python脚本实现短剧配音
1 功能描述
输入:小说文本(txt格式),通过python库函数生成音频文件(MP3格式),配音可通过在文本中加入指定提示词切换不同音源。
2 实现方式
有两种实现方式:
(1)tts库:可以离线生成,可调整生成音频的语速,但生成的音频机械感重,通常情况下仅有一种windows系统自带的声音引擎SAPI5,可以自行安装其他语音包来切换音源;
(2)edge-tts库:本质是调用edge浏览器的的音源完成配音,所以需要安装edge浏览器并联网,生成的音频富有感情。
3 功能实现
3.1 tts库生成
(1)安装支持包
pip install pyttsx3
(2)创建示例文稿testfile.txt
这是一段示例文稿,文稿内容可以自定义。
(3)创建生成脚本pydemo-tts.py
脚本文件要与示例文稿testfile.txt在同一路径下,运行脚本生成的音频也会保存到当前路径下。
点击查看代码
import pyttsx3
INPUT_FILE = "testfile.txt"
TEMPOUTPUT_DIR = "outputAudios"
OUTPUT_FILE = "generatefile.mp3" #可以生成mp3格式或wav格式
with open(INPUT_FILE, "r", encoding="utf-8") as f:
text = f.read()
engine = pyttsx3.init()
# engine.say(text) #可以在生成时播放生成的语音
# rate:设置语速
# volume:设置音量
# voice:设置声音引擎
engine.setProperty('rate', 180) # 语速
engine.setProperty('volume', 0.9) # 音量
engine.save_to_file(text,OUTPUT_FILE)
engine.runAndWait()
print("音频文件已生成!")
(4)运行效果


3.2 edge-tts库生成
3.2.1 环境配置
(1)若未安装Microsoft edge浏览器则需要先安装浏览器。
(2)安装支持包:
① 直接使用pip自动安装edge-tts包:
pip install edge-tts
② 我的程序脚本中,会根据提示词切换不同音源,生成多个音频,还需要安装ffmpeg将多个音频合成一个,ffmpeg包的的zip下载地址:https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip
下载后解压,我的解压路径如下:
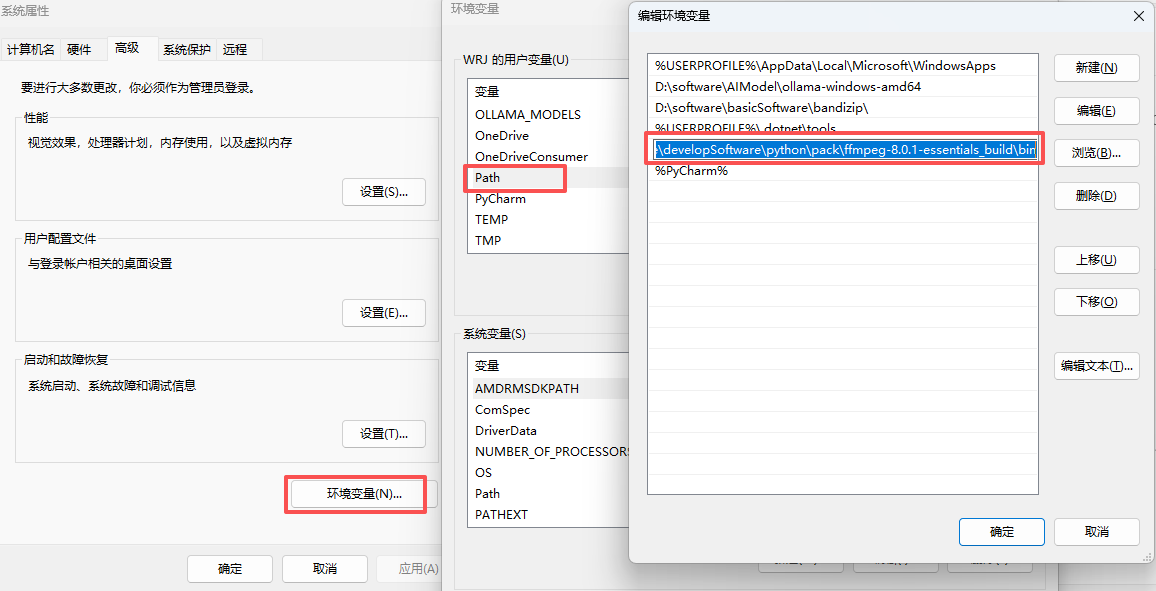
③ 将...\pack\ffmpeg-8.0.1-essentials_build\bin路径添加到环境变量PATH中:
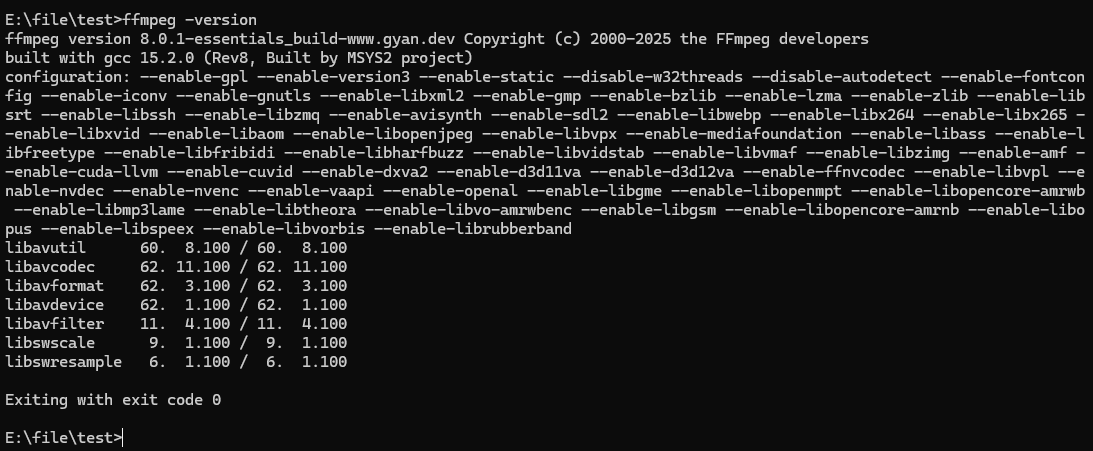
在CMD中输入ffmpeg -version可以验证是否配置成功,成功可正确输出版本号:
④ 安装pydub
pip install pydub
3.2.2 生成脚本
(1)创建示例文稿testfile.txt
【旁白】这是一段示例文稿,文稿内容可以自定义。
【男一】这是男一的声音。
【女一】这是女一的声音。
【男二】这是男二的声音。
【女二】这是女二的声音。
(2)创建生成脚本dubscript.py
点击查看代码
from pydub import AudioSegment
import asyncio
import edge_tts
import re
import os
from pydub import AudioSegment # 导入音频处理库
import imageio_ffmpeg
# --- 配置区域 ---
VOICE_PROFILES = {
"女一": {"voice": "zh-CN-XiaoyiNeural"}, # 晓伊,声音稍显成熟知性
"女二": {"voice": "zh-CN-XiaoxiaoNeural"}, # 晓晓,最常用,声音标准、温柔,适合大多数场景
# "女三": {"voice": "zh-CN-XiaohanNeural"}, # 晓涵,比较甜美、活泼
"男一": {"voice": "zh-CN-YunxiNeural"}, # 云希,声音比较稳重,适合纪录片或男声旁白
"男二": {"voice": "zh-CN-YunyangNeural"}, # 云扬,听起来像新闻主播,比较正式
"男三": {"voice": "zh-CN-YunjianNeural"}, # 云健,沉稳,适合讲故事
"旁白": {"voice": "zh-CN-YunxiNeural"} # 云希,声音比较稳重,适合纪录片或男声旁白
}
INPUT_FILE = "testfile.txt"
TEMPOUTPUT_DIR = "outputAudios"
OUTPUT_FILE = "generatefile.mp3"
os.makedirs(TEMPOUTPUT_DIR, exist_ok=True)
# 用于存储生成的音频文件路径
generated_files = []
# 异步函数:调用edge_tts库接口函数文本转语音
# text:输入文本字符串
# voice:选择声音音源
# output_file:生成的输出音频文件
async def text_to_speech(text, voice, output_file):
communicate = edge_tts.Communicate(text, voice)
await communicate.save(output_file)
return output_file
# 函数:调用ffmpeg库函数将多个音频合成一个
# file_list:音频列表
# output_path:合成视频输出路径
def merge_audio_files_ffmpeg(file_list, output_path):
print("正在使用 FFmpeg 合并音频...")
# 1. 创建一个临时文件列表 txt,告诉 ffmpeg 要合并哪些文件
# 注意:Windows 路径中如果有空格或特殊字符,需要用单引号括起来
with open("temp_list.txt", "w", encoding="utf-8") as f:
for file in file_list:
# 写入格式:file 'C:/path/to/audio.mp3'
f.write(f"file '{os.path.abspath(file)}'\n")
# 2. 构建 FFmpeg 命令
# -f concat: 告诉 ffmpeg 使用拼接模式
# -safe 0: 允许使用绝对路径
# -c copy: 直接复制流,不重新编码(速度快,无损质量)
cmd = f'ffmpeg -f concat -safe 0 -i temp_list.txt -c copy "{output_path}"'
# 3. 执行命令
print(f"执行命令: {cmd}")
os.system(cmd)
# 4. 清理临时文件
if os.path.exists("temp_list.txt"):
os.remove("temp_list.txt")
print(f"合并完成!最终音频: {output_path}")
# 异步函数:调用text_to_speech将INPUT_FILE文本转换为音频存储到TEMPOUTPUT_DIR路径下
async def process_novel_script():
global generated_files
with open(INPUT_FILE, "r", encoding="utf-8") as f:
text = f.read()
# 正则表达式:用于识别音源提示
pattern = r'【([^】]+)】([^【]+)'
matches = re.findall(pattern, text)
tasks = []
for i, (character, dialogue) in enumerate(matches):
clean_dialogue = dialogue.strip()
# 选择声音
if character in VOICE_PROFILES:
voice_name = VOICE_PROFILES[character]["voice"]
else:
voice_name = VOICE_PROFILES["旁白"]["voice"] # 默认旁白
output_file = os.path.join(TEMPOUTPUT_DIR, f"segment_{i:03d}.mp3")
generated_files.append(output_file) # 记录文件名,用于后续合并
# print(f"[{character}] -> {clean_dialogue}")
task = text_to_speech(clean_dialogue, voice_name, output_file)
tasks.append(task)
# 先生成所有音频片段
await asyncio.gather(*tasks)
print("所有音频片段生成完毕。")
if __name__ == "__main__":
# 运行异步处理
asyncio.run(process_novel_script())
# 合并音频
# 检查是否有生成的文件
if generated_files:
# 确保文件按顺序排列(因为文件名有000, 001编号)
generated_files.sort()
merge_audio_files_ffmpeg(generated_files, OUTPUT_FILE)
else:
print("未生成任何音频文件。")
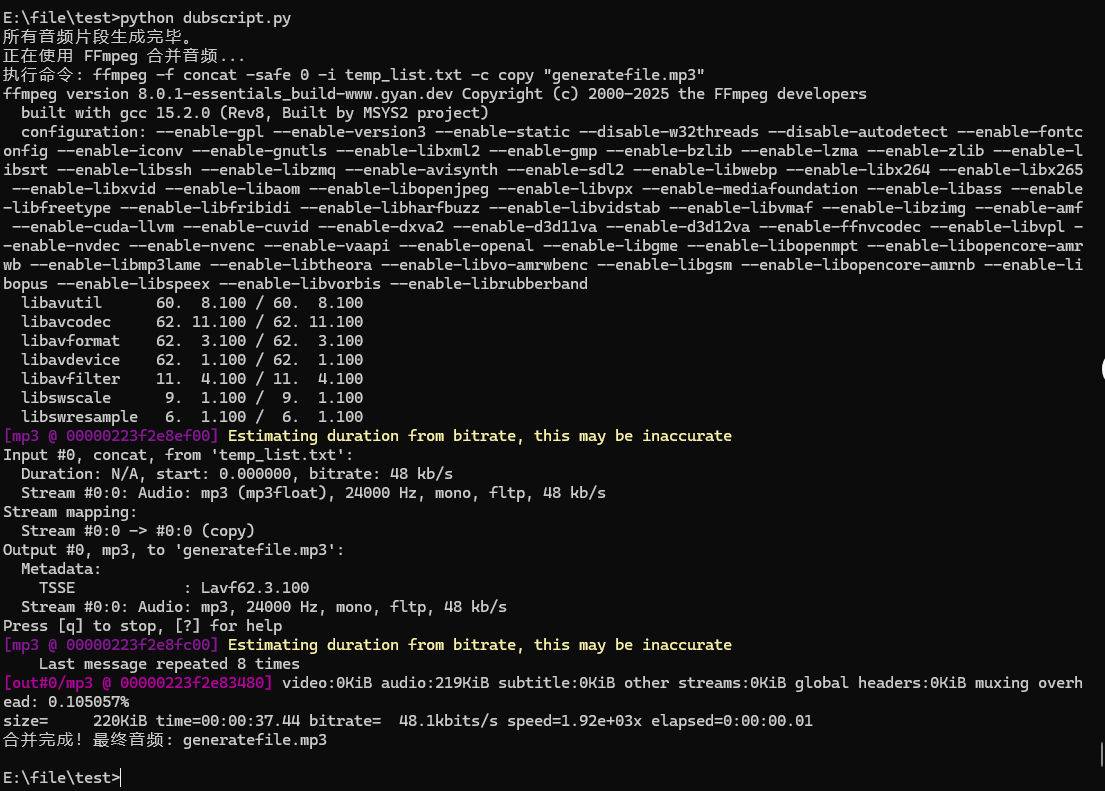
(3)运行效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号