

PaddleOCRSharp 5.0.0重磅发布:OCR精度跃升13%,单模型支持多语种、手写体
前言
2025年5月20日,飞桨团队发布PaddleOCR 3.0并对外开源,全面适配飞桨框架3.0正式版,进一步提升文字识别精度,支持多文字类型识别和手写体识别,满足大模型应用对复杂文档高精度解析的旺盛需求,结合文心大模型4.5 Turbo显著提升关键信息抽取精度,并新增对昆仑芯、昇腾等国产硬件的支持。2025年5月21日,广州英田信息科技随即完成适配了全场景文字识别模型PP-OCRv5和PP-OCRv5_Server,并发布了PaddleOCRSharp 5.0.0版本的SDK,该SDK可以通过nuget包安装下载使用。


PaddleOCRSharp 简介
PaddleOCRSharp 是一个.NET版本OCR可离线使用类库。项目核心组件PaddleOCR.dll目前已经支持C\C++、.NET、Python、Golang、Rust、java等众多开发语言的直接API接口调用。项目包含文本识别、文本检测、表格识别功能。本项目做了大量优化,提高了识别率和推理性能。包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持中英文、纯英文以及多种语言文本检测识别。
PaddleOCRSharp封装极其简化,实际调用仅几行代码,极大地方便了中下游开发者的使用和降低了PaddleOCR的使用入门级别,同时提供不同的.NET框架使用,方便各个行业应用开发与部署。Nuget包即装即用,可以离线部署,不需要网络就可以识别的高精度中英文OCR。
本项目支持官方所有公开的通用OCR模型,如:PPOCRV2、PPOCRV3、PPOCRV4、PP-OCRv4_server、PP-OCRv4_server_doc(1.5万字符字典模型)、
PP-OCRv5、PP-OCRv5_Server(1.8万+字符字典模型):★windows系统支持:win7SP1、win10、win11、winserver2012R2、winserver2016、winserver2019、winserver2022等。免费版支持在x86的CPU上使用,CPU指令集需要包含AVX指令集。
★windows下版本有免费开源版、CPU加速版(付费版)、GPU加速版(付费版)
★linux系统支持(付费版):统信UOS、麒麟、ubuntu、CentOS8等绿色离线部署,支持docker部署。支持国产CPU如华为鲲鹏、飞腾、海光、兆芯等CPU。
本项目目前支持以下.NET框架(linux版本仅支持net6.0及以上框架):
net35;net40;net45;net451;net452;net46;net461;net462;net47;net471;net472;net48;net481; netstandard2.0;netcoreapp3.1; net5.0;net6.0;net7.0;net8.0;net9.0
PaddleOCRSharp 特点
★ 高度集成高度集成:PaddleOCRSharp将百度飞桨PaddleOCR的核心功能完美集成到.NET平台,让开发者无需关心底层实现,只需调用相应接口即可实现OCR功能。
★ 性能卓越性能卓越:得益于百度飞桨PaddleOCR的高效算法和对PaddleOCR代码的部分算法优化,PaddleOCRSharp在保持高度集成的同时,也保证了卓越的性能表现。
★ 易于使用易于使用:PaddleOCRSharp提供了丰富的API接口和详细的文档说明,让开发者能够轻松上手,快速实现OCR功能。
★ 扩展性强扩展性强:PaddleOCRSharp支持自定义模型加载和训练,开发者可以根据自己的需求进行模型扩展和优化。
★ 离线免费离线免费:PaddleOCRSharp支持离线绿色部署,无其他依赖需要安装,满足了众多开发者的福音。
PaddleOCRSharp提供了两个SDK,一个是C++版本,一个是.net版本,.net版本是对C++版本的二次封装,其他语言开发亦是调用C++版本。同时也提供了Go、Python、C++的调用示例代码博客园文章:NET框架下如何使用PaddleOCRSharp新版模型优势PP-OCRv5单模型支持5种文字类型和复杂手写体识别整体识别精度相比上一代提升13个百分点。




(以上图片来源飞桨官方公众号)


中英文V4效果图

PP-OCRv5效果图
PP-OCRv5的主要优势有:
-
单模型支持5种文字类型(简体中文、繁体中文、中文拼音、英文和日文)。PP-OCRv5是业界首个单模型支持5种文字类型的超轻量级(<100M)开源模型,在此之前,通常是单一模型解决一种文字类型的识别。若一个文档中有3种文字类型,则需要调用三个模型去实现文字识别,导致识别效率不高。PP-OCRv5通过统一模型架构实现5种文字类型的无缝识别,无需针对不同文字类型部署独立模型,简化了部署流程,也提升了识别的总体精度和速度。
-
支持复杂手写体识别。手写体混合印刷体的识别是多个应用场景的刚需,例如:教育行业的试卷作业批改场景、医疗行业的病历数字化场景、法律行业的合同笔录数字化场景等。PP-OCRv5支持中英日手写体识别,对复杂连笔、非规范字迹识别精度有显著提升。
-
整体识别达到SOTA精度。在业务多场景高难度文字识别评估集上,PP-OCRv5的识别精度达到当前最优,比上一版本PP-OCRv4,识别精度提升13个百分点!

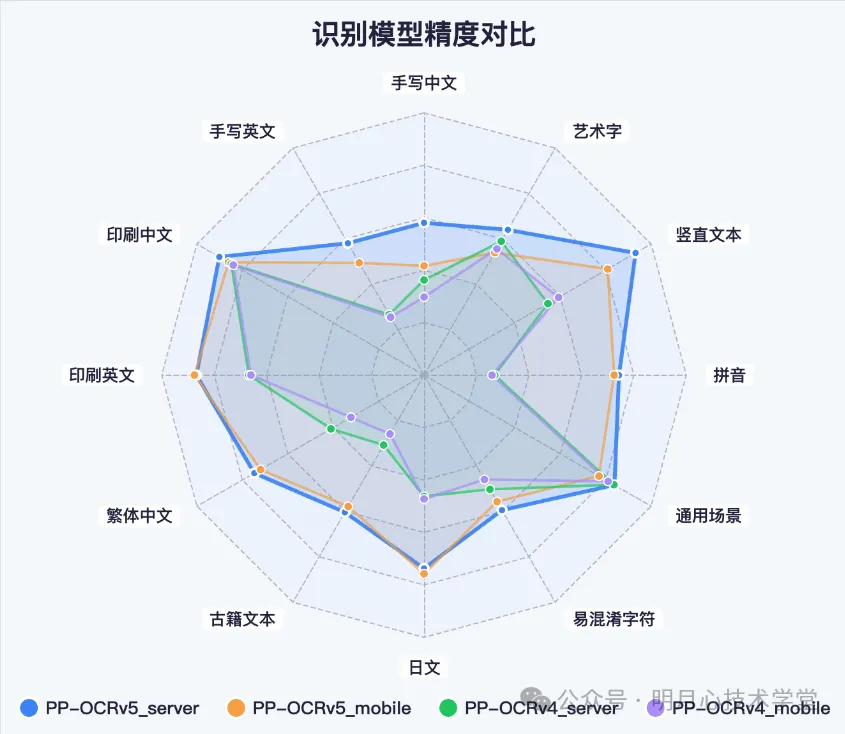
(以上图片来源飞桨官方公众号)
PaddleOCRSharp开源地址:https://gitee.com/raoyutian/PaddleOCRSharp技术交流:扫描下方二维码,加入QQ技术交流群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号