
数据结构与算法
数据结构与算法
关于算法的代码写了一些在:https://gitee.com/yuan_yi_xiang/data_structure_algorithm欢迎指正
基础的数据结构:
数组、链表、栈、队列
基础排序算法:
冒泡排序o(n²)、插入排序o(n²)、选择排序o(n²)
归并排序和快速排序都是分治思想,时间复杂度都为nlogn但快速排序的空间消耗较归并排序少
线性排序
如果是给大量数据进行排序,内存不够用的时候可以用
桶排序o(n):如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
但是要求划分的桶也是有序的,如果划分在一个桶内的数据较多无法进入内存,可以继续划分
计数排序:很像通排序,有大量的数据但是数据很多都是重复的,举个例子我们都经历过高考,高考查分数系统你还记得吗?我们查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有 50 万考生,如何通过成绩快速排序得出名次呢?考生的满分是 900 分,最小是 0 分,这个数据的范围很小,所以我们可以分成 901 个桶,对应分数从 0 分到 900 分。根据考生的成绩,我们将这 50 万考生划分到这 901 个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了 50 万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是 O(n)。
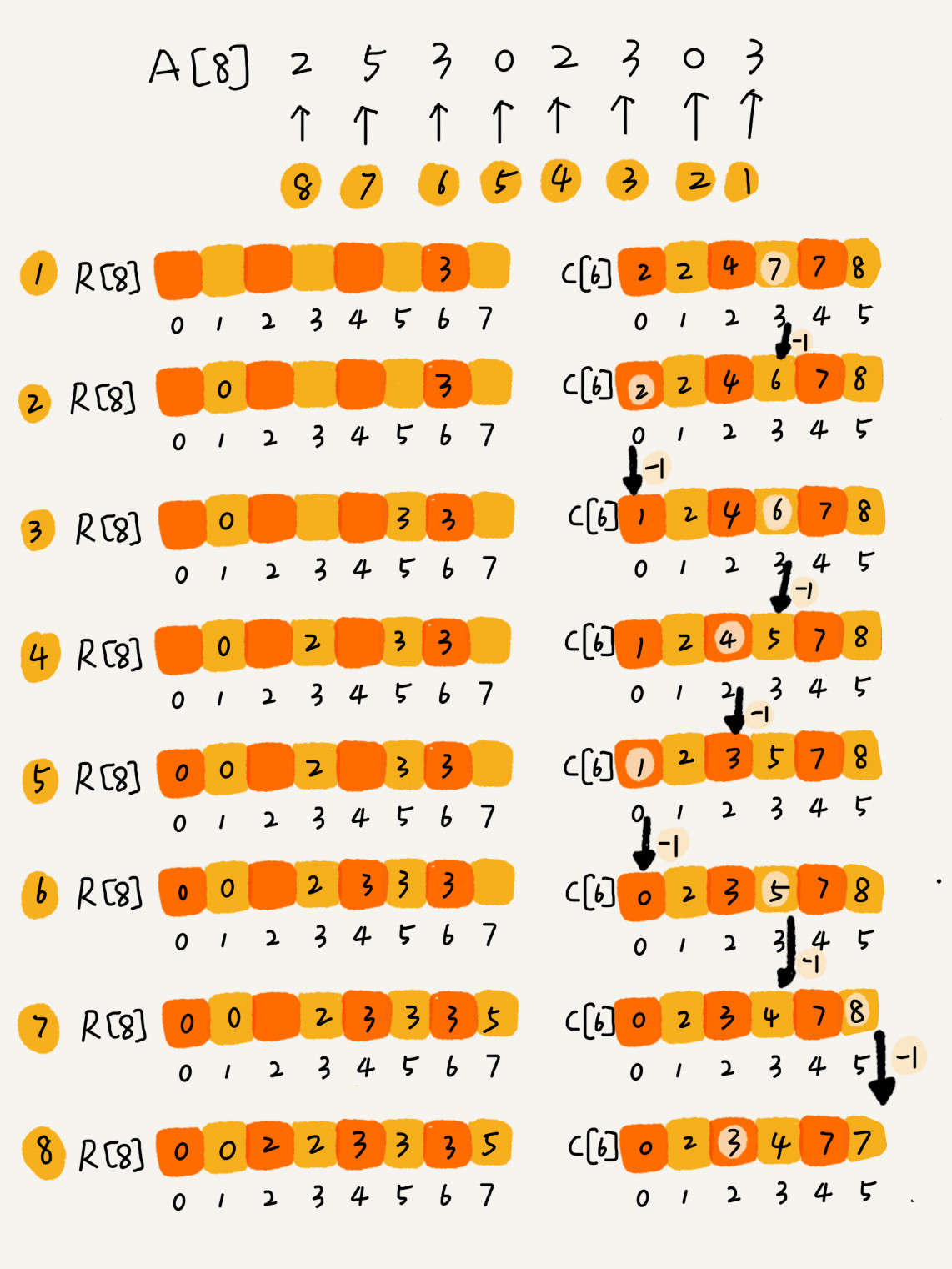
使用极客时间学习的引用。
将a数组中的找到最大的值,比如这里是5,就建立大小为6的数组保存0-5的个数,然后依次相加,就能得到对应小于等于这个数总共有几个数,就能得出数本身的下标。
基数排序:可以分割出每一位来比较大小,位之间有递进的关系,每一位的数据范围不是太大,每一位可以用线性排序算法来进行排序
排序优化
归并排序在最坏的情况下时间复杂度是nlogn而快速排序最坏情况下是n²,而快排使用较多,归并排序的空间消耗大并且快速排序达到最糟糕情况是因为分区点选的不合理,要使分区两边的数据数量差不多例如使用取中法根据数据数量,进行间隔取数比较取中间值。
在实现算法的时候我们可以进行结合,O(n²)在数据量较小的情况下会比O(nlogn)的时间消耗更小,只是变化趋势较大。可以先判断数量再判断使用的算法
二分查找
查找效率高,时间复杂度位o(logn),但是要求数据是有顺序的,数据要使用顺序表存储,其他的数据结构存储会导致访问的时间变慢,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用。数据量太小不适合,数据量太大会因为空间问题不适合
跳表
以空间换时间的思想,在单链表上构建多级索引提高了查找的效率,是一种动态的数据结构,支持快速的插入删除和查找操作,时间复杂度都是logn,可以通过改变索引的构建策略来平衡执行的效率和内存的消耗,redis中就是使用的跳表来实现的
散列表
基础:散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。解决散列冲突的方法:1、开放寻址法2、连表法
后面会持续更新,可以一起学习。评论欢迎指正

 浙公网安备 33010602011771号
浙公网安备 33010602011771号