【Python】 Pandas: 拼接, 删除行列, 聚合
pandas
import pandas as pd
2021/9/21
删除DataFrame中含缺失值的记录
DataFrame.dropna()
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
axis: 默认axis=0。0为按行删除,1为按列删除
how: 默认 ‘any’。 ‘any’指带缺失值的所有行/列;'all’指清除一整行/列都是缺失值的行/列
thresh: int,保留含有int个非nan值的行
subset: 删除特定列中包含缺失值的行或列
inplace: 默认False,即筛选后的数据存为副本,True表示直接在原数据上更改
pd.concat()
train = pd.concat([train_x, train_y], axis=1, join='inner')
行对齐, 横向拼接: axis=1 . 按index对齐. 默认join='outer' 取并集. join='inner' 取交集
列对齐, 纵向拼接(默认): axis=0 . 拼接后的大表字段为所有字段的并集. 若小表缺失部分字段, 在拼接到大表后, 这些位置的值置空.
详解: 详解pandas数据合并与重塑(pd.concat篇)_python_脚本之家 (jb51.net)
2021/8/17
dataframe删除一列或者一行
>>>df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D'])
>>>df
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
# 删除列 df.drop(['B', 'C'], axis=1) df.drop(columns=['B', 'C']) # 删除行 df.drop([0, 1]) df.drop(index=[0, 1])
2021/8/2
去重计数
原文链接:https://blog.csdn.net/weixin_40040404/article/details/80742556
baby_names.head() Out[30]: Name Year Gender State Count 0 Emma 2004 F AK 62 1 Madison 2004 F AK 48 2 Hannah 2004 F AK 46 3 Grace 2004 F AK 44 4 Emily 2004 F AK 41
- Series.value_counts()
出现频率(注意DataFrame (baby_names)和DataFrame的分组(DataFrame.groupby())没有value_counts()属性)
1) Name 列的去重计数:
baby_names['Name'].value_counts().shape baby_names.drop_duplicates('Name').count()
注意:在方法2中 drop_duplicats('Name') 表示 Name 列不重复的数据, 若 drop_duplicats(['Name', 'Gender')] 则表示元组 (Name, Gender) 作为一个整体且该整体不重复的数据. (Lucy, F) 和 (Lucy, M) 整体不重复,计数为2条数据
2021/7/31
DataFrame的分组与聚合
-
groupby
In [5]: group = data.groupby("company")
将上述代码输入ipython后,会得到一个DataFrameGroupBy对象
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),第二个元素的是对应组别下的DataFrame.
In [8]: list(group) Out[8]: [('A', company salary age 3 A 20 22 6 A 23 33), ('B', company salary age 4 B 10 17 5 B 21 40 8 B 8 30), ('C', company salary age 0 C 43 35 1 C 17 25 2 C 8 30 7 C 49 19)]
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
-
agg 聚合操作
聚合操作是groupby后常见的操作。聚合操作可以用来求和、均值、最大值、最小值等:
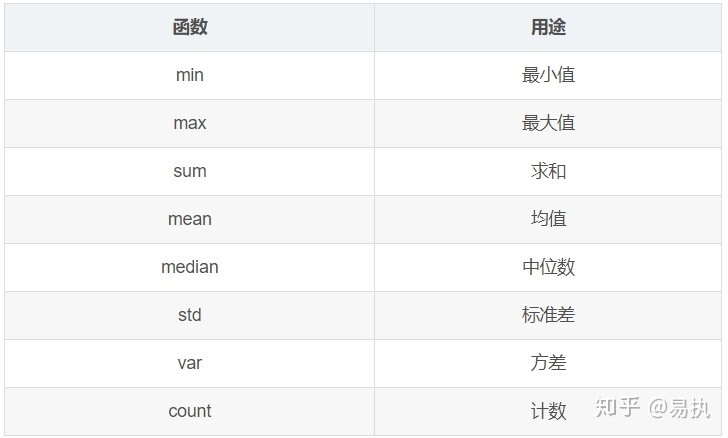
针对样例数据集,如果我想求不同公司员工的平均年龄和平均薪水,可以groupby后使用agg函数:
data.groupby("company").agg('mean')
如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以在agg的参数中利用字典指定聚合操作:
data.groupby('company').agg({'salary':'median','age':'mean'})
-
transform
在上面的agg中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列 avg_salary ,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系 map 到对应的位置,实现代码如下:
avg_salary_dict = data.groupby('company')['salary'].mean().to_dict() data['avg_salary'] = data['company'].map(avg_salary_dict)
如果使用 transform 的话,仅需要一行代码:
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
-
apply
对于groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame,而之前介绍的apply的基本操作单位是Series。还是以一个案例来介绍groupby后的apply用法。
假设我现在需要获取各个公司年龄最大的员工的数据,该怎么实现呢?可以用以下代码实现:
In [38]: def get_oldest_staff(x): ...: df = x.sort_values(by = 'age',ascending=True) ...: return df.iloc[-1,:] ...: In [39]: oldest_staff = data.groupby('company', as_index=False).apply(get_oldest_staff) In [40]: oldest_staff Out[40]: company salary age 0 A 23 33 1 B 21 40 2 C 43 35
注意:其中 as_index=False 指分组后,不将company这一列作为索引index。
面试实战题:用pandas读企业表(企业、行业、用户数共3列),如何得出各企业用户数前3名?
A:题目不完整,有两种理解。各企业用户数前3名(的行业?)
理解1:如果是求企业中,按用户数排名的前3名行业,需要在企业内对行业排序
def get_3_industry(data): data = data.sort_values(by='user_num', ascending=True) return data.iloc[-3:, :]
data_rank = data.groupby('company', as_index=False).apply(get_3_industry)
理解2:如果是求各企业的用户数排名。新增一列 company_user ,计算各企业的总用户数
data['company_user'] = data.groupby('company')['user_id'].transform('count')
df.sort_values
df.sort_values('score', ascending=False, na_position='first')
na_position 指排序后NaN的位置, 'first'指将NaN放在最前面.
字符串转变量
str2 = "123 sjhid dhi" list2 = str2.split() #or list2 = str2.split(" ") str3 = "www.google.com" list3 = str3.split(".")
list vs. tuple
- 相同点:
都是有序列表;
都可以使用下标索引来访问元素, 下标索引从0开始,可以进行截取,组合等
- 不同点:
元组中的元素值是不允许修改的,但我们可以对多个元组进行连接组合, 运算后会生成一个新的元组。
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号