Spark和Java API(四)分区
RDD的分区是什么?
RDD,顾名思义它是分布式的,那么它是怎么实现分布式呢?答案就是分区,也即是一个RDD会将计算逻辑分布在整个集群中。这很像kafka中的topic的分区,通过水平扩展的方式提供系统的吞吐量。
那么分区是如何分布在整个集群中呢?我们拿hdfs举例,假设hdfs上有一个文件A,大小为1个GB,hdfs默认会将这个文件切割成多个block,每个block为128MB,那么A拥有4个主block,因为hdfs会对文件做冗余,一个block有2个备份。所以A一共有12个block。这12个block分散在集群的不同的节点上,当一个RDD需要引用文件A时,它会分配4个分区,每个分区对应一个主block和两个备block,然后将计算逻辑发送到block所在的节点进行运算。
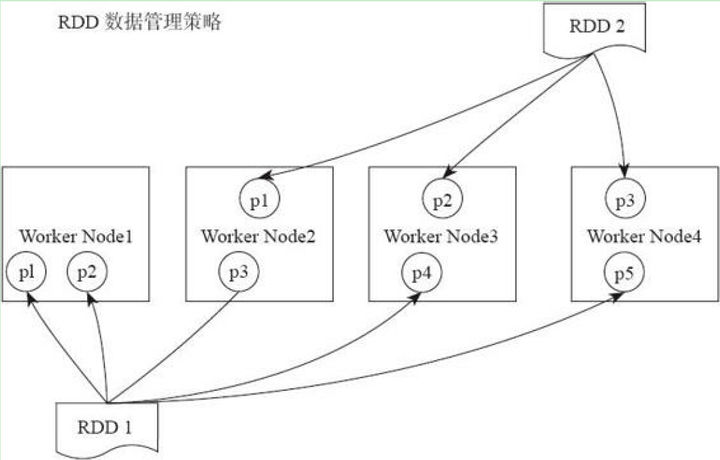
RDD作为一个分布式的数据集,是分布在多个worker节点上的。如下图所示,RDD1有五个分区(partition),他们分布在了四个worker nodes 上面,RDD2有三个分区,分布在了三个worker nodes上面。
RDD为什么需要分区?
和Kafka一样,对topic分区可以提高系统的吞吐量,假设没有分区,那么计算过程中会移动大量数据,这在大数据环境中并不是一个好现象,毕竟大数据环境的最佳实践是移动计算而非数据。假设我们现在也实现了移动计算而非移动数据,但是没有分区,那么计算就因无法并行执行而浪费了集群的算力,造成吞吐量低下的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号