Basics of Java Garbage Collection(Java的垃圾回收基础知识)
原文的链接: https://codeahoy.com/2017/08/06/basics-of-java-garbage-collection/
- Knock, knock.
- Who’s there?
- …long GC pause…
- Java.
上面是一个历史悠久的笑话,用于嘲讽Java刚推出时性能弱于其他语言的事实。然而到现在,Java的已经变得快多了。现今基于Java可以开发很多实时应用承接成百上千的并发用户并发数。如今,对Java的性能影响最大的还是来自于它的垃圾回收机制。幸运的时,在许多情况下,它能够被调整优化以提高性能。
对于绝大部分应用,JVM仅使用默认配置就能工作得很好。但是当你开始注意到一些因为GC引发得性能问题且同时无法再给JVM更多内存时,那么你就应该调整优化GC了。对于大部分开发者,这是一个杂活,它需要耐心,需要你懂得GC是如何工作得以及理解应用得行为。这篇文章用几个性能问题解决的例子来概述Java的GC。
Let’s get started.
Java装配有多种GC收集器。更具体来说,有不同的垃圾回收算法运行在他们的各自的线程中。每一种收集器互不相同且都有优缺点。你时刻要记住的最重要的事情是GC会STW(stop the world)。也就是说,你的应用会被挂起直到GC结束后才继续运行。这些垃圾回收算法主要的不同点是它们是如何STW的。一些算法会一直静默直到需要GC然后暂停你的应用很长一段时间,而另一些算法则和你的应用并发地执行完成大部分工作也因此需要更短的STW时间。最好的算法依赖于你的目标:你可以在高吞吐量(STW会很长)和低延迟之间进行选择(STW会很短)。
为了强化垃圾回收过程,Java(更准确地说是HotSpot JVM)把堆内存分成了两代:新生代和老年代。还有个永久代,本文不涉及这个区域。
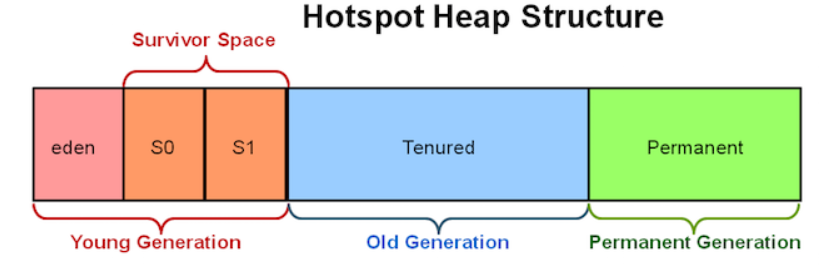
新生代里面是新的对象所在区域,它被细分为以下区域:
- Eden
- Survivor Space 1
- Survivor Space 2
默认情况下,Eden比两个Survivor加起来都要大。在我的MAC OS X 64-bit HotSpot JVM上,Eden占用了76%的新生代。所有对象都会在Eden中经历第一次创建。当Eden区满了之后,会触发一个minor GC。所有新的对象回收会被快速地检查看他们哪些是可以被GC的。如果一个对象死掉了,换句话说是没有引用指向它了,这个对象就会被标记为dead然后被GC掉。那些没有死亡的的对象(survival)会被移动到一个空的Survivor空间。对象应该拷贝到两个中的哪个Survivor空间内呢?为了回答这个问题,让我们讨论一下Survivor空间。
之所以要有两个Survivor空间是为了避免内存碎片问题。假设现在只有一个Survivor空间,这个空间是一个连续的已用的内存空间。当你的GC收集了这个区域,它标记dead对象为了接下来的删除操作。删除操作执行完后会留下一个空洞在内存中,这些空洞需要整理。为了避免整理操作,HotSpot JVM将survival对象从survivor空间移到到另一个(空的)survivor空间,这样就消除掉那些内存空洞了。当我们讨论内存整理时,请注意老年代的GC收集器(除了CMS)都会在老年代中执行整理操作以解决内存碎片问题。
简单来讲,minor GC(当Eden满了时触发的)来回地在两个survivor之间搬运对象。这一切会在下面情况发生后停止:
- 对象的年龄到达阈值,换句话说对象不再年轻了。
- survivor区已经没有空间容纳新的对象。
当上述情况发生,对象就会被移动老年代。让我通过一个真实的例子来理解这一个过程。假设我们有如下应用,它在初始化阶段创建了一些长时间生存的对象,然后运行时创建许多短时间生存的对象(比方说一个web服务器会利用短时间生存的对象来处理请求)。
private static void createFewLongLivedAndManyShortLivedObjects() {
HashSet<Double> set = new HashSet<Double>();
long l = 0;
for (int i=0; i < 100; i++) {
Double longLivedDouble = new Double(l++);
set.add(longLivedDouble); // add to Set so the objects continue living outside the scope
}
while(true) { // Keep creating short-lived objects. Extreme but illustrates the point
Double shortLivedDouble = new Double(l++);
}
}
运用下面JVM命令行参数开启GC日志:
-Xmx100m // Allow JVM 100 MB of heap memory
-XX:-PrintGC // Enable GC Logs
-XX:+PrintHeapAtGC // Enable GC logs
-XX:MaxTenuringThreshold=15 // Allow objects to live in the young space longer
-XX:+UseConcMarkSweepGC // Ignore for now; covered later
-XX:+UseParNewGC // Ignore for now; covered later
应用日志会显示GC前与GC后的状态:
Heap <b>before</b> GC invocations=5 (full 0):
par new (<u>young</u>) generation total 30720K, used 28680K
eden space 27328K, <b>100%</b> used
from space 3392K, <b>39%</b> used
to space 3392K, 0% used
concurrent mark-sweep (<u>old</u>) generation total 68288K, used <b>0K</b> <br/>
Heap <b>after</b> GC invocations=6 (full 0):
par new generation (<u>young</u>) total 30720K, used 1751K
eden space 27328K, <b>0%</b> used
from space 3392K, <b>51%</b> used
to space 3392K, 0% used
concurrent mark-sweep (<u>old</u>) generation total 68288K, used <b>0K</b>
从日志中,我们可以了解一些事实。首先,在这次GC之前已经发生了5次minor GC。Eden区因为使用率为100%触发了这次GC(第六次)。其中的一个survivor空间使用率是39%,还有剩余一些空间。在GC结束后,我们可以看到Eden区变成0%的使用率然后survivor空间的使用率增加至51%。这意味着Eden区和Survivor的live对象被移动至第二个survivor空间,以及dead对象被GC掉了。我们为什么能说一些dead对象被回收了呢?我们可以看到Eden区比survivor区要大的多(27328K vs 3392K)而因为survivor区只是轻微地增长,所以可以认为大量的对象已经被回收。在GC前后老年代保持为空(记得晋升老年代的阈值为15)。
我们再看另一个实验。我们跑一个这样的程序,它是多线程的,且只创建生命周期很短的对象。基于到目前为止的讨论,这些对象都不应该进入老年代;minor GC应该能够清除掉他们。
private static void createManyShortLivedObjects() {
final int NUMBER_OF_THREADS = 100;
final int NUMBER_OF_OBJECTS_EACH_TIME = 1000000;
for (int i=0; i<NUMBER_OF_THREADS; i++) {
new Thread(() -> {
while(true) {
for (int i=0; i<NUMBER_OF_OBJECTS_EACH_TIME; i++) {
Double shortLivedDouble = new Double(1.0d);
}
sleepMillis(1);
}
}
}).start();
}
}
}
针对这个例子,我给10MB内存给JVM,让我们看下GC日志。
Heap <b>before</b> GC invocations=0 (full 0):
par new (<u>young</u>) generation total 3072K, used 2751K
eden space 2752K, 99% used
from space 320K, 0% used
to space 320K, 0% used
concurrent mark-sweep (<u>old</u>) generation total 6848K, used <b>0K</b> <br/>
Heap <b>after</b> GC invocations=1 (full 0):
par new generation (<u>young</u>) total 3072K, used 318K
eden space 2752K, 0% used
from space 320K, 99% used
to space 320K, 0% used
concurrent mark-sweep (<u>old</u>) generation total 6848K, used <b>76K</b>
这个结果和我们预测的不一样。我们可以看到这次有数据在minor GC之后进入了老年代。我知道这些对象都是短寿命的,进入老年代的年龄阈值是15,另外这只是第一次回收。这背后发生了什么?是这样的:应用创建了大量的对象塞满了Eden空间。Minor GC收集器触发运行尝试GC。不过,大多数的这些短寿命对象在GC期间还是存活的,亦即是说,他们被来自一个运行中的线程引用并且正在被处理。新生代GC回收器只能将这些对象放入老年代。这是一件很糟糕的事情,短寿命的对象被放入了老年代,等待需要更多时间的老年代的major GC收集器收集。CMS,接下来我们会讲解的major GC收集器,会在老年代内存使用率达到70%时被触发并开始工作。默认值可以通过修改参数-XX:CMSInitiatingOccupancyFraction=70来实现。
如何避免短寿命的对象进入老年代?方法有几个,一个理论上的方法是估算活跃的短寿命对象以及调整新生代的大小到一个合适的值。我们做一些改变:
- 默认情况下新生代的大小是整个堆大小的1/3.我们运用-XX:NewRatio=1来分配更多的内存给新生代(大约是3.4MB,比之前的3MB多)
- 同时用-XX:SurvivorRatio=1增加survivor空间的比例(大约是1.6M,比之前的0.3MB多)。
这样这个问题就解决了,在8个minor GC之后,老年代依然为空。
Heap <b>before</b> GC invocations=7 (full 0):
par new generation total 3456K, used 2352K
eden space 1792K, 99% used
from space 1664K, 33% used
to space 1664K, 0% used
concurrent mark-sweep generation total 5120K, used <b>0K</b> <br/>
Heap <b>after</b> GC invocations=8 (full 0):
par new generation total 3456K, used 560K
eden space 1792K, 0% used
from space 1664K, 33% used
to space 1664K, 0% used [
concurrent mark-sweep generation total 5120K, used <b>0K</b>
以上例子所展示的绝非详尽的调试方法。我只是简单展示一些步骤。对于真实应用,一个好的优化配置是一个反复实验反复经历错误的结果。例如,我也可以通过增加一倍堆内存来解决问题。
Garbage Collection Algorithms
现在我们已经提及到分代,我们来看看垃圾回收算法。HotSpot JVM装配了多个算法,有些是适用于新生代的,有些是适用于老年代的。在一个高层次角度来看,有三种回收算法,每一种都有它的性能特征。
-
Serial收集器用一条线程来执行GC,这样会让它非常高效,因为没有线程间的通信负担。它是最适合单核机器的收集器。
-
并行收集器(也被称为吞吐量收集器)以多线程的方式执行minor GC,它们明显地降低GC所带来的负载。它被设计成适合那*些有中等或大规模数据集的,运行在多核或多线程机器上的应用。
-
并发收集器并发地执行它的工作(比如,当应用还在运行时它也同样在执行),以此来保持GC停顿的时间很短。它被设计成适合那些有中等或大数据集,响应延迟比吞吐量更重要的应用。
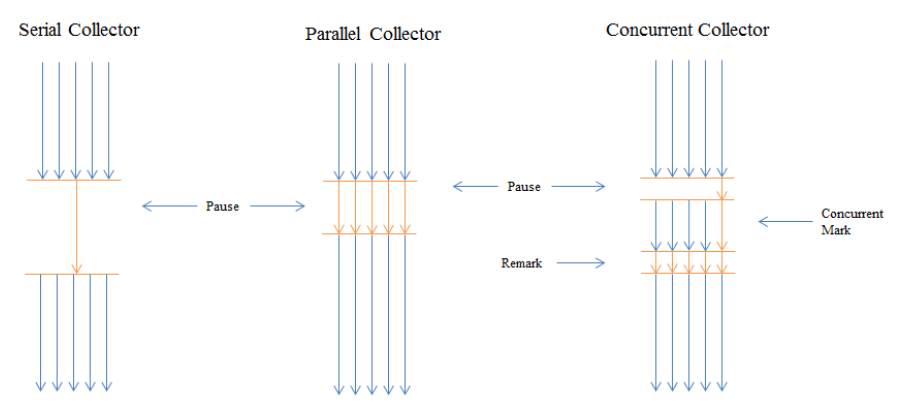
HotSpot JVM允许你为不同分代指定不同的GC算法。不过两个代的算法需要兼容。比如,你不能够在新生代使用Parallel Scavenge的同时在老年代使用CMS,因为它们两时不兼容的。算法的兼容性如下图所示:
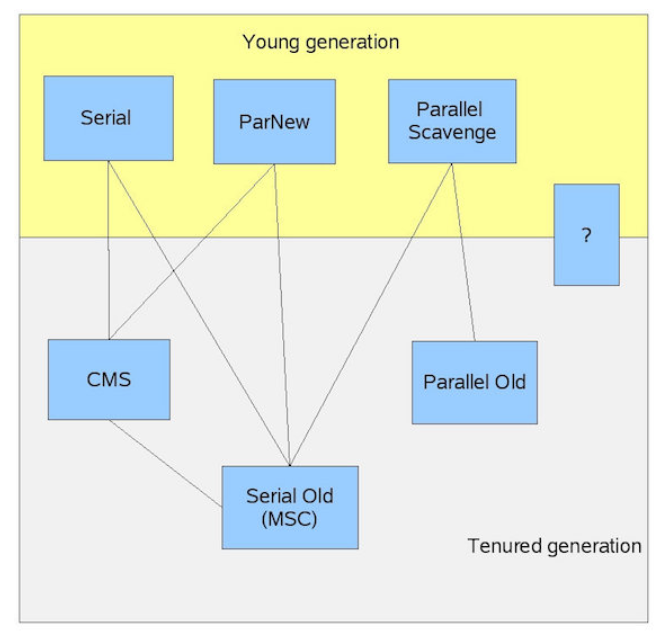
- “Serial”是一个STW、单线程、复制收集器。
- “Parallel Scavenge”是STW、多线程、复制收集器。
- “ParNew”是STW、多线程、复制收集器。它和“Parallel Scavenge”的区别是它能和CMS兼容。 例如“ParNew” does the synchronization needed 以便它能够在CMS的并发阶段也能执行。
- “Serial Old”是一个STW、单线程、标记整理收集器。
- CMS是大部分工作都是和应用并发运行的,STW时间很短的收集器。
- “Parallel Old”是一个多线程、标记整理收集器。
CMS配合ParNew,对于服务器端程序它们可以很好的工作。我就在使用它,堆内存为10G,它保持响应时间稳定且GC停顿很短暂。一些我认识的开发者则使用Parallel收集器(Parallel Scavenge + Parallel Old),他们对这个选择的结果也很满意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号