MySQL索引浅析(一)
首先思考一个问题,SQL语句是这样的,select * from t where t.col2 = 89,如果没有索引,查询是什么样子的呢?如果t.col2 = 89这条记录的数据是数据表的最后一条数据,没有索引的话,为了得到正确的结果,MySQL需要遍历每一条数据,每遍历一次,都是一次磁盘IO操作,这个消耗是很大的。
索引对应的数据结构有二叉树、红黑树、Hash表、B-Tree。如果我们用一个二叉树来存储col2这一列的数据会是什么样的呢?如下图所示:
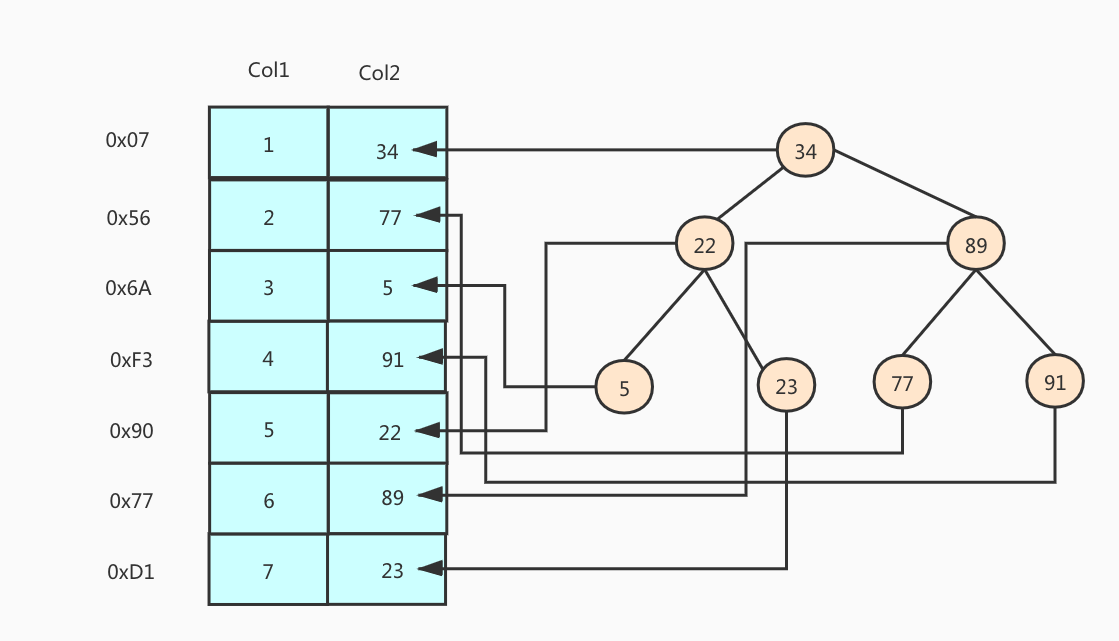
如果我们把col2这一列的数据放入到二叉树为数据结构的索引中,然后再次使用select * from t where t.col2 = 89又会如何呢?MySQL首先会从根节点进行查询,发现这个节点的值是34,不是要查询的数据,因为二叉树有一个特性是,右边的子元素大于父元素的值,所以会继续在右子节点进行查询,这次MySQL发现这个节点储存的是89,符合查询条件,所以MySQL立刻返回查询结果。从这个查询流程中我们可以清楚的看出来,我们进行了2次查询,高于没有索引时候的6次查询。二叉树每一个节点存储的是一个key-value对,key就是col2的值,比如说是89,value是col2 = 89所对应的这一行磁盘数据的指针,这里是0x77。我们根据这个指针,就可以快速的在磁盘上查找到对应的那一行数据,并把它载入到内存中,返回给用户使用。
但是MySQL并不是使用的二叉树来作为索引的。这是为什么呢?我们来思考这样的一个场景。如果我们现在把col1,从1到7递增的顺序存入到二叉树中,根据二叉树右边的子元素大于父元素的值特性,就会退化成为一个链表。如果我要查询col1 = 7,这一条数据,就要逐个节点遍历,需要经历7次磁盘IO。所以二叉树不太适合存储单边增长的序列字段。
红黑树是否适合做MySQL的索引呢?其实也不适合存储索引的。大家可以想一想如果我要索引500万个数据,你可以想象一下这颗红黑树的树高是多少?在这么高的红黑树中查询数据,也是不方便的。如果我们能对红黑树进行改造,例如我现在想存储1000万行数据,但是树高是可控的,比如树高为5,应该怎么做呢?我们可以把红黑树上每一个节点的磁盘存储空间分配的大一点,让每一个节点在横向上面可以存储更多的索引元素。这就是B-Tree。如下图所示:
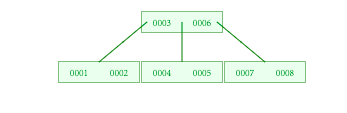
如果使用B-Tree来存储数据,会把索引对应的data数据也存储在同一个节点上。MySQL默认一个节点是16KB,这样一个节点上能存储的索引个数就变少了。这样的话,如果数据量过大的话,这个树的高度还是很高。所以第一个关于MySQL索引的结论是,MySQL使用B+Tree来存储索引。MySQL在B+Tree的非叶子节点是不存储data的,只存储索引,它是冗余存储。叶子节点包含索引和data,叶子节点用指针连接,提高区间访问的性能。叶子节点存储的是所有的索引数据,而在非叶子节点会存储叶子节点的一些中间索引。这样做的目的是方便进行查找。如果我们要查询col2 = 49,看下图解释如何查询。
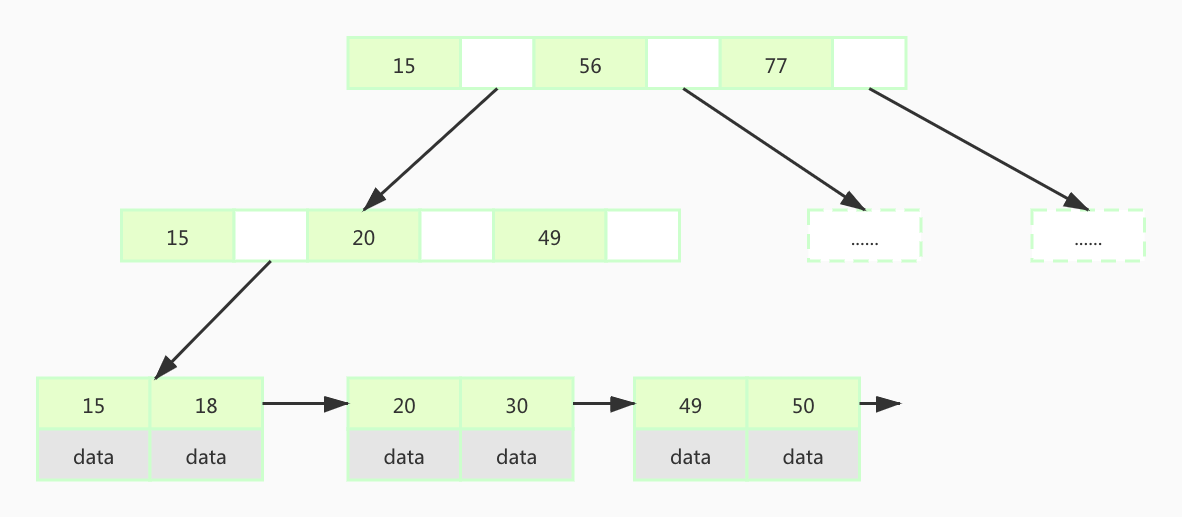
首先B+Tree节点中的数据也是单调递增的,从根节点开始进行检索,因为非叶子节点存储的是一部分索引数据,所以这一步查询到的是一个区间范围。它发现要查询的49在15-56之间,根据存储的指针向下查找下一个非叶子节点,第二次查询,找到了49对应的索引指针。最后去查询叶子节点,根据磁盘文件地址,在磁盘上找到对应的data,然后返回给用户。注意:这些查询都是将节点加载进入内存中进行的,所以查询效率很高。MySQL给B+Tree每一个节点设置16K,节点里面每一个索引是8 Byte,与索引相连的指向下一级的节点的指针是6 Byte。这样可以计算一下每一个非叶子节点可以存储多少索引,公式是(16 * 1024 Byte)/ (8 Byte + 6 Byte)= 1170。根节点有1170个索引元素,每一个索引元素指针指向下一级节点也是1170个索引元素,上一级有1170个指针,所以第二级就有1170 * 1170个索引元素。叶子节点因为存储了data,所以这里我们就算data的大小是1KB,从第二层1170*1170个索引值,每一个叶子节点可以存储16个数据,整个B+Tree就存储1170*1170*16=21902400,大约是2000多万数据。
MySQL的索引实现方式有HASH和BTREE两种。那么MySQL是如何用HASH这种方式来存储索引呢?比如这里有一条SQL查询,select * from t where t.col1 = 6;首先会进行hash(6)这个操作,得到的值和数据行对应的磁盘地址指针有一个映射关系,存储在一张hash表中。我们就可以根据hash值从hash表中取出对应的磁盘文件指针。但是我们在开发的过程中不用hash存储索引,因为hash存储的索引不支持范围查找、排序搜索、模糊查询。
B+Tree中的叶子节点间的指针又是做什么的呢?如果我们现在想查找col1 > 20的这些数据,如果没有指针的话,我们先找到col1 = 20的这个叶子节点,然后向右边遍历这些数据,然后从根节点重新查询,看看还有没有起始叶子节点的值大于20的。我们可以清楚的感觉到,没有指针的查询,需要多次从根节点进行查询,效率不高。
InnoDB引擎存储的索引就是一个聚集索引,也叫聚簇索引。所谓聚集索引就是索引和表的数据列存储在一个文件中。而MyISAM引擎存储的是非聚集索引,也叫稀疏索引。MyISAM引擎在B+Tree叶子节点中存储的是磁盘文件地址指针,在磁盘上索引和数据文件是分别存储的。索引是存储在.myi文件中,数据是存储在.myd文件中。
接下来我们来思考几个问题。第一个问题,为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?因为MySQL要用B+Tree存储主键索引。我们有时候创建InnoDB存储引擎的表,没有指定主键,但是也成功了,这又是为什么呢?其实MySQL会给你的表自动创建一个叫rowid的列,用它作为主键,并创建了主键索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号