gettimeofday、clockgettime 以及不同时钟源的影响
我们写程序的时候经常会使用计时函数,比如RPC中计算超时时间,日志中打印当前时间,性能profile中计算某个函数的执行时间等。在使用时间函数的时候,我们一般默认认为时间函数本身的性能是很高的,对主逻辑的影响可以忽略不计。虽然绝大部分情况下这个假设都没问题,但是了解更多细节能够增加我们对问题的把控力,利于系统的设计和问题的调查。
首先来比较gettimeofday/clock_gettime的性能。
程序代码见后
Glibc版本:
$rpm -qa|grep glibc-comm
glibc-common-2.5-81
内核版本:
$uname -a
2.6.32-220.23.2
$./a.out -help
[gettimeofday/clock_gettime] thread_number loop_count
$./a.out gettimeofday 1 100000000
gettimeofday(50035480681901) , times : 100000000
thread 1105828160 consume 4000225 us
单线程gettimeofday大概每次40ns
图1看出,gettimeofday走的是vsyscall[1](虚拟系统粗糙的描述就是不经过内核进程的切换就可以调用一段预定好的内核代码),没有线程切换的开销。
图1 gettimeofday 走vsyscall

图2 gettimeofday能将usr态cpu消耗压到100%

因为走vsyscall,没有线程切换,所以多线程运行性能跟单线程是类似的。
$./a.out gettimeofday 12 100000000
gettimeofday(51127820371298) , times : 100000000
thread 1201568064 consume 4111854 us
$./a.out clock_gettime 1 100000000
clock_gettime(50265567600696623) , times : 100000000
thread 1107867968 consume 10242448 us
单线程clock_gettime大概每次100ns
图3 clock_gettime 走真正的系统调用
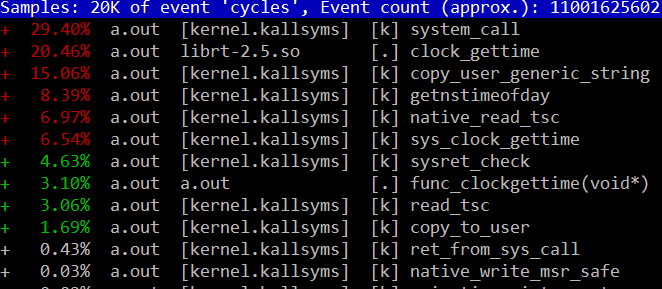
图4 clock_gettime 70%的cpu花在sys态,确实进入了系统调用流程
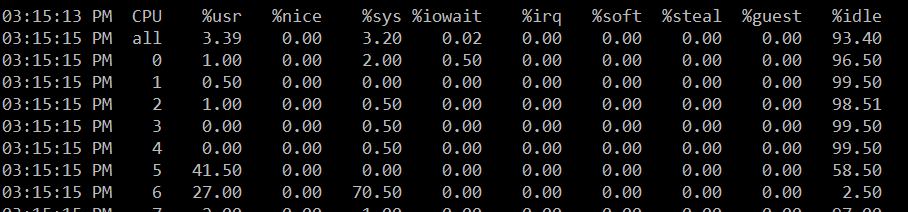
因为开销集中在系统调用本身,而不是花在进程切换上,所以多线程结果跟单线程类似。
$./a.out clock_gettime 12 100000000
clock_gettime(50369061997211567) , times : 100000000
thread 1122031936 consume 10226828 us
这里说“开销集中在系统调用本身”意思是说clock_gettime本身的执行就非常耗费时间,其大概的调用路径是
clock_gettime -> sys_call -> sys_clock_gettime -> getnstimeofday -> read_tsc -> native_read_tsc
void getnstimeofday(struct timespec *ts)
{
unsigned long seq;
s64 nsecs;
WARN_ON(timekeeping_suspended);
do {
// 下面代码执行过程中xtime可能会被更改,这里通过持有一个序号来避免显示加锁,如果该代码执行完毕之后,seq并未改变,说明xtime未被更改,此次执行成功,否则重试;无论这里重试与否,CPU都会一直干活;
seq = read_seqbegin(&xtime_lock);
*ts = xtime;
nsecs = timekeeping_get_ns(); //从当前时钟源取更细致的时间精度
/* If arch requires, add in gettimeoffset() */
nsecs += arch_gettimeoffset(); // 中断从发出到执行有时间消耗,可能需要做补偿
} while (read_seqretry(&xtime_lock, seq));
timespec_add_ns(ts, nsecs); //时间转换
}
/* Timekeeper helper functions. */
static inline s64 timekeeping_get_ns(void)
{
cycle_t cycle_now, cycle_delta;
struct clocksource *clock;
/* read clocksource: */
clock = timekeeper.clock;
// 使用系统注册的时钟源[2]来读取,当前情况下,一般tsc是默认时钟源
// /sys/devices/system/clocksource/clocksource0/current_clocksource
// 下面的调用最终执行native_read_tsc, 里面就是一条汇编指令rdtsc
cycle_now = clock->read(clock);
/* calculate the delta since the last update_wall_time: */
cycle_delta = (cycle_now - clock->cycle_last) & clock->mask;
/* return delta convert to nanoseconds using ntp adjusted mult. */
return clocksource_cyc2ns(cycle_delta, timekeeper.mult,
timekeeper.shift);
}
上面说到时钟源是可以替换的,
$cat /sys/devices/system/clocksource/clocksource0/available_clocksource
tsc hpet acpi_pm
这是所有可用的时钟源。硬件出问题或者内核bug有时候会使得tsc不可用,于是时钟源默认会切换到hpet,使用hpet后gettimeofday和clock_gettime性能如何?测试一下。
$sudo bash -c "echo hpet > /sys/devices/system/clocksource/clocksource0/current_clocksource"
$cat /sys/devices/system/clocksource/clocksource0/current_clocksource
hpet
$./a.out gettimeofday 1 100000000
gettimeofday(50067118117357) , times : 100000000
thread 1091926336 consume 71748597 us
延时是原来的17倍,大概700ns一次;clock_gettime 与此类似,因为此时瓶颈已经不是系统调用,而是hpet_read很慢。
此时大概的调用路径是
clock_gettime -> sys_call -> sys_clock_gettime -> getnstimeofday -> read_hpet -> hpet_readl –> readl
实现非常直白,但是readl是读时钟设备的内存映射,慢是肯定的了。
总结来说,上文制定的内核和glibc版本下,tsc时钟源,gettimeofday 比 clock_gettime快1倍多,适合做计时用(clock_gettime使用CLOCK_REALTIME_COARSE也是很快的);如果因为tsc不稳定(硬件或者内核bug都可能导致,碰到过),hpet一般不会同时出问题,这时hpet成为了新的时钟源,整体性能下降数十倍,两者没啥区别了。
[1]. On vsyscalls and the vDSO : http://lwn.net/Articles/446528/
[2]. Linux内核的时钟中断机制 : http://wenku.baidu.com/view/4a9f37f24693daef5ef73d32.html
#include <sys/time.h>
#include <iostream>
#include <time.h>
using namespace std;
uint64_t now()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void* func_gettimeofday(void* p)
{
int32_t c = *(int32_t*)p;
uint64_t start = now();
uint64_t us = 0;
int i = 0;
while (i++ < c) {
struct timeval tv;
gettimeofday(&tv, NULL);
us += tv.tv_usec; // avoid optimize
}
cout << "gettimeofday(" << us << ") , times : " << c << endl;
cout << "thread " << pthread_self() << " consume " << now() - start << " us" << endl;
return 0;
}
void* func_clockgettime(void* p)
{
int32_t c = *(int32_t*)p;
uint64_t start = now();
uint64_t us = 0;
int i = 0;
while (i++ < c) {
struct timespec tp;
clock_gettime(CLOCK_REALTIME, &tp);
us += tp.tv_nsec;
}
cout << "clock_gettime(" << us << ") , times : " << c << endl;
cout << "thread " << pthread_self() << " consume " << now() - start << " us" << endl;
return 0;
}
int main(int argc, char** argv)
{
if (argc != 4) {
cout << " [gettimeofday/clock_gettime] thread_number loop_count" << endl;
exit(-1);
}
string mode = string(argv[1]);
int n = atoi(argv[2]);
int loop = atoi(argv[3]);
pthread_t* ts = new pthread_t[n];
for (int i = 0; i < n; i++) {
if (mode == "gettimeofday") {
pthread_create(ts+i, NULL, func_gettimeofday, &loop);
} else {
pthread_create(ts+i, NULL, func_clockgettime, &loop);
}
}
for (int i = 0; i < n; i++) {
pthread_join(ts[i], NULL);
}
delete [] ts;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号