MapReduce中的Shuffle原理
source: MapReduce shuffle过程详解_xidianycy-CSDN博客_mapreduce shuffle
- 简述
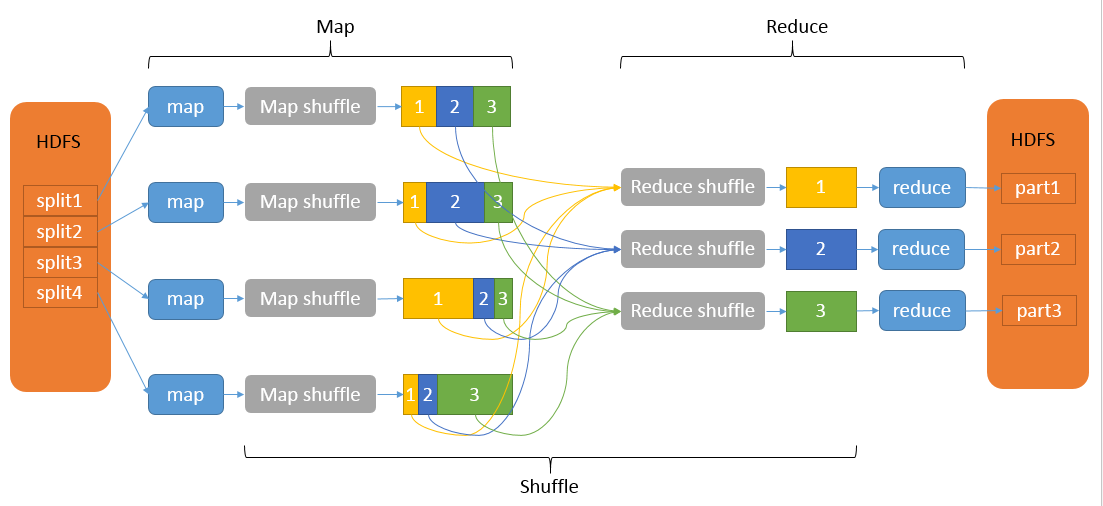
HDFS中的MapReduce计算模型主要分为3个部分: Map, Shuffle, Reduce.
-
- Map是映射, 将原始数据转化为键值(key-values)对.
- Reduce是合并, 将具有相同key值的values处理后再输出新的键值对作为最终结果.
- 为了让Reduce能够并行处理, 需要对Map后的键值对进行排序和分割, 然后再交给对应的Reduce, 这个过程我们称为Shuffle.
整个MR过程大致如下:
- Shuffle详解
Map和Reduce操作需要我们自己定义相应Map类和Reduce类,以完成我们所需要的化简、合并操作,而shuffle则是系统自动帮我们实现的,了解shuffle的具体流程能帮助我们编写出更加高效的Mapreduce程序.
Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle.
- Map shuffle
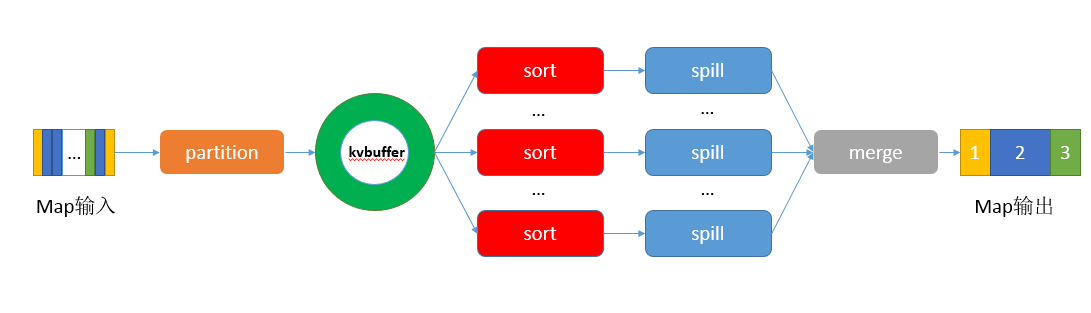
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件.
分区有序的含义是map输出的键值对中,具有相同partition值的键值对存储在同一个分区,每个分区里面的键值对又按key值进行升序排列(默认).
- Reduce shuffle
在Reduce端,shuffle主要分为复制Map输出、排序合并两个阶段. 最终输出一个整体有序的数据块.
-
- Copy
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据.
-
- Merge Sort
Copy过来的数据会先放到内存缓冲区, 属于内存到内存merge. 当内存放不下时, 开始内存到磁盘merge.
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件,这时开始执行合并操作,即磁盘到磁盘merge.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号