linux正则表达式初探
为什么要学习正则表达式?
简单而言,仅仅用通配符无法满足处理字符的需求,这时候就是正则表达式大展身手的机会。相较而言,正则表达式比通配符更灵活,也更强大。
我们在网站注册用户的时候,网站一般会对用户密码做出格式要求,比如只允许使用大小写字母、下划线、减号和数字并且8≤密码字符长度≤24。这个时候必须要使用正则表达式来起到规范格式的作用。
^[a-zA-Z0-9_-]{8,24}$ # 看到这一串是不是还以为乱码了?
正则表达式描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
需要说明的是,正则表达式是一种表示方法,支持该方法的程序就可以用正则表达式来处理字符串。
语系对正则表达式的影响
二进制计算机记录的都是0和1,屏幕输出可以阅读的文字是根据编码表转换而来的。不同语系的编码顺序可能存在区别,所以在使用正则表达式时,需要注意系统语系。
-
C : 0 1 2 3 4 … A B C D … Z a b c d … z
-
zh_CN.big5 : 0 1 2 3 4 … a A b B c C d D … z Z
若使用[A-Z]选取大写字母,在zh_CN.big5语系下,会把除了大写字母外从b-z的小写字母也会找出来。(似乎采用UTF-8编码方式会较少的遇到这个问题?有待研究)
如何规避语系对正则表达式的影响
使用一些特殊符号:
| [:alnum:] | 代表英文大小写字母和数字 |
| [:alpha:] | 仅代表英文字母 |
| [:blank:] | 代表空格或tab |
| [:cntrl:] | 代表控制键,ctrl tab del |
| [:digit:] | 仅代表数字 |
| [:graph:] | 与 [:blank:] 相反 |
| [:lower:] | 小写字母 |
| [:upper:] | 大写字母 |
| [:print:] | 代表可以被打印出来的字符 |
| [:punct:] | 标点 |
| [:space:] | 代表任意可产生空白的字符,如空格 tab CR回车 |
| [:xdigit:] | 16进制数字类型,0-9,A-F,a-f |
基本型正则表达式的元字符
^chars # 匹配的字符串在行首(^代表行首)
chars$ # 匹配的字符串在行末($代表行末)
[list] # 匹配一个列表中存在的字符。如a[bc]d可以匹配到abd或acd,无法匹配到abcd
[^list] # 匹配一个列表中不存在的字符,注意和^chars区分
[n1-n2] # 匹配一个从n1(含)到n2(含)字符之间所有的连续字符,这里的连续指的是在ASCII编码上的连续,要注意语系问题!
char* # 星号代表重复0到任意多个星号之前的字符
. # 代表有一个任意字符,如a.c可以匹配到abc\azc\a空格c,但不能匹配到ac
\ # 转义符,去掉特殊符号所代表的意义
.*联用表示零个或多个任意字符
扩展型正则表达式的元字符
char+ # 匹配加号之前的字符一次或多次
char? # 匹配问号之前的字符零次或一次
| # or的意思
() # 分组匹配,如搜寻glad或good,可以这样表达:egrep -n 'g(la|oo)d' filename
()+ # 将组内的字符匹配一次或多次,比如查找AxyzxyzxyzxyzC,可以用egrep 'A(xyz)+C'
char{} # 表示匹配模式中前面字符的期望个数。如'r.{2}t’ 匹配以r开头,后面跟两个任意字符,最后以t结尾的任何单词。花括号可以指定区间,char{2,5}表示匹配前面的字符最少2次,最多5次。自行理解char{2,}和char{,5}。
正则表达式的使用
新建文本文件取名REtest.txt,填充内容如下:
taste. test teas ts I am grt I am grot I am groot! I am grooooot!
I am groooot I am groooooot? deep. dump decamp dp
d
1. 匹配以t开头的行

2. 匹配以p结尾的行

3. 匹配以t开头中间是a或e后跟s的字符串所在行

4. 匹配以t开头中间有零个或任意个字符后跟s的字符串所在行,注意和3比较
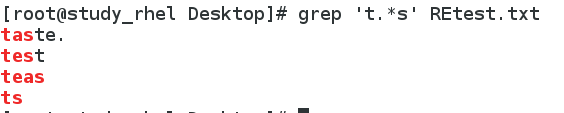
5. 匹配gr中间有零个或任意个o后跟t的字符串所在行
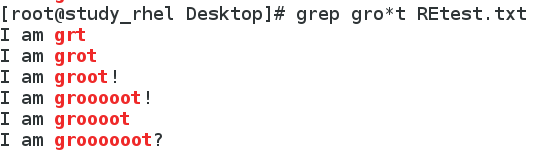
6. 匹配d后跟有一个字符的字符串所在行 # 注意结果中没有单独的d字母所在行
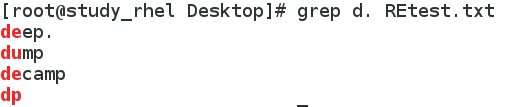
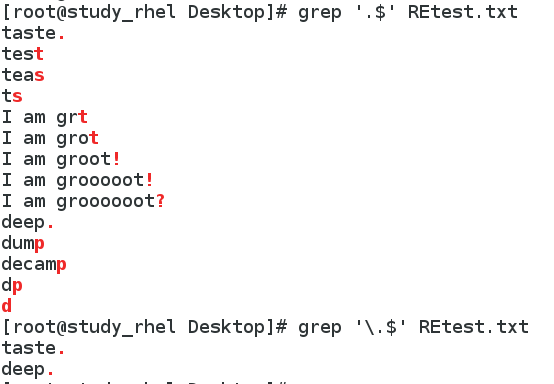
7. 匹配以.结尾的行,注意转义符的使用
8. 匹配gr开头后跟的(oo)最少出现2次、最多出现3次,后跟t的字符串所在行,注意这里用了egrep
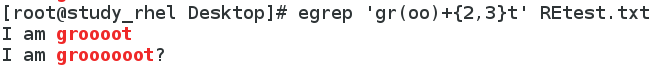
9. 匹配空白行并输出行号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号