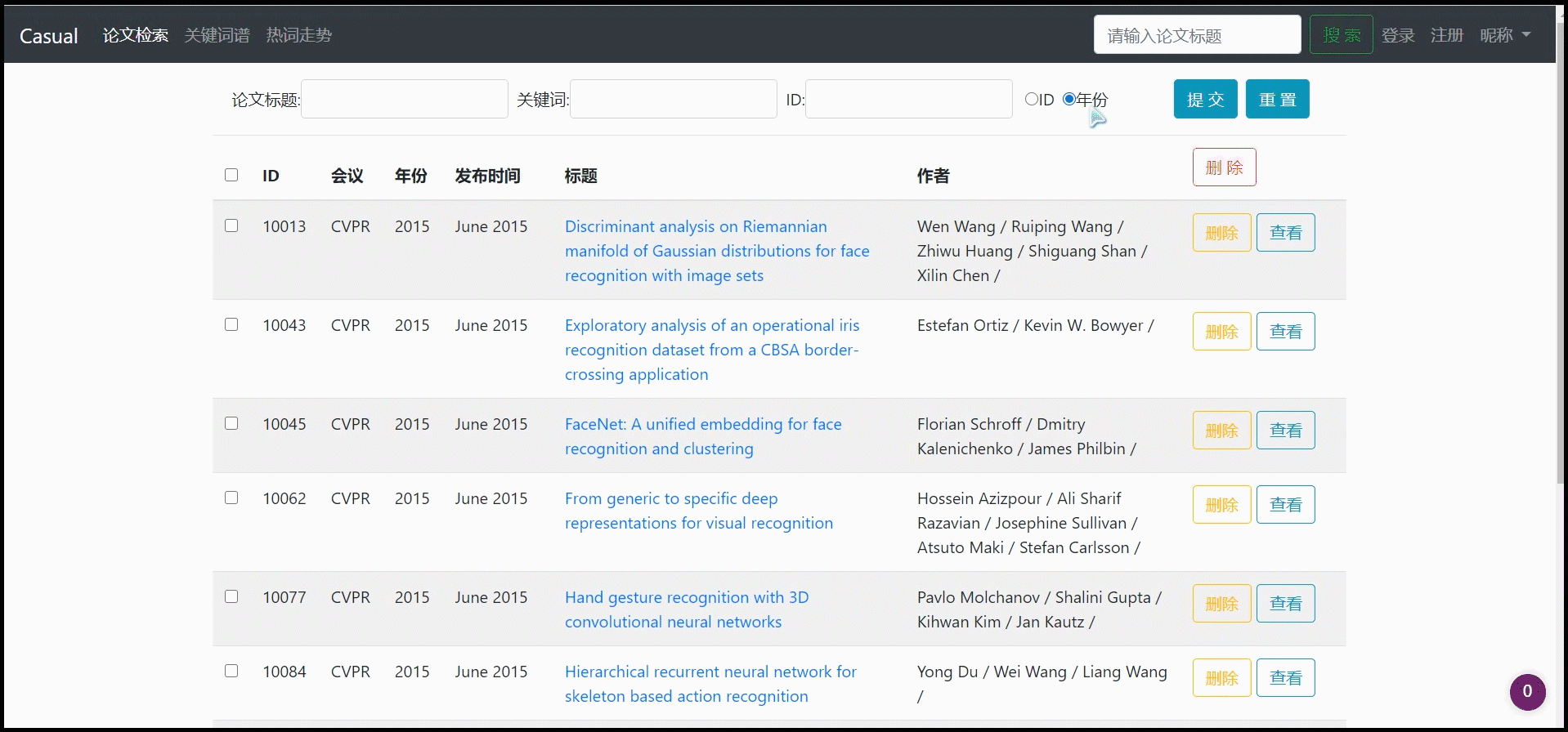
-
论文列表进行排序(ID[默认]、年份)
-
论文列表进行分页显示

-
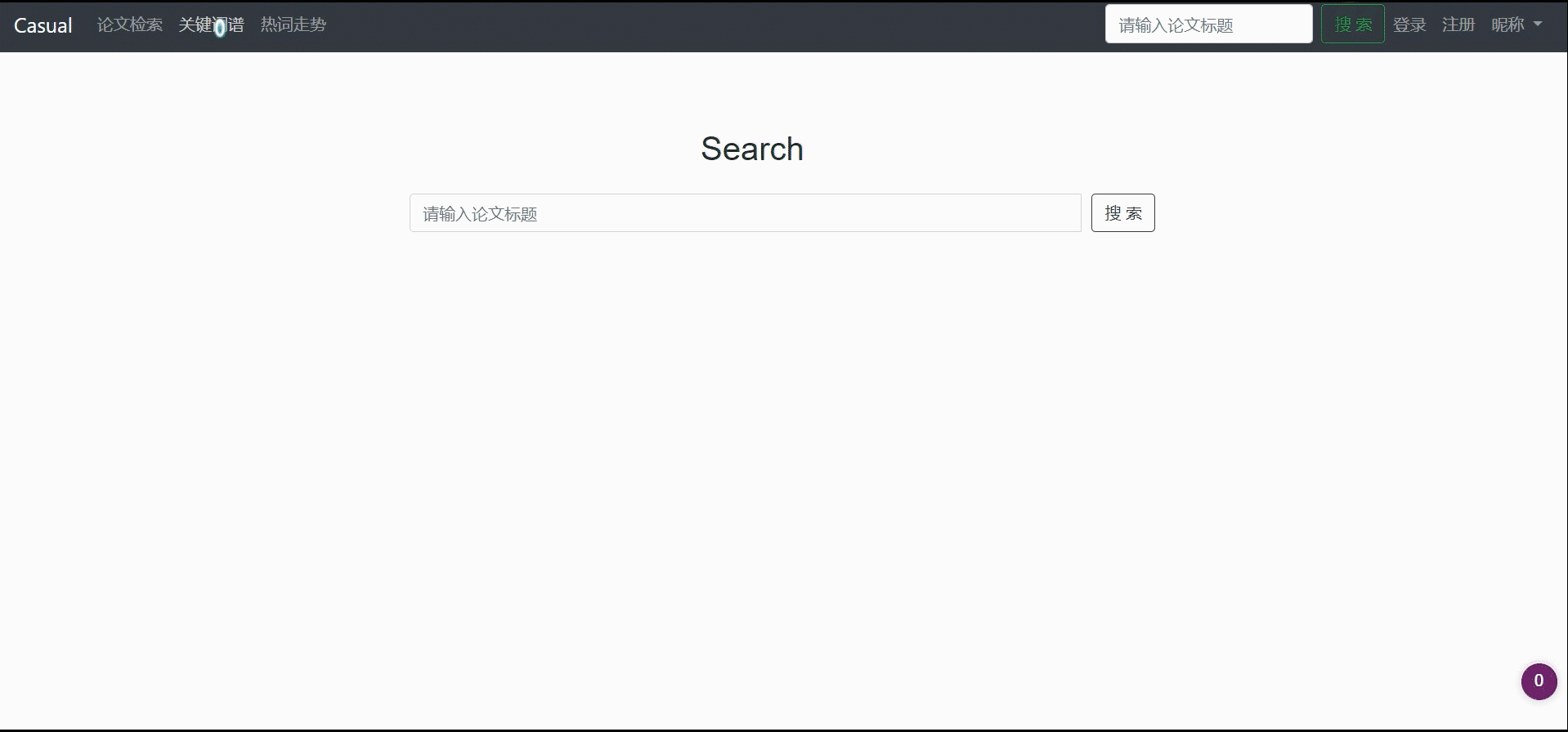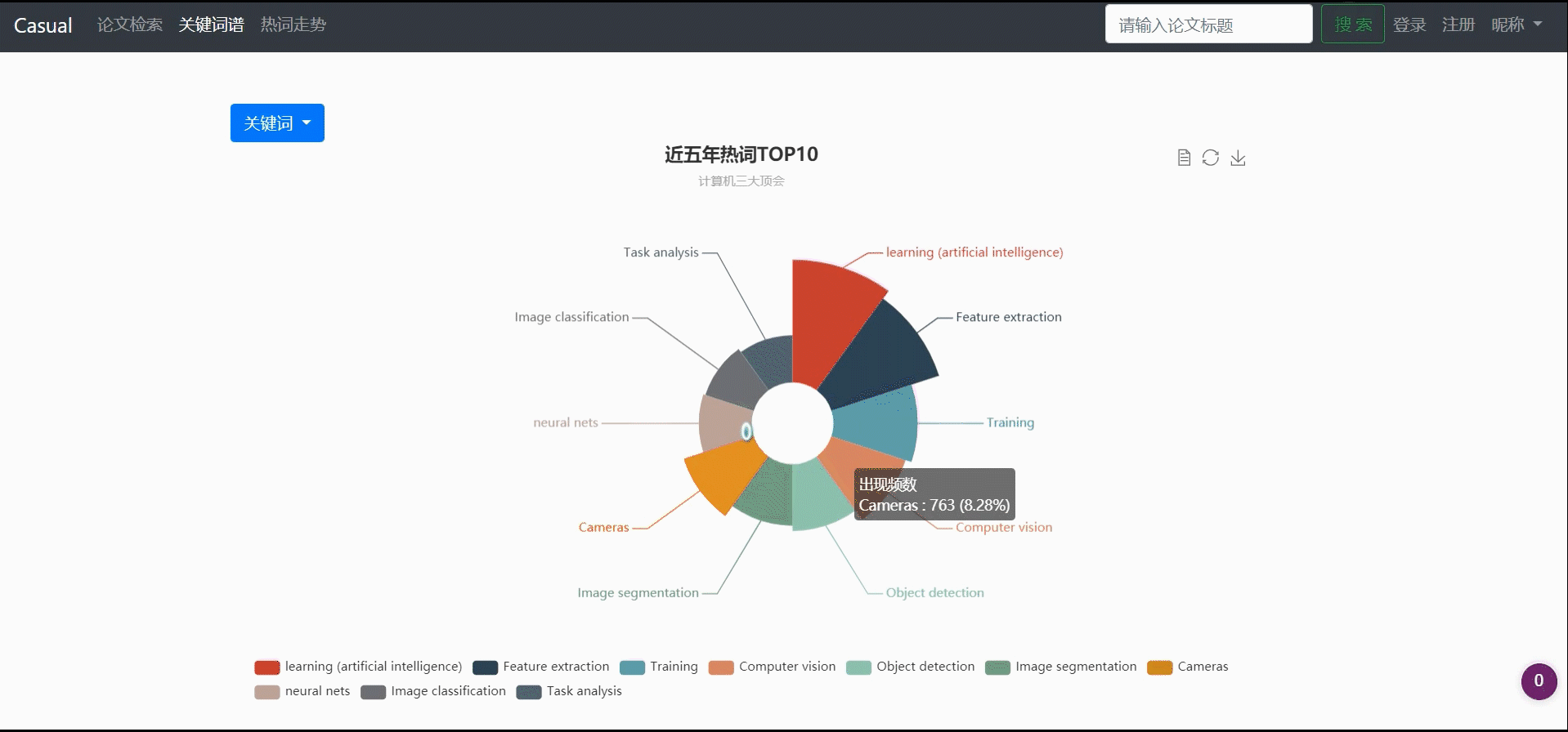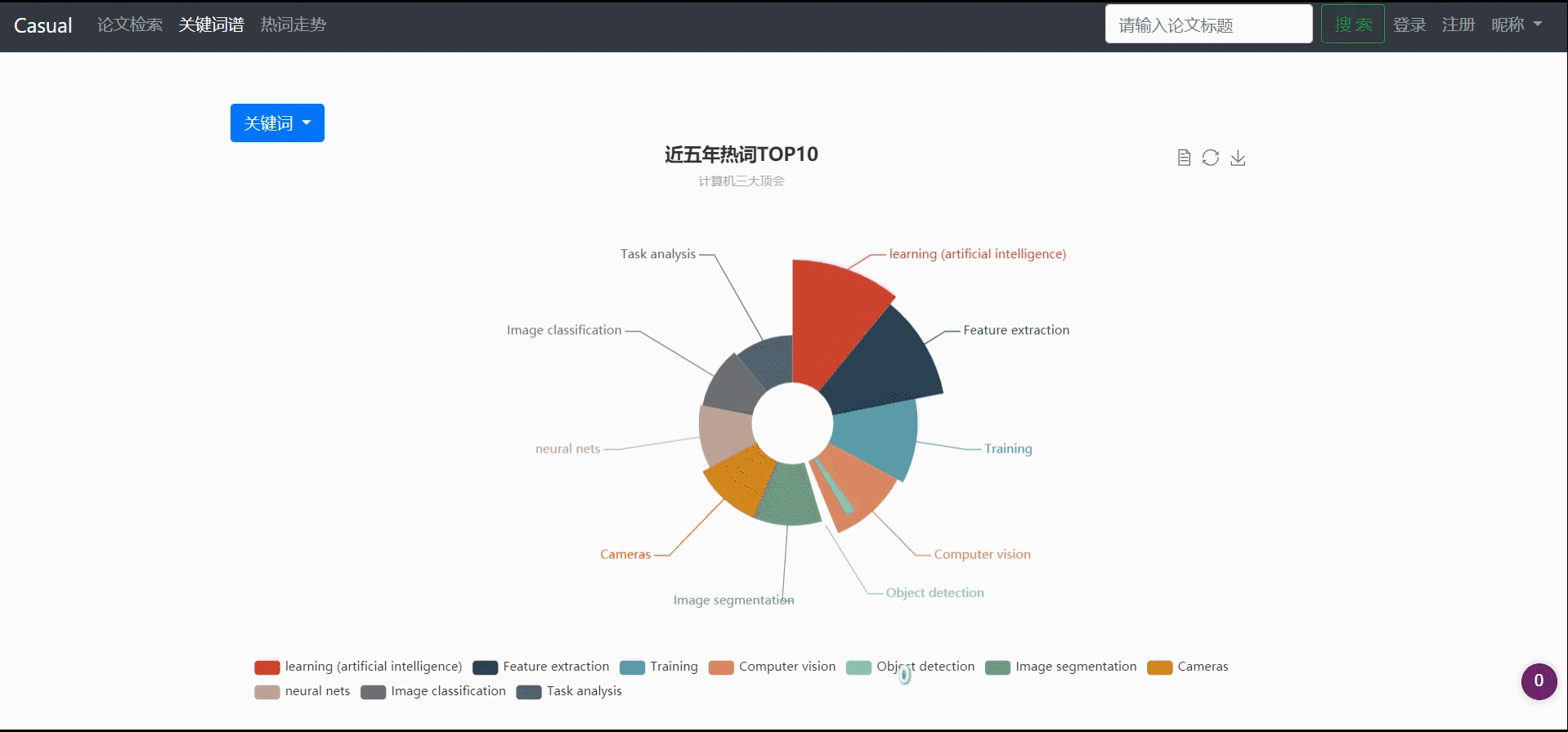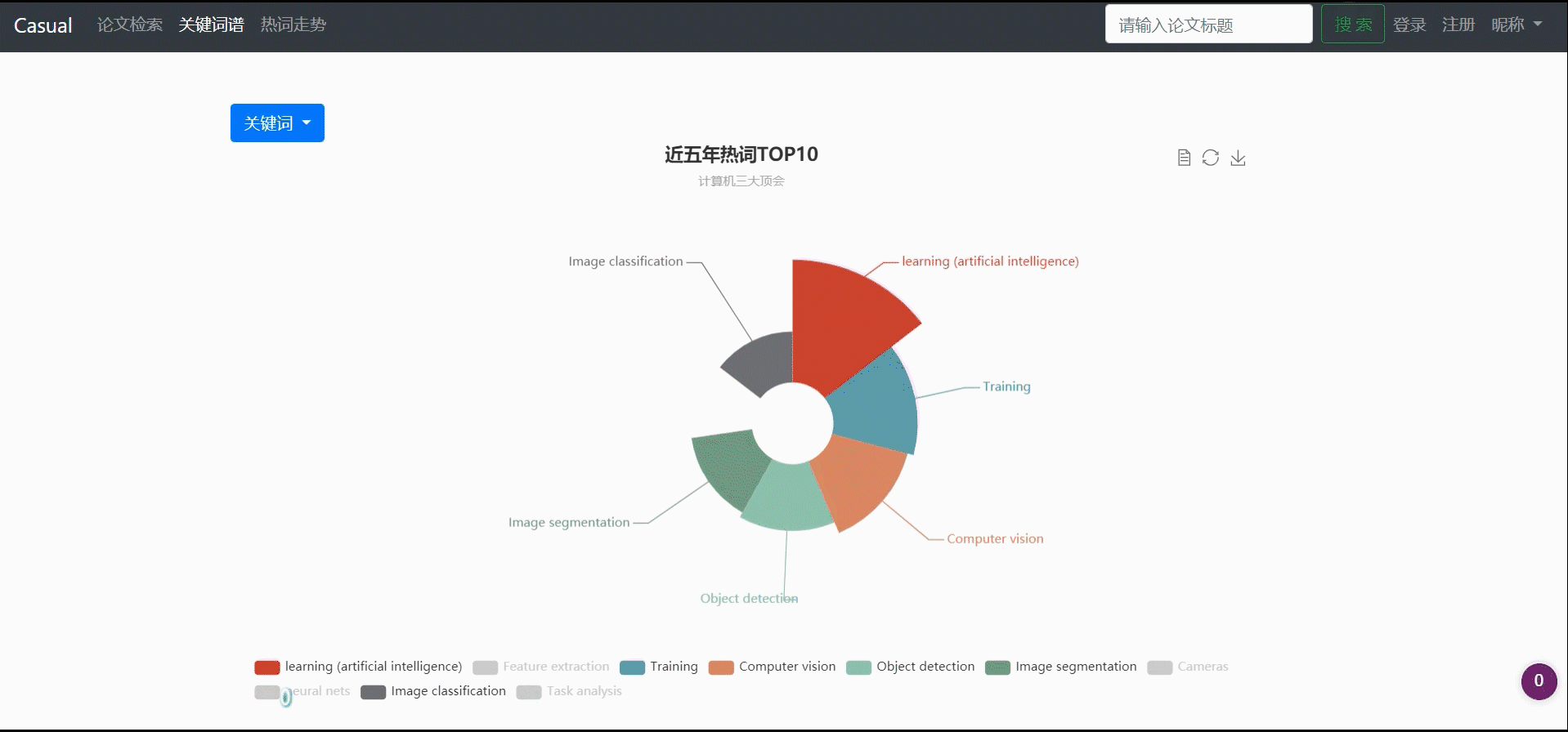
形成关键词top10图谱
-
根据显示的关键词,点击可以查看相关的论文列表

-
热词热度走势对比

五、结对讨论过程
问题与解决:
- 问题:设计论文列表显示时,由于引入了4.4版本的Bootstrap组件,导致导航栏及搜索表单等组件排版消失。
解决:起初设计的导航栏及搜索表单引用的是3.2版本的Bootstrap组件,尝试整体更换为4.x版本后解决了版本冲突问题。 - 问题:对于前端html技术中的表单form属性不熟悉。导致在论文检索页进行模糊查询设计时,无法将输入框内的内容通过表单提交到后端进行数据库查询。
解决:首页的输入框能进行正常搜索,仔细对比后发现<input>标签内没有提供相应的name属性,误以为传到后端的是id属性,添加name属性及相应值后成功进行数据的传递。 - 问题:设计论文列表的复选框批量勾选删除时,前端传勾选论文的pid装进Array传给后端,后端无法接收到Srting[ ]。
解决:在前端勾选传参时,构造的是数组,后端需要将Array转为List<String>,但控制器类里的删除方法传递的是int类型的id,上网搜索后使用List<Integer> pidList = ps.stream().map(Integer::parseInt).collect(Collectors.toList());将其进一步转换为List<Integer>。将删除接口原本传递的参数@RequestBody String[]改为HttptServletRequest类进行客户端对服务器的请求。同时,debug时在前端添加console语句显示已勾选的论文id,发现使用pid[i] = cks[i].value拼接数组后,显示的第一个数组元素为null。将其改为pids.push(cks[i].value);后获取到正确的数组内容。 - 问题:(1)前端分页时逻辑混乱,无法合理的显示当前页数的前后几个页数,当页数过多时,显示省略号。(2)当点击某页数的按钮时,无法正确跳转到正确的url,以显示最近一次查询道德结果(会刷新成查询全部论文的当前页内容)。
解决:(1)上网查询别人写过的分页fragment,进行参考,将其逻辑运用到自己的html中。(2)需要分页的页面中引入分页的fragment文件时,传入url等一系列参数:<div th:replace="page1 :: page_pager(${page.current}, 0, ${page.pages},10,5,@{'/paper/search/'})"></div>。在fragment页面中,使用传入的url和获取到的url的现有参数及其值,进行url跳转的拼接:th:href="@{${url}+${i}(title=${param.title},keyword=${param.keyword},pid=${param.pid},sort=${param.sotr})} - 问题:ajax获取接口的数据传给前端进行图表的显示时,json的解析出现问题,无法获取到正确的数据放入图表中,导致图标无法显示。
解决:js加上<script th:inline="javascript">。先是将数据写死来测试是否为图表本身的问题,发现图表无问题。之后将ajax获取到的数据console.log到前端显示进行排错,发现数据格式不对,之后再js中一步步进行相应的解析测试之后,成功把值传入图表。 - 问题:在获取top10关键词图谱的页面上,设置一个下拉列表,点击列表项(某个top10的关键词)时,跳转到相应的论文列表。此处需要在页面固定的位置用js动态的加载下拉列表,需要获取存放下拉列表项的div,但是无法获取到。且获取到之后,列表项的href出错,导致列表项无法显示。
解决:应该把获取dom节点的代码放到body外面:oDiv = document.getElementById('dm');。之后通过basePath = '[[${ #httpServletRequest.getScheme() + "://" + #httpServletRequest.getServerName() + ":" + #httpServletRequest.getServerPort() + #httpServletRequest.getContextPath()}]]';获取到项目根url,之后再拼接url(将keyword放入url参数)访问接口,进行相应的跳转。 - 问题:前端传递要删除的id的list给后端进行批量删除时,后端接收不到list数据。
解决:后端通过HttpServletRequest得到id的list存入String[]中,之后转化为List<String>,再转化为List<Integer>
讨论过程:
结对讨论过程描述,即刚开始拿到题目后,和队友怎么讨论,解决问题和查找资料的过程,并提供两人结对讨论的截图。(讨论过程描述不笼统,提供结对讨论截图,未提供结对讨论截图该项扣5分。)
-
拿到题目要求后,首先一起熟悉了一下git的基本使用,并进行psp表格最初判断。之后讨论确定了前后端的分配以及采用的技术实现,后端使用SpringBoot,前端使用原生html引用Bootstrap框架,使用Thymeleaf模板引擎进行前后端数据交互。界面的设计大多数采用了第一次作业的原型设计简版。
-
讨论数据库表的设计:根据所要求的功能进行考虑,主要是为了方便不同年份、会议的关键词的统计、分析,并且考虑到论文存在删除,所以把每篇论文的每个关键词都单独存一个记录。
-
前后端开发差不多完成之后,进行结合,开发期间利用接口文档展示接口。之后后端给出接口,前端取后端传来的数据,并进行相应的显示。此处出了较多的问题,因为刚开始没有商量好一些参数与规范,并且页面的显示出了一些问题,之后便在同地一起编程,后端修改一些接口以方便前端进行接收。
-
截图
-
-
-
六、设计实现过程
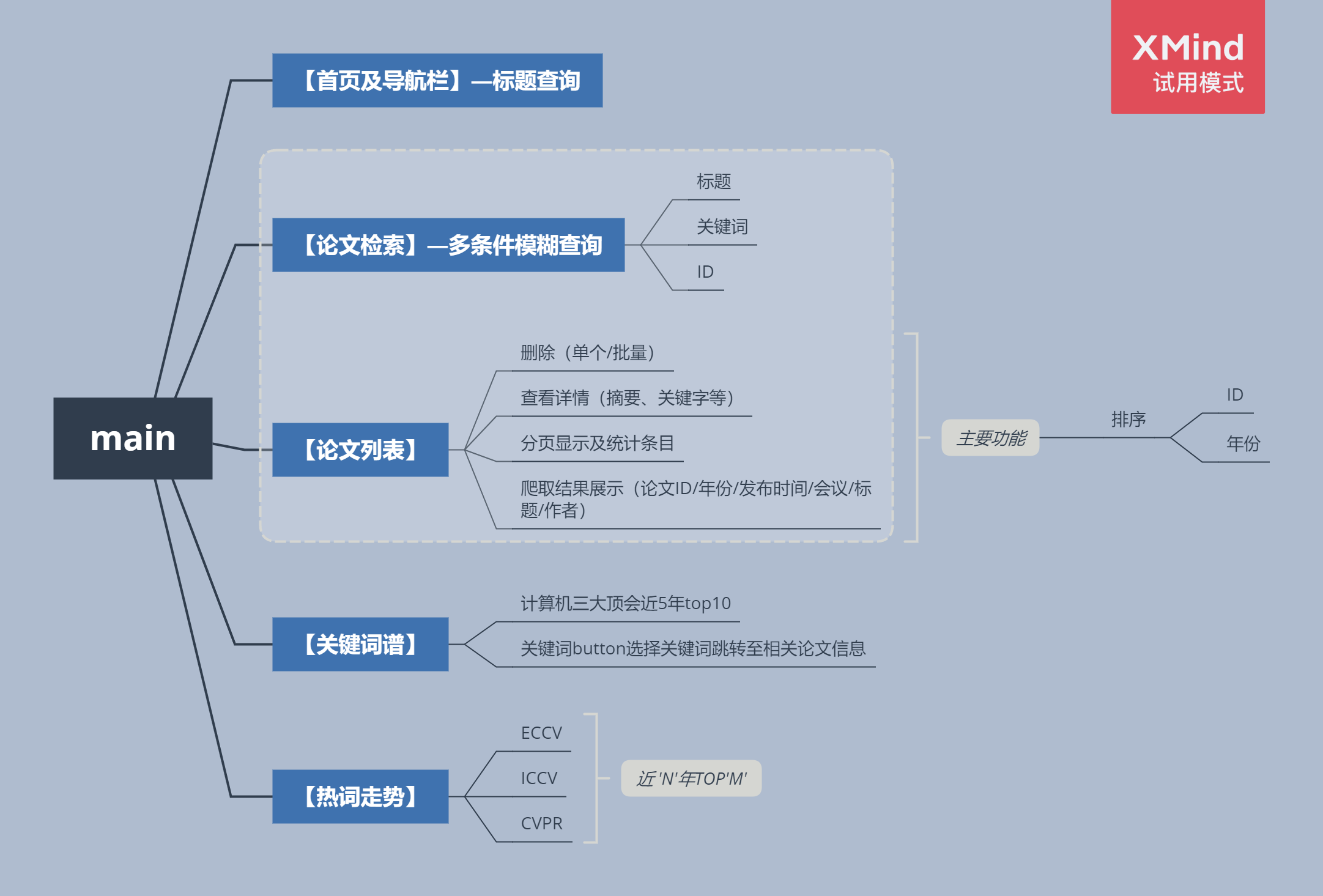
设计合理,实现过程描述不笼统;提供功能结构图,未提供功能结构图该项扣5分;
设计实现描述
-
前端采用原生html结合Bootstrap 4.x版本进行设计。首页的搜索使用表单进行提交,查询结果的论文列表采用表格形式将查询到的每一条数据插入表格中的一行,使用Thymeleaf的标签动态引入后端控制器中的各个元素。关于对论文列表子项进行删除的操作,使用ajax向服务器发送删除请求,服务器返回状态码以确认操作的执行。关于关键词图谱和热词走势的动图呈现,主要是采用了Echarts的环状图和折线图。而数据的动态传递则使用了js以及ajax进行获取。
- 分页页面:单独建一个html来存放分页选项组的fragment。需要分页的页面去包含此页面,并传入一些参数,例如:与最近一次查询相关的url,之后便可以动态进行url的拼接,结合后端的接口地址进行相应的页面跳转。在次fragment中进行一些逻辑的判断,例如只让分页显示指定个数的页数,其他的部分用省略号替代、当页数为第一页时,上一页失效。
- 论文列表显示页面:通过循环,逐个显示论文信息。每行论文信息都有复选框、删除按钮、查看按钮,都会传递论文id给后端进行相应操作。批量删除时,通过dom得到全选框的状态,赋值给所有复选框,之后点击删除,遍历所有复选框,判断状态是否为选中,若是,则存入id数组,最后将id数组传给后端进行批量操作。查看论文的详细信息时,使用了bootstrap的模态框,点击查看按钮时,ajax调用后端接口并传递id,回调函数内进行论文详细数据在页面的设置。
-
后端采用spribgboot:使用springboot搭建项目,整合mybatis进行数据库操作,数据库使用mysql。
- 数据库表设计:paper表存储论文的除了关键词的所有要求与需要的字段信息,观察到作者和发布时间在有的论文中不存在,便可置空。keyword表存储所有关键词信息,包括关键词内容,对应的论文id,论文的年份、会议。在进行关键词统计时,使用
count(*)与group by content来计算关键词频数。缺点是数据库数据较大、有较多冗余,进行查询统计时比较耗时;优点查询逻辑较清晰、方便理解。 - 将论文存入数据库:使用jackson进行解析。先将每种会议的论文放在不同的文件夹下,之后分别读取每个文件夹下的所有论文存入一个文件的list,之后逐个解析。因为论文的json格式有两种,所以分别写了两个解析函数。
- 分页多条件联合查询:后端接收页码、每页论文显示个数、查询条件等,利用mybatis-plus分页插件进行分页(利用页码、每页论文显示个数),将拆线呢条件放入map中,sql操作时,判断查询条件是否存在,若不存在,则不放入where子句中。
- 形成关键词top10图谱:先获取当前年份,之后计算出所需的最小年份(5年内,则最小年份为2017),之后利用
select content, count(*) as total from keyword where year > years group by content order by total desc limit topNum统计所有论文中出现次数最多的10个关键词。 - 多年间、不同顶会的热词呈现热度走势对比:先统计某会议某年多少年间top几的热词,得到一个关键词的list,之后遍历这几个年份查询每年这几个关键词的频数,存入map,以年份为key。
- 数据库表设计:paper表存储论文的除了关键词的所有要求与需要的字段信息,观察到作者和发布时间在有的论文中不存在,便可置空。keyword表存储所有关键词信息,包括关键词内容,对应的论文id,论文的年份、会议。在进行关键词统计时,使用
功能结构图
七、代码说明
- 热词热度走势:因为后端数据接口格式与图表需要的数据格式不一致,此处利用二维数组读取map(key为年份)中关于每年的每个top关键词的频数,并将关键词、关键词对应的每年的频数存入数组,之后再放到图表相应位置显示。
<script th:inline="javascript">
var chartDom2 = document.getElementById('fre');
var myChart2 = echarts.init(chartDom2);
var json;
var option2;
var keywords = new Array();
var ktotal = new Array();
var jsontotal = new Array();
var years = [];
var mySeries = [];
option2 = {
title: {
text: ''
},
tooltip: {
trigger: 'axis'
},
legend: {
data: keywords[years[0]],
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
toolbox: {
feature: {
saveAsImage: {}
}
},
xAxis: {
type: 'category',
boundaryGap: false,
data: years,
},
yAxis: {
type: 'value',
},
series: mySeries,
};
$.ajax({
url: encodeURI("/keyword/trend/ECCV"),
type: "get",
cache: false,
async: false,
dataType: 'JSON',
data: {
"years": 10,
"topNum": 15
},
success: function (result) {
$.each(result.map, function (i, item) {
years.push(i);
keywords[i] = [];
ktotal[i] = [];
for (let j = 0; j < 10; j++) {
keywords[i].push(item[j].content);
ktotal[i].push(item[j].total);
}
});
for (let i = 0; i < 10; i++) {
jsontotal[i] = [];
for (let j = 0; j < years.length; j++) {
jsontotal[i].push(ktotal[years[j]][i])
}
}
for (let i = 0; i < 10; i++) {
mySeries.push({
name: keywords[years[0]][i],
type: 'line',
stack: '总量',
data: jsontotal[i],
});
}
}
})
option2 && myChart2.setOption(option2);
</script>
- 关键词下拉列表: ajax访问接口后得到top10的关键词内容,现存入一个全局数组。之后在
</body>标签之写js,获取下拉列表所在的div,逐个将每个下拉列表项(<a>)放入div,并且修改<a>的样式,设置<a>的href为相关接口url
<div class="dropdown-menu" id="dm">
</div>
<script>
//根路径
basePath = '[[${ #httpServletRequest.getScheme() + "://" + #httpServletRequest.getServerName() + ":" + #httpServletRequest.getServerPort() + #httpServletRequest.getContextPath()}]]';
oDiv = document.getElementById('dm');
for (let i = 0; i < 10; i++) {
oA = document.createElement('a'); //创建a标签
aaa = basePath + '/paper/list/1/' + '?keyword=' + keyword[i];
oA.href = aaa; //增加a标签的href属性
oA.innerHTML = keyword[i]; //给a标签添加内容
oA.className = "dropdown-item";
oDiv.appendChild(oA); //将a标签添加到div里面
}
</script>
- 论文载入数据库:得到要解析的文件夹里的所有json文件,之后遍历文件list,逐个取出论文需要的数据,存入论文对象,再利用mybatis存入数据库表;同时把论文的关键词遍历取出存入对象,再添入需要的数据,存入数据库表。最后返回文件夹的论文篇数,判断是否全部存入成功。
//ECCV
public int loadECCVpapers(int index){
ArrayList<File> fileList = this.loadFiles(index);
//实例一个ObjectMapper
ObjectMapper mapper = new ObjectMapper();
try{
for (File f : fileList) {
JsonNode rootNode = mapper.readValue(f, JsonNode.class);
//会议和年份
String meeting_year = rootNode.path("会议和年份").asText();
String[] my = meeting_year.split(" ");
//其他
Paper paper = Paper.builder()
.abstractContent(rootNode.path("摘要").asText())
.publicDate(rootNode.path("发布时间").asText())
.title(rootNode.path("论文名称").asText())
.link(rootNode.path("原文链接").asText())
.meeting(my[0]) //meeting[index]
.year(my[1])
.build();
//将此论文存入【paper】
if( paperService.insertPaper(paper) > 0 ){
//System.out.println("------插入论文成功【" + paper.getPid() + "】: " + paper);
}
//关键词
JsonNode keywords = rootNode.path("关键词");
if (keywords.isArray()) {
for (JsonNode kw : keywords) {
Keyword keyword = Keyword.builder()
.content(kw.toString().replace("\"",""))
.pid(paper.getPid())
.meeting(my[0])
.year(my[1])
.build();
//System.out.println(kw.toString().replace("\"",""));
//将关键词存入【keyword】
if(keywordService.insertPKeywords(keyword) > 0){
}
}
}
}
} catch (IOException e){
e.printStackTrace();
}
return fileList.size();
}
//CVPR_ICCV
public int loadCVPR_ICCVpapers(int index){
ArrayList<File> fileList = this.loadFiles(index);
//实例一个ObjectMapper
ObjectMapper mapper = new ObjectMapper();
try{
for(int i = 0; i < fileList.size(); i++){
//for (File f : fileList) {
StringBuffer authorsName = new StringBuffer("");
JsonNode rootNode = mapper.readValue(fileList.get(i), JsonNode.class);
if(rootNode.path("abstract").asText().isEmpty() || rootNode.path("abstract").asText().equals("")){
continue;
}
//作者
JsonNode authors = rootNode.path("authors");
//System.out.println("【作者名字】:");
if (authors.isArray()) {
for (JsonNode at : authors) {
//System.out.println(at.path("name").asText());
authorsName.append(at.path("name").asText() + " / ");
}
}
//其他
Paper paper = Paper.builder()
.abstractContent(rootNode.path("abstract").asText())
.meeting(meeting[index])
.year(rootNode.path("publicationYear").asText())
.publicDate(rootNode.path("publicationDate").asText())
.title(rootNode.path("title").asText())
.link(rootNode.path("doiLink").asText())
.authors(authorsName.toString())
.build();
//将此论文存入【paper】
if( paperService.insertPaper(paper) > 0 ){
//System.out.println("------插入论文成功【" + paper.getPid() + "】: " + paper);
}
//关键词
JsonNode keywords = rootNode.path("keywords");
if (keywords.isArray()) {
for (JsonNode kw : keywords) {
JsonNode kwd = kw.path("kwd");
if (kwd.isArray()) {
for (JsonNode keyword : kwd) {
Keyword k = Keyword.builder()
.content(keyword.toString().replace("\"",""))
.pid(paper.getPid())
.meeting(paper.getMeeting())
.year(paper.getYear())
.build();
//将关键词存入【keyword】
if(keywordService.insertPKeywords(k) > 0){
//System.out.println("~~~~~插入关键词成功【" + paper.getPid() + "】: " + k);
}
}
}
}
}
}
} catch (IOException e){
e.printStackTrace();
}
return fileList.size();
}
八、结对心路历程及队友评价
结对心路历程&收获
-
291800139:这一次的结对编程真的给了我很多不同面的感受......因为本身自己学业任务比较繁重,加上此次编程的难度,让我有点措手不及。我本身实力不足且拉慢了整个队伍的进度,对队友觉得非常抱歉。所以想着以后一定要快速解决掉自己手上的事情,不能因为个人原因拖累队友。后来被队友带着通宵debug,又让我有了前所未有的体验。(虽然其实都是她在改bug。。。最大的收获是,很庆幸队友人很好并且有一定的开发经验,但是我太菜了带不动)这次结对编程让我对前后端混合开发中关于前后端数据交互有了浅显的认识;其次,看队友打代码和debug让我有了新的学习动力。
-
221801431: 意识到自己对前后端整合过程还是不太熟练,特别是在前端接收数据之后在回调显示信息进行处理这一块。关于数据库的设计也纠结了挺久,最开始打算是在存入的时候就进行以年份、会议为单位的频数统计,后来意识到如果论文出现增删改会难以统一频数,之后就换了别的设计,直接在sql查询的时候利用count(*)进行统计,就是响应时间比较久,之后可能还会进行优化,还需要加强自己对数据库知识的理解,进行更深入的学习。刚开始解析json时,看到json文件一大串就有点抵触,好在之后静下心来,将两种论文json都解析成功,就是之后存入数据库的时候网络断了几次,有点搞心态。收获:意识到自己在一些方面的不足,之后会积极的去学习。
队友评价
-
291800139对221801431的评价:总体来说,我从队友身上看到了高效和毅力两个词。前期她很快速地开始编码,也很快就写完了大部分的功能并整理了接口。印象最深的是29号晚上我们进行前后端整合时,她在我的宿舍改bug,一个接一个......虽然那时候夜已经很深了,我非常困倦,但是我的队友没有放弃(她的行为有感染到我。同时,阳台外面天一点一点亮起来,手上的工作才暂告一段落。后来前端页面大改并且大部分技术工作都是由队友完成的,让我觉得她非常厉害。
-
221801431对 291800139的评价:虽然没什么开发的经验,但是在课业繁忙之时积极学习新知识,来配合我一起开发。虽然遇到了一些很蠢很呆的bug,饶了一些圈圈,但是两个人一起深夜debug,脖子不酸了,腰不痛了,感觉都不孤单惹呢!最后还是觉得,多多锻炼很重要,毕竟深夜debug太伤身体了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号