(Nosql)列式存储是什么?
首先nosql可以被理解为not only sql 泛指非关系型数据库,也就是说不仅仅是sql,所以它既包含了sql的一些东西,但是又和sql不同,并在其的基础上改变或者说扩展了一些东西。
提到nosql,首先我们就要分析一下关系型数据库的行式存储和非关系型数据库的列式存储区别在哪?
行式存储我们都很熟悉,不论是mysql数据表还是我们熟悉的excel表,这些表里每一行都是完整的一条数据,它们彼此关联,彼此有关系。
以核酸检测的数据为例:
行式存储
一般核酸检测需要以下几个字段:姓名、身份证号、检测机构、检测时间、结果、价格
比如是这样的:
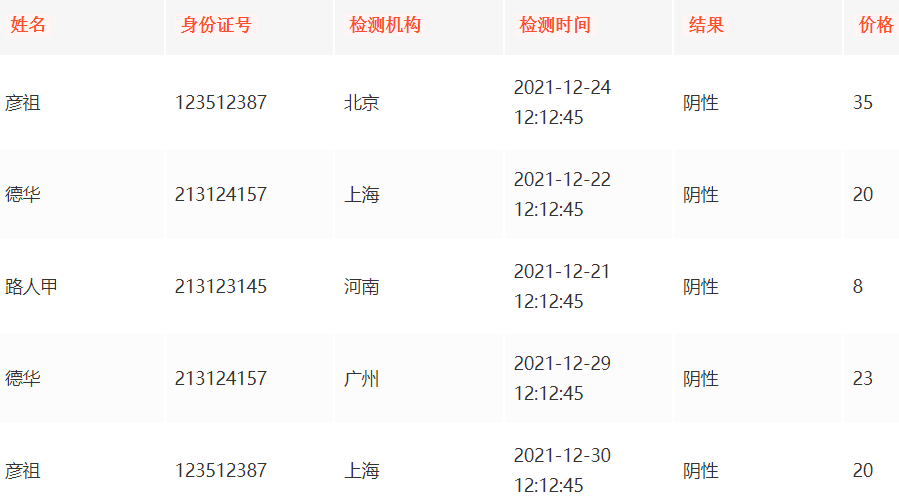

行存储优点分析
- 在这样的物理结构下,因为是连续空间,所以插入一条数据只需要追加到当前数据之后即可,很方便
- 对于按记录查询也很方便,例如:我们要查询彦祖的所有核酸记录,页面应用的话应该是通过彦祖的身份证号
- 对应的sql如下:
select * from 核酸记录表 where 身份证号='彦祖的身份证号'
- 这个sql的执行流程比较清晰
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
- 这样就可以快速得到彦祖的核酸记录
行存储缺点分析
- 这时候,业务方提了一个需求,他要统计彦祖做核酸总共花了多少钱
- 对于这个需求,sql实现也很简单,通过对
价格列sum就可以实现,sql如下:
select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
- 这个sql的执行流程也比较清晰
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
3.拿到所有数据时候,再通过对于价格列sum聚合得到结果
- 分析下,因为行存储使用的是连续空间,即使需求里面只需要
select sum(价格),但是读取物理存储时候,还是读取出来了所有的字段
行存储优缺点总结
- 通过上面的分析,总结一下行存储的优缺点
优点:
1.连续空间对于插入/更新很方便
2.对于记录查询很方便
缺点
1.会查询出来很多不需要的列
列式存储
- 在列存储中,对于同样的核酸记录表,存储的物理结构如下:

- 在列式存储中,会把每一列存储到一起,如
姓名列,是把所有记录中的姓名这列的值使用连续空间存放到一起 - 而对于各个列之间,是没有必要使用连续空间存放到一起的,所以很多列式数据库都使用了分布式存储的方式,存储各个列
- 下面我们来分析下列存储的
数据压缩和查询执行流程
列存储的数据压缩
- 很多列式数据库都是通过
字典表的方式进行数据压缩 - 因为是把每一列存放到一起的,所以很容易通过对于每一列进行去重,来构建一个字典表,例如:
- 对于
姓名列,这列的所有数据如下:
彦祖|德华|路人甲|德华|彦祖
-
对这列值去重以后,构建一张
姓名列字典表,构建算法忽略,就使用自增id的方式,如下:id姓名列1 彦祖 2 德华 3 路人甲 -
这样构建字典表,对于列存储的物理存储结构,就可以执行存储字典表中的id,而不用存储具体的值,有了字典表以后
姓名列存储如下:
1|2|3|2|1
- 同样对于
价格列,这列的所有数据如下:
35|20|8|23|20
-
对这列值去重以后,构建一张
价格列字典表,构建算法忽略,就使用自增id的方式,如下:id价格列1 35 2 20 3 8 4 23 -
有了字典表以后
价格列存储如下:
1|2|3|4|2
- 这样通过一些数据压缩算法等,可以对数据存储进行压缩
列存储的查询执行过程
- 有字典表以后,我们来看下,列存储一般是如何进行查询的
- 业务需求查询
彦祖,20块钱做的核酸记录:
select * from 核酸记录表 where 姓名=彦祖 and 价格=20
- 对于该sql,执行过程如下:
1.对于where 姓名=彦祖
首先查询姓名字典表,查询到彦祖的id=1
id |
姓名列 |
|---|---|
| 1 | 彦祖 |
| 2 | 德华 |
| 3 | 路人甲 |
2.通过查询到彦祖的id,对于性名列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
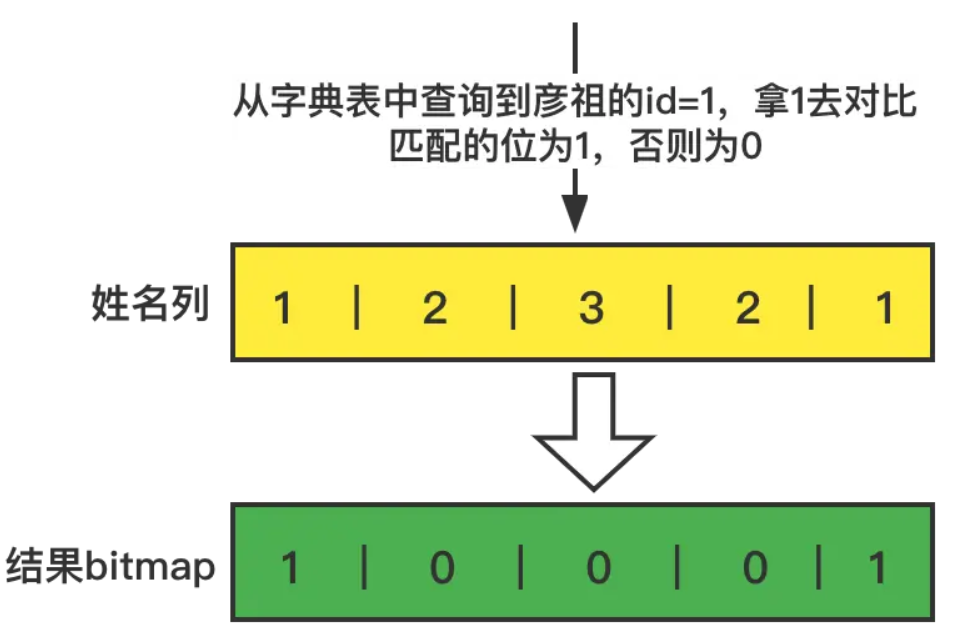
3.对于where 价格=20 和上面一样的操作,先查询价格字段表,20 的id=2
id |
价格列 |
|---|---|
| 1 | 35 |
| 2 | 20 |
| 3 | 8 |
| 4 | 23 |
4.通过查询到价格20的id,对于价格列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
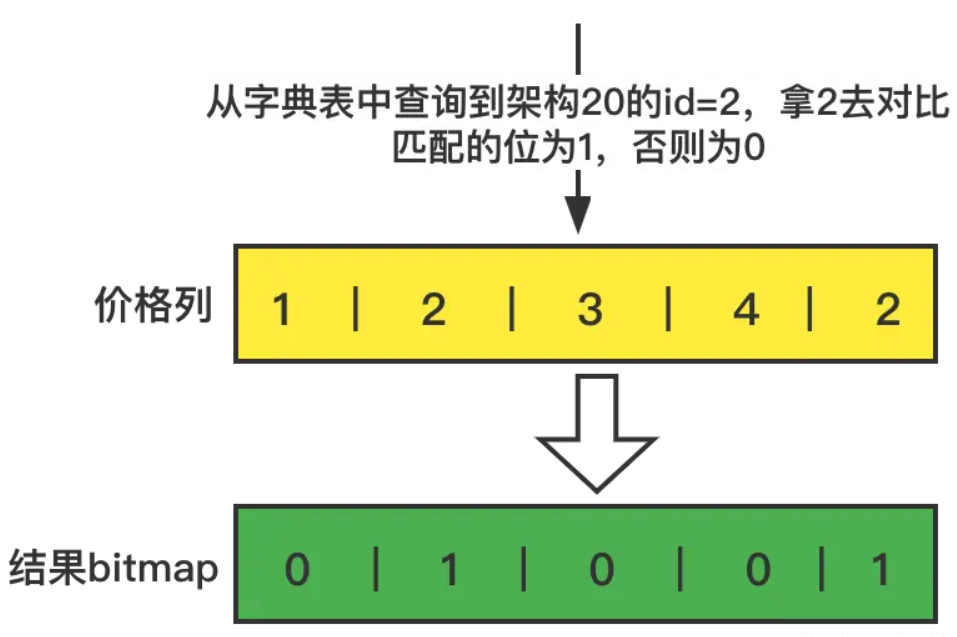
5.对于两个where条件的结果bitmap做与运算,bitmap中,位为1的索引就是要查询数据的所有列的索引,如该例子中,两个结果bitmap与运算后的结果是00001,所以所有列的第5个值,拼接起来就是我们要查询的数据。
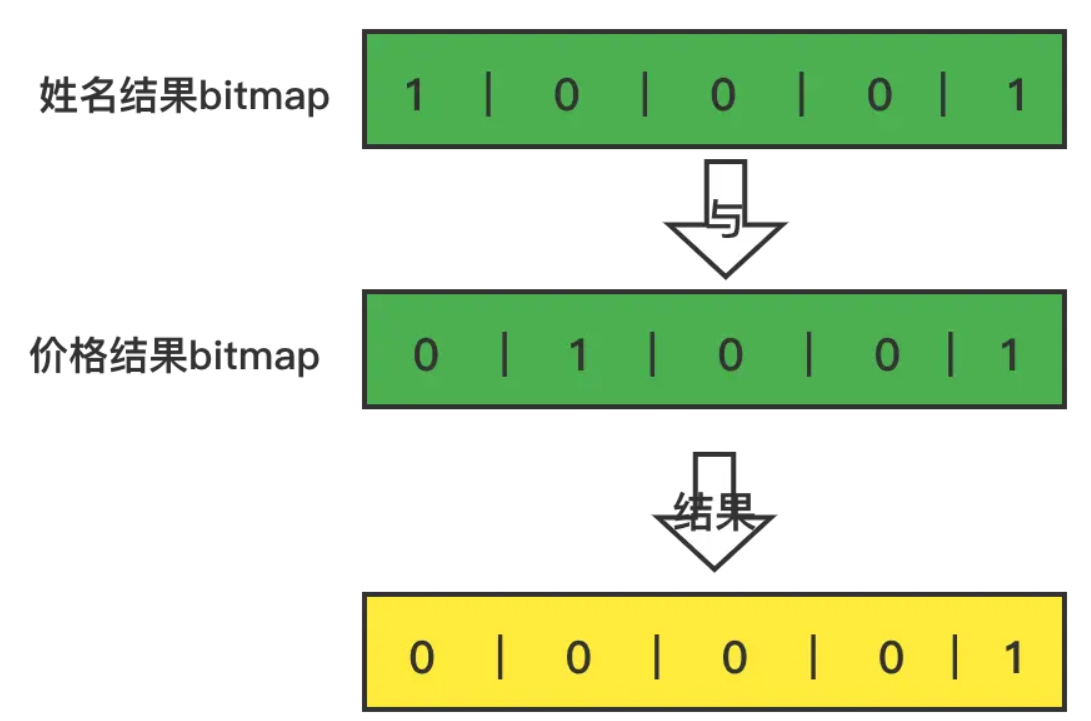
6.所以我们把所有列的第五个值拿出来组装后就是我们需要的数据
列存储优点分析
- 上面讲了列存储的
数据压缩,在数据压缩上列存储有一定的优势 - 每一列都可以天然做索引,不需要额外的数据结构来对各个列构建索引,所以不用在意每一列的数据类型,都可以做索引
- 对于统计彦祖做核酸总共花了多少钱这种需求
select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
- 因为列是
分开存储的,按照上面讲的查询流程,其实最后我们得到的结果bitmap,拿到位=1的索引后,我们不需要查询所有的列,只需要拿着索引去价格列中获取相应位置的值,然后在进行sum聚合
列存储缺点分析
- 因为各个列是分开存储的,所以在插入、更新时,需要对于
每一个列进行操作,没有行存储连续空间那么方便 - 还是看上面说的查询过程,每次查询过后,都需要对查询到的需要的列进行一个数据组装
列存储优缺点总结
- 通过上面的分析,总结一下列存储的优缺点
优点:
1.数据压缩比较有优势
2.任何列都可以做索引
3.查询时只有涉及到的列会被读取
缺点
1.每次查询时,都需要对查询到的列进行数据重新组装
2.插入/更新操作比较困难
好看请赞,养成习惯:) 本文来自博客园,作者:靠谱杨, 转载请注明原文链接:https://www.cnblogs.com/rainbow-1/p/16573903.html
欢迎来我的51CTO博客主页踩一踩 我的51CTO博客
文章中的公众号名称可能有误,请统一搜索:靠谱杨的秘密基地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号