Python简介及编码
首先Python是一种语言,因此根据其实现的不同,有Cpython, Jython, IronPython, Pypy等。
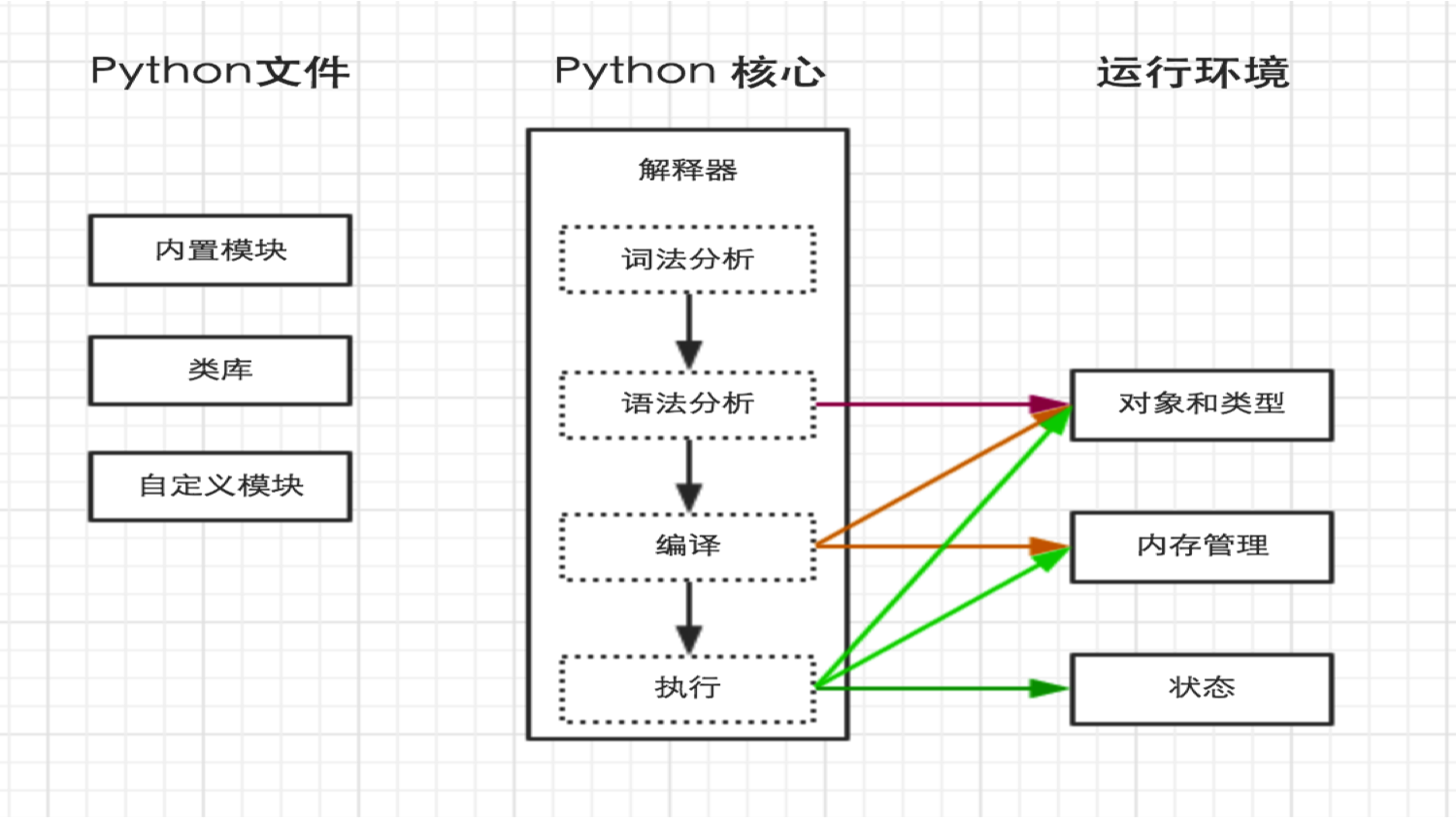
Python执行流程
$ python /home/hello.py 当在终端上执行py文件,流程图如下:
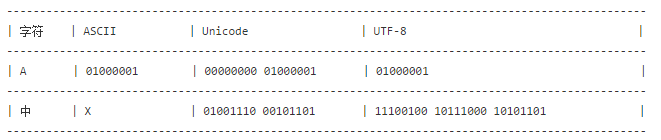
字符集
- ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
- Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是最少2个字节,可能更多。
- UTF-8是对Unicode编码的压缩和优化,目前使用的最广泛,是一种可变长字符编码,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
内存读写信息是以byte为单位.

编码和解码(encode==编码,decode==解码)
为什么要编码和解码?
答案是:便于存储和传输。因为计算机底层只能识别0和1的二进制数据,encode就是把逻辑上的字符变成二进制数据,以便存储和传输,使用decode把二进制数据解码成逻辑的字符便于用户理解和操作。至于编码前和解码后的字符是怎么存储的,是Python的内部实现,只有 Python 自己需要操心,用户不用管,就像你不用管整数在 Python 内存里长什么样一样,但是你把整数存起来或者传输到网络上时就得考虑,是转成十进制字符串表示呢,还是转成32位无符号小端序表示呢,还是64位有符号网络序表示呢……
python 2.x 默认编码(ASCII)
在Python2中默认是ASCII编码,所以不支持中文,如果要支持中文就必须声明为unicode字符串,即在字符串前面加个u。


>>> str1 = 'my name is Ray' # ascii字符串 >>> str2 = u'我的名字是Ray' # unicode字符串 >>> >>> type(str1) <type 'str'> >>> type(str2) <type 'unicode'>
非unicode字符串需要先解码为unicode字符集才能编码为其他字符集,unicode字符集起到一个中介作用。
>>> str1 = 'my name is Ray' >>> str2 = u'我的名字是Ray' >>> >>> str1.decode() u'my name is Ray' >>> >>> str1.decode().encode('utf-8') 'my name is Ray' >>> >>> str2.encode('gbk') '\xce\xd2\xb5\xc4\xc3\xfb\xd7\xd6\xca\xc7Ray'
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果有文件中有非ascii字符出现,则需要申明utf-8编码,让解释器以utf-8编码,不然会报错。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
python 3.x 默认编码(unicode)
在Python3中字符串都是str类型,编码之后变成byte类型(二进制,输出时一般以16进制或者10进制表示,方便查看),str类型使用encode编码为byte类型,byte类型使用decode解码为str类型,也可以使用str()和bytes()方法对两种类型进行转换,效果是一样的。
>>> str1 = 'Hello China' >>> str2 = '你好中国' >>> >>> type(str1) <class 'str'> >>> type(str2) <class 'str'> >>> >>> str1.encode('utf-8') b'Hello China' >>> str2.encode('gbk') b'\xc4\xe3\xba\xc3\xd6\xd0\xb9\xfa' >>> >>> s3 = str1.encode('utf-8') >>> s4 = str2.encode('gbk') >>> >>> type(s3) <class 'bytes'> >>> type(s4) <class 'bytes'> >>> >>> for i in str2: ... print(i) ... 你 好 中 国 >>> for j in s4: ... print(j) ... 196 227 186 195 214 208 185 250 >>> # 使用str()和bytes()转换,效果是一样的 >>> str(s4, 'gbk') '你好中国' >>> bytes(str2, 'gbk') b'\xc4\xe3\xba\xc3\xd6\xd0\xb9\xfa' >>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号