

PaddleOCRSharp如何加载自己的模型
PaddleOCRSharp 是基于百度飞桨 PaddleOCR 打造的 C# 版 OCR 识别库,凭借轻量、高效、跨平台的特性,成为.NET 开发者实现文字识别的优选工具。官方默认提供了通用的中、英、多语言识别模型,能满足大部分基础场景需求,但在证件识别、行业票据、特定字体等个性化场景下,通用模型的识别精度会大幅下降。此时将 PaddleOCRSharp 适配自研的定制化模型,成为提升专属场景识别效果的关键。本文将从模型准备、配置调整、代码实现到常见问题排查,全方位讲解 PaddleOCRSharp 使用自定义模型的完整流程,帮助.NET 开发者快速落地专属 OCR 识别需求。
一、前置准备
在使用自定义模型前,需完成基础环境和工具的配置,确保开发环境与 PaddleOCRSharp 的运行要求匹配,同时做好自定义模型的格式校验。
1.1 开发环境要求
框架:.NET Framework 4.0 及以上 /.NET Core 6.0以上
操作系统:Windows(x86/x64)
依赖库:已安装 PaddleOCRSharp NuGet 包
运行库:需将 PaddleOCRSharp 对应的paddle_inference运行库)放置在项目输出目录,官方包会自动携带,若缺失可从 PaddleOCRSharp 仓库下载。
1.2 自定义模型的格式要求
PaddleOCRSharp 仅支持PaddlePaddle 的推理模型(inference model),不支持训练过程中的预训练模型、检查点模型,自定义模型需满足以下规范,这是模型能被加载的核心前提:
模型结构:需包含 PaddleOCR 标准的检测模型(det)、识别模型(rec),若需方向检测则增加方向分类模型(cls),三者为 PaddleOCR 的标准流水线,缺一不可(若无需方向分类,可在配置中关闭);
文件组成:
旧版格式模型每个模型需包含 3 个核心文件 inference.pdmodel、inference.pdiparams、inference.pdiparams.info;识别模型需要额外字典文件,例如:ppocr_keys.txt。
新版格式模型每个模型需包含 3 个核心文件 inference.json、model.pdiparams、inference.yml;新版格式不需要额外的字典文件,字典存于识别模型的inference.yml中。缺少任一文件可能会导致模型加载失败;
字典文件:若自定义模型的识别字典与官方通用字典不同(如行业专属词汇、自定义字符集),需准备对应的dict.txt字典文件,确保识别结果与字符集匹配。
1.3 项目目录规划
为方便管理自定义模型和配置文件,建议按分类存放模型的原则规划项目目录,避免文件路径混乱导致的加载错误,推荐目录结构如下(可根据实际需求调整):
OCRProject/
├─ bin/Release/net6.0/ # 项目输出目录,存放运行库、模型文件
│ ├─ inference/ # 包含PaddleOCRSharp默认的模型和配置文件
│ ├─ custom_model/ # 自定义模型根目录
│ │ ├─ det/ # 自定义检测模型(含3个核心文件)
│ │ ├─ rec/ # 自定义识别模型(含3个核心文件)
│ │ ├─ cls/ # 自定义方向分类模型(可选,含3个核心文件)
│ │ └─ dict.txt # 自定义模型对应的字典文件
│ └─ PaddleOCRSharp.dll# 核心OCR库文件,包含opencv、paddle等必要依赖文件
└─ Program.cs # 核心代码实现文件
注意:发布项目时,需将custom_model整个目录复制到项目输出目录,确保程序运行时能正确读取模型文件,路径建议使用相对路径,避免绝对路径导致的跨环境运行问题。
二、核心步骤:使用自定义模型实现 OCR 识别
PaddleOCRSharp 加载自定义模型的核心逻辑是通过配置类指定自定义模型的路径、配置自定义字典,而非修改源码。整个流程分为模型文件部署、配置类参数调整、代码编写实现识别三步,以下以.NET 6 控制台项目为例,讲解完整实现过程,WinForm/WPF/ASP.NET Core 项目的实现逻辑一致,仅界面交互部分不同。
步骤 1:部署自定义模型文件
将训练好的推理模型按上述目录规划,复制到项目输出目录的custom_model子目录中,确保检测、识别(可选方向分类)模型的 3 个核心文件完整,同时将自定义dict.txt字典文件放在custom_model根目录。
步骤 2:调整 PaddleOCRSharp 配置类参数
PaddleOCRSharp 通过OCRModelConfig类统一管理 OCR 的所有模型配置,OCRParameter类统一管理相关配置参数。使用自定义模型的关键是修改默认路径,指定自定义模型的相对 / 绝对路径。
配置项调整原则
模型路径需指向模型所在目录,而非具体模型文件,PaddleOCRSharp 会自动读取目录下的 3 个核心模型文件;底层自动检测和加载model或者inference文件名的模型。
步骤 3:编写核心代码实现自定义模型的 OCR 识别
基于调整后的OCRModelConfig配置类,结合 PaddleOCRSharp 的PaddleOCR核心类,即可实现自定义模型的文字识别。以下提供完整可运行的代码示例,包含图片文件识别和图片流识别两种常用场景。
说明:本示例实际仍用的是PP_OCR_v5_Mobile模型,仅修改模型文件夹来作为演示模型。
PaddleOCRSharp版本采用v5.1+Paddle.Runtime.win_x64 v3.1.0.1
完整代码示例
using System;
using System.IO;
using System.Linq;
using PaddleOCRSharp;
namespace OCRProject
{
internal class Program
{
static PaddleOCREngine engine;
static void Main(string[] args)
{
try
{
//新建一个模型配置对象
OCRModelConfig modelConfig = new OCRModelConfig();
//获取程序根目录
string rootPath = AppContext.BaseDirectory;
//asp.net framework的根目录在bin文件夹下
//rootPath = Path.Combine( AppContext.BaseDirectory,"bin");
//获取程序根目录下自定义模型的文件夹目录
string modelPath = Path.Combine(rootPath, "custom_model");
modelConfig.det_infer = Path.Combine(modelPath, "det");
modelConfig.cls_infer = Path.Combine(modelPath, "cls");
modelConfig.rec_infer = Path.Combine(modelPath, "rec");
//如果是新格式模型,这里keys不为空即可。
modelConfig.keys = Path.Combine(modelPath, "dict.txt");
//新建一个参数配置对象,具体参数的描述和缺省值详见:https://gitee.com/raoyutian/PaddleOCRSharp/blob/master/doc/UseInCsharp.md
OCRParameter oCRParameter = new OCRParameter();
//使用modelConfig加载自定义模型,oCRParameter参数
//engine = new PaddleOCREngine(modelConfig, oCRParameter);
//使用modelConfig加载自定义模型,custom.json配置文件参数(推荐,修改参数不用修改代码部署后仍能修改配置)
string parameterjsonfile = Path.Combine(modelPath, "custom.json");
string parameterjson = File.ReadAllText(parameterjsonfile);
engine = new PaddleOCREngine(modelConfig, parameterjson);
//使用文件路径参数
//有其他重载方法,如bitmp、byte数组,base64、cvMat 指针、bitmp指针
string imagefile= Path.Combine(rootPath, "image","test.jpg");
OCRResult result= engine.DetectText(imagefile);
//使用bytes参数
//var bytes= File.ReadAllBytes(imagefile);
//engine.DetectText(bytes);
//使用Bitmap参数
//var bmp=new Bitmap() ;
//engine.DetectText(bmp);
//OCRResult类具体描述详见:https://gitee.com/raoyutian/PaddleOCRSharp/blob/master/doc/UseInCsharp.md
if (result!=null && result.TextBlocks!=null)
{
//result.Text默认是对所有文本框进行拼接的字符串,没有空格换行等
Console.WriteLine("识别结果:\n" + result.Text);
//result.JsonText是底层原始json格式的字符串,result.TextBlocks是根据result.JsonText反序列化得到的对象
Console.WriteLine("识别结果(json):\n" + result.JsonText);
//遍历每个文本框
foreach (var tb in result.TextBlocks)
{
// 识别文字内容 ToString()是对TextBlock的字符串形式的组合。
Console.WriteLine($"{tb.ToString()}");
// 识别文字纯内容
Console.WriteLine($"{tb.Text}");
//文本框坐标左上顶点
Console.WriteLine($"{tb.BoxPoints[0].ToString()}");
//文本框坐标右上顶点
Console.WriteLine($"{tb.BoxPoints[1].ToString()}");
//文本框坐标右下顶点
Console.WriteLine($"{tb.BoxPoints[2].ToString()}");
//文本框坐标左下顶点
Console.WriteLine($"{tb.BoxPoints[3].ToString()}");
}
//如果对返回结果顺序不满意,可以自行对结果进行排序
//从左到右,从上到下排序
result.TextBlocks = result.TextBlocks.OrderBy(u => u.BoxPoints[0].X).ThenBy(u => u.BoxPoints[0].Y).ToList();
}
}
catch (Exception ex)
{
Console.WriteLine("err:"+ex.Message);
}
//阻止命令行窗口自动关闭
Console.ReadKey();
}
}
}
步骤 4:项目发布与运行
右键项目→生成,确保项目无编译错误;
进入项目输出目录(如bin/Release/net6.0),检查custom_model目录、运行库、PaddleOCRSharp 核心文件是否完整;将测试图片test.jpg放入image目录,直接运行OCRProject.exe,即可看到自定义模型的识别结果。
示例运行结果如图:
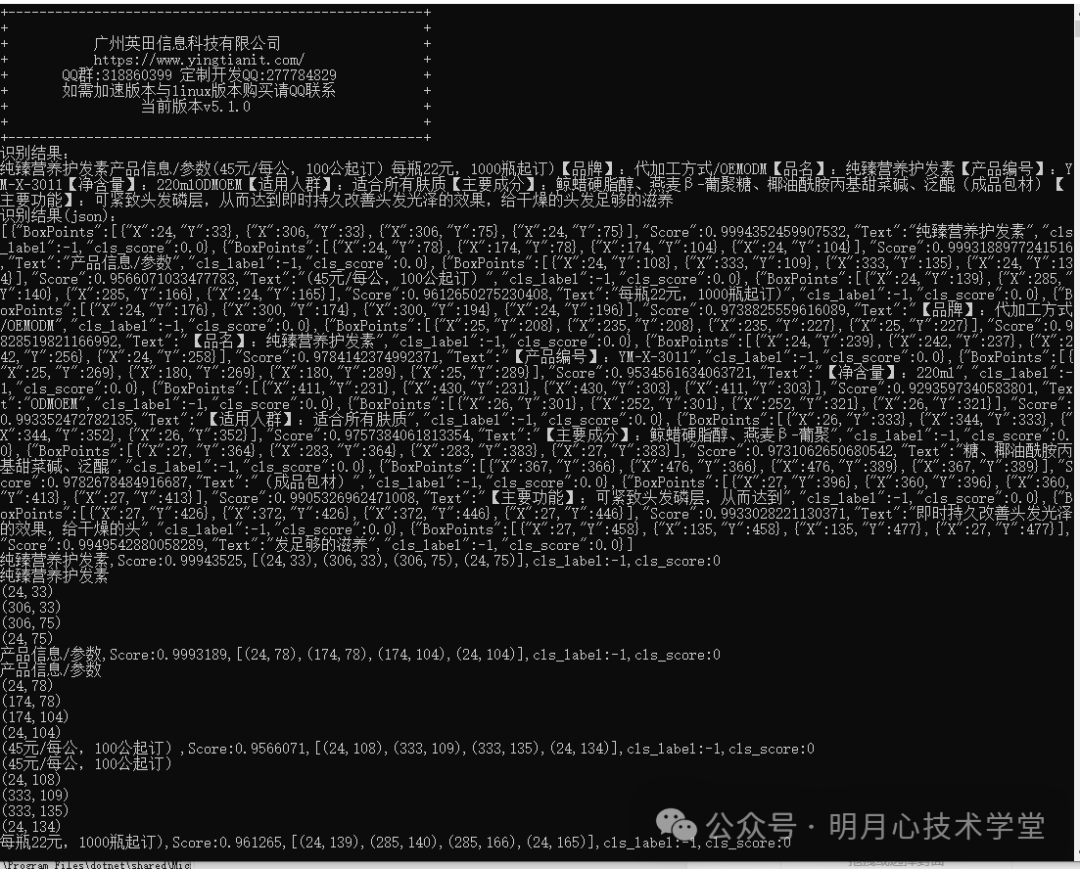
三、WinForm/WPF 项目适配:可视化界面中使用自定义模型
实际开发中,更多场景是在 WinForm/WPF 可视化项目中使用自定义模型,核心配置与控制台项目完全一致,仅需增加图片选择、界面展示的逻辑。此处不再给出示例。
四、常见问题与排查方案
使用自定义模型时,容易因模型格式、路径、配置等问题导致加载失败或识别异常,以下是高频问题及对应的排查方案,覆盖 90% 以上的使用场景:
问题 1:程序运行时报错 “模型文件不存在”
原因:模型路径配置错误、模型文件缺失、相对路径根目录错误;
排查:
检查配置中的模型路径是否为项目输出目录的相对路径,而非源码目录;
验证模型目录下是否存在model.pdmodel、model.pdiparams、model.pdiparams.info三个文件;
尝试使用绝对路径测试,排除相对路径解析问题。
问题 2:模型加载成功,但识别结果为乱码 / 漏字 / 错字
原因:字典文件与自定义模型字符集不匹配、识别模型输入尺寸与训练时不一致;
排查:
检查keys是否指向自定义dict.txt,确保字典中的字符集与模型训练时的字符集完全一致;
建议基于 PaddleOCR v3/v4 训练模型,搭配最新版 PaddleOCRSharp,算子兼容性最佳。
问题 4:CPU 推理速度过慢
优化方案:
适当减小模型输入尺寸(如将 max_side_len从 960 改为 640),牺牲少量精度提升速度;
开启 PaddleOCRSharp 的多线程推理(配置类中cpu_math_library_num_threads默认设为 10,根据 CPU 核心数调整);
对输入图片进行预处理,裁剪掉无文字的区域,减少模型推理的像素量;
问题 5:ASP.NET 项目中使用自定义模型,部署后识别失败
原因:IIS 进程权限不足、模型文件被锁定、路径解析错误;
排查:
给网站部署目录添加IIS_IUSRS和Network Service的读写权限;
模型路径使用AppContext.BaseDirectory拼接(如Path.Combine(AppContext.BaseDirectory, "custom_model/det")),确保在ASP.NET 中正确解析根目录;
将PaddleOCREngine引擎的初始化放在单例中,避免多次加载模型导致的文件锁定问题。
五、进阶优化:提升自定义模型的识别效果与运行效率
5.1 模型优化
训练时增加场景化样本,提升模型对目标场景的适配性,如票据识别需增加不同版式、不同清晰度的票据样本。
5.2 配置优化
根据实际场景调整检测阈值避免漏检;
开启图片预处理:在识别前对图片进行灰度化、二值化、降噪处理,提升模糊图片的识别精度,可使用 OpenCvSharp 配合 PaddleOCRSharp 实现预处理。
5.3 代码优化
在ASP.NET Core/WinService 等服务端项目中,将PaddleOCR引擎设为单例,避免每次请求都加载模型(模型加载耗时较长,单例可大幅提升并发效率);
对识别结果进行后处理:根据业务需求筛选文字块(如按坐标筛选特定区域的文字、按字符长度过滤无效识别结果),提升结果的可用性。
六、总结
PaddleOCRSharp 使用自定义模型的核心是遵循 PaddleOCR 的推理模型规范,通过 OCRModelConfig 配置类精准指定自定义模型、字典文件的路径,整个过程无需修改 PaddleOCRSharp 的源码,仅需调整配置和编写少量业务代码,即可快速适配专属场景的 OCR 需求。
PaddleOCRSharp 的高扩展性让.NET 开发者能快速落地定制化 OCR 需求,结合自定义模型的场景化优势,可在证件、票据、物流、金融等众多行业实现高精度的文字识别,是.NET 生态中 OCR 开发的优质选择。
完整项目源代码可以加入QQ群获取:318860399
 浙公网安备 33010602011771号
浙公网安备 33010602011771号