Go语言高效拼接字符串
1、什么是字符串❓
-
是只读的字节数组-------------------------------本质
-
字符串是不可变的
-
是一串连续的内存地址-------------------------内存表现
-
数据结构如下
// StringHeader is the runtime representation of a string.
是字符串的运行时表示。
// It cannot be used safely or portably and its representation may
// change in a later release.
它不能安全或便携地使用,它的表示可能在以后的版本中更改。
// Moreover, the Data field is not sufficient to guarantee the data
而且,Data字段不足以保证数据
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
它的引用不会被垃圾收集,所以程序必须保持一个单独的、正确类型的指向底层数据的指针。
type StringHeader struct {
Data uintptr
Len int
}
PS:所有基于字符串的操作,如追加,截取,分割等都不是改变原本的内存空间,而是通过拷贝来进行实现的
2、申明字符串的方式
双引号方式声明
- 只能用于单行字符串初始化,如果再次出现双引号,则需要\进行转义
反引号方式申明
-
可用于单行字符串初始化,也可用于多行字符串初始化,如果出现双引号,则直接使用,不需要\转义。
-
定义标签和手写JSON或复杂字符串场景使用方便
3、Go编译器解析过程
-
扫描器
cmd/compile/internal/syntax.scanner
将输入的字符串转换成 Token 流-
token流
-
token流本质是uint无符号整形
-
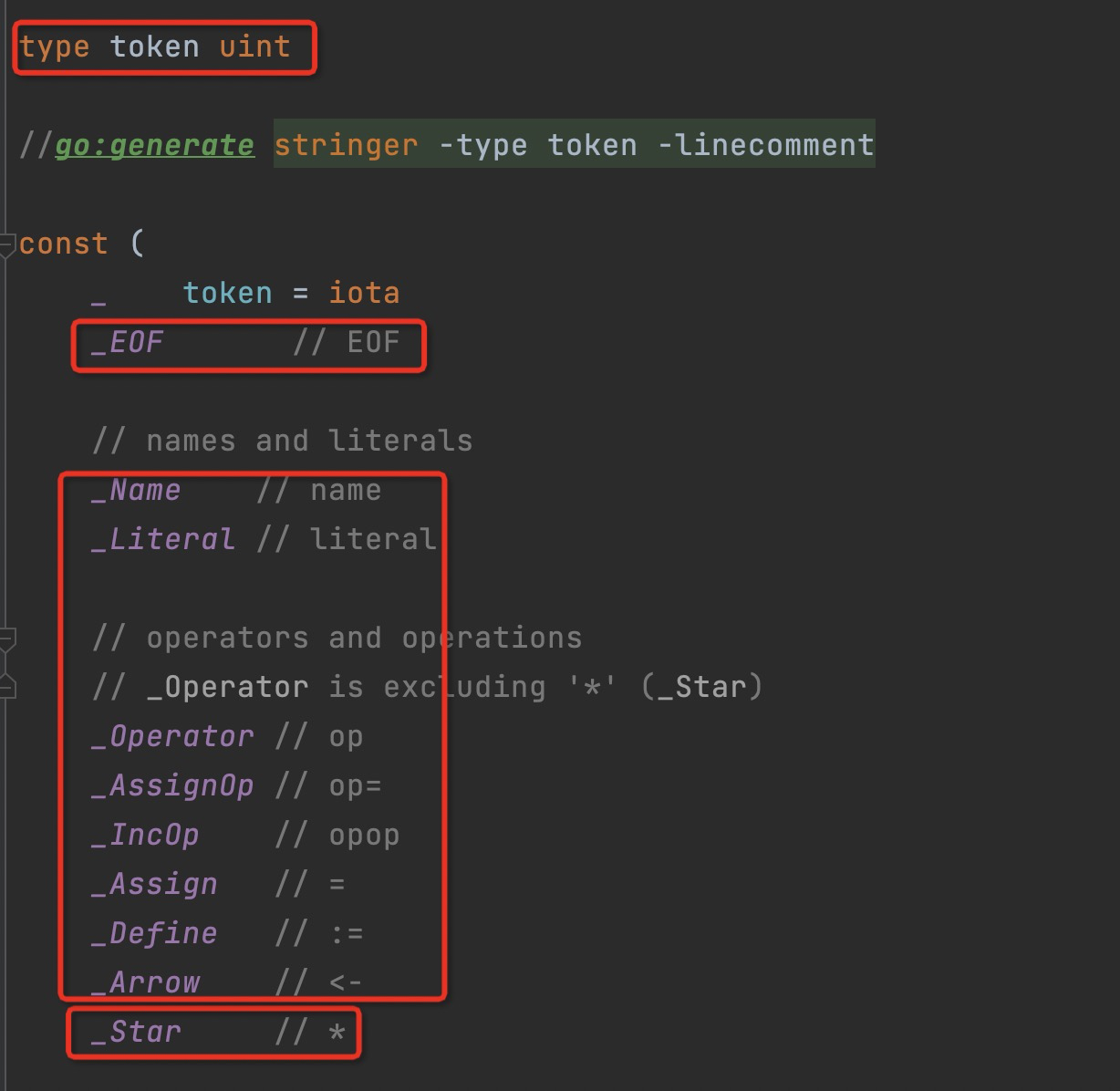
枚举中定义了各种token变量
![image-20211129203812598]()
-
在/usr/local/go/src/cmd/compile/internal/syntax/scanner.go 110行中可以直接看出扫描器扫描生成token流的顺序
-
比如解析到\n,token对应就是“;”号,表示下一行
-
解析到“(”号,token对应就是无符号数11即“(”号
![image-20211129204015885]()
-
通过 遍历字符串来生成对应的无符号数
-
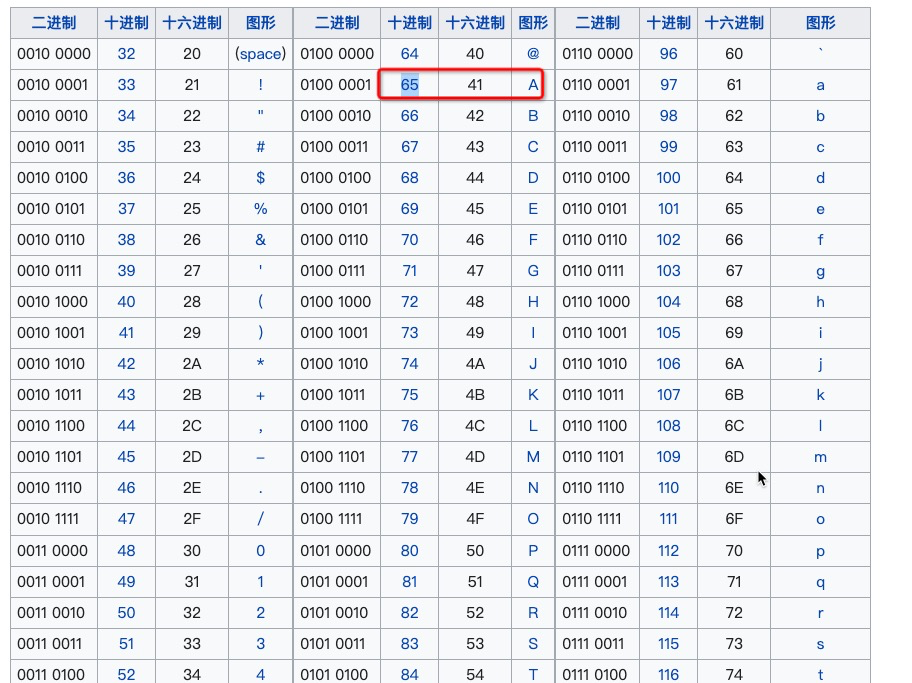
对应字母或汉字就是用ASCII码表示
-
举例
-
AAA(]:bbb解析出来就是65 65 65 11 15 19 98 98 98
![image-20211129204412440]()
-
-
-
-
-
解析器解析
2.1.双引号定义的字符串解析器
cmd/compile/internal/syntax.scanner.stdString 标准字符串使用双引号表示开头和结尾
标准字符串需要使用反斜杠
\来逃逸双引号 标准字符串不能出现如下所示的隐式换行
\n2.2.反引号定义的字符串解析器
cmd/compile/internal/syntax.scanner.rawString
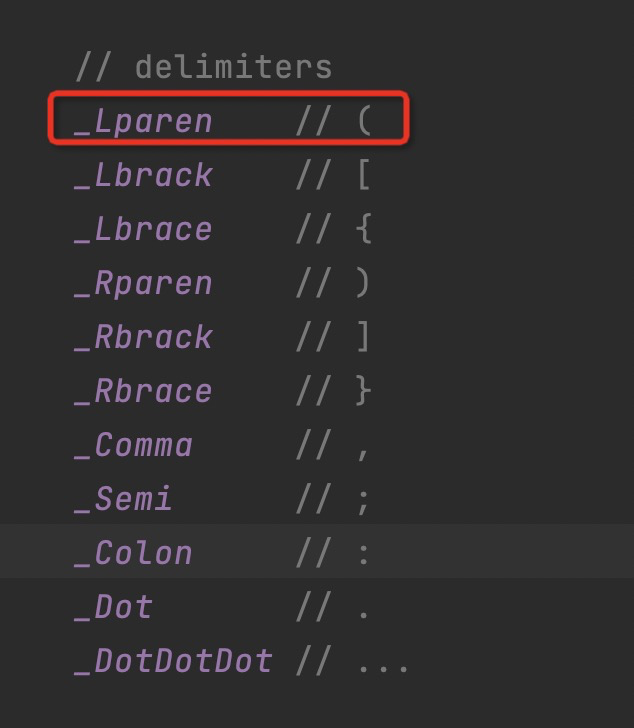
将非反引号的所有字符都划分到当前字符串的范围中
-
语法分析器
cmd/compile/internal/gc.noder.basicLit对字符串 Token 进行反序列,还原其本来的面目
4、拼接字符串的方式
-
说明
-
测试思路
-
常见的字符串拼接方式有
+号拼接、fmt.Sprint、strings.Join、bytes.Buffer、strings.Builder,通过测试各种方式的用时、内存分配大小、内存分配次数来看看哪一种方式比较高效一点。 -
benchmark 基准测试
go test -bench="Fib$" -benchtime=30s -count=1 -benchmem-
-bench="正则匹配"(运行哪些用例)
-
-cpu=x,y,z 传入列表作为使用CPU个数的参数(默认CPU核数)(使用x,y,z个CPU各跑一次)
-
-benchtime=测试的时间(e.g. 5s 五秒)或者用例的运行次数(e.g. 10x 十次)
-
-count测试的次数(默认一次)
-
-benchmem 查看内存分配
-
解析如图
![image-20211124100835213]()
-
-
-
-
开始测试
-
首先初始化一些字符串,放在数组里用于拼接
var stringArray []string func init() { setString(10, "AAA") } func setString(n int, s string) { fmt.Println("执行初始化字符串数组") for i := 0; i <= n; i++ { stringArray = append(stringArray, s) } } -
+号拼接
- 拼接函数
func addMethod() { var s string for _, v := range stringArray { s += v + "," } }- 测试函数
func BenchmarkAdd(b *testing.B) { for n := 0; n < b.N; n++ { addMethod() } }-
fmt.Sprint
-
拼接函数
func fmtMethod() {
a := make([]interface{}, len(stringArray))
for i, v := range stringArray {
a[i] = v
}
println(fmt.Sprintf("%s%s%s%s%s%s%s%s%s%s", a...))
}- 测试函数 ```go func BenchmarkFmt(b *testing.B) { for n := 0; n < b.N; n++ { fmtMethod() } } -
-
strings.Join
-
拼接函数
func joinMethod() { strings.Join(stringArray,",") } -
测试函数
func BenchmarkJoin(b *testing.B) { for n := 0; n < b.N; n++ { joinMethod() } }
-
-
bytes.Buffer
-
拼接函数
func bufferMethod() { var b bytes.Buffer for _, v := range stringArray { b.WriteString(v) } } -
测试函数
func BenchmarkBuffer(b *testing.B) { for n := 0; n < b.N; n++ { bufferMethod() } }
-
-
strings.Builder
-
拼接函数
func builderMethod() { var b strings.Builder for _, v := range stringArray { b.WriteString(v) } } -
测试函数
func BenchmarkBuilder(b *testing.B) { for n := 0; n < b.N; n++ { builderMethod() } }
-
-
-
测试结果
-
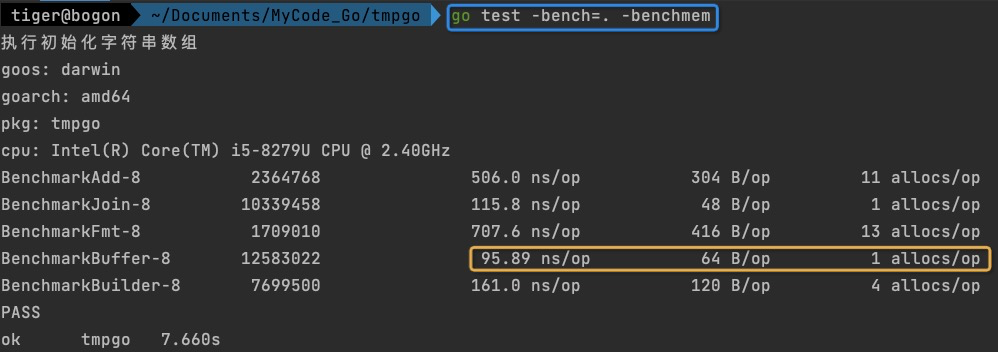
字符串为AAA,数组长度10
![image-20211124110231251]()
-
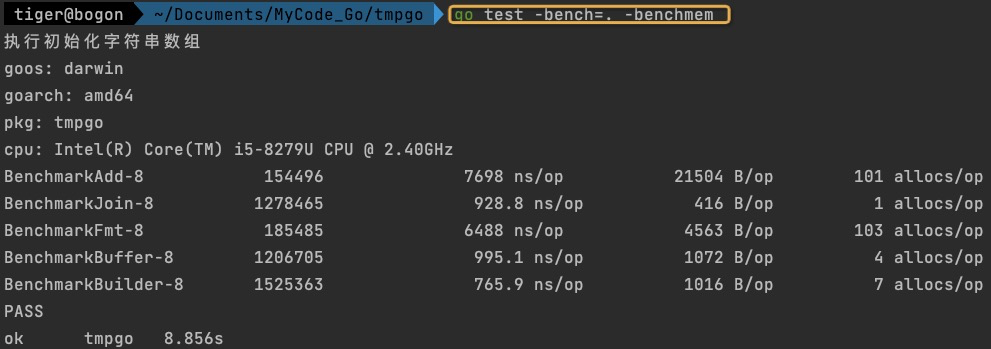
字符串为AAA,数组长度为100
![image-20211124110745495]()
-
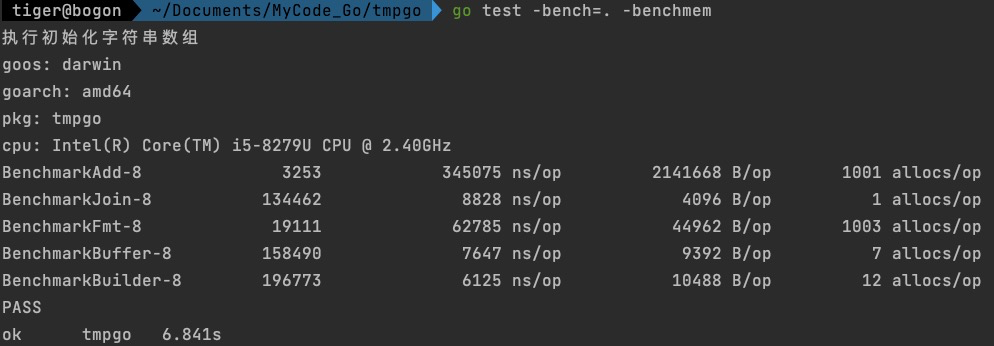
数组长度为1000
![image-20211124110925263]()
-
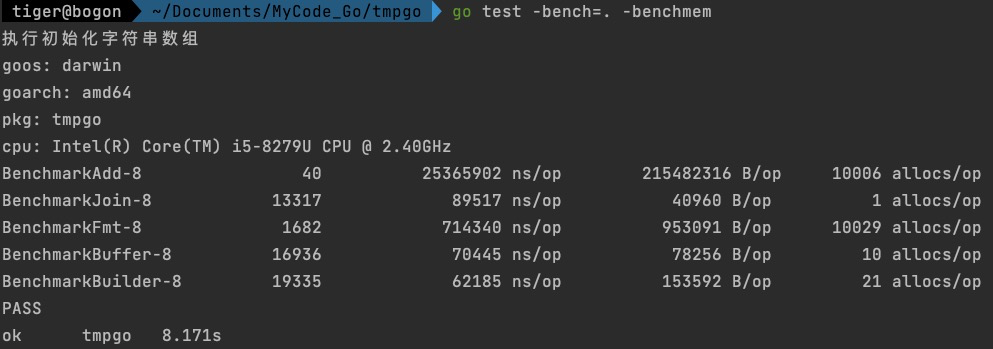
数组长度为10000
![image-20211124111031955]()
-
-
解读结果
-
➕号拼接
- 因为string是不可变的,每次拼接都会生成一个新的string,也就是会进行一次内存分配,可以看出数组长度为10,分配了11次内存,数组长度为100,分配了101次内存,数组长度为1000,分配了1001次内存
-
Builder拼接
- 随着数组的长度递增,每次操作使用的时间逐渐变短,时间优势逐渐体现。
-
Join拼接
- 不论数组长度是否递增,内存分配每次都是1次,这是因为每次都已知了数组长度,因为就能决定分配多少内存了,一次就搞定了
-
fmt拼接
- 内存分配和时间,看起来都和➕号拼接差不多,有时候甚至还不如➕号拼接
-
汇总
- ➕号拼适用于短小的、常量字符串(明确的,非变量),因为编译器会给我们优化
- Join适合有现成切片、数组的时候,并且使用固定方式进行分解的,比如逗号、空格等,比较局限。
- fmt适用于传参数拼接对象,格式化对象显示的时候
- buffer就中规中矩,普普通通,处于中间流派
- Builder从性能和灵活性上,都是上佳的选择
-
-
Builder的优化
-
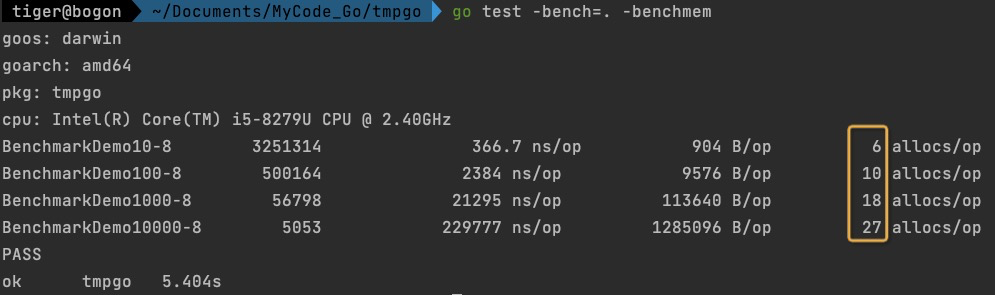
首先看一下拼接数组长度依次为10-100-1000-10000的效果
![image-20211124150908076]()
- 可以看到随着数组长度递增,分配内存的次数就会递增,这浪费了一些时间以及内存分配次数
-
可以通过预先设置builder的内存容量,来让内存只分配一次,这样就可缩短时间
-
拼接函数
//不设置容量的拼接 func noSetSize(s []string) { var b strings.Builder for _, v := range s { b.WriteString(v) } } //设置容量的拼接 func setSize(s []string, cap int) { var b strings.Builder b.Grow(cap) for _, v := range s { b.WriteString(v) } } -
测试函数
func BenchmarkBuilder10(b *testing.B) { s := initStrings(10) for n := 0; n < b.N; n++ { noSetSize(s) } } func BenchmarkBuilder100(b *testing.B) { s := initStrings(100) for n := 0; n < b.N; n++ { noSetSize(s) } } func BenchmarkBuilder1000(b *testing.B) { s := initStrings(1000) for n := 0; n < b.N; n++ { noSetSize(s) } } func BenchmarkBuilder10000(b *testing.B) { s := initStrings(10000) for n := 0; n < b.N; n++ { noSetSize(s) } } func BenchmarkBuilder10_(b *testing.B) { s := initStrings(10) for n := 0; n < b.N; n++ { setSize(s, len(BLOG)*10) } } func BenchmarkBuilder100_(b *testing.B) { s := initStrings(100) for n := 0; n < b.N; n++ { setSize(s, len(BLOG)*100) } } func BenchmarkBuilder1000_(b *testing.B) { s := initStrings(1000) for n := 0; n < b.N; n++ { setSize(s, len(BLOG)*1000) } } func BenchmarkBuilder10000_(b *testing.B) { s := initStrings(10000) for n := 0; n < b.N; n++ { setSize(s, len(BLOG)*10000) } } -
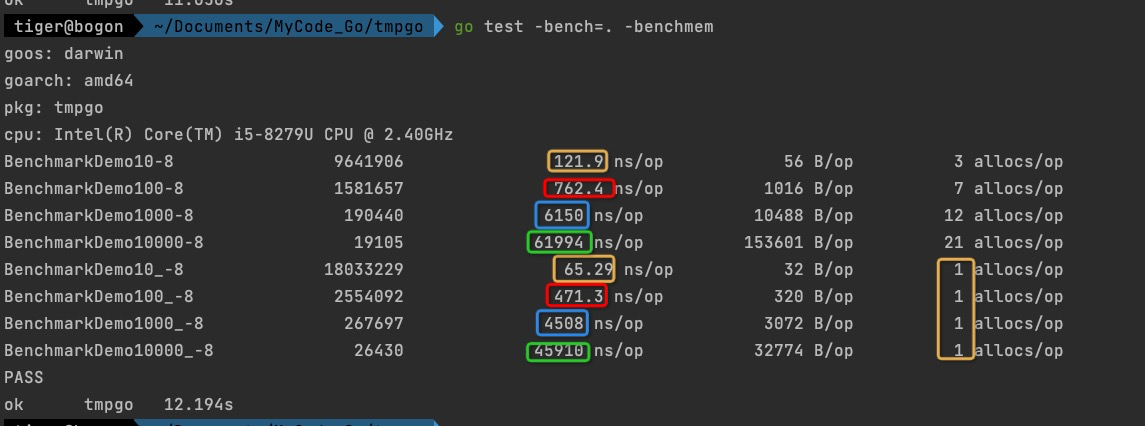
测试结果
![image-20211124152616438]()
可以看出,如果预先分配了容量,就能更快的拼接字符串,使得builder的效率再次提升。
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号