
4.transformer
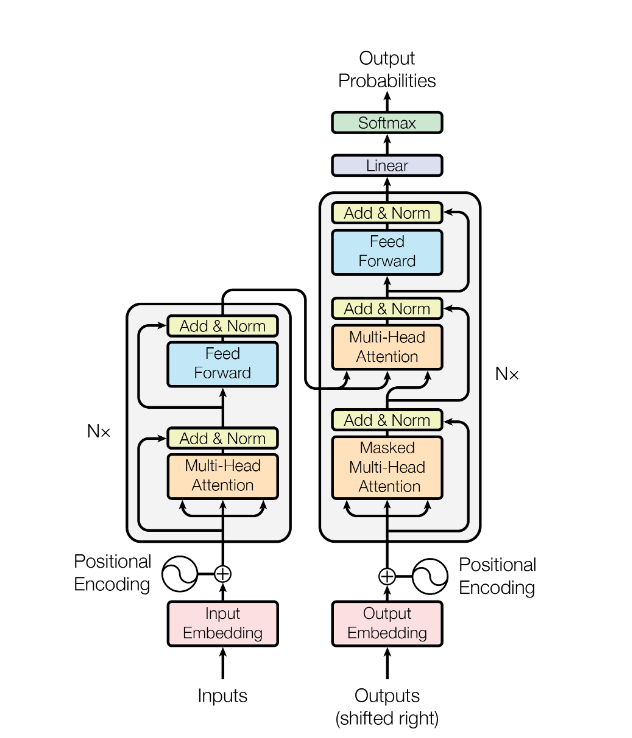
建议直接看参考的知乎链接,我这是一坨
1. encorder
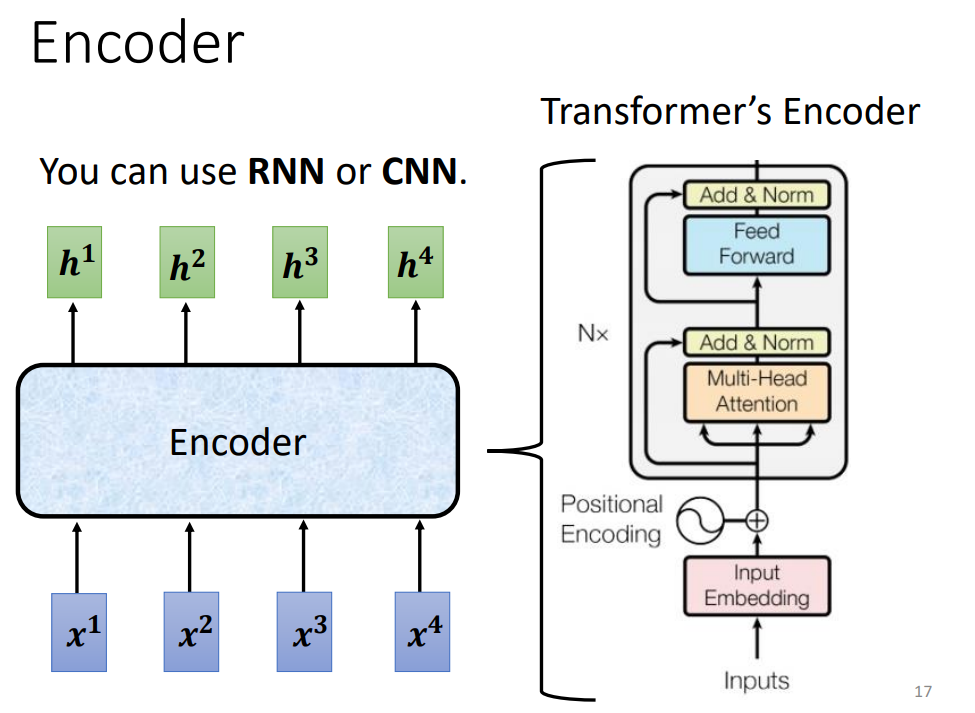

\[\mathrm{LayerNorm}\big(X+\mathrm{MultiHeadAttention}(X)\big)
\]
\[\mathrm{LayerNorm}\big(X+\mathrm{Feed}\mathrm{Forward}(X)\big)
\]
\[\mathrm{FeedForward}(X)=\max(0,XW_1+b_1)W_2+b_2
\]
做layernorm而不是batchnorm,李沐视频有讲
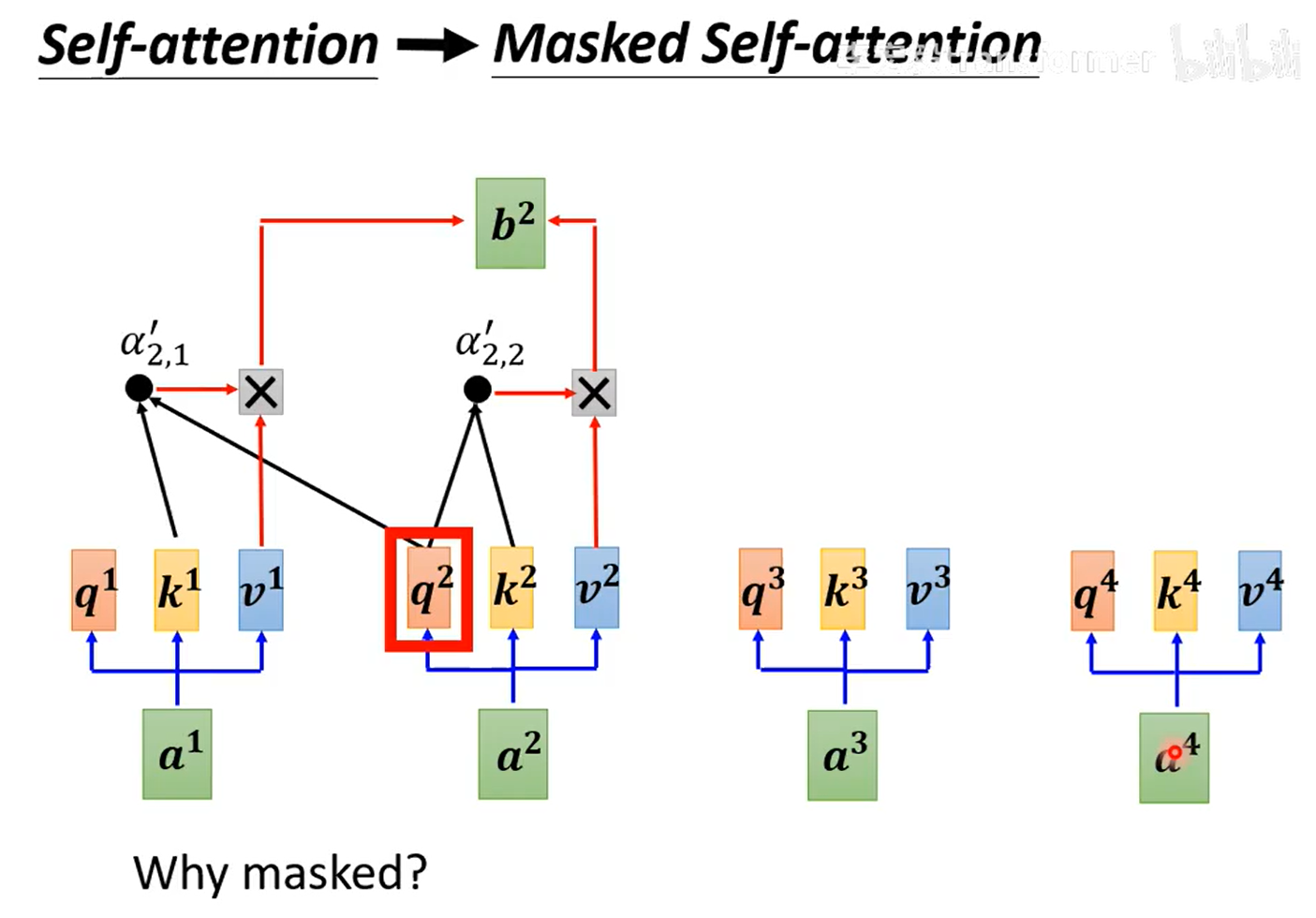
2. decorder

masked attention,每次输出都会考虑之前所有的输出,故后面的需要“遮住”
2.1 cross attention

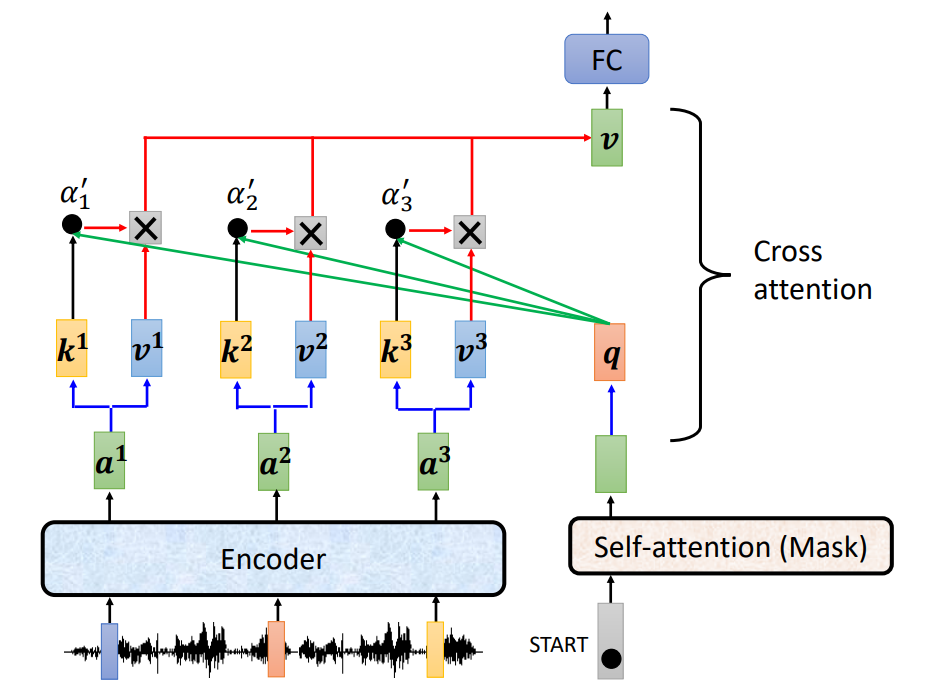
所以encorder有两个箭头指进来,下面masked的只有一个
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号