scrapy的入门
0,scapy的安装
pip install scrapy
注意安装的过程可能会有一些错误,需要尝试多次解决
1,创建工程项目
scrapy startproject demo
demo是项目的名称
2,创建爬虫
cd demo
项目根目录下执行如下命令
scrapy genspider bqb www.itcast.com
bqb表示爬虫的名称
www.itcast.com表示爬去的站点
3,项目目录结构
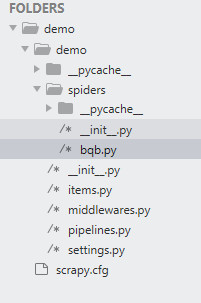
4,实例代码
在bqb.py中编写代码如下
'''---------------------------------
# @Date: 2023-10-25 16:39:05
# @Author: Devin
# @Last Modified: 2023-11-24 17:33:46
------------------------------------'''
import scrapy
from demo.items import DemoItem
from scrapy.pipelines.images import ImagesPipeline
class Myspider(scrapy.Spider):
name='bqb'
# 2,检查域名
allowed_domains=["itcast.cn"]
# 1,修改起始url
start_urls=["https://www.itcast.cn/channel/teacher.shtml"]
# 3,实现爬去逻辑
def parse(self,response):
# 定义对于网站的相关操作
# 获取所有教师的节点
node_list=response.xpath("//div[@class='li_txt']")
# 遍历教师节点
for node in node_list:
temp={}
# xpath方法返回的是选择器对象列表
# temp["name"]=node.xpath("./h3/text()").extract_first() #防止空列表报错
temp["name"]=node.xpath("./h3/text()")[0].extract()
temp["title"]=node.xpath("./h4/text()")[0].extract()
temp["desc"]=node.xpath("./p/text()")[0].extract()
print(temp)
break
#yield temp
5,运行爬虫
scrapy crawl bqb --nolog
6,实例结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号