Hadoop入门 集群崩溃的处理方法
集群崩溃的处理方法
搞崩集群
hadoop102
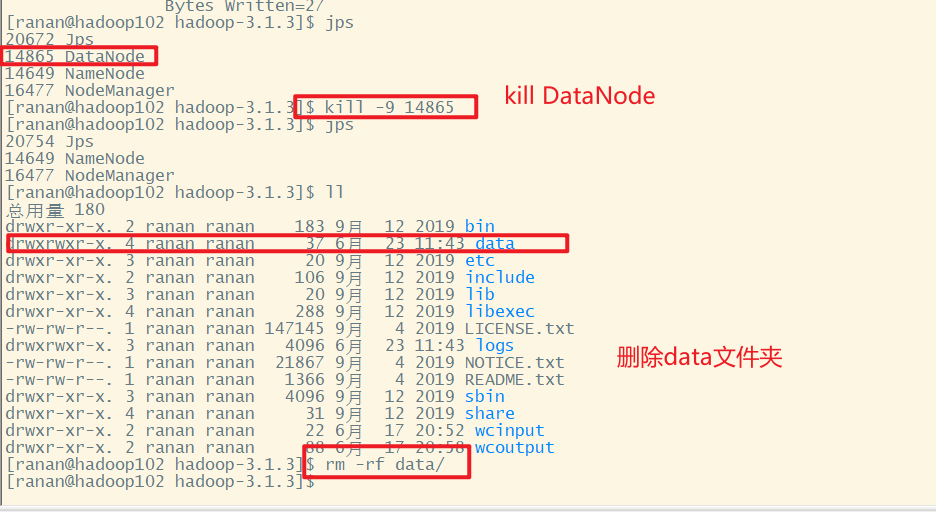
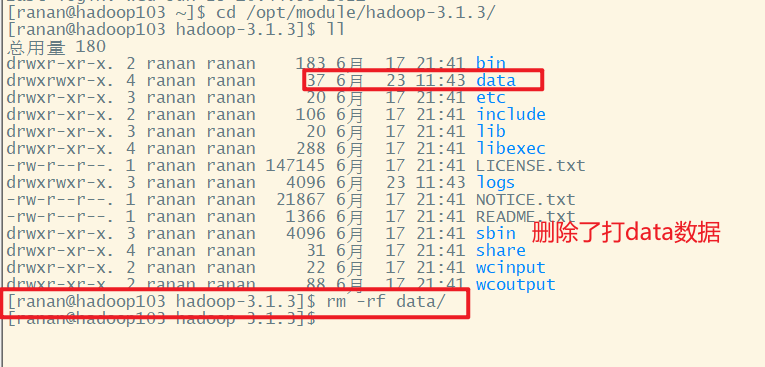
hadoop103
hadoop104

此时HDFS Web端的文件是不可以下载的,因为三个副本都删除了。
错误示范
最先想到的是格式化集群
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format

提示需要先停掉集群,正常情况下先把yarn停掉
[ranan@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh

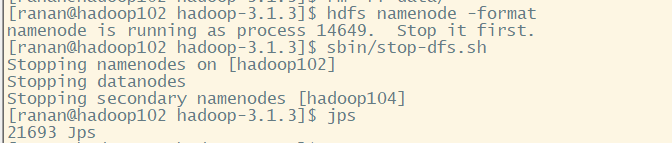
启动集群,发现集群正常启动,但是NameNode没了
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
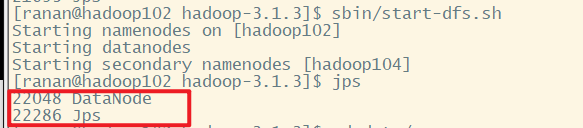
查看目录,发现删除了DataNode中的name
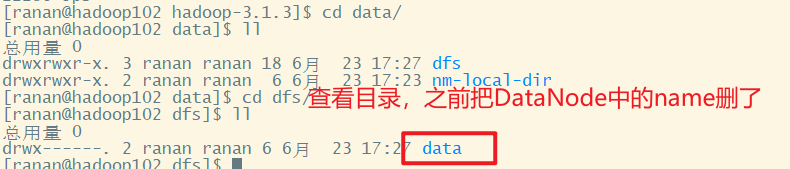
那就格式NameNode,之前并没有成功格式化。
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
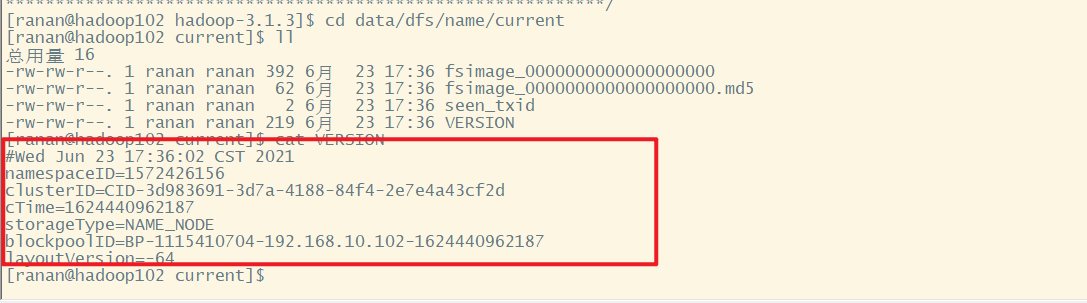
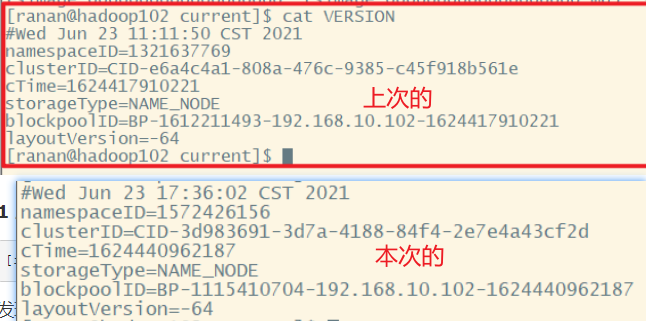
格式化之后,发现name文件夹有了,进去查看版本号。发现两次的版本号不一样。
[ranan@hadoop102 hadoop-3.1.3]$ cd data/dfs/name/current
[ranan@hadoop102 current]$ cat VERSION
此时进入HDFS网页,发现进不去了
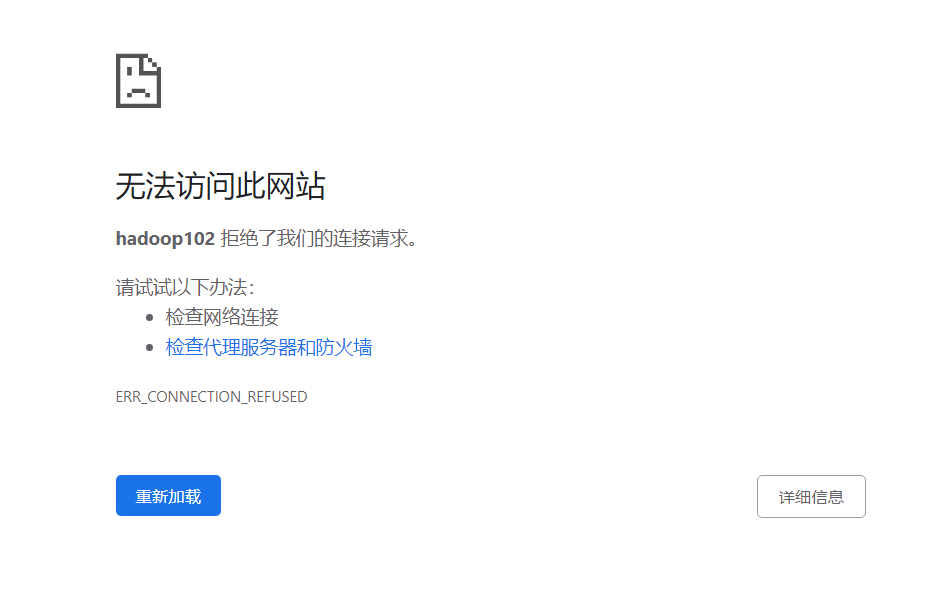
查看发现namenode还是没有启动

那该怎么办?
正确处理方法
1 回到hadoop的家目录
2 杀死进程
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
3 删除每个集群的data和logs
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data logs
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data logs
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data logs
4 格式化
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
5 启动集群
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
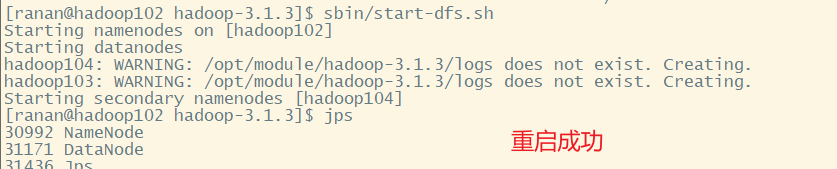
重启成功,但是数据都被清空了
总结
1.先停HDFS服务
2.清除所有节点的历史data和logs
3.格式化NameNode
4.重新启动
原因分析
格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
namenode,datanode都有自己的版本号。namenode和datanode是一一绑定的。
格式化以后的namenode是匹配不上没有格式化以前的datanode。
版本要能匹配的上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号