Web框架之Django
一、什么是框架?
在学习框架之前,我们应该先明白Web应用的本质:
-
浏览器发送一个HTTP请求到服务器;
-
服务器收到请求,通过生成一个HTML文档;
-
服务器把HTML文档作为HTTP响应的Body发送给浏览器;
-
浏览器收到HTTP响应,从HTTP Body取出HTML文档并显示。
所以,最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。Apache、Nginx、Lighttpd等这些常见的静态服务器就是干这件事情的。
我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。下面让我们自己来搭建一个简单的框架。


from wsgiref.simple_server import make_server def f1(req): print(req) print(req["QUERY_STRING"]) f1=open("index1.html","rb") data1=f1.read() return [data1] def f2(req): f2=open("index2.html","rb") data2=f2.read() return [data2] import time def f3(req): #模版以及数据库 f3=open("index3.html","rb") data3=f3.read() times=time.strftime("%Y-%m-%d %X", time.localtime()) data3=str(data3,"utf8").replace("!time!",str(times)) return [data3.encode("utf8")] def routers(): urlpatterns = ( ('/yuan',f1), ('/alex',f2), ("/cur_time",f3) ) return urlpatterns def application(environ, start_response): print(environ['PATH_INFO']) path=environ['PATH_INFO'] start_response('200 OK', [('Content-Type', 'text/html')]) urlpatterns = routers() func = None for item in urlpatterns: if item[0] == path: func = item[1] break if func: return func(environ) else: return ["<h1>404</h1>".encode("utf8")] httpd = make_server('', 8518, application) print('Serving HTTP on port 8084...') # 开始监听HTTP请求: httpd.serve_forever()
二、MVC和MTC模型
著名的MVC模式:所谓MVC就是把web应用分为模型(M),控制器(C),视图(V)三层;他们之间以一种插件似的,松耦合的方式连接在一起。
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。
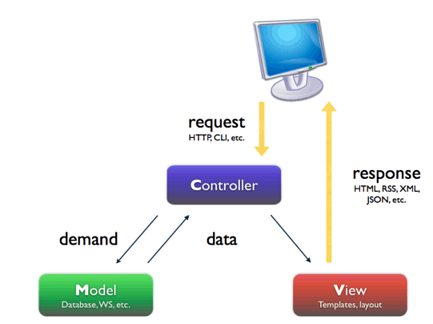
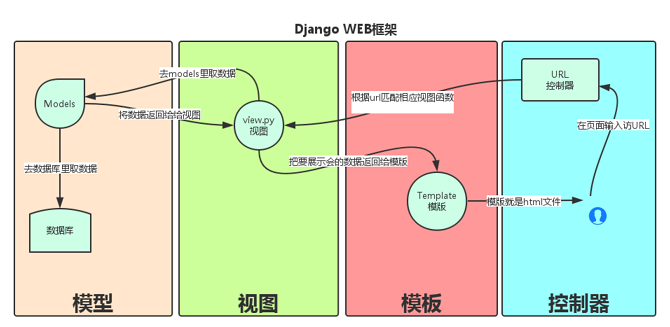
Django的MTV模式本质上与MVC模式没有什么差别,也是各组件之间为了保持松耦合关系,只是定义上有些许不同,Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个url分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
三 django的流程和命令行工具
#安装: pip3 install django 添加环境变量 1 创建project django-admin startproject mysite 2 创建APP python mannage.py startapp app01 3 settings配置 TEMPLATES //添加css或js路径 STATICFILES_DIRS=( os.path.join(BASE_DIR,"statics"), ) STATIC_URL = '/static/' # 我们只能用 STATIC_URL,但STATIC_URL会按着你的STATICFILES_DIRS去找 4 根据需求设计代码 urls.py (路由) views.py (视图) 5 使用模版 render(reqest,"index.html") 6 启动项目 python manage.py runserver 127.0.0.1:8090 7 连接数据库,操作数据 model.py
1、配置文件(Settings)
1)数据库:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'dbname',
'USER': 'root',
'PASSWORD': 'xxx',
'HOST': '',
'PORT': '',
}
}
#由于Django内部连接MySQL时使用的是MySQLdb模块,但是python3使用的是pymysql #如下设置放置的与project同名的配置的 __init__.py文件中 import pymysql pymysql.install_as_MySQLdb() 2)模版:
TEMPLATE_DIRS = (
os.path.join(BASE_DIR,'templates'),
)
3)静态文件:
#为了后端的更改不会影响前端的引入,避免造成前端大量修改
STATIC_URL = '/static/' #引用名(别名)
STATICFILES_DIRS = (
os.path.join(BASE_DIR,"statics") #实际名 ,即实际文件夹的名字
)
必须用STATIC_URL = '/static/':
#<script src="/static/jquery-3.1.1.js"></script>
#statics文件夹一般写在不同的app下,静态文件的调用:
STATIC_URL = '/static/'
STATICFILES_DIRS=(
('hello',os.path.join(BASE_DIR,"app01","statics")) ,
)
#<script src="/stati/jquery-1.8.2.min.js"></script>
#利用别名调用:
STATIC_URL = '/static/'
{% load staticfiles %}
# <script src={% static "jquery-1.8.2.min.js" %}></script>
2、urls路由系统
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
urls路由默认的是path路径,如果需要使用正则表达式规定url路径的话需要导入url模块,这样就可以使用正则表达式的路径了。
from django.conf.urls import url
urlpatterns = [
path('admin/',admin.site.urls), url(正则表达式, views视图函数,参数,别名), ]
参数说明:
- 一个正则表达式字符串
- 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 可选的要传递给视图函数的默认参数(字典形式)
- 一个可选的name参数,取别名。
设置名称之后,可以在不同的地方调用,如:
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path,include
from blog import views
#路由功能,获取用户输入的网址后,对应到相关的views.py视图里面的函数
urlpatterns = [
path('admin/', admin.site.urls),
path('show_time/', views.show_time),
# path('register/',views.register,name='reg'), #取别名reg,以后前端调用直接用reg
path('blog/',include('blog.urls')), #路由分发给blog应用下的urls
path('login/',views.login),
]
3、Views视图
1) http请求中产生两个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
2) 对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse
在HttpResponse对象上扩展的常用方法:
4、Template模版
1)组成:HTML代码+逻辑控制代码
2)模版语言:
{% load mytag %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
{#变量可以是字符串、字典、列表#}
<h3>{{ nowTime }}</h3>
<h3>{{ l }}</h3>
<h3>{{ dic }}</h3>
{#------深度变量的查找(万能的句点号)#}
<h3>{{ dic.name }}</h3>
<h3>{{ dic.age }}</h3>
<h3>{{ dic.gender }}</h3>
{#------变量的系统过滤器(filter)的使用#}
<h3>{{ dic.age|add:4 }}</h3> {#把age添加4#}
<h3>{{ dic.name|capfirst }}</h3> {#首字母大写#}
<h3>{{ cutt|cut:" " }}</h3> {#去除空格#}
<h3>{{ nowTime|date:"Y-m-d" }}</h3> {#格式化时间,按照Y-m-d#}
<h3>{{ defaul|default:"这是一个空" }}</h3>
{#------自定义过滤器(filter)和simple_tag的使用#}
<h3>我是自定义过滤器{{ dic.age|filter_multi:10 }}</h3>
<h3>我是自定义tag{% tag_multi dic.age 5 2 %}</h3>
{#------{% if %} 的使用语法#}
{% if dic.age > 30 %}
<p>年龄大于30岁</p>
{% elif dic.age > 18 %}
<p>年龄大于18小于30</p>
{% else %}
<p>未成年</p>
{% endif %}
{#------{% for %}的使用#}
{# {% for name in allName %}#}
{# <p>{{ name }}</p>#}
{# {% endfor %}#}
{% for name in allName %}
{# <p>{{ forloop.counter0 }}:{{ name }}</p>#} {# 循环allName里面的值,索引从0开始 #}
<p>{{ forloop.revcounter0 }}:{{ name }}</p> {# 反循环allName里面的值,索引从0开始 #}
{% endfor %}
{#------{% with %}:用更简单的变量名替代复杂的变量名#}
{% with nowTime as t %}
{{ t }}
{% endwith %}
{#------{% verbatim %}: 禁止render,可以真正的显示大括号{{ }}#}
{% verbatim %}
<p>{{ 我是大括号,你变不了我 }}</p>
{% endverbatim %}
</body>
</html>
3)extends模版继承:
当我们做一个系统页面的时候,你会许多功能页面跟我们的母板(也就是首页)几乎一模一样,需要的只是局部的内容,此时我们就需要写重复的代码。为了解决这个冗余问题,这时我们就运用了extends继承,减少重复代码。
在加载 current_datetime.html 模板时,模板引擎发现了 {% extends %} 标签, 注意到该模板是一个子模板。 模板引擎立即装载其父模板,即本例中的 base.html 。此时,模板引擎注意到 base.html 中的三个 {% block %} 标签,并用子模板的内容替换这些 block 。因此,引擎将会使用我们在 { block title %} 中定义的标题,对 {% block content %} 也是如此。 所以,网页标题一块将由{% block title %}替换,同样地,网页的内容一块将由 {% block content %}替换。
{% extends 'index.html' %} {# 拷贝母板 #}
{#------------- css样式 -------------#}
{% block css %}
h1{
text-align:center;
}
{% endblock %}
{#------------- 内容 -------------#}
{% block content %}
{{ block.super }} {# 访问父模板中的块的内容 #}
<h1>Hi here,it's student things</h1>
{% endblock %}
四、models之ORM模型
django默认支持sqlite,mysql, oracle,postgresql数据库。在项目中会默认使用sqlite数据库,如果我们想要更改为Mysql数据库,需要修改如下:
首先需要在mysql里创建好数据库,然后再设置Settings配置文件。
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'books', #你的数据库名称 'USER': 'root', #你的数据库用户名 'PASSWORD': '', #你的数据库密码 'HOST': '', #你的数据库主机,留空默认为localhost 'PORT': '3306', #你的数据库端口 } }
如果需要在后台查看ORM语句对Mysql底层到底做了什么操作,可以在Settings配置文件加上以下代码:
#数据库后台显示底层执行代码 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
配置完Settings里面数据库的操作后,接下来就需要建表了,在Django创建的应用Models下:
from django.db import models #python manage.py makemigtations #python manage.py migrate # Create your models here. class Book(models.Model): name = models.CharField(max_length=20) price = models.IntegerField() pub_date = models.DateField() publish = models.ForeignKey("Publish",on_delete=models.CASCADE) def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=20) class Publish(models.Model): name = models.CharField(max_length=20) city = models.CharField(max_length=20)
再学习表查询之前,我们先来看一下有关查询相关的API:
# 查询相关API: # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
1、表操作之一对一:
表记录: 1、添加: 方式一: Book() b=Book(name="python基础",price=68,pub_date='2018-12-20',author='ray') b.save() 方式二: Book.objects.create(name="python基础",price=68,pub_date='2018-12-20',author='ray') 2、修改 方式一: b=Book.objects.get(author='ray') b.price=100 b.save() 方式二(推荐): Book.objects.filter(author='ray').update(price=100) //QuerySet集合对象 3、删除 Book.objects.filter(author='ray').delete() 4、查询 books_list=books.objects.all() # books_list=books.objects.all()[::2] # books_list=books.objects.all()[::-1] # print('books_list',books_list) #拿到的是一个QuerySet集合对象,里面是一个个对象 # print('books_list[0]',books_list[0]) # books_list=books.objects.exclude(author='ray') #不包括作者为ray的书籍列表 #first,last,get取到的是一个实例对象,并非一个QuerySet集合对象 # books_list=books.objects.first() #一条结果,不能循环遍历 # books_list=books.objects.last() #一条结果,不能循环遍历 # books_list=books.objects.get(id=3) #查的是一条信息,不然就会报错,#一条结果,不能循环遍历 # books_list=books.objects.filter(author='ray') #查的是多条信息 # books_list=books.objects.filter(author='ray').values("name") #values相当于一个过滤,去除所有作者为ray的name # books_list = books.objects.all().values("name","price").distinct() #去重 # books_count = books.objects.all().values("name","price").distinct().count() #数量 # print(books_count) #------------------------------模糊查询之双下划线----------------------------------- # books_list = books.objects.filter(price__gt=60,price__lt=80).values("name","price") #价格大于60小于80 # books_list = books.objects.filter(id__in=[3,4,6]) # 获取id等于3,4,6的数据 # books_list = books.objects.exclude(id__in=[11, 22, 33]) # not in 3,4,6的数据 # books_list = books.objects.filter(name__contains="r") #区分大小写,作者带‘r'的书籍信息 # books_list = books.objects.filter(author__icontains="r") #不区分大小写,作者带‘r'的书籍信息 books_list = books.objects.filter(id__range=[3,5]) #就是范围bettwen and
2、表操作之多对一:
from django.shortcuts import render,HttpResponse from app01.models import * # Create your views here. def select(request): #查询记录(通过对象,[外键]) # question 1: 查找python这本书的出版社名字 #******方法一******正向查询 # res=Book.objects.filter(name='python')[0] # pub_obj=res.publish #--->通过外键获取到书籍对象对应的出版社对象 # print(pub_obj.name) #该出版社名字 # question 2: 查找人民出版社出版的所有书 # ******方法二******反向查询 # pub_obj=Publish.objects.filter(name='人民出版社')[0] # print(pub_obj.book_set.all().values('name','price')) # ******方法三******通过filter\values 双下划线查询 # print(Publish.objects.filter(name='人民出版社').values('book__name')) #正向查询 # print(Book.objects.filter(publish__name='人民出版社').values('name','price')) #反向 # question: 查找python这本书的出版社名字 # print(Publish.objects.filter(book__name='python').values('name','book__price')) #反向 # print(Book.objects.filter(name='python').values('publish__name')) #正向 # question: 查找在北京出版的所有书籍 # print(Publish.objects.filter(city='北京').values('book__name')) #正向 # print(Book.objects.filter(publish__city='北京').values('name','price')) #反向 return HttpResponse('success!')
3、表操作之多对多:
在多表查询中,难免会有许多复杂的条件,比如需要用到聚合函数、以及下面的Q,F查询等等。在django默认情况下是没有导入这些模块的,此时就需要我们自己导入: from django.db.models import Avg,Min,Sum,Max from django.db.models import Q,F book_obj=Book.objects.get(id=1) author_obj=Author.objects.all() # book_obj.authors.add(*author_obj) #authors对象添加author表的所有作者 # book_obj.authors.remove(2) # book_obj.authors.remove(3) #question 1:alex出过的所有书籍名称和价格 # print(Book.objects.filter(authors__name='alex').values('name','price')) #question 2:所有书总价格的平均值、总和(需要导入聚合函数) # print(Book.objects.all().aggregate(Avg('price'))) # print(Book.objects.all().aggregate(Sum('price'))) #question 3:alex卖的书的总价格 # print(Book.objects.filter(authors__name='alex').aggregate(Sum('price'))) # print(Book.objects.filter(authors__name='alex').aggregate(alex_book_money=Sum('price'))) #question 4:按作者分组,求每个作者出的书的总价格之和 # print(Book.objects.values('authors__name').annotate(Sum('price'))) # F使用查询条件的值,专门取对象中某列值的操作 # Q构建搜索条 #question 5:对所有书的价格提升10块 # print(Book.objects.all().update(price=F('price')+10)) #question 6:查询book表里面名字为GO并且/或者价钱为78的对象 # print(Book.objects.filter(Q(name='GO') & Q(price=78))) # print(Book.objects.filter(Q(name='GO') | Q(price=78))) #question 7:查询book表里面名字不为GO的所有对象 print(Book.objects.filter(~Q(name='GO'))) return HttpResponse('success!') # 补充:QuerySet特点: # ①惰性机制,orm语句查询完的时候,只有调用了才执行mysql语句,提高性能 # ②缓存效果,两次调用只能读取第一次调用的结果 # ③可迭代(for循环) # ④可切片 #print(objs[1:4])
1) 聚合查询: aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
from django.db.models import Avg,Min,Sum,Max
aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值
取别名:
Book.objects.aggregate(average_price=Avg('price'))
如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
2) 分组:annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
#question 4:按作者分组,求每个作者出的书的总价格之和
print(Book.objects.values('authors__name').annotate(Sum('price')))
4、补充:
https://www.cnblogs.com/ray-h/p/10193567.html
五、admin的配置
admin是django强大功能之一,它能共从数据库中读取数据,呈现在页面中,方便用户对数据库进行管理。它有包含许多功能,如果你觉得不好,也是可以自己编辑的。但是有时候,一些特殊的功能还需要定制,比如搜索功能,下面这一系列文章就逐步深入介绍如何定制适合自己的admin应用。
admin页面默认是英文的,如果你想要把它设置为中文,则需要在Settings里面修改下面的代码:
LANGUAGE_CODE = 'en-us' #LANGUAGE_CODE = 'zh-hans'
需要进入admin管理我们的数据库,需要下面两个步骤:
1、创建后台管理员
python manage.py createsuperuser
2、注册和配置django admin 后台管理页面
from django.contrib import admin
from app01.views import *
# Register your models here.
#这里定义的类只是在页面中显示一些功能,如果你已经注册完用户了,也可以跳过这一步,不需要先定义类。
class AdminBook(admin.ModelAdmin):
list_display=('name','price','pub_date','publish') #指定要显示的字段
ordering = ('price',) #指定排序字段
search_fields = ('publish',) #指定搜索的字段
fieldsets = [ #列表过滤器,添加信息的时候折叠显示其他不重要的字段
(None, {'fields': ['name']}),
('price information', {'fields': ['price', "publish"], 'classes': ['collapse']}),
]
#使用register的方法,admin页面才会显示我们的数据库
admin.site.register(Book,AdminBook)
admin.site.register(Publish)
admin.site.register(Author)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号