


PTA5-8次大作业总结分析
-
前言(作业分析)
本次总结共有四次大作业,包括最后一次的五边形计算几何和电信计费三次。其余的小题目都是比较简单的题,大概五到十分钟就能写完,在这里就不过多总结。这次总结主要是总结每次大作业中分最多的那个大题目。
首先是第五次作业中的五边形计算几何题目,一如既往的不会,真的很难。最后实在没办法了只能骗分。然后是三次电信计费题目,主要是考察正则表达式和ArrayList和集合。本次作业我主要使用的是树集。
-
设计与分析
- 第五次大作业 -- 凸五边形的计算
和前几次的计算几何题目一致,把图形更换了。之前使用数组的方式来存点,这次选择改进,换成了无序储存的哈希集合,有利于题目后面涉及到的冗点删除,所以直接使用哈希集合删除相同的点。其他的计算方式基本相同。
贴题目:
用户输入一组选项和数据,进行与五边形有关的计算。 以下五边形顶点的坐标要求按顺序依次输入,连续输入的两个顶点是相邻顶点,第一个和最后一个输入的顶点相邻。 选项包括: 1:输入五个点坐标,判断是否是五边形,判断结果输出true/false。 2:输入五个点坐标,判断是凹五边形(false)还是凸五边形(true),如果是凸五边形,则再输出五边形周长、面积,结果之间以一个英文空格符分隔。 若五个点坐标无法构成五边形,输出"not a pentagon" 3:输入七个点坐标,前两个点构成一条直线,后五个点构成一个凸五边形、凸四边形或凸三角形,输出直线与五边形、四边形或三角形相交的交点数量。如果交点有两个,再按面积从小到大输出被直线分割成两部分的面积(不换行)。若直线与多边形形的一条边线重合,输出"The line is coincide with one of the lines"。若后五个点不符合五边形输入,若前两点重合,输出"points coincide"。 以上3选项中,若输入的点无法构成多边形,则输出"not a polygon"。输入的五个点坐标可能存在冗余,假设多边形一条边上两个端点分别是x、y,边线中间有一点z,另一顶点s: 1)符合要求的输入:顶点重复或者z与xy都相邻,如:x x y s、x z y s、x y x s、s x y y。此时去除冗余点,保留一个x、一个y。 2) 不符合要求的输入:z不与xy都相邻,如:z x y s、x z s y、x s z y
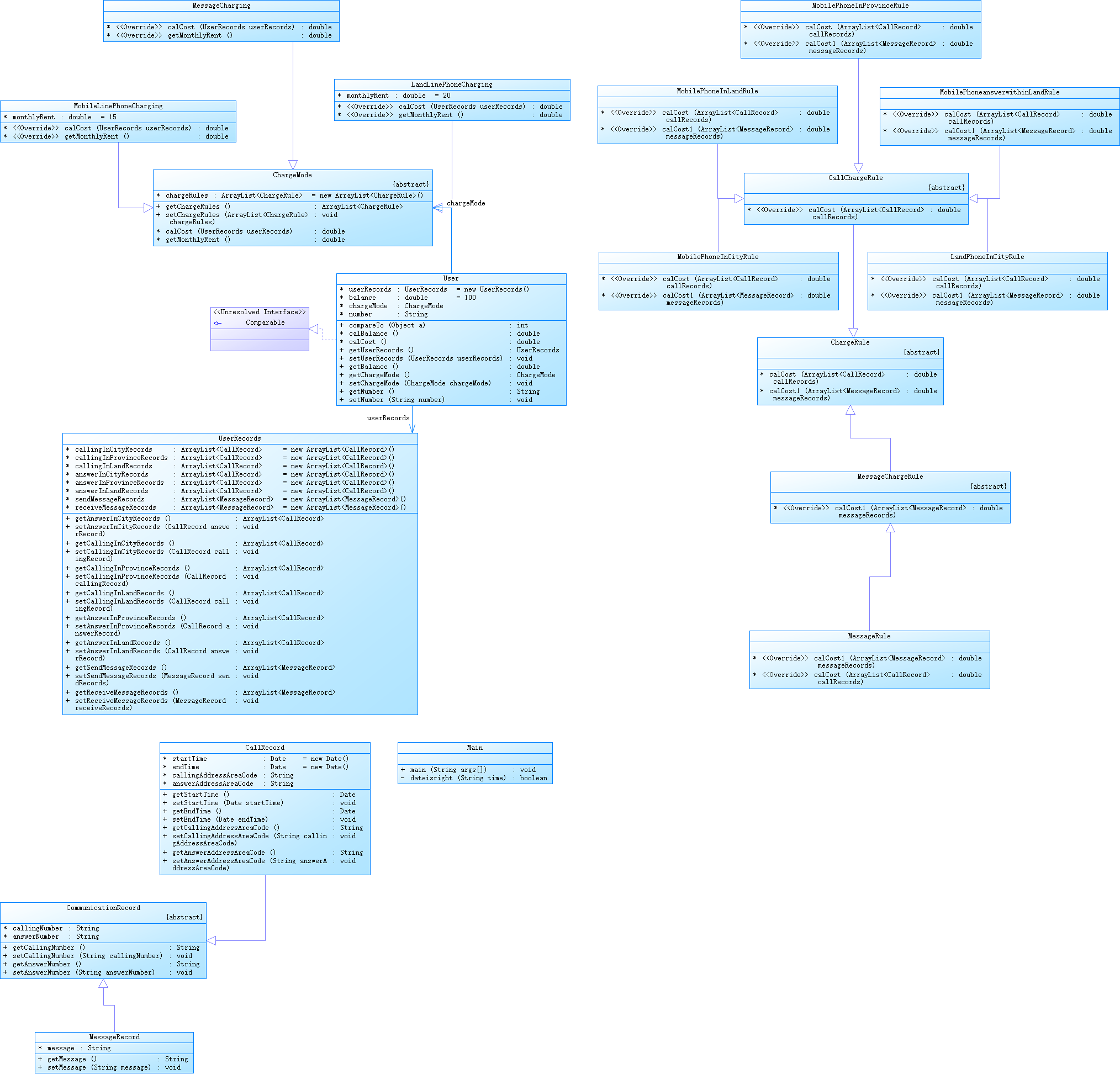
类图:

本次作业基本上使用了与前几次大作业一致的功能函数,但是在判断图形方面还是存在一些误差,导致个别几个测试点无法通过。
本次作业要求判断三角形四边形和五边形,所以直接将前几次作业中的判断图形拿进来了,但是在凹凸图形判断方面,四边形和五边形的判断有些许差别,所以四边形的算法无法直接使用到五边形上,在一定改进之后还是有些许错误,导致无法判断为五边形或者凹凸五边形的情况。作业结束之后我也没有找到错误原因。
分析图 :
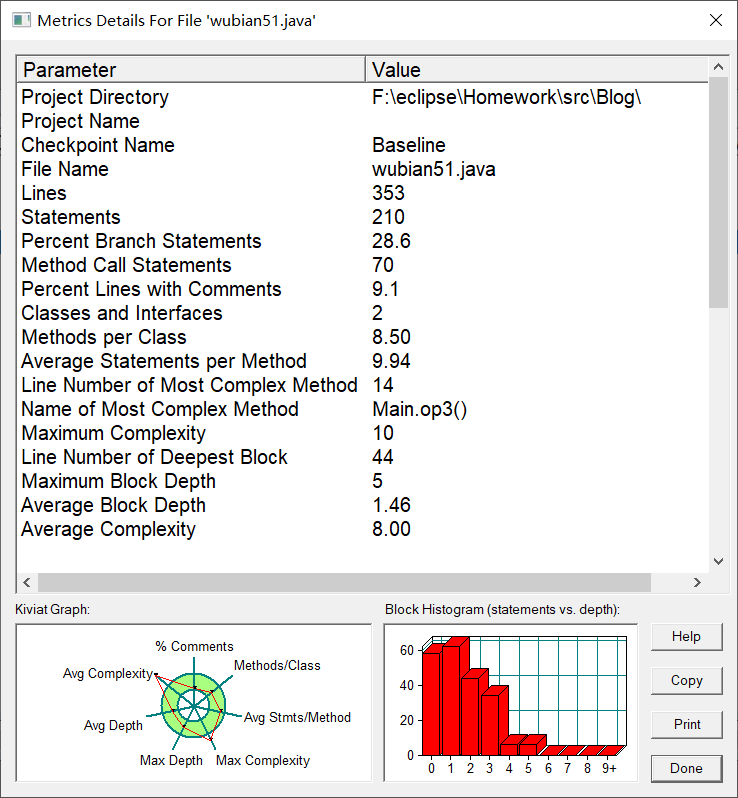
按照分析图来看,总的还是不错的,代码的重复度不高,但是太复杂了,希望可以改进。
- 第六次大作业 -- 电信计费系列1-座机计费
新的作业系列。主要考察的是正则表达式和SimpleDateFormat类的使用,还有ArrayList类的使用。第一题只考虑了座机的计费方式,所以较为简单,只需要将大部分的正则表达式写对,考虑日期的正确输入,其他的错误输入不做判断直接忽略。
贴题目:
实现一个简单的电信计费程序: 假设南昌市电信分公司针对市内座机用户采用的计费方式: 月租20元,接电话免费,市内拨打电话0.1元/分钟,省内长途0.3元/分钟,国内长途拨打0.6元/分钟。不足一分钟按一分钟计。 南昌市的区号:0791,江西省内各地市区号包括:0790~0799以及0701。 输入格式: 输入信息包括两种类型 1、逐行输入南昌市用户开户的信息,每行一个用户, 格式:u-号码 计费类型 (计费类型包括:0-座机 1-手机实时计费 2-手机A套餐) 例如:u-079186300001 0 座机号码除区号外由是7-8位数字组成。 本题只考虑计费类型0-座机计费,电信系列2、3题会逐步增加计费类型。 2、逐行输入本月某些用户的通讯信息,通讯信息格式: 座机呼叫座机:t-主叫号码 接听号码 起始时间 结束时间 t-079186330022 058686330022 2022.1.3 10:00:25 2022.1.3 10:05:11 以上四项内容之间以一个英文空格分隔, 时间必须符合"yyyy.MM.dd HH:mm:ss"格式。提示:使用SimpleDateFormat类。 以上两类信息,先输入所有开户信息,再输入所有通讯信息,最后一行以“end”结束。 注意: 本题非法输入只做格式非法的判断,不做内容是否合理的判断(时间除外,否则无法计算),比如: 1、输入的所有通讯信息均认为是同一个月的通讯信息,不做日期是否在同一个月还是多个月的判定,直接将通讯费用累加,因此月租只计算一次。 2、记录中如果同一电话号码的多条通话记录时间出现重合,这种情况也不做判断,直接 计算每条记录的费用并累加。 3、用户区号不为南昌市的区号也作为正常用户处理。 输出格式: 根据输入的详细通讯信息,计算所有已开户的用户的当月费用(精确到小数点后2位, 单位元)。假设每个用户初始余额是100元。 每条通讯信息单独计费后累加,不是将所有时间累计后统一计费。 格式:号码+英文空格符+总的话费+英文空格符+余额 每个用户一行,用户之间按号码字符从小到大排序。 错误处理: 输入数据中出现的不符合格式要求的行一律忽略。
因为题目要求要按照手机号码的大小排序,及按照Java语言的字典进行排序,所以这次针对重复输入的储存,我选择了自带排序的树集进行数据的储存。树集属于SortedSet的一种,所以在书写的时候,如果要按照要求进行排序,需要自己重写comparaTo方法,按照所需的排序顺序进行比较。
在这里贴一下TreeSet的使用和new方法:
package java.util; public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { // 使用NavigableMap对象的key来保存Set集合的元素 private transient NavigableMap<E,Object> m; //使用PRESENT作为Map集合中的value private static final Object PRESENT = new Object(); // 不带参数的构造函数。创建一个空的TreeMap //以自然排序方法创建一个新的TreeMap,再根据该TreeMap创建一个TreeSet //使用该TreeMap的key来保存Set集合的元素 public TreeSet() { this(new TreeMap<E,Object>()); } // 将TreeMap赋值给 "NavigableMap对象m" TreeSet(NavigableMap<E,Object> m) { this.m = m; } //以定制排序的方式创建一个新的TreeMap。根据该TreeMap创建一个TreeSet //使用该TreeMap的key来保存set集合的元素 public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<E,Object>(comparator)); } // 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中 public TreeSet(Collection<? extends E> c) { this(); // 将集合c中的元素全部添加到TreeSet中 addAll(c); } // 创建TreeSet,并将s中的全部元素都添加到TreeSet中 public TreeSet(SortedSet<E> s) { this(s.comparator()); addAll(s); } // 返回TreeSet的顺序排列的迭代器。 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 public Iterator<E> iterator() { return m.navigableKeySet().iterator(); } // 返回TreeSet的逆序排列的迭代器。 // 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器 public Iterator<E> descendingIterator() { return m.descendingKeySet().iterator(); } // 返回TreeSet的大小 public int size() { return m.size(); } // 返回TreeSet是否为空 public boolean isEmpty() { return m.isEmpty(); } // 返回TreeSet是否包含对象(o) public boolean contains(Object o) { return m.containsKey(o); } // 添加e到TreeSet中 public boolean add(E e) { return m.put(e, PRESENT)==null; } // 删除TreeSet中的对象o public boolean remove(Object o) { return m.remove(o)==PRESENT; } // 清空TreeSet public void clear() { m.clear(); } // 将集合c中的全部元素添加到TreeSet中 public boolean addAll(Collection<? extends E> c) { // Use linear-time version if applicable if (m.size()==0 && c.size() > 0 && c instanceof SortedSet && m instanceof TreeMap) { //把C集合强制转换为SortedSet集合 SortedSet<? extends E> set = (SortedSet<? extends E>) c; //把m集合强制转换为TreeMap集合 TreeMap<E,Object> map = (TreeMap<E, Object>) m; Comparator<? super E> cc = (Comparator<? super E>) set.comparator(); Comparator<? super E> mc = map.comparator(); //如果cc和mc两个Comparator相等 if (cc==mc || (cc != null && cc.equals(mc))) { //把Collection中所有元素添加成TreeMap集合的key map.addAllForTreeSet(set, PRESENT); return true; } } return super.addAll(c); } // 返回子Set,实际上是通过TreeMap的subMap()实现的。 public NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) { return new TreeSet<E>(m.subMap(fromElement, fromInclusive, toElement, toInclusive)); } // 返回Set的头部,范围是:从头部到toElement。 // inclusive是是否包含toElement的标志 public NavigableSet<E> headSet(E toElement, boolean inclusive) { return new TreeSet<E>(m.headMap(toElement, inclusive)); } // 返回Set的尾部,范围是:从fromElement到结尾。 // inclusive是是否包含fromElement的标志 public NavigableSet<E> tailSet(E fromElement, boolean inclusive) { return new TreeSet<E>(m.tailMap(fromElement, inclusive)); } // 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。 public SortedSet<E> subSet(E fromElement, E toElement) { return subSet(fromElement, true, toElement, false); } // 返回Set的头部,范围是:从头部到toElement(不包括)。 public SortedSet<E> headSet(E toElement) { return headSet(toElement, false); } // 返回Set的尾部,范围是:从fromElement到结尾(不包括)。 public SortedSet<E> tailSet(E fromElement) { return tailSet(fromElement, true); } // 返回Set的比较器 public Comparator<? super E> comparator() { return m.comparator(); } // 返回Set的第一个元素 public E first() { return m.firstKey(); } // 返回Set的最后一个元素 public E first() { public E last() { return m.lastKey(); } // 返回Set中小于e的最大元素 public E lower(E e) { return m.lowerKey(e); } // 返回Set中小于/等于e的最大元素 public E floor(E e) { return m.floorKey(e); } // 返回Set中大于/等于e的最小元素 public E ceiling(E e) { return m.ceilingKey(e); } // 返回Set中大于e的最小元素 public E higher(E e) { return m.higherKey(e); } // 获取第一个元素,并将该元素从TreeMap中删除。 public E pollFirst() { Map.Entry<E,?> e = m.pollFirstEntry(); return (e == null)? null : e.getKey(); } // 获取最后一个元素,并将该元素从TreeMap中删除。 public E pollLast() { Map.Entry<E,?> e = m.pollLastEntry(); return (e == null)? null : e.getKey(); } // 克隆一个TreeSet,并返回Object对象 public Object clone() { TreeSet<E> clone = null; try { clone = (TreeSet<E>) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(); } clone.m = new TreeMap<E,Object>(m); return clone; } // java.io.Serializable的写入函数 // 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { s.defaultWriteObject(); // 写入比较器 s.writeObject(m.comparator()); // 写入容量 s.writeInt(m.size()); // 写入“TreeSet中的每一个元素” for (Iterator i=m.keySet().iterator(); i.hasNext(); ) s.writeObject(i.next()); } // java.io.Serializable的读取函数:根据写入方式读出 // 先将TreeSet的“比较器、容量、所有的元素值”依次读出 private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden stuff s.defaultReadObject(); // 从输入流中读取TreeSet的“比较器” Comparator<? super E> c = (Comparator<? super E>) s.readObject(); TreeMap<E,Object> tm; if (c==null) tm = new TreeMap<E,Object>(); else tm = new TreeMap<E,Object>(c); m = tm; // 从输入流中读取TreeSet的“容量” int size = s.readInt(); // 从输入流中读取TreeSet的“全部元素” tm.readTreeSet(size, s, PRESENT); } // TreeSet的序列版本号 private static final long serialVersionUID = -2479143000061671589L; }
TreeSet的按序读取需要使用迭代器进行访问,无法使用for循环。在迭代器中可选择使用foreach语句进行数据更改或者输出。同时,因为treeset是根据treemap进行访问的,所以在读取的时候,如果读取为空但是进行了数据访问的话是会报错的,所以这也是他一处需要注意的地方,在我本次作业的判断中就增加了账户读取为空的判断情况,需要详细分类讨论防止报错。
在此处贴一下本题使用treeset的进行重写compareTo的地方,其他的代码基本上与普通的书写没有什么区别,就不多贴代码了。
@Override public int compareTo(Object a) { User b = (User)a; double num1 = Double.parseDouble(this.number); double num2 = Double.parseDouble(b.getNumber()); if(num1>num2) return 1; else if(num2>num1) return -1; return 0; }
因为是对电话号码进行排序,所以按照树集中compareto的比较方法,需要返回1,-1,0来进行排序储存。
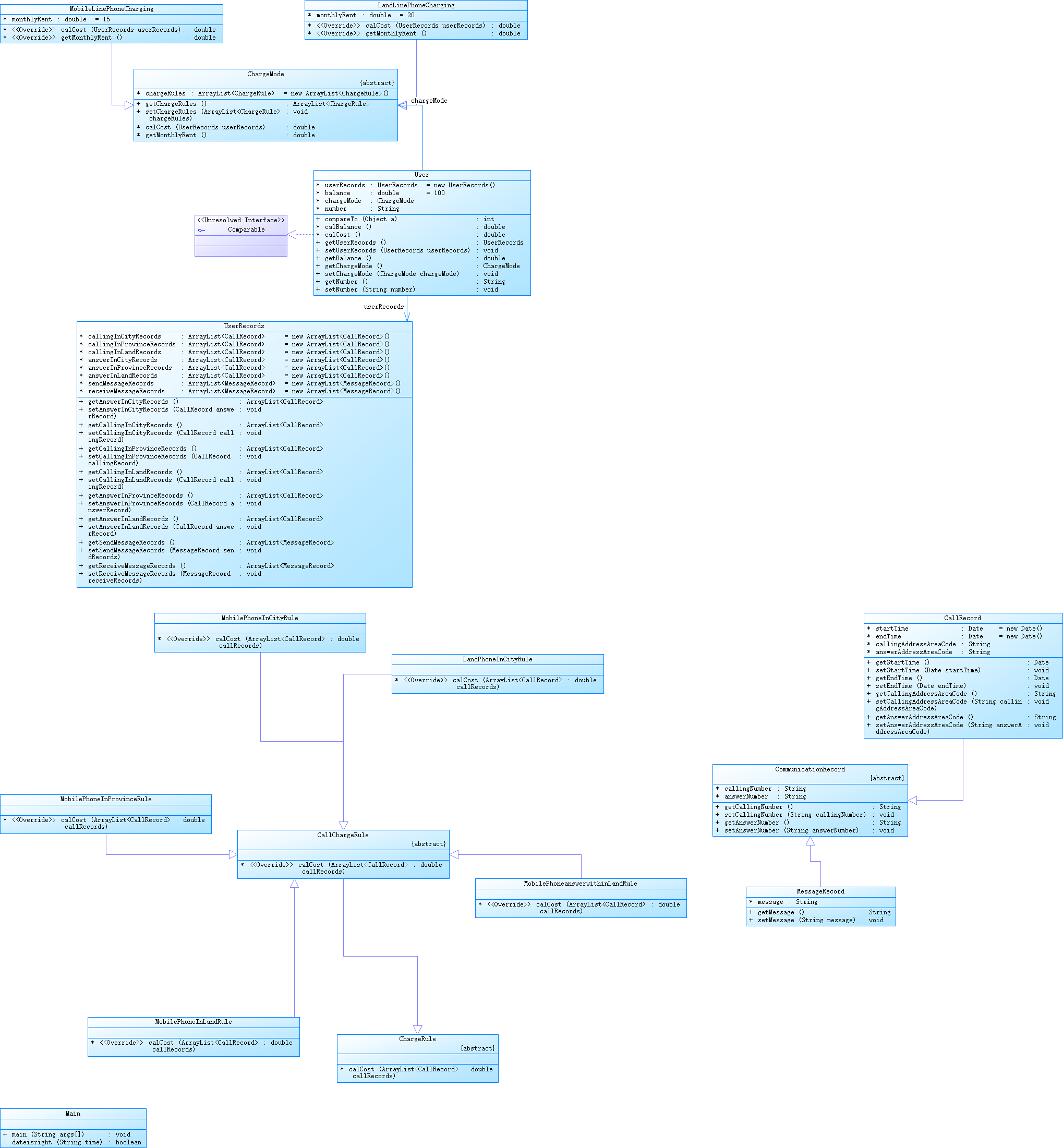
类图:

类图就是按照所给的类图进行i书写,因为题目中没有对接打电话记录的访问,因此在提交作业的时候将一部分代码注释了,减少运行压力,同时因为一些bug,接打电话的记录函数并不完善,所以没有放上去。
在正则表达式方面,对多用户的错误输入还是有部分错误,后期发现是因为没有对闰年进行判断,因此少了部分测试点的分数。
分析图:
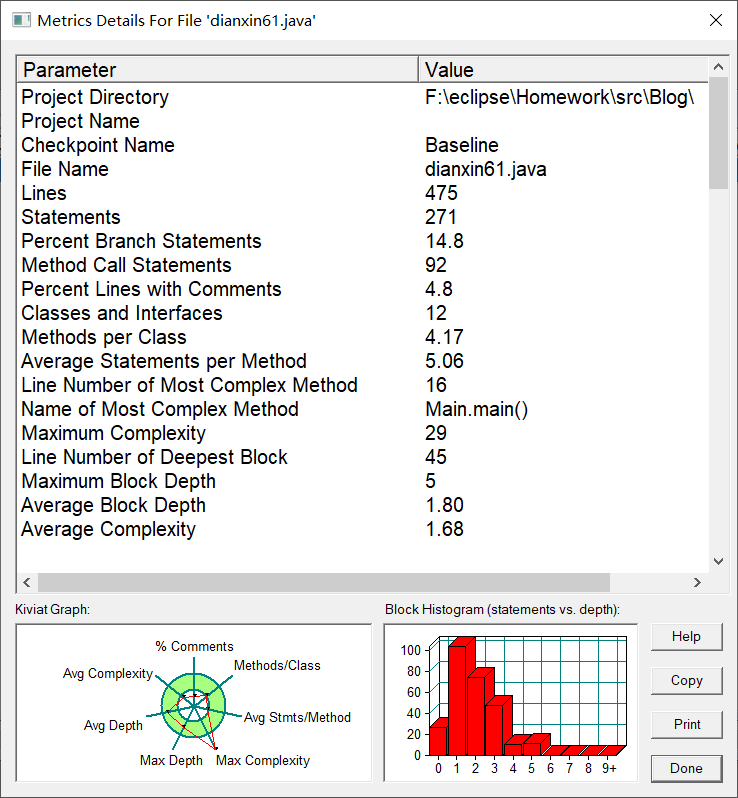
- 第七次大作业 -- 电信计费系列2-手机+座机计费
本次作业新增了手机计费方式,同时要求了对通话记录的访问。同时本次计费的储存方式进行了更改,这次换了一种方法理解题目,所以将题一中储存incity inprovince inland的几个类进行了更改,单独记录手机或座机的打出地与接听地,让后面手机漫游接听的判断简化,不容易混乱,同时也简化了ArrayList的储存与访问。
同时对于输入字符串的切割储存也有了新的模式,本次作业选择在程序进行的一开始就对输入字符串进行拆分储存,分门别类存入number数组time数组,同时对时间的判断更新了对闰年的判断以及对错误时间的判断。
类图:
分析图:
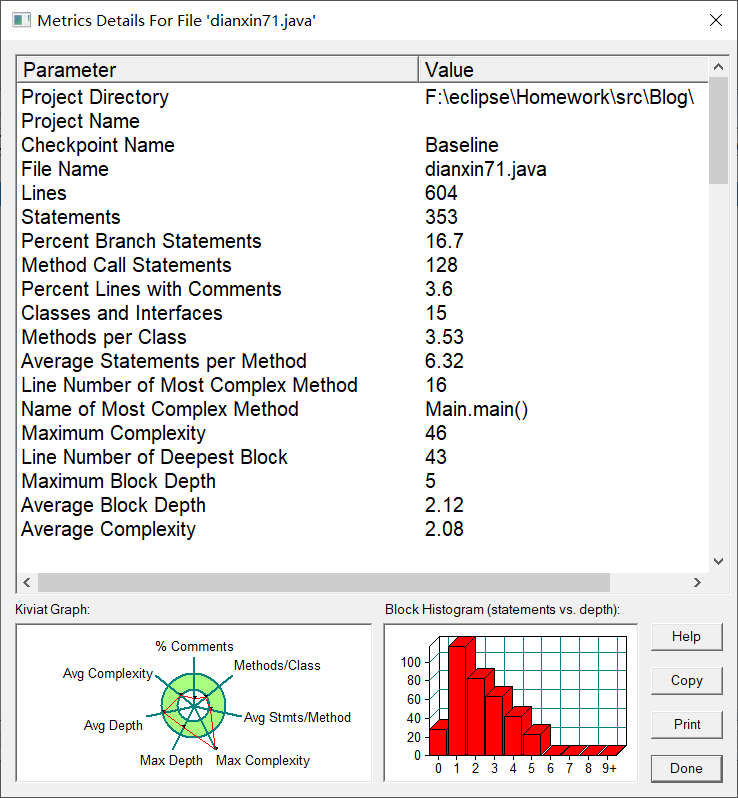
本次作业大多数内容与第一次电信收费内容一致,书写方式基本都是一致的,所以没有特别新增或者更改函数与方法,只是在第一题的基础上新增了对手机用户的创建以及收费标准。
- 第八次大作业 -- 电信计费系列3-短信计费
本次作业不同于前两次电话通信,本次为短信计费,相较于前两次电话拨打简单了许多,只需要对字符串进行判断以及计数就行。
类图:
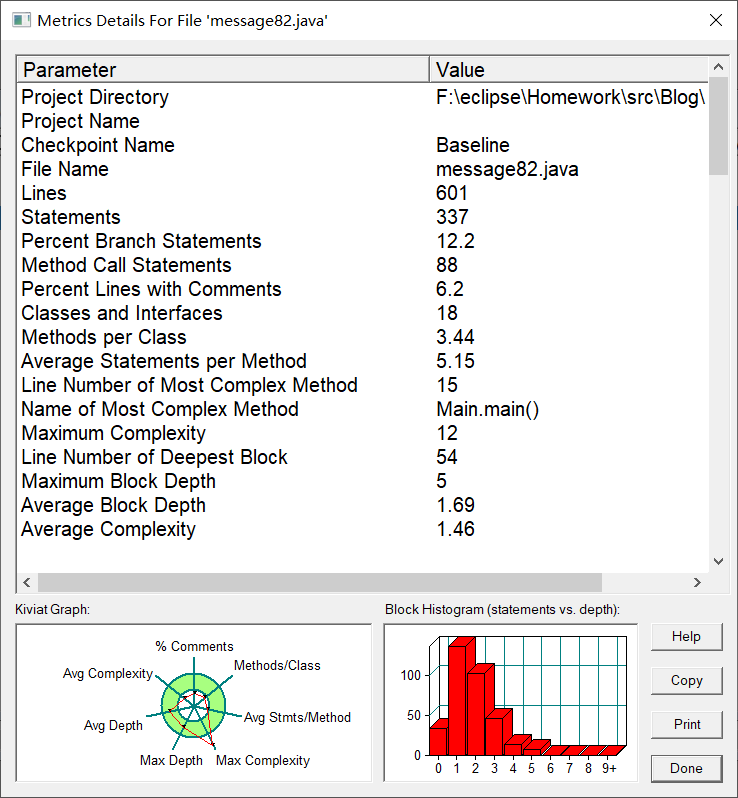
分析图:
-
踩坑心得
- 大作业的计算几何让我深深认知到了我对几何计算方面的不足,暑假会抽时间去学习一下有关于计算机图形学的相关知识。
- 电信计费系列作业让我学会了一些集合的运用,比如sortedset 和 treeset,让我了解了不同的set之间的关系和区别,虽然treeset在计算等方面的速度不如hashset,但是树集的指定数据排序确实是一个很好用的工具,可以不用自己再多写排序方式。
- 这几次作业都使用到了正则表达式,让我对正则表达式的掌握更进一步了,以前的作业需要参考或者询问别的同学正则表达式的相关写法,但是这几次作业基本上都能够轻松写出来,并且进行优化,这对我来说是比较大的进步。
-
改进建议
- 首先是正则表达式,虽然说已经能比较熟练的写出来,但是写出的正则表达式仍有一些无法过测试点的bug,在以后的书写中害得不断改进,丰富自己对正则表达式的了解。
- Java是一个工具类函数比较多的语言,要熟练掌握和使用还需要不断的学习,在这几次作业中,我学到了集合中的小小一部分,但是还有很多有自己特色的set没有进行深入学习,包括本次博客中提到的树集,我也只了解了小小一部分,但是树集还有很多功能是我没有了解到的,希望可以在之后的学习中进一步了解这些内容。
-
总结
10到16周的Java学习可以说是特别的充实,学到了许多C语言没有接触到的工具类函数,对面向对象语言有了全新的认知,但是因为期末考试的原因,没有办法进行系统的学习,都是挑选式学习,只学习了需要使用的部分,对于大部分内容都还是一知半解,希望可以不断学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号