Hadoop入门 完全分布式运行模式-准备
Hadoop运行环境
Local Mode:测试偶尔使用
Pseudo-Distributed Mode:用的少
Full-Distreibuted Mode:通常使用
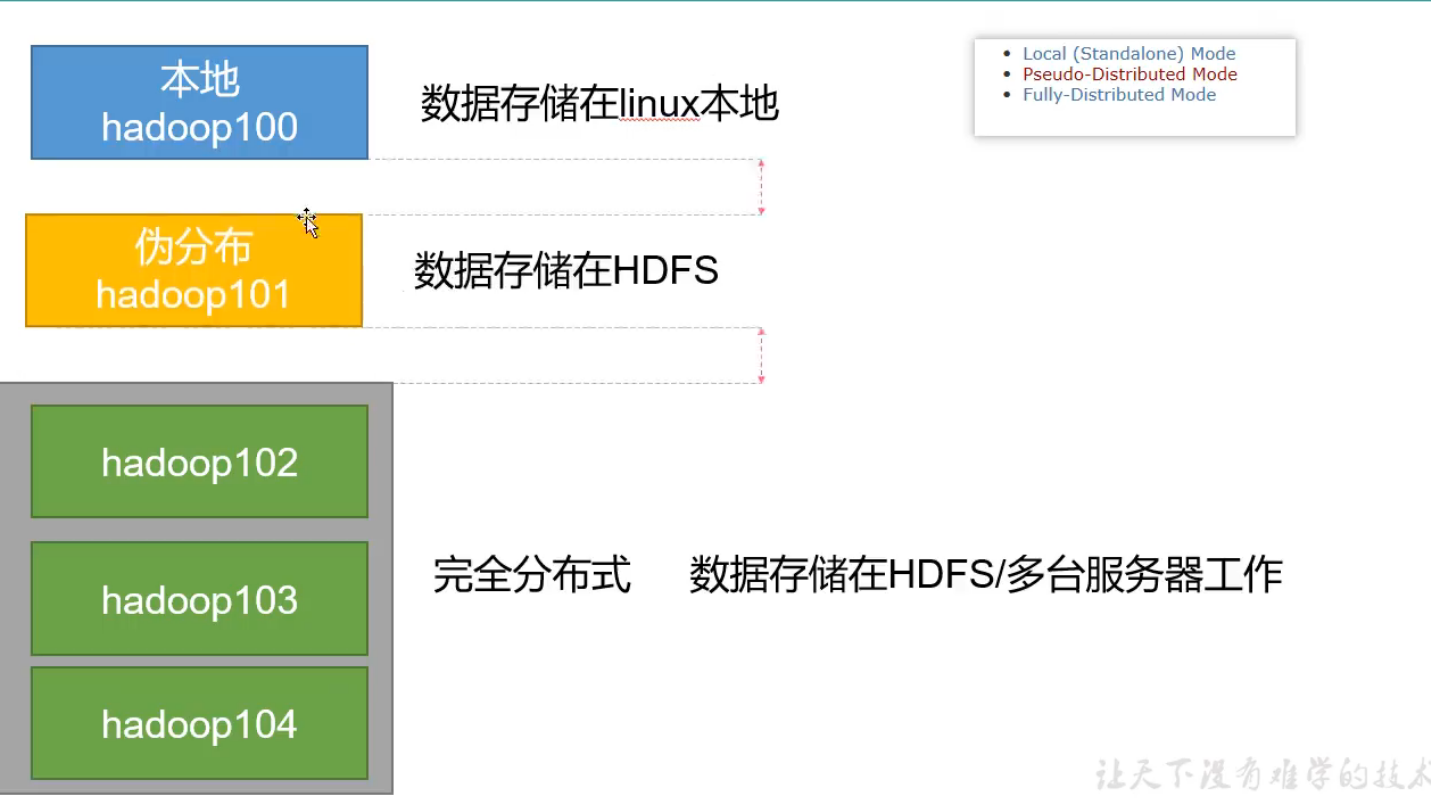
完全分布式运行模式(重点)
任务:
1.准备三台客户机(关闭防火墙、静态IP、主机名称) √
2.安装JDK
3.配置环境变量
4.安装Hadoop
5.配置环境变量
6.配置集群
7.单点启动
8.配置ssh
9.群起并测试集群
scp secure copy 安全拷贝
scp可以实现服务器与服务器之间的数据拷贝
基本语法

1 hadoop102上的JDK文件推给103
前提:在hadoop102、hadoop103、hadoop104都已经创建好了/opt/module、/opt/sofeware两个目录 并且修改为ranan:ranan
opt下: sudo chown ranan:ranan moudule/ sofeware/
在hadoop102上,将hadoop102中/opt/module/jdk1.5目录拷贝到103上
scp -r jdk1.8.0_212/ ranan@hadoop103:/opt/module/

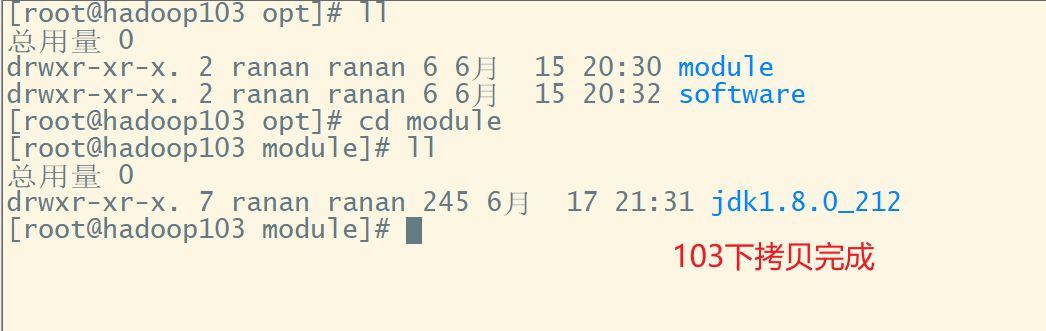
2 hadoop103从102上拉取Hadoop文件
在hadoop103,从hadoop102拉去数据到103
scp -r ranan(对方的用户名):hadoop102(对方的主机名):/opt/module/hadoop-3.1.3(没办法自动补全) /opt/module/(目的路径)


3 在hadoop103上从102把数据拷贝到104
hadoop103下

hadoop104下

rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同的内容和支持符号链接的优点。
rsync和scp区别
rsync:速度更快,只更新差异文件。第一次同步 = scp
scp:复制所有的文件
基本语法
rsync -av(选择参数) 要拷贝的文件路径 目的用户@主机:目的路径
-a 归档拷贝
-v 显示复制过程
编写集群分发脚本xsync
做法:rsync上进行封装
需求:循环复制文件到所有节点的相同目录下
需求分析:
1.rsync原始拷贝命令
# hadoop102下
rsync -av /opt/module/ ranan@hadoop103:/opt/module
2.期望脚本
xsync 要同步的文件名称
3.期望脚本在任何路径都能使用
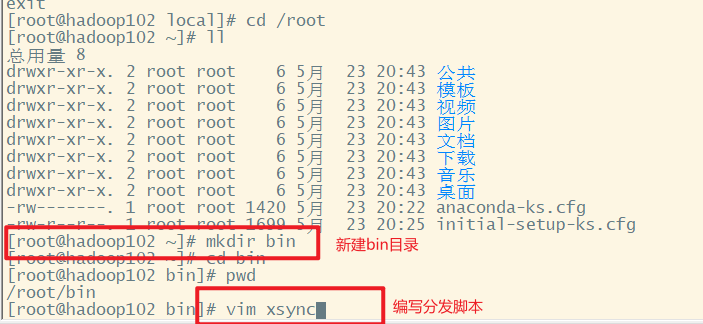
脚本放在声明了全局环境变量的路径
声明了全局环境变量的路径echo $PATH如图所示,这里选择使用/root/bin

3.脚本实现
把脚本放在全局环境变量下就可以任何路径都能使用了
编写脚本代码
#!/bin/bash
#1. 判断参数个数
# 判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 对102,103,104都进行分发
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送 $@代表命令行中所有的参数
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done
脚本可执行权限
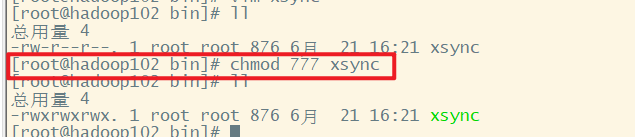
这里hadoop103,104已经通过scp,rsync安装了JDK和Hadoop了。那么我们就使用分发脚本分发环境变量,给hadoop103、104配置环境变量
这样前5步就完成了。
我这里用的root,用其他用户可能权限不够,解决办法
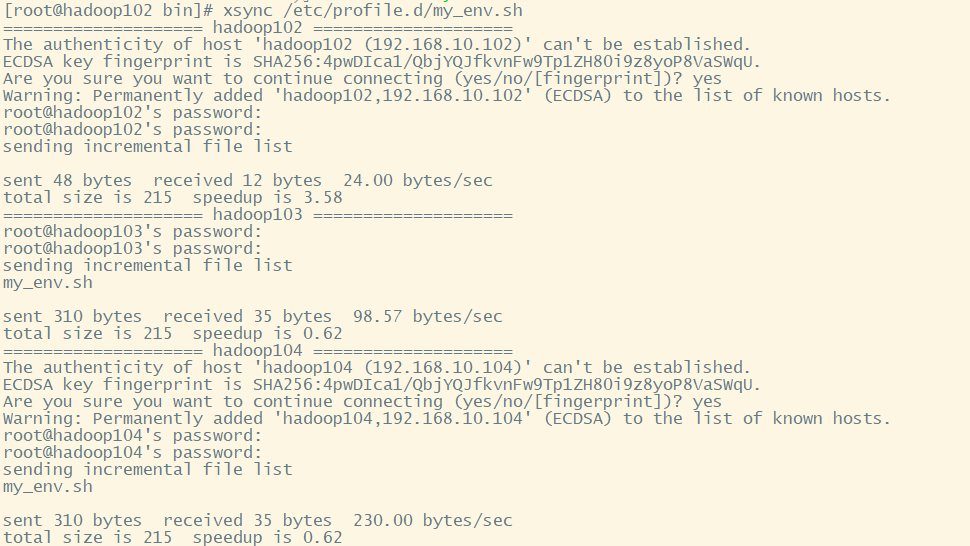
xsync /etc/profile.d/my_env.sh

6 配置SSH
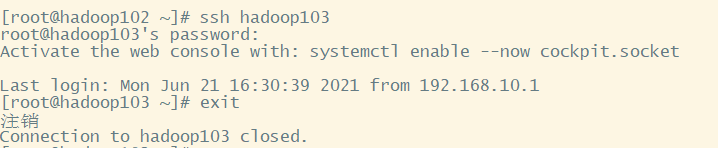
说明:SSh可以访问其他服务器
基本语法:ssh 服务器
退出当前登录:exit
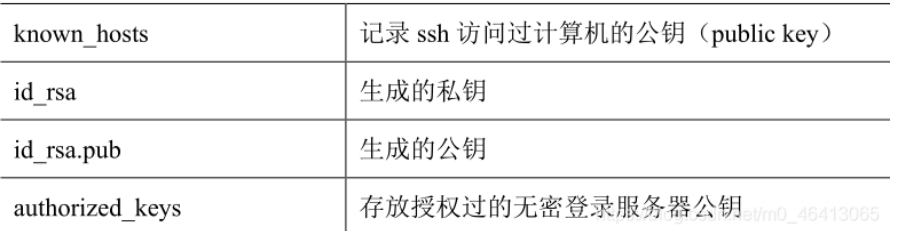
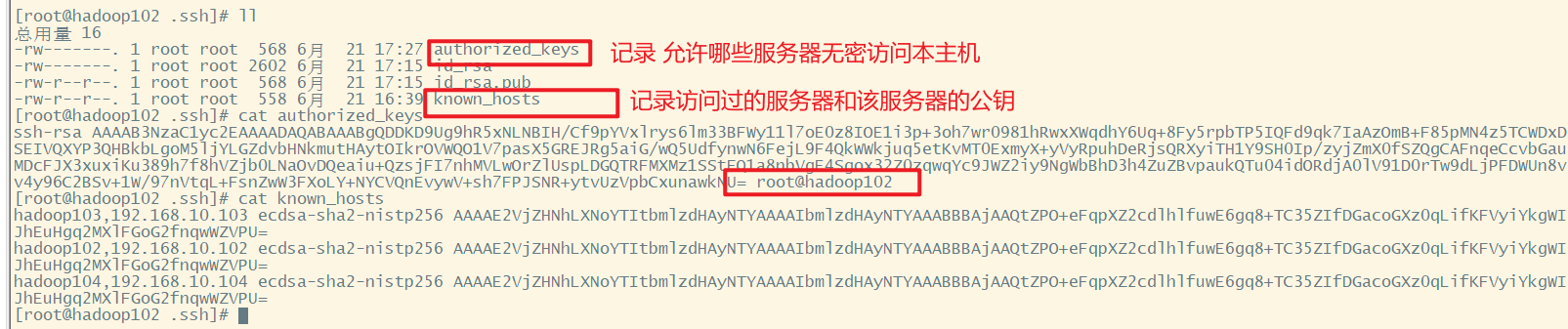
相关文件
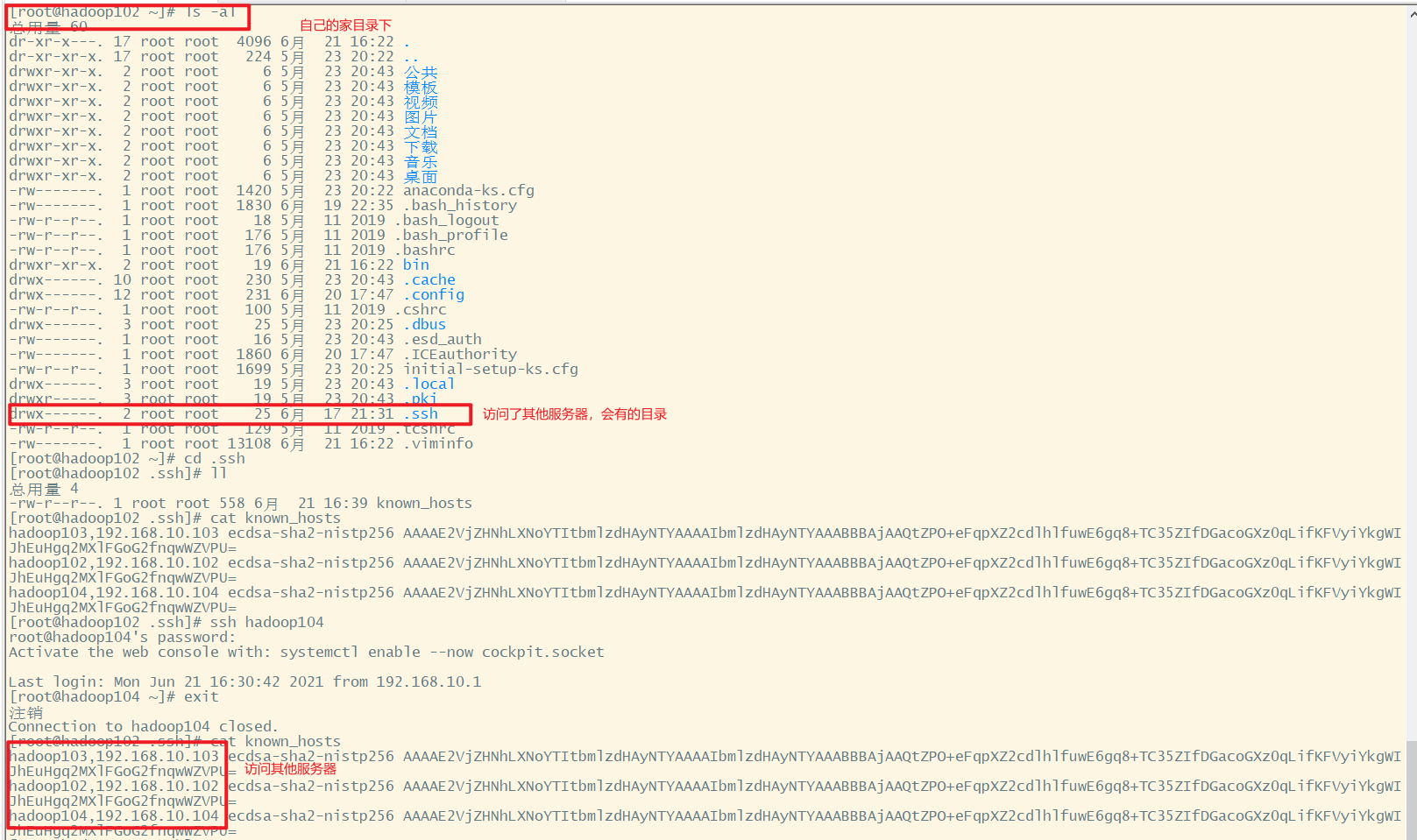
在自己的家目录下,查看隐藏文件ls -al.ssh,进入到.ssh查看known_hosts
.ssh文件夹是在自己的家目录下,所以如果切换到其他用户如ranan,还需要去ranan的家目录重新配置免密登录
配置无密登录
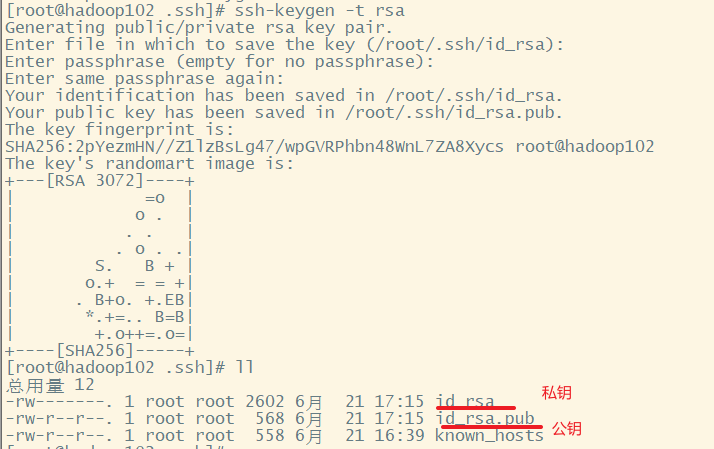
命令:ssh-keygen -t rsa + 三次回车
说明:生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
1. 获得102的公钥和私钥
2. 把102的公钥拷贝给103、104
[root@hadoop102 .ssh]# ssh-copy-id hadoop103
[root@hadoop102 .ssh]# ssh-copy-id hadoop104
[root@hadoop102 .ssh]# ssh-copy-id hadoop102 # ssh访问自己也需要密码
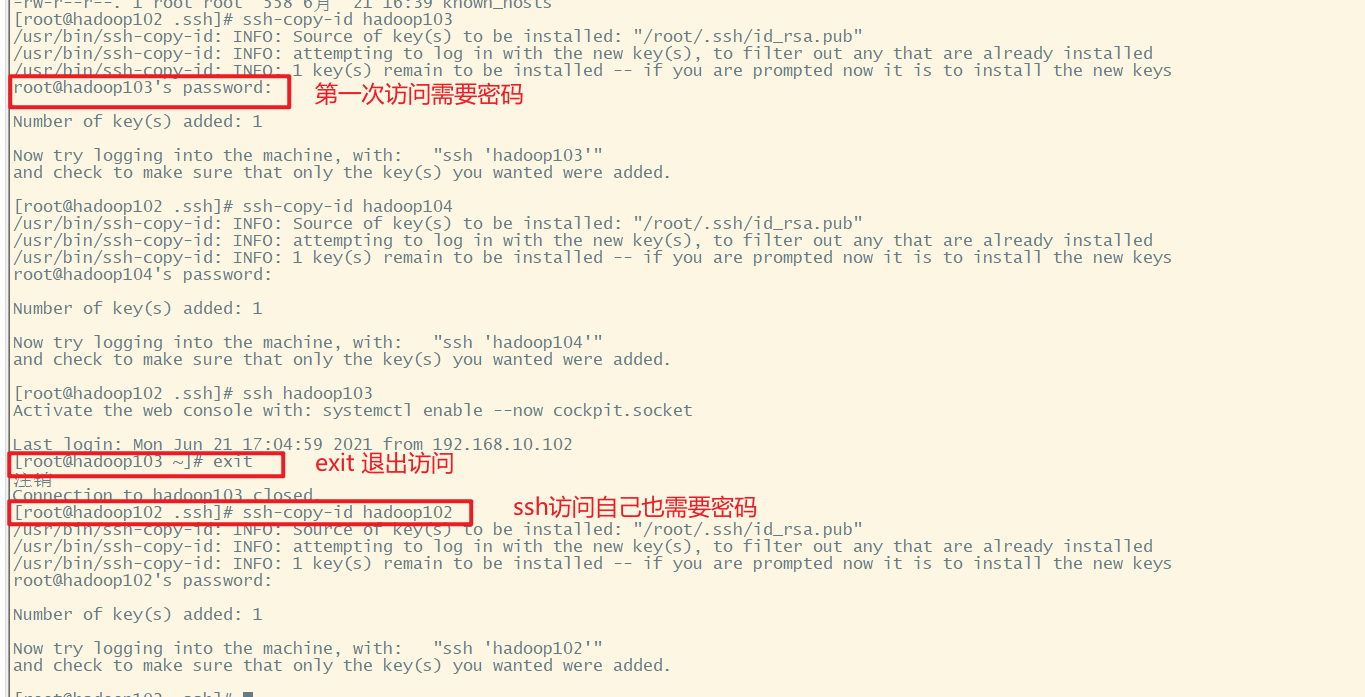
这里102已经可以免密登录103、104了
3. 103、104做同样的操作
[root@hadoop103 .ssh]# ssh-keygen -t rsa
[root@hadoop103 .ssh]# ssh-copy-id hadoop103
[root@hadoop103 .ssh]# ssh-copy-id hadoop104
[root@hadoop103 .ssh]# ssh-copy-id hadoop102
配置102、103已经足够了,配置104的目的是为了操作灵活,任何一台主机都可以访问和操作集群。

步骤总结
1.获得自己的公钥和私钥
2.把自己的公钥拷贝到目的服务器
3.本服务器可以无密访问目的服务器
ssh文件下的文件功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号