Spark和Java API(五)Shuffle后Reduce端的分区数
情况1,ShuffledRDD只有一个父RDD
假设有一个RDD是这么生成的:
SparkConf conf = new SparkConf().setAppName("TryPartition Application");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> data1 = sc.parallelize(Arrays.asList("A", "B", "C", "D", "E", "F"), 3);
data1的分区是3个。接着我们shuffle data1:
JavaPairRDD<String, Iterable<String>> data2 = data1.groupBy(line -> line);
System.out.println("partitions="+data2.partitions());
System.out.println(data2.collect());
会出现下面结果:
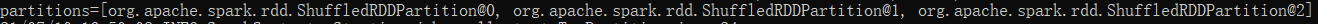
以及
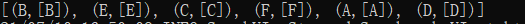
可以看出data2这个ShuffledRDD继承了父RDD data1的分区数,也即是3个分区。
情况2,ShuffledRDD有多个父RDD
比如join操作,ShuffledRDD有两个父RDD,那么它会继承哪个父RDD的分区数呢?
看如下代码,首先先生成两个父RDD:
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> data1 = sc.parallelize(Arrays.asList("A 1", "B 2", "C 3", "D 4", "E 5", "F 6"), 3);
JavaRDD<String> data2 = sc.parallelize(Arrays.asList("A 10", "B 20", "C 30", "D 40", "E 50", "F 60"), 4);
JavaPairRDD<String, String> data1_1 = data1.mapToPair(line -> {
String[] kv = line.split("\\s+", 2);
return new Tuple2<String, String>(kv[0], kv[1]);
});
JavaPairRDD<String, String> data2_1 = data2.mapToPair(line -> {
String[] kv = line.split("\\s+", 2);
return new Tuple2<String, String>(kv[0], kv[1]);
});
接着连接两个父RDD data1_1, data2_1:
JavaPairRDD<String, Tuple2<String, String>> data3 = data1_1.join(data2_1);
System.out.println("partitions=" + data3.partitions());
System.out.println(data3.collect());
得到结果如下:

以及

接下来我们交换join的顺序,用data2_1 join data1_1:
JavaPairRDD<String, Tuple2<String, String>> data4 = data2_1.join(data1_1);
System.out.println("partitions=" + data4.partitions());
System.out.println(data4.collect());
得到结果如下:

以及

最后我们得到结论,当两个父RDD join时,继承于它们的CoGroupPartition RDD的分区数是两个父RDD中分区数值最大的那个分区数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号