
redis淘汰机制,持久化,主从复制,哨兵机制 ,集群
1. 淘汰机制
Redis内存回收机制主要体现在以下两个方面:
1. 删除到达时间的键对象。
2. 内存使用达到maxmemory上限时触发内存溢出控制策略。
1.1.1. 删除过期键对象
Redis所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存了大量的键,维护每个键精准的过期删除机制会导致消耗大量的CPU,对于单线程的
Redis来说成本过高,因此Redis采用惰性删除和定时任务删除机制实现过期键的内存回收
- 惰性删除:惰性删除用于当客户端读取带有超时属性的键时,如果已经超过键设置的过期时间,会执行删除操作并返回空,这种策略是出于节省CPU成本 考虑,不需要单独维护TTL链表来处理过期键的删除。但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内 存不能及时释放。正因为如此,Redis还提供另一种定时任务删除机制作为惰性删除的补充。 - 定时任务删除:Redis内部维护一个定时任务,默认每秒运行10次(通过配置hz控制)。定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比 例,使用快慢两种速率模式回收键。 流程说明: 1. 定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。 2. 如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或运行超时为止,慢模式下超时时间为25ms。 3. 如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1ms且2s内只能运行1次。 4. 快慢两种模式内部删除逻辑相同,只是执行的超时时间不同
1.1.2. 内存溢出控制策略
当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制,Redis支持6种策略
1. noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。 2. allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。推荐使用,目前项目在用这种。 3. allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。应该也没人用吧,你不删最少使用 Key,去随机删。 4. volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又 做持久化存储的时候才用。不推荐。 5. volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。依然不推荐。 6. volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。不推荐。如果没有对应的键,则 回退到noeviction策略。
我们通过配置redis.conf中的maxmemory这个值来开启内存淘汰功能。
* maxmemory : 值得注意的是,maxmemory为0的时候表示我们对Redis的内存使用没有限制
* maxmemory-policy noeviction :配置淘汰策略
* config set maxmemory-policy {policy} :动态配置淘汰策略
如何选择淘汰策略
下面看看几种策略的适用场景
allkeys-lru :如果我们的应用对缓存的访问符合幂律分布,也就是存在相对热点数据,或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择 allkeys-lru策
略
allkeys-random :如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction
另外,volatile-lru策略和volatile-random策略适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个Redis实例来达
到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存
注意:频繁执行回收内存成本很高,主要包括查找可回收键和删除键的开销,如果当前redis有从节点,回收内存操作对应的删除命令会同步到从节点,导致写放大
的问题
2. 持久化
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令) 从内
存保存到硬盘。 当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。Redis持久化分为
RDB持久化和AOF持久化,前者将当前数据保存到硬盘,后者则是将每次执行的写命令保存到硬盘。
2.1. RDB持久化
RDB是一种快照存储持久化方式,具体就是将Redis某一时刻的内存数据保存到硬盘的文件当中,默认保存的文件名为dump.rdb,而在Redis服务器启动时,会重新
加载dump.rdb文件的数据到内存当中恢复数据。触发 RDB 持久化过程分为手动触发和自动触发。
/ # find / -name *.rdb /dump.rdb /redis/data/dump.rdb
我们可以通过如下命令查看信息
/ # redis-check-rdb /redis/data/dump.rdb [offset 0] Checking RDB file /redis/data/dump.rdb [offset 26] AUX FIELD redis-ver = '5.0.7' [offset 40] AUX FIELD redis-bits = '64' [offset 52] AUX FIELD ctime = '1588308363' [offset 67] AUX FIELD used-mem = '1861168' [offset 85] AUX FIELD repl-stream-db = '0' [offset 135] AUX FIELD repl-id = '5c0730ddf00e446c6e4e99df86f508c38bed46d0' [offset 151] AUX FIELD repl-offset = '1666' [offset 167] AUX FIELD aof-preamble = '0' [offset 169] Selecting DB ID 0 [offset 195] Checksum OK [offset 195] \o/ RDB looks OK! \o/ [info] 2 keys read [info] 0 expires [info] 0 already expired
RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件是的数据库状态
触发机制
手动触发分别对应 save 和 bgsave 命令
save 命令:阻塞当前 Redis 服务器,直到 RDB 过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave 命令:Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork 阶段,一般时间很短。显然 bgsave
命令是针对 save 阻塞问题做的优化。因此 Redis 内部所有的涉及 RDB 的操作都采用 bgsave 的方式
除了执行命令手动触发之外,Redis 内部还存在自动触发 RDB 的持久化机制,例如以下场景:
1. 使用 save 相关配置,如“save m n”。表示 m 秒内数据集存在 n 次修改时,自动触发 bgsave。
2. 如果从节点执行全量复制操作,主节点自动执行 bgsave 生成 RDB 文件并发送给从节点。
3. 执行 debug reload 命令重新加载 Redis 时,也会自动触发 save 操作。
4. 默认情况下执行shutdown命令时,如果没有开启 AOF 持久化功能则自动执行 bgsave
2.2. AOF持久化
AOF(append only file)持久化:与RDB存储某个时刻的快照不同,AOF持久化方式会记录客户端对服务器的每一次写操作命令到日志当中,并将这些写操作 以
Redis协议追加保存到以后缀为aof文件末尾
开启 AOF 功能需要设置配置:appendonly yes,默认不开启。AOF 文件名通过 appendfilename 配置设置,默认文件名是 appendonly.aof。保存路径同 RDB 持久
化方式一致,通过 dir 配置指定
参数说明
appendonly yes #启用aof持久化方式 appendfsync always #每次收到写命令就立即强制写入磁盘,最慢的大概只有几百的TPS,但是保证完全的持久化,不推荐使用 appendfsync everysec #每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐 appendfsync no #完全依赖os,性能最 好,持久化没保证,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调 试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上
演示
docker run -itd -v /redis_2004/masterandslave/slave:/redis -p 6389:6379 --network=redis5sm --ip=192.160.1.189 --name redis5slave redis5asm ps
修改配置 /redis/conf/redis.conf
appendonly yes appendfilename "appendonly.aof"
然后测试
/ # redis-server /redis/conf/redis.conf / # redis-cli 127.0.0.1:6379> set k y OK 127.0.0.1:6379> set o p OK 127.0.0.1:6379> exit / # cat /redis/data/appendonly.aof *2 $6 SELECT $1 0 *3 $3 set $1 k $1 y *3 $3 set $1 o $1 p
2.3. 混合持久化及持久化数据恢复
在redis5.0下默认就是开启了这个模式通过配置 aof-use-rdb-preamble
该模式并不会影响到正常的命令备份,仅仅只是影响到 aof模式的文件重写的;
主要是对于aof的一个补充;因为aof的流程中对于redis所有数据库中的内容读取并重写为命令,而重写的过程中会存在这命令写入的可能,aof的处理是先放在缓冲
区中积累,由子进程重写回收,主进程会通过管道的方式发送给子进程并直到子进程结束;但是子进程结束之后也还是会存在没有写入的命令,就会被回收;
父进程用来积累命令使用的结构体,如果服务端执行一条命令时正在执行aof重写,命令还会同步到aof_rewrite_buf_blocks中这是一个list类型的缓冲区;
实现
在同时启用了RDB和AOF方法后,并且 aof-use-rdb-preamble 设置为yes,在重写AOF文件时,Redis首先会把数据集以RDB的格式转储到内存中并作为AOF文件的
开始部分。在重写之后, Redis继续使用传统的AOF格式在AOF文件中记录写人命令。你可以通过观察重写后的AOF文件头部和尾部清楚地了解这种混合格式。如果
启用了混合持久化,那么在AOF文件的开头首先使用的是RDB格式。因为RDB的压缩格式可以实现更快速地重写和加载数据文件,同时也保留了AOF数据一致性更
好的优点,所以Redis可以从混合持久化中获益。
数据恢复演示
首先确保持久化aof的配置关闭,先演示根据与rdb恢复数据
/redis/data # cat /redis/conf/redis.conf | egrep "^save|^append" save 900 1 save 300 10 save 60 10000 appendonly no appendfilename "appendonly.aof" appendfsync everysec
可以使用DEBUG POPULATE命令添加测试数据(aof不会检测到添加的数据)
/redis/data # redis-server /redis/conf/redis.conf /redis/data # redis-cli 127.0.0.1:6379> DEBUG POPULATE 5 OK 127.0.0.1:6379> save OK 127.0.0.1:6379> exit /redis/data # ls dump.rdb /redis/data # ps PID USER TIME COMMAND 1 root 0:00 sh 122 root 0:00 sh 156 root 0:00 redis-server /redis/conf/redis.conf 162 root 0:00 ps /redis/data # kill 156 /redis/data # redis-server /redis/conf/redis.conf /redis/data # redis-cli 127.0.0.1:6379> keys * 1) "key:1" 2) "key:2" 4) "key:4" 5) "key:3" 7) "key:0" 127.0.0.1:6379>
注意如果说配置了, appendonly 为yes;redis在每次启动的时候就会去检测是否存在这个文件
需要额外注意:在redis4 及以上的版本中即时存在RDB 文件开起了aof 也不会加载;因为redis 会生成一个新的aof
[root@localhost data]# ll 总用量 4 -rw-r--r-- 1 root root 0 5月 19 21:57 appendonly.aof -rw-r--r-- 1 root root 92 5月 19 21:57 dump.rdb
3. 主从复制
3.0. 背景
在实际的场景当中单一节点的redis容易面临风险
比如:
机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。而数据是最重要的,如果你不在乎, 基
本上也就不会使用 Redis了。
要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。
Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用。
3.1. 什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到
从节点。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
3.2. 实践主从复制
首先确定目录
1. 主从复制架构-规划
一主一从
| 容器名称 | 容器IP地址 | 映射端口号 | 宿主机IP地址 | 服务运行模式 |
| redis5-master | xx.xx.xx.150 | 6350 -> 6379 | xxx | master |
| redis5-slave | xx.xx.xx.140 | 6340 -> 6379 | xxx | slave |
2. 构建主从容器
对应的dockerfile
FROM alpine:3.11 RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories \ && apk add gcc g++ libc-dev wget vim openssl-dev make linux-headers COPY ./redis-5.0.7.tar.gz redis-5.0.7.tar.gz #通过选择更小的镜像,删除不必要文件清理不必要的安装缓存,从而瘦身镜像 #创建相关目录能够看到日志信息跟数据跟配置文件 RUN mkdir -p /usr/src/redis \ && mkdir -p /redis/data \ && mkdir -p /redis/conf \ && mkdir -p /redis/log \ && mkdir -p /var/log/redis \ && tar -zxvf redis-5.0.7.tar.gz -C /usr/src/redis \ && cd /usr/src/redis/redis-5.0.7 && make \ && cd /usr/src/redis/redis-5.0.7 && make install; RUN apk del gcc g++ libc-dev openssl-dev make linux-headers EXPOSE 6379 # CMD ["redis-server", "/redis/conf/redis.conf"] ENTRYPOINT ["redis-server", "/redis/conf/redis.conf"]
构建容器
[root@localhost ~]# docker network create --subnet=192.160.1.0/24 redis5sm 355edc743429e308669dcd783a6fa4715504548531b63a36601148175e09ad8b [root@localhost ~]# docker network ls NETWORK ID NAME DRIVER SCOPE e9da9cae0b4e bridge bridge local eade643125b5 host host local 29835fbeb0ab none null local 355edc743429 redis5sm bridge local [root@localhost masterandslave]# docker run -itd -v /redis_2004/masterandslave/master:/redis -p 6350:6379 --network=redis5sm -- ip=192.160.1.150 --name redis5master redis5asm af9b75289ac79235a97dfb3f5048f6f02d3b5f5fe4a0ff99920e0c0a5c9b634a [root@localhost masterandslave]# docker run -itd -v /redis_2004/masterandslave/slave:/redis -p 6340:6379 --network=redis5sm -- ip=192.160.1.140 --name redis5slave redis5asm
4. 哨兵机制
redis的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工讲从节点晋升为主节点,同时还要通知应用方更新主节点地址,那这就会存在着问题;哨兵
就是来处理这个问题的
4.1. 基础概念
| 名称 | 逻辑 |
| 主节点 | redis主服务器 |
| 从节点 | redis从服务器 |
| redis数据节点 | 主节点和从节点 |
| 哨兵节点 | 监控redis数据节点 |
| 哨兵节点集合 | 若干哨兵节点的抽象组合 |
| redis 哨兵 | redis高可用实现方案 |
| 应用方 | 第三方客户端如PHP |
4.2. 主从复制的问题
“ 高可用性 ” ( High Availability )通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性
Redis 复制的主要内容中提到,Redis 复制有一个问题,当主机 Master 宕机以后,我们需要人工解决切换,比如使用 slaveof no one 。实际上主从复制并没有实现高可用。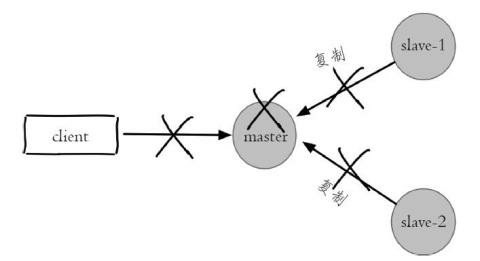
1. 主节点发生故障后,客户端连接主节点失败,两个从节点与主节点连接失败造成复制中断
2. 如果主节点无法正常确定,需要选出一个从节点升级为主节点,对它执行 slaveof no one 命令
3. 原来的从节点成为新的主节点后,更细应用方的主节点信息,重新启动应用方
4. 客户端命令另外一个从节点去复制新的主节点
5. 待原来的主节点恢复后,让它去复制新的主节点。
4.3. redis哨兵安装和部署
4.3.1. 部署结构
3个哨兵、1个主节点、2个从节点
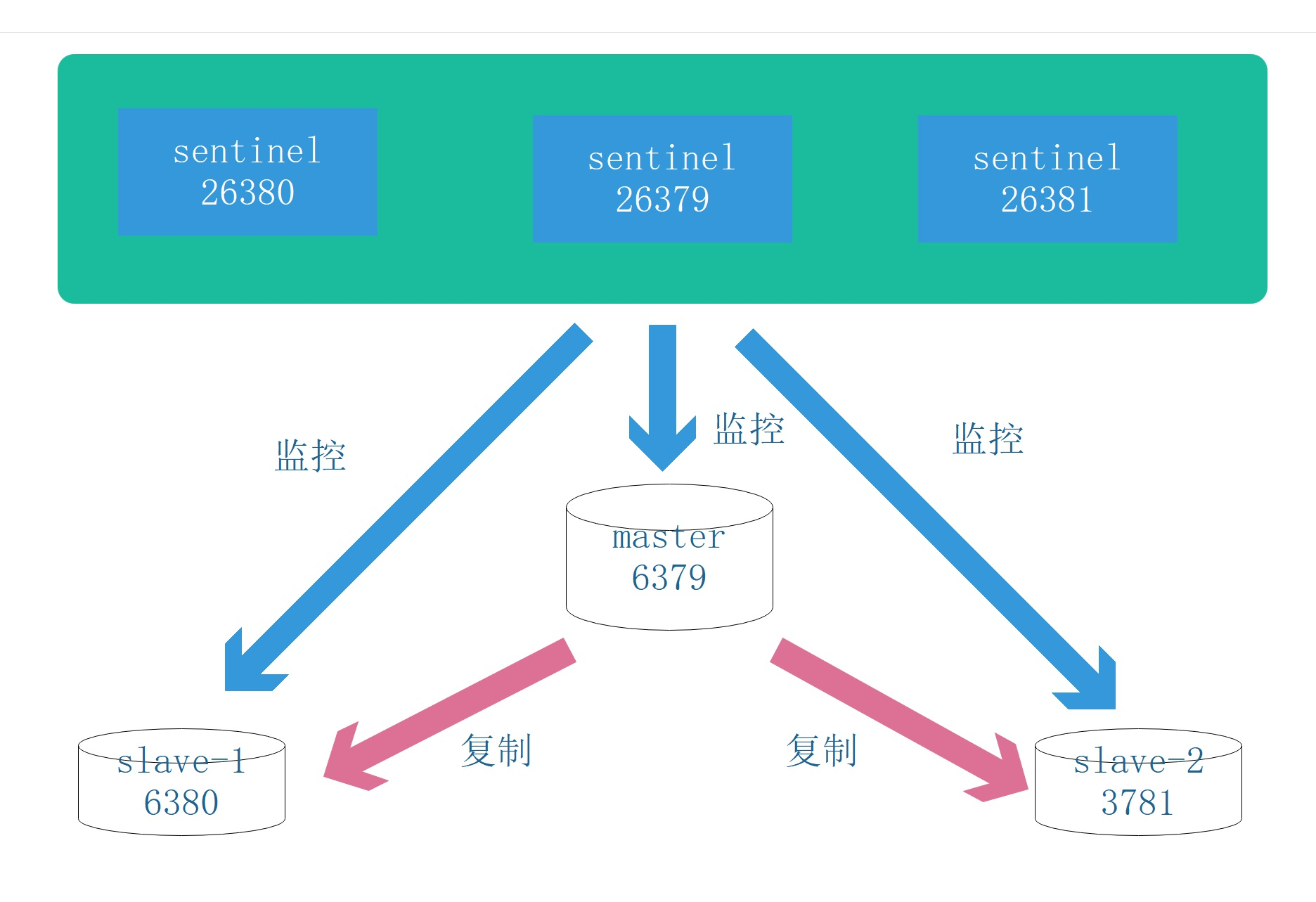
对应的配置事项说明;网络段为 192.160.1.0/24
| 角色 | ip | port主 主->port容 容 |
| master | 192.160.1.79 | 6379->6379 |
| slave-1 | 192.160.1.80 | 6380->6379 |
| slave-2 | 192.160.1.81 | 6381->6379 |
| sentinel_79 | 192.160.1.179 | 26379->26379 |
| sentinel_80 | 192.160.1.180 | 26380->26379 |
| sentinel_81 | 192.160.1.181 | 26381->26379 |
部署主从:
如下为配置
# 主节点配置 bind 0.0.0.0 protected-mode no port 6379 daemonize no dir "/redis/data" logfile "/redis/log/redis.log" # 从节点配置 bind 0.0.0.0 protected-mode no port 6379 daemonize no replicaof 192.160.1.79 6379 dir "/redis/data" logfile "/redis/log/redis.log"
然后通过docker-compose的命令创建redis容器并且确认关系
[root@localhost data]# docker-compose up -d [root@localhost data]# docker exec -it redis5_m_79 sh / # redis-cli 127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.160.1.80,port=6379,state=online,offset=98,lag=1 slave1:ip=192.160.1.81,port=6379,state=online,offset=98,lag=0 ... 127.0.0.1:6379> exit / # exit
哨兵部署
bind 0.0.0.0 protected-mode no port 26379 daemonize no logfile "/redis/log/sentinel.log" sentinel monitor mymaster 192.160.1.79 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel failover-timeout mymaster 180000 sentinel parallel-syncs mymaster 1
参数介绍:
启动sentinel节点:
# 方法一 redis-sentinel /redis/conf/sentinel.conf # 方法二 redis-server /redis/conf/sentinel.conf --sentinel
5. 集群
5.1. 简绍
Redis Cluster 是 Redis 的分布式解决方案,在3.0版本正式推出,有效地解决了 Redis 分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用 Cluster
架构方案达到负载均衡的目的。
架构图:
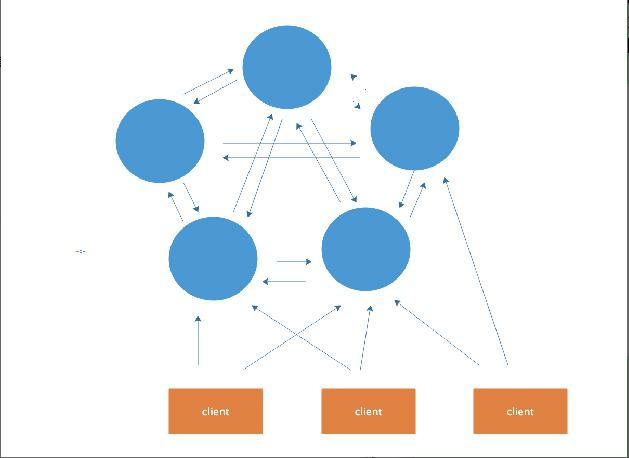
在这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群
中的任何一个节点,对其进行存取和其他操作。
Redis 集群提供了以下两个好处:
1、将数据自动切分到多个节点的能力。 2、当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力,拥有自动故障转移的能力。
5.2. redis cluster vs. replication + sentinal如何选择
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了。
Replication:一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,结合sentinal集群,去保证redis主从架构的高可用性,就可以了。
redis cluster:主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号