
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
Spark作为计算引擎,是承载大数据操作的框架媒介。作为程序体的框架,调用配置所处位置下的机器的硬件设施来实现调用配置。
HBase作为数据库,是大数据存储和读取的存储(读取)媒介。
Hadoop作为分布式系统架构,则是对大量机器进行管理控制的管理者。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储系统,可融入Hadoop生态。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是--Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Apache YARN(Yet Another Resource Negotiator) 是Hadoop的集群资源管理系统。YARN被引入Hadoop2最初是为了改善MapReduce的实现,但它具有足够的通性,同样可以支持其他的分布式计算模式。
Yarn大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 mapred-site.xml 配置。
对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsMasters( 注意不是 ApplicationMaster),它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。
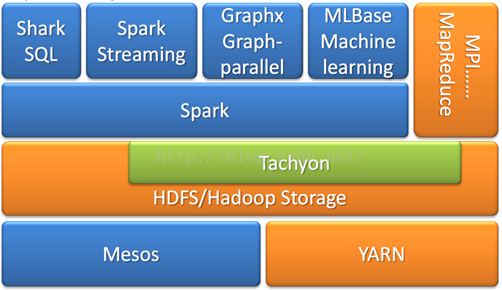
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
Spark成功的使用Spark SQL、Spark Streaming、MLLib、GraphX近乎完美的解决了大数据中Batch Processing、Streaming Processing、Ad-hoc Query等三大核心问题,更为美妙的是在Spark中Spark SQL、Spark Streaming、MLLib、GraphX四大子框架和库之间可以无缝的共享数据和操作。
3. 用图文描述你所理解的Spark运行架构,运行流程。
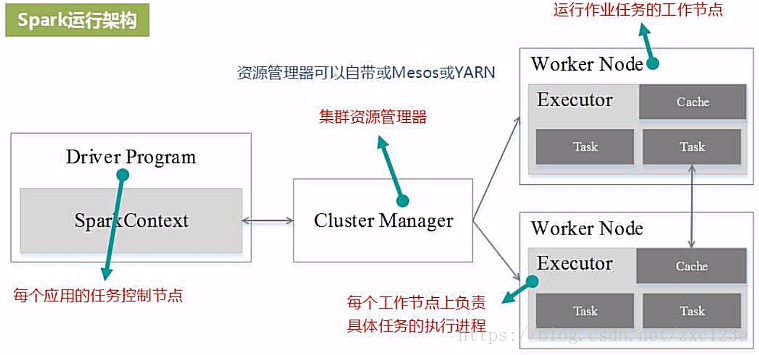
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
- 利用多线程来执行具体的任务减少任务的启动开销;
- Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销;
Spark运行流程
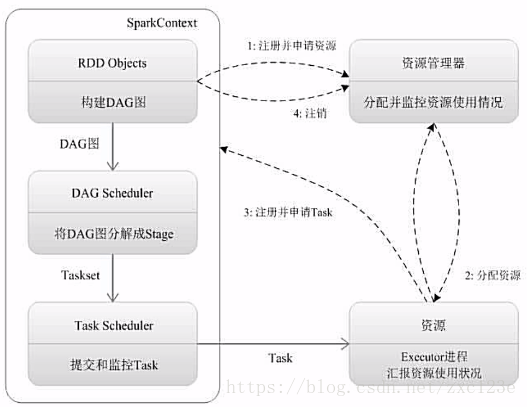
1、为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控
2、资源管理器为Executor分配资源,并启动Executor进程
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
4、Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
4. 软件平台准备:Linux-Hadoop。
- Linux系统的安装
http://dblab.xmu.edu.cn/blog/285/
- 在Windows中使用VirtualBox安装Ubuntu
http://dblab.xmu.edu.cn/blog/337-2/
- Linux系统的常用命令
http://dblab.xmu.edu.cn/blog/1624-2/
- 在Windows系统中利用FTP软件向Ubuntu系统上传文件
http://dblab.xmu.edu.cn/blog/1608-2/
- Linux系统中下载安装文件和解压缩方法
http://dblab.xmu.edu.cn/blog/1606-2/
- Linux系统中vim编辑器的安装和使用方法
http://dblab.xmu.edu.cn/blog/1607-2/
- Hadoop的安装和使用
http://dblab.xmu.edu.cn/blog/install-hadoop/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号