Redis7底层数据结构源码级深度解析
Redis7底层数据结构源码级深度解析
🎯 核心设计理念:从源码看Redis的内存优化哲学
数据结构决定了性能的上限!!算法的优化只能说是锦上添花,选好数据结构至关重要
一、Redis对象系统源码剖析
1.1 对象元数据结构深度解析
核心源码:
struct redisObject {
unsigned type:4; // 对象类型(string/hash/list/set/zset)
unsigned encoding:4; // 编码方式(核心!决定底层数据结构)
unsigned lru:LRU_BITS; // LRU/LFU信息(内存回收策略)
int refcount; // 引用计数(内存管理)
void *ptr; // 指向实际数据结构的指针
};
源码级分析:
type:4使用4位存储对象类型,说明Redis最多支持16种对象类型encoding:4同样使用4位,支持16种编码方式,目前使用了12种lru:LRU_BITS用于内存淘汰策略,LRU和LFU复用这24位refcount引用计数实现内存共享和自动回收ptr万能指针,指向具体的底层数据结构
1.2 编码类型宏定义详解
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skip list */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
演进历史分析:
ZIPMAP/ZIPLIST是Redis早期的紧凑数据结构,已被listpack取代EMBSTR是Redis对短字符串的特殊优化,减少内存分配次数LISTPACK是新一代紧凑数据结构,解决了ziplist的连锁更新问题
| Redis 版本 | string | set | zset | list | hash |
|---|---|---|---|---|---|
| Redis 6 | SDS(动态字符串) | intset+hashtable | skiplist+ziplist | quicklist+ziplist | hashtable+ziplist |
| Redis 7 | SDS | intset+listpack+hashtable | skiplist+listpack | quicklist+listpack | hashtable+list |
二、String类型:SDS字符串源码级实现
2.1 SDS结构体源码分析
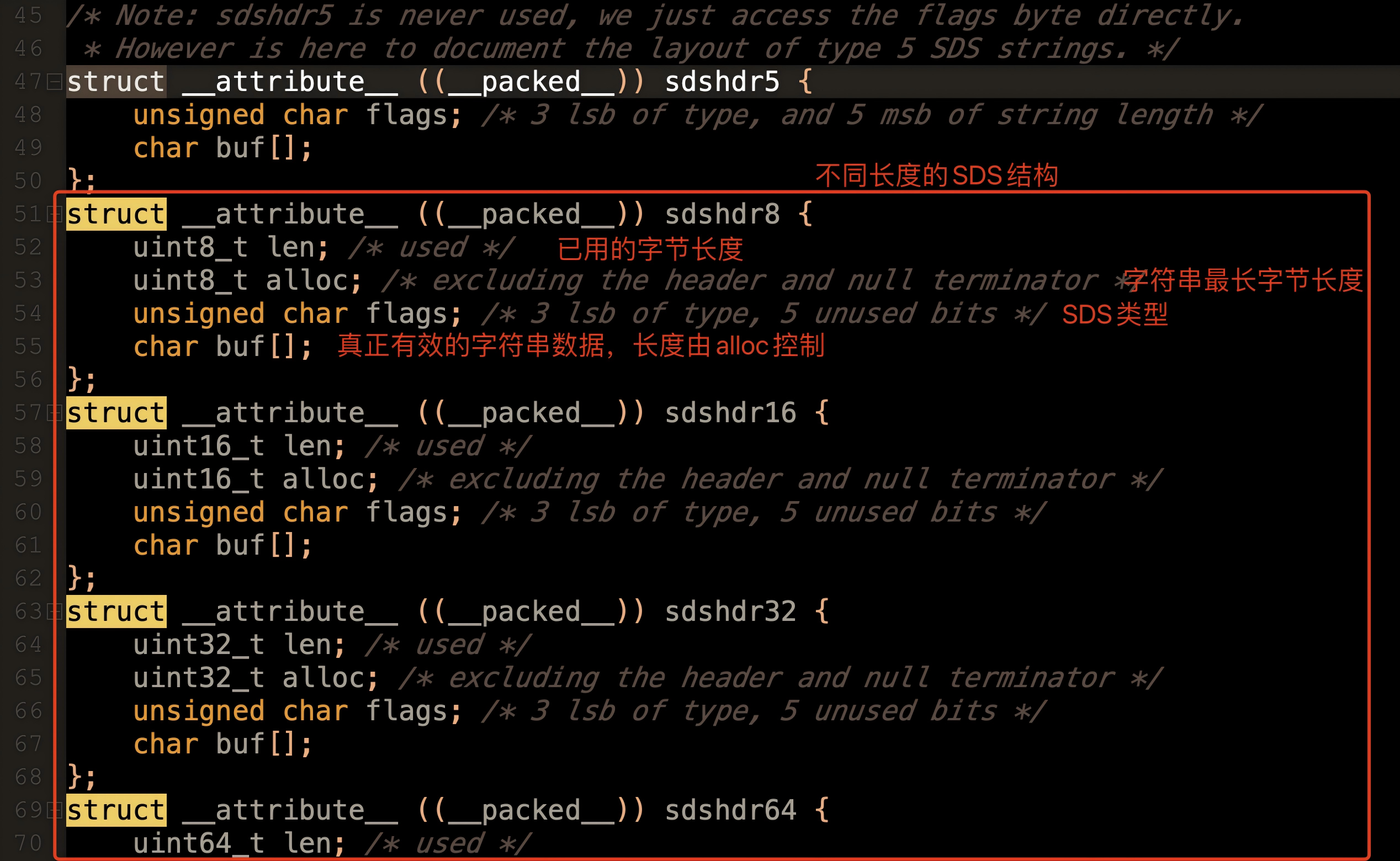
// EMBSTR编码内存布局(连续内存)
[redisObject(16字节)][SDS头部][字符串数据]\0
// RAW编码内存布局(分离内存)
[redisObject] -> 指针 -> [SDS头部][字符串数据]\0
EMBSTR:将新创建的SDS对象直接分配在对象自己的内存后面,内存读取效率更高
raw类型的处理方式就是单独创建⼀个SDS,然后将robj的ptr指向这个SDS
2.2 三种编码的源码级选择逻辑
// 根据字符串特征选择编码的伪代码
if (is_integer_string(str)) {
// 整数字符串:"123" -> 直接存储为long类型
robj->encoding = OBJ_ENCODING_INT;
robj->ptr = (void*)long_value;
} else if (len <= 44) { // 44字节是经验阈值
// 短字符串:使用EMBSTR,一次性分配内存
robj->encoding = OBJ_ENCODING_EMBSTR;
// 分配连续内存:redisObject + SDS + 数据
} else {
// 长字符串:使用RAW,分离分配
robj->encoding = OBJ_ENCODING_RAW;
// 分别分配redisObject和SDS
}
为什么是44字节?
- redisObject占16字节
- SDS头部至少占3字节(len+alloc+flags)
- 字符串数据+1字节\0
- 内存对齐考虑:总共64字节是常见的内存页大小
2.3 实战验证编码选择
# 测试INT编码
127.0.0.1:6379> set k2 1
127.0.0.1:6379> OBJECT encoding k2 # "int"
# 源码分析:Redis检测到"1"是纯数字,直接存储为long类型
# 测试EMBSTR编码
127.0.0.1:6379> set k1 v1
127.0.0.1:6379> OBJECT encoding k1 # "embstr"
# 源码分析:"v1"长度2字节 <= 44,使用EMBSTR
# 测试RAW编码
127.0.0.1:6379> set k3 "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
127.0.0.1:6379> OBJECT encoding k3 # "raw"
# 源码分析:长度超过44字节,使用RAW编码
三、Hash类型:listpack与hashtable转换机制
3.1 listpack内部结构源码分析
# 通过DEBUG命令观察Hash的内部结构
127.0.0.1:6379> hset user:1 id 1 name roy
127.0.0.1:6379> OBJECT encoding user:1 # "listpack"
value数据少--》listpack,如果数据比较多--》hashtable
listpack是ziplist的升级版,ziplist是由连续内存块组成的顺序性数据结构,类似数组
listpack vs 早期ziplist的改进:
- 解决了ziplist的连锁更新问题
- 每个元素独立记录长度信息
- 支持更高效的插入和删除操作
3.2 转换阈值源码逻辑
// Hash编码转换的触发条件
if (hash->entries > server.hash_max_listpack_entries ||
max_value_len > server.hash_max_listpack_value) {
// 转换为hashtable编码
hashTypeConvert(hash, OBJ_ENCODING_HT);
}
实战演示转换过程:
# 初始状态:使用listpack
127.0.0.1:6379> hset user:1 id 1 name roy
127.0.0.1:6379> OBJECT encoding user:1 # "listpack"
# 修改配置,降低转换阈值
127.0.0.1:6379> config set hash-max-listpack-entries 3
127.0.0.1:6379> config set hash-max-listpack-value 8
# 触发转换:value长度超过阈值
127.0.0.1:6379> hset user:1 name "royaaaaaaaaaaaaaaaa"
127.0.0.1:6379> OBJECT encoding user:1 # "hashtable"
# 触发转换:元素数量超过阈值
127.0.0.1:6379> hset user:2 id 1 name roy score 100 age 18
127.0.0.1:6379> OBJECT encoding user:2 # "hashtable"
3.3 hashtable源码结构
// Redis字典(hashtable)实现
typedef struct dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 两个哈希表,用于渐进式rehash
long rehashidx; // rehash索引,-1表示未进行rehash
unsigned long iterators; // 正在使用的迭代器数量
} dict;
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用于计算索引值
unsigned long used; // 已有节点数量
} dictht;
四、List类型:quicklist实现深度剖析
数据⽐较“⼩”的list类型,底层⽤listpack保存。数据量⽐较"⼤"的list类型,底层⽤quicklist保存
4.1 quicklist结构设计
# 观察List的编码转换
127.0.0.1:6379> config set list-max-listpack-size 2
127.0.0.1:6379> lpush l3 a1 a2 a3
127.0.0.1:6379> OBJECT encoding l3 # "quicklist"
listpack可以看成是⼀个数组(Array)结构,数组结构不利于lpush这样的操作。于是quicklist出现了,quicklist结合了链表与数组的优点
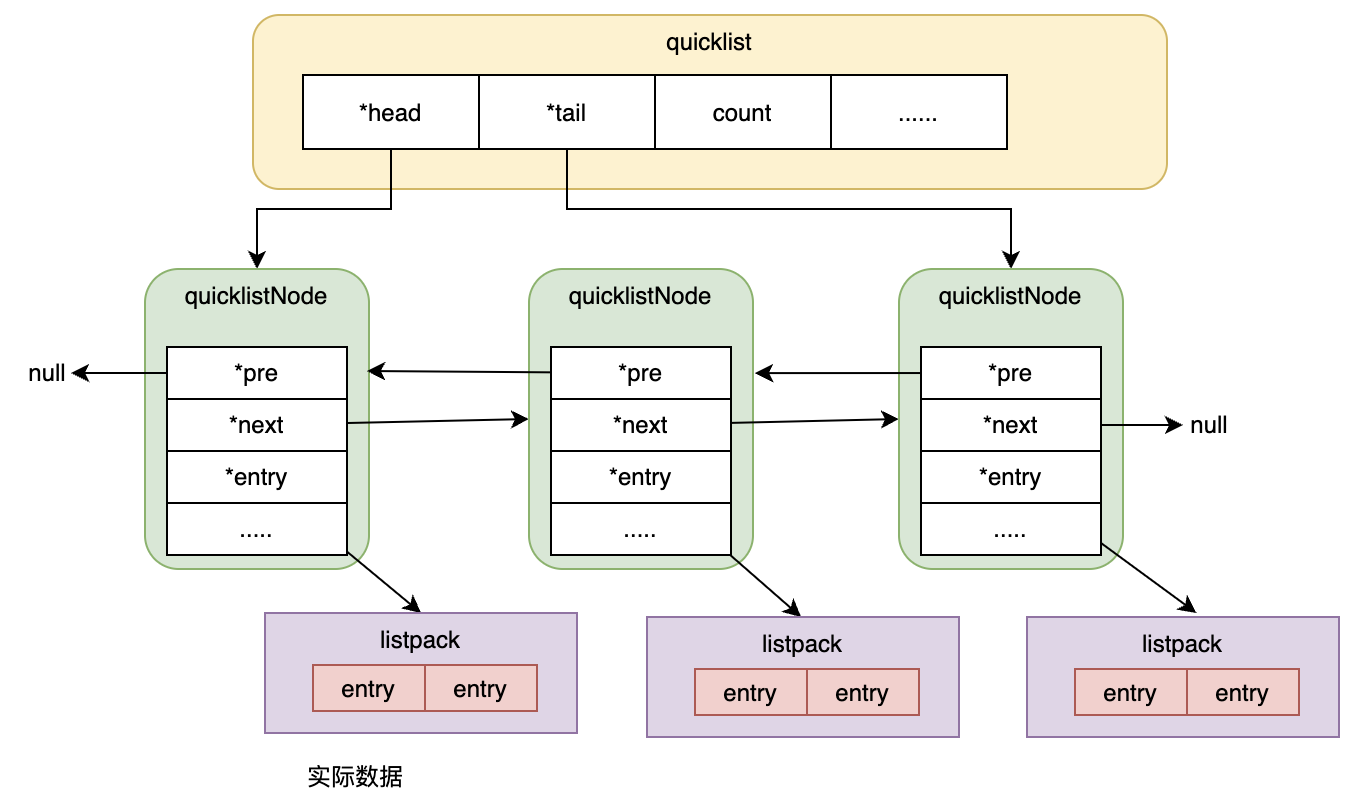
4.2 压缩策略源码分析
# List压缩配置详解
# list-compress-depth设置含义:
0: 不压缩(默认)
1: 压缩中间节点,保留头尾各1个节点
2: 压缩更深层的节点,保留头尾各2个节点
压缩算法选择:
- LZF压缩:轻量级压缩算法,压缩和解压速度快
- 压缩触发条件:节点被访问时检查,根据compress深度决定是否压缩
- 解压触发条件:访问被压缩的节点时自动解压
4.3 listpack大小配置源码逻辑
// list-max-listpack-size配置的含义
// 负数表示最大字节数,正数表示最大元素数量
-5: 64KB -4: 32KB -3: 16KB -2: 8KB -1: 4KB
正数n: 最多n个元素
// 源码中的处理逻辑
if (fill < 0) {
// 按字节数限制:(-fill) * 1024字节
max_bytes = (-fill) * 1024;
} else {
// 按元素数量限制:fill个元素
max_count = fill;
}
五、Set类型:intset源码级分析
5.1 intset内部结构
# 整数集合的紧凑存储
127.0.0.1:6379> sadd s1 1 2 3 4 5
127.0.0.1:6379> OBJECT encoding s1 # "intset"
intset源码结构:
typedef struct intset {
uint32_t encoding; // 编码方式:INT16_ENC, INT32_ENC, INT64_ENC
uint32_t length; // 元素数量
int8_t contents[]; // 柔性数组,存储实际元素
} intset;
intset的升级机制:
// 当新元素超出当前编码范围时,自动升级编码
// INT16_ENC -> INT32_ENC -> INT64_ENC
// 升级过程:
1. 重新分配内存,扩大编码空间
2. 将现有元素转换为新编码
3. 插入新元素
4. 更新encoding字段
5.2 Set编码选择源码逻辑
// Set编码选择的完整逻辑
if (所有元素都是整数 && 元素数量 <= set_max_intset_entries) {
// 使用intset编码
encoding = OBJ_ENCODING_INTSET;
} else if (元素数量 <= set_max_listpack_entries &&
最大元素长度 <= set_max_listpack_value) {
// 使用listpack编码
encoding = OBJ_ENCODING_LISTPACK;
} else {
// 使用hashtable编码
encoding = OBJ_ENCODING_HT;
}
实战验证:
# 整数集合:intset编码
127.0.0.1:6379> sadd s1 1 2 3 4 5
127.0.0.1:6379> OBJECT encoding s1 # "intset"
# 字符串集合:listpack编码
127.0.0.1:6379> sadd s2 a b c d e
127.0.0.1:6379> OBJECT encoding s2 # "listpack"
# 大集合:hashtable编码
127.0.0.1:6379> config set set-max-listpack-entries 2
127.0.0.1:6379> sadd s3 a b c d e
127.0.0.1:6379> OBJECT encoding s3 # "hashtable"
六、ZSet类型:skiplist实现深度剖析
6.1 双重数据结构源码分析
# 有序集合的两种编码
127.0.0.1:6379> zadd z1 80 a
127.0.0.1:6379> OBJECT encoding z1 # "listpack"
127.0.0.1:6379> config set zset-max-listpack-entries 3
127.0.0.1:6379> zadd z2 80 a 90 b 91 c 95 d
127.0.0.1:6379> OBJECT encoding z2 # "skiplist"
skiplist源码结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头节点和尾节点
unsigned long length; // 节点数量
int level; // 最大层数
} zskiplist;
typedef struct zskiplistNode {
sds ele; // 成员对象(字符串)
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(跨越的节点数)
} level[]; // 柔性数组,多层指针
} zskiplistNode;
6.2 跳表vs平衡树的源码级对比
为什么选择跳表而不是平衡树?
// 跳表的优势:
1. 实现简单:代码量少,易于维护
2. 范围查询高效:O(log n) + O(m)(m为结果数量)
3. 内存可控:通过概率控制层数,平均1.33倍内存开销
4. 并发友好:插入删除不影响其他节点的结构
// 平衡树的劣势:
1. 实现复杂:旋转操作复杂,容易出错
2. 范围查询需要中序遍历:O(log n) + O(m),但常数更大
3. 内存开销不确定:取决于树的平衡度
4. 并发困难:旋转操作需要锁保护
6.3 ZSet的双重结构优化
// ZSet同时包含dict和skiplist
typedef struct zset {
dict *dict; // 字典:成员 -> 分值的映射,O(1)查询
zskiplist *zsl; // 跳表:按分值排序,支持范围查询
} zset;
// 双重结构的优势:
1. ZSCORE操作:通过dict实现O(1)复杂度
2. ZRANGE操作:通过skiplist实现O(log n)复杂度
3. ZRANGEBYSCORE:通过skiplist实现高效范围查询
七、内存优化配置源码级详解
7.1 配置参数的源码定义
// Redis配置文件中的默认值
struct redisServer {
// Hash类型配置
int hash_max_listpack_entries; // 默认512
int hash_max_listpack_value; // 默认64字节
// List类型配置
int list_max_listpack_size; // 默认-2(8KB)
int list_compress_depth; // 默认0(不压缩)
// Set类型配置
int set_max_intset_entries; // 默认512
int set_max_listpack_entries; // 默认128
int set_max_listpack_value; // 默认64字节
// ZSet类型配置
int zset_max_listpack_entries; // 默认128
int zset_max_listpack_value; // 默认64字节
};
7.2 配置参数的业务含义
Hash配置分析:
hash-max-listpack-entries 512
含义:当Hash字段数 <= 512时,使用listpack编码
原因:小Hash用紧凑存储,内存效率极高
hash-max-listpack-value 64
含义:当所有Hash字段值长度 <= 64字节时,使用listpack编码
原因:避免大字段导致listpack过大,影响操作性能
List配置分析:
list-max-listpack-size -2
含义:每个listpack节点最大8KB
原因:平衡内存连续性和操作效率
list-compress-depth 0
含义:不压缩quicklist节点
原因:压缩会增加CPU开销,需要根据业务特点调整
7.3 内存优化实战源码
# 查看当前配置
127.0.0.1:6379> config get *max*
# 根据业务特点调优
# 场景1:社交关系(小对象多)
config set hash-max-listpack-entries 1000
config set set-max-listpack-entries 256
# 场景2:缓存系统(大对象多)
config set hash-max-listpack-value 128
config set list-max-listpack-size -1 # 4KB
# 场景3:计数器(整数多)
config set set-max-intset-entries 1024
八、性能监控与诊断源码级工具
8.1 OBJECT命令源码分析
# OBJECT命令的完整功能
127.0.0.1:6379> OBJECT help
1) OBJECT <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) ENCODING <key> # 查看编码方式
3) FREQ <key> # 查看访问频率(LFU)
4) IDLETIME <key> # 查看空闲时间(LRU)
5) REFCOUNT <key> # 查看引用计数
OBJECT ENCODING源码逻辑:
void objectCommand(client *c) {
robj *o;
if (!strcasecmp(c->argv[1]->ptr,"encoding") && c->argc == 3) {
o = lookupKeyRead(c->db,c->argv[2]);
if (o == NULL) {
addReply(c,shared.null[c->resp]);
return;
}
// 返回编码方式的字符串表示
addReplyBulkCString(c,strEncoding(o->encoding));
}
}
8.2 内存使用统计源码
# MEMORY命令详解
127.0.0.1:6379> MEMORY help
1) MEMORY <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) USAGE <key> [SAMPLES <count>] # 统计key的内存使用
3) STATS # 内存使用统计
4) PURGE # 清理内存
5) MALLOC-STATS # jemalloc统计
内存统计源码分析:
// MEMORY USAGE命令的实现
size_t objectComputeSize(robj *o, size_t sample_size) {
size_t size = 0;
switch(o->type) {
case OBJ_STRING:
// 字符串大小计算
size = sizeof(robj) + sdsAllocSize(o->ptr);
break;
case OBJ_LIST:
// 列表大小计算(遍历quicklist)
size = sizeof(robj) + quicklistGetMemoryUsage(o->ptr);
break;
// ... 其他类型
}
return size;
}
九、核心设计思想源码总结
9.1 渐进式优化哲学
通过分析PDF文档中的所有源码和示例,Redis的设计遵循以下原则:
// Redis内存优化的核心算法
if (数据量小) {
// 使用紧凑编码,极致节省内存
encoding = COMPACT_ENCODING;
} else if (数据量中等) {
// 平衡内存和性能
encoding = BALANCED_ENCODING;
} else {
// 使用高效结构,保证操作性能
encoding = EFFICIENT_ENCODING;
}
9.2 源码级的性能权衡
内存 vs CPU 的权衡:
listpack:节省内存,但操作复杂度O(n)
hashtable:内存开销大,但操作复杂度O(1)
选择策略:
- 小数据:内存优先,用listpack
- 大数据:性能优先,用hashtable
- 阈值可配置:根据业务特点调整
压缩 vs 解压的权衡:
quicklist压缩:
- 节省内存:特别是存储大量小元素时
- 增加CPU:访问时需要解压
- 策略:只压缩中间节点,头尾节点保持解压状态
9.3 从源码看Redis的进化
通过PDF文档中的示例和源码,我们可以看到Redis的演进历程:
Redis 2.x:简单数据结构(linkedlist、ziplist)
Redis 3.x:引入quicklist,优化List类型
Redis 5.x:引入listpack,替代ziplist
Redis 7.x:完善listpack应用,优化内存使用
演进方向:
1. 内存效率越来越高
2. 操作性能持续优化
3. 代码复杂度适中
4. 配置灵活性增强
总结:源码级理解Redis设计精髓
通过深入分析PDF文档中的源码片段、实战示例和配置详解,我们可以得出以下核心结论:
源码级洞察
-
对象系统:16字节的redisObject结构体,用4位编码字段实现了12种编码方式的智能切换
-
String优化:44字节阈值是内存对齐和CPU缓存效率的完美结合
-
Hash进化:从ziplist到listpack,解决了连锁更新问题,保持了内存紧凑性
-
List压缩:quicklist通过压缩中间节点,在内存和CPU之间找到平衡点
-
Set智能:intset/listpack/hashtable三种编码根据数据特征自动选择
-
ZSet双重:dict + skiplist的组合,实现了O(1)查询和O(log n)范围查询的完美统一
实战指导
# 源码级优化建议:
1. 理解数据特征 -> 预测编码方式
2. 监控内存使用 -> 调整配置阈值
3. 测试验证 -> 理论结合实际
4. 持续优化 -> 跟随业务发展
# 配置调优黄金法则:
small_data + few_fields -> 提高阈值,用紧凑编码
big_data + many_fields -> 降低阈值,用高效结构
mixed_scenario -> 平衡配置,监控调优
设计哲学
Redis的底层数据结构体现了智能适配的设计哲学:
- 小数据用紧凑结构:极致节省内存,牺牲少量CPU
- 大数据用高效结构:保证操作性能,接受内存开销
- 动态切换:根据数据特征自动选择最优结构
- 可配置:允许根据业务特点精细调优

 浙公网安备 33010602011771号
浙公网安备 33010602011771号