软件工程实践寒假作业2/2
寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业2/2 |
| 这个作业的目标 | 1. 重读《构建之法》 2. 学习使用GitHub 3. 实现词频统计程序 |
| 参考文献 | 《构建之法》、CSDN |
part1. 阅读《构建之法》
问题
-
章节4.5《结对编程》篇首提到"极限编程(Extreme Pro-gramming)"的思想体现在把一些卓有成效的开发方法用到极致,由此引入"结对编程"的说明。在此,"极限编程"只是一个引子,书上并没有过多对于该概念的阐述。二者之间有什么区别和联系?查阅资料得知"极限编程"的基础和价值是:任何一个软件项目都可以从四个方面入手进行改善:加强交流;从简单坐骑;寻求反馈;用于实事求是。而结对编程是极限编程的一种实践。
-
章节5.3《开发流程》中提到了一些软件开发的模式和模型。其中,我对瀑布模型印象深刻,相邻步骤的回溯,解决上一阶段未能解决的问题。,这确实是一个很重要的方式。但是这里我想提出疑问,不相邻的步骤之间有时也存在相关性,分局部-小整体-大整体进行分析是否更合适?
-
章节6.5《敏捷的故事》中以问答的形式解决了大多数人对敏捷开发的疑惑。文中提到大多数被测试、被研究的新东西都很有效果,这是Haqthoren效应。熟练书中也称敏捷不是万能的,但还是大篇幅阐述了"敏捷开发"的好处。上网搜索后发现曾经A公司多个项目都采用瀑布式开发,几乎无一例外的出现了延期。后来公司有一个项目采用敏捷的方式,虽然效果看起来不错但仍然受到很多人的反对。当谈及敏捷是否比瀑布式开发优秀的争议,在需求明确且项目人员较多时,敏捷似乎并不是最好的选择。查阅资料后发现,如果我们目前在开发一个创新项目的话,由于需求是不可估的,敏捷开发的价值在此会最大程度的体现出来。但如果是传统软件开发,需求清晰准确可估计,则可以采用瀑布模型。(见解如果有误还望老师和助教提出。
-
章节8.4《竞争性需求分析的框架》中谈到同学们不能穿新鞋,走老路。学习了很多新技术、新的开发模式、新的团队管理方法,却做一个毫无新意、没人使用、演示完就扔掉的东西(例如:虚拟的学籍管理系统,图书馆里系统......)。,这一点应该是普遍人都想问的。而下文引出了NABCD模型,这里的对象是面向用户的,用户给定需求后,由开发人员进行创意的实现。灵感、创新此类对于每个人来说都是不可定量和定性的,在此想问老师和助教们是否能多多做一些引导。
-
章节11.5.2《每日构建(Daily Build)》中举了阿超大学篮球课的例子表明了每日构建的重要性,但此处并未谈及专业知识上的好处,查阅资料后得到:(1)针对"开发的混乱",对于每日构建的流程,开发人负责提交代码到代码库,无需逐个给测试人员提供编译后的二进制文件。(2)针对"测试的混乱",在开发阶段,由于测试拿到的程序是自动编译的因此保证了测试人员拿到了统一的运行程序;在测试阶段,每一个开发人员修复后都将新的代码提交到代码库,那么测试人员也将拿到新的二进制程序。(3)针对"集成的混乱",每日构建会产生安装包或IOS镜像,这个集成的过程是持续进行的。如果出现问题会在项目进行的任意时刻暴露出来,不至于拖到项目后期而难以解决。
小故事
高级语言名称的由来
-
Python中文译为蟒; 蚺蛇;是荷兰人Guido van Rossum于上世纪80年代末设计的语言,他起名的初衷是——短的、独特的、有神秘色彩的。因其是英国著名戏剧团体Monty Python的粉丝,所以以Python命名这门语言。
(os:大一的时候看计算机的同学朋友圈用Python爬虫po了一张图片,一直不是很理解,蟒蛇和爬虫是什么,后来上网搜才知道,与生物意义上的蛇和虫一点关系都没有😓) -
Java是印度尼西亚爪哇岛的英文名称,该地盛产咖啡。语言的命名有一种比较可信的说法——Sun公司副总裁James Gosling喜爱咖啡。而Java中的库也有与其相关的类命,如JavaBeans(咖啡豆)。且Java的LOGO也是一杯冒着热气的咖啡。

(os:智能机初普及的时候在山寨iPhone4上曾经见过Java咖啡的logo,大概是小学四五年级的时候,那时候点开这个软件也根本啥都看不懂...没想到现在在使用它😓(这么说来那支山寨机是安卓系统。?))
part2. WordCount编程
2.1 GitHub项目地址
2.2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 300 |
| • Design Spec | • 生成设计文档 | 30 | 20 |
| • Design Review | • 设计复审 | 30 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| • Design | • 具体设计 | 480 | 240 |
| • Coding | • 具体编码 | 480 | 780 |
| • Code Review | • 代码复审 | 60 | 180 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 30 | 50 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 730 | 1810 |
2.3 解题思路
- 统计字符数:用字符流读取文件后将其转为字符串,通过length()方法获得总字符数。
- 统计单词总数:将所有字母化为小写,过滤非字母和数字的字符。分割文本后预判单词,同时,借助HashMap中的map记录词频。
- 统计有效行数:借助String类的CharAt()方法进行索引,该行非空且有换行则为有效行。
- 统计各单词的出现次数:第二点已经提及,获取字符并映射为关键-值插入到HashMap,再将HashMap中的Entry插入到线性表List里。通过比较器排序词频,输出的话,这里我使用简单的if条件以及for循环来得到前十条。
2.4 代码规范制定
2.5 设计与实现过程
其实上述的解题思路在一开始并不是这么想的,我写的是最终版。在这里给出具体的设计和实现过程。

-
关于文件的读取和写入
主要写于WordCount主类中
//读取文件 public static String readFile(File filePath) //key.使用BufferedReader类的read()方法单字节读取并添加到result字符串 while ((ch = br.read()) != -1) { result.append((char)ch); } //写入文件 public static void writeFile(int characters, int words, int lines,File filePath, List<HashMap.Entry<String, Integer>> wList) //该处传入的参数依次为字符数,单词数,行数,输出文件的路径,排序后的list表 //key.使用BufferedWriter类的write()方法写文件 bw.write(text);
以下功能封装在Lib类中
-
关于单词的判定和数量统计
//判断是否为字母一一匹配并 public static boolean isLetter(CharSequence charSequence) //统计单词总数及各词频,先在replaceAll()方法中使用正则表达式去符号置为纯文本 public int wordCount(String data) //key.分割文本筛选单词 StringTokenizer words = new StringTokenizer(lowerData); try { while (words.hasMoreTokens()) { String word = words.nextToken(); //判断是否为单词 if (word.length() >= 4 && isLetter(word.subSequence(0, 4))) { sum++; //统计词频 if (wordsMap.containsKey(word)) { count = wordsMap.get(word); wordsMap.put(word, ++count);//单词已存在则个数+1 } else { wordsMap.put(word, 1);//单词只出现1次 } } } } -
关于行数的统计
public int lineCount(String data) //key.这个方法的实现比较简单,借助了flag来标记是否为空字符或换行符 if (data.charAt(i) > ' ') {//字符索引至i处 flag = true; } else if (data.charAt(i) == '\n') { if (flag) { lines++; flag = false;//置空 } -
关于词频的排序
public List<HashMap.Entry<String, Integer>> wordSort() //key.先将map中的元素放入list再重写比较器类的caompare()方法并通过sort()实现最终的排序 Comparator<Map.Entry<String, Integer>> cmp = new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if (o1.getValue().equals(o2.getValue())) { return o1.getKey().compareTo(o2.getKey()); //值相同时按键返回字典序 } return o2.getValue() - o1.getValue(); //字典序靠前排在前面 } };
2.6 性能改进
-
文件的读写使用缓冲流,更加高效。读文件后将读到的字符载入StringBuilder内,虽然它不是线程安全的,但是性能更高一些。
StringBuilder result = new StringBuilder(); -
使用HashMap<String, Integer>键值对结构存储单词及对应个数,便于通过比较器比大小后直接进行排序。
List<HashMap.Entry<String, Integer>> wordList = new ArrayList<>();
2.7 单元测试
此处只对Lib类下进行测试方法的编写
- 测试统计行数
@Test
public void testLineCount() {
Lib lib = new Lib();
String str = "welcome back to New York\nBlank Space\rStyle\r\n";
String testStr = "";
for (int i = 0; i < 2000; i++) {
testStr += str;
}
Assert.assertEquals(lib.lineCount(testStr), 4000);
}
-
测试是否为字母
@Test public void testIsLetter() { Lib lib = new Lib(); Assert.assertEquals(lib.isLetter("3a:sd"), false); Assert.assertEquals(lib.isLetter("w123."), false); Assert.assertEquals(lib.isLetter("`;'[`"), false); Assert.assertEquals(lib.isLetter("ADFDS"), false); Assert.assertEquals(lib.isLetter("asdawe"), true); } -
测试统计单词数
@Test public void testWordCount() { Lib lib = new Lib(); String str = ",ajr-h/r/rw123/rhello/nworld/r"; String testStr = ""; for (int i = 0; i < 2000; i++) { testStr += str; } Assert.assertEquals(lib.wordCount(testStr), 4000); } -
测试词频排序
@Test public void testWordSort() { Lib lib = new Lib(); StringBuilder str = new StringBuilder(""); String expStr = "ahead: 3\nblack: 3\narea: 1\npink: 1\n"; Lib.wordsMap.put("black",3); Lib.wordsMap.put("ahead",3); Lib.wordsMap.put("pink",1); Lib.wordsMap.put("area",1); List<HashMap.Entry<String, Integer>> sortedList = lib.wordSort(); for (Map.Entry<String, Integer> entry: sortedList) { str.append(entry.getKey()).append(": ").append(entry.getValue()).append("\n"); } Assert.assertEquals(expStr, str.toString()); } -
正确率及覆盖率

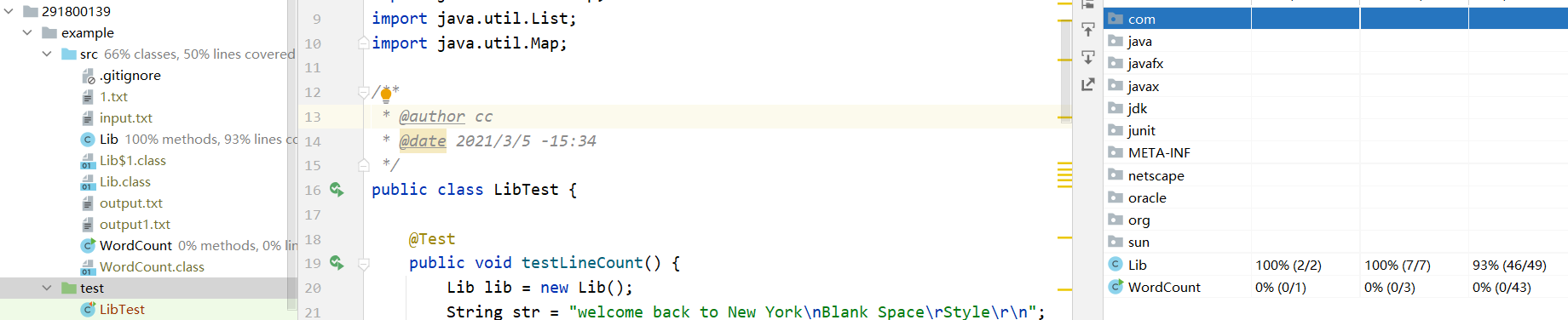
2.8 异常处理说明
- 在文件的读取和写入处定义了读写异常,在单词计数处也定义了一个异常。
try {
} catch (Exception e) {
System.out.println("Failed to read! <error> :" + e.getMessage());
}
try {
} catch (Exception e) {
System.out.println("Failed to write! <error> :" + e.getMessage());
}
try {
} catch (Exception e) {
System.out.println("Failed to count! <error> :" + e.getMessage());
}
因其比较相似,便不作过多说明。
- 值得一提的是,在编码阶段,曾经抛出过多次"写"异常。

因为错误信息的提示是字符串越界,但是考虑到HashMap自动扩容,很快排除掉这个原因。后来发现是在write方法里传参的问题。
- 以及后面也出现了一次"数"异常。

错误提示非常相似,通过调试和测试发现是单词的判断出现问题,修正后得到正确结果。
2.9 心路历程与收获
-
作业刚发布后,由于要求和内容的繁琐而心生畏惧,觉得无从下手所以一直没有开始。
-
准备工作做了很多,先大概复习了一下Java。在学习Git和GitHub的使用时走了一些弯路,且作业的要求有点看不懂,摸索了很久才开始项目的搭建。
-
关于文件的读取利用命令行给主函数传参之前接触得少,这一次尝试后稍稍会使用了一点。字母数字等字符的判断,一开始设想了很多种情况,写起来感觉会很复杂,后来在cdsn上搜索,才使用正则表达式。以前没有自己写过异常,这一次异常都被catch到之后才发现写异常的重要性。(虽然找bug和解决bug依然很困难......简单学习了JUnit的使用,但是要想测试得周全还是需要多练多看。
-
如果早一点开始的话,应该能再多学多改进。
ps. PSP表格的使用其实有点难,花在估计时间和统计时间上的时间有时也是难以预料的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号